唔~咖啡泡出来好好看呀!
一、写作业
第一件事是将昨天读的NER综述补充到作业之中~大概30min
50分钟,补充完了思维导图和文档,明确了下一步论文的阅读方向——NER的综述/网安NER具体技术类文章(找找最新的叭)。
二、AttacKG
(一)重调代码
昨天代码跑起来啦,但是emm输出结果好奇怪hhh,本以为是源代码的bug,但看了哆啦a梦的blog,emm发现是自己的问题,再看看~预计1小时
1、重新装了coferee,不太管用
2、把图片放大看,好像没有那么荒凉,还是有字的
哈哈哈哈哈
要被蠢死啦hhhh

不过这也太丑了叭~
(二)改字体大小(小改代码)
借着这个机会,熟悉一下这里面的代码~
1、在main.py找到对应画图函数


2、跳进attackGrapg_generating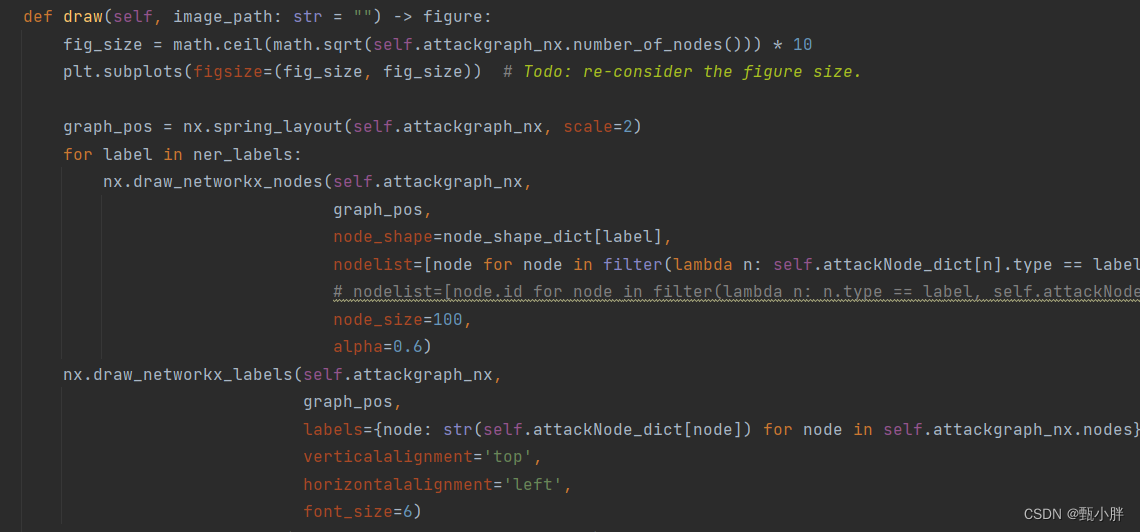
3、改draw就好啦
4、文本太长了emm全都重叠了

5、主要问题在于label太长了,好丑,之后再调,把节点调大了一点
6、现在觉得git真香哦~
—1402下午场的AttacKG,
(三)梳理代码
1、先磨下刀,看看别人是怎么复现一篇论文的
(1)先看.py文件的结构,一般分为数据预处理、增强、训练、测试
(2)放小批量数据debug,弄清模块之间的顺序,每个模块的大致功能,不需要弄清楚细节
(3)画出流程图,理清每个模块之间的关系。
https://blog.csdn.net/weixin_45638136/article/details/123772812
tips:
(1)勤注释;输入、输出、功能,不熟练时加入输入输出维度
2、梳理.py结构
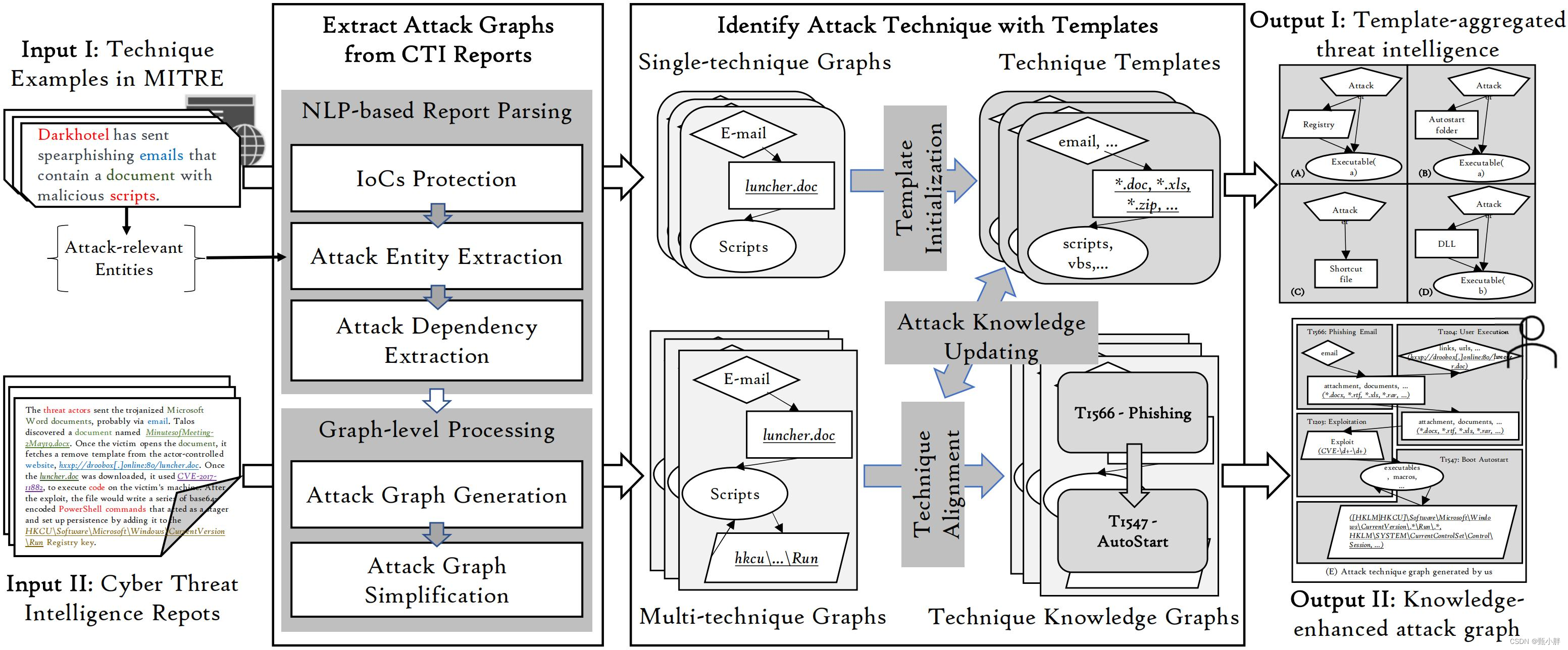
(1)惊奇地发现了一张图,比论文呢里的详细一点嘿嘿
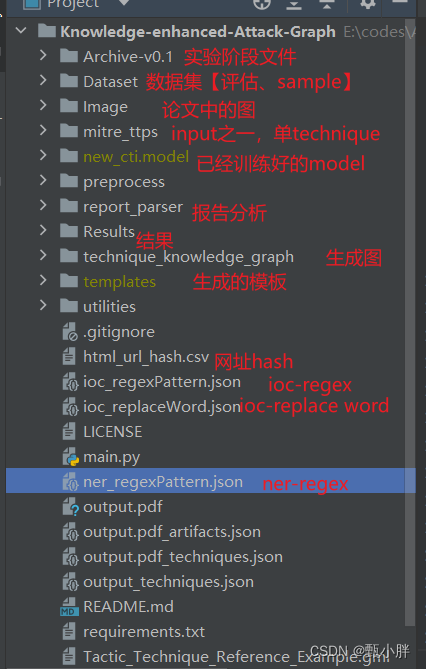
(2)大致目录
preprocess是对报告的预处理
3、main.py
running_mode = arguments.mode
print(f"Running mode: {running_mode}")
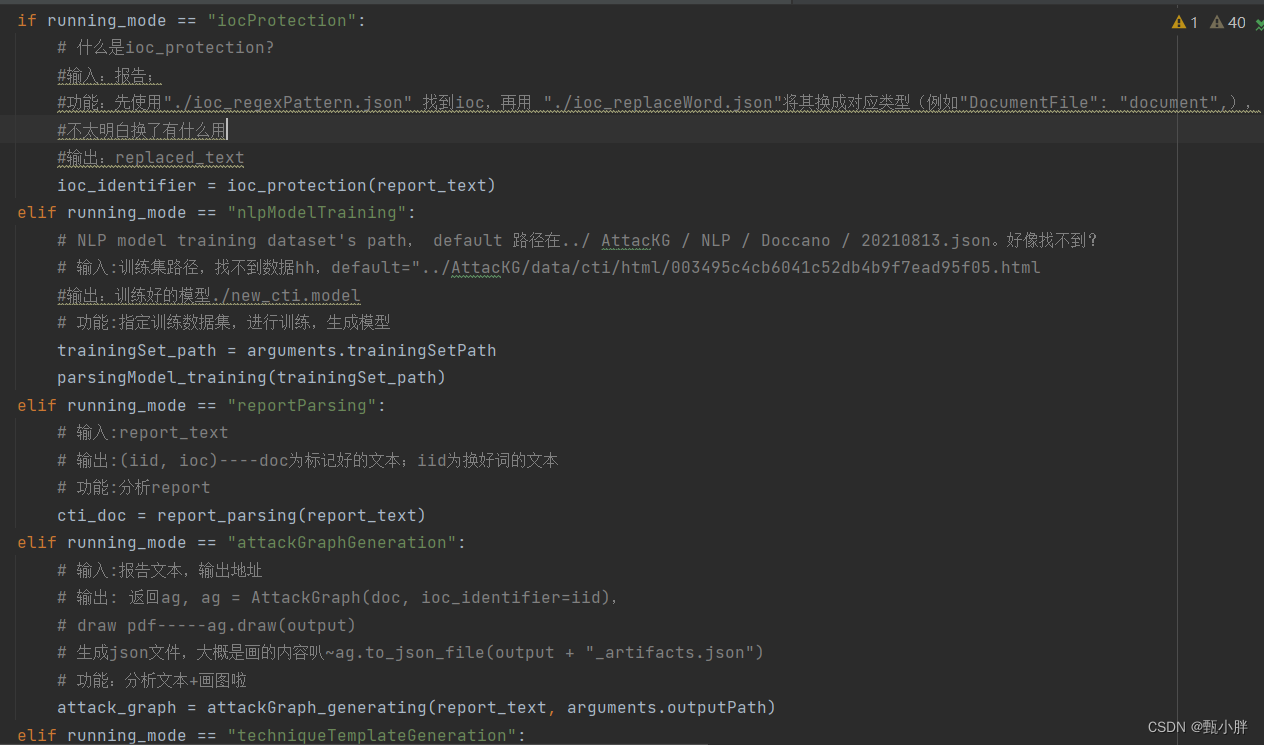
if running_mode == "iocProtection":
# 什么是ioc_protection?
#输入:报告;
#功能:先使用"./ioc_regexPattern.json" 找到ioc,再用 "./ioc_replaceWord.json"将其换成对应类型(例如"DocumentFile": "document",),
#不太明白换了有什么用
#输出:replaced_text
ioc_identifier = ioc_protection(report_text)
elif running_mode == "nlpModelTraining":
# NLP model training dataset's path, default 路径在../ AttacKG / NLP / Doccano / 20210813.json。好像找不到?
# 输入:训练集路径,找不到数据hh,default="../AttacKG/data/cti/html/003495c4cb6041c52db4b9f7ead95f05.html
#输出:训练好的模型./new_cti.model
# 功能:指定训练数据集,进行训练,生成模型
trainingSet_path = arguments.trainingSetPath
parsingModel_training(trainingSet_path)
elif running_mode == "reportParsing":
# 输入:report_text
# 输出:(iid, ioc)----doc为标记好的文本;iid为换好词的文本
# 功能:分析report
cti_doc = report_parsing(report_text)
elif running_mode == "attackGraphGeneration":
# 输入:报告文本,输出地址
# 输出: 返回ag, ag = AttackGraph(doc, ioc_identifier=iid),
# draw pdf-----ag.draw(output)
# 生成json文件,大概是画的内容叭~ag.to_json_file(output + "_artifacts.json")
# 功能:分析文本+画图啦
attack_graph = attackGraph_generating(report_text, arguments.outputPath)
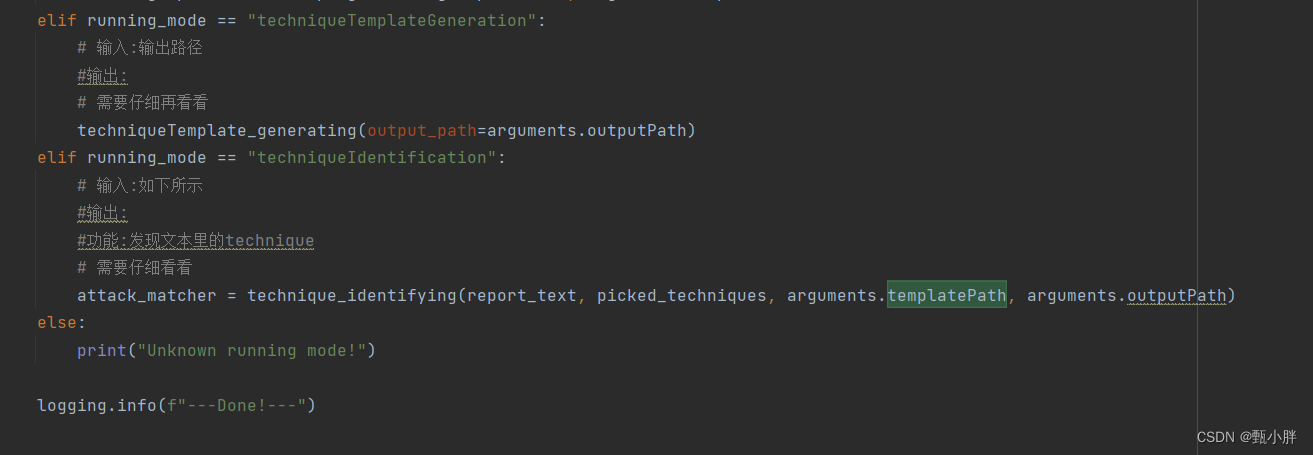
elif running_mode == "techniqueTemplateGeneration":
# 输入:输出路径
#输出:
# 需要仔细再看看
techniqueTemplate_generating(output_path=arguments.outputPath)
elif running_mode == "techniqueIdentification":
# 输入:如下所示
#输出:
#功能:发现文本里的technique
# 需要仔细看看
attack_matcher = technique_identifying(report_text, picked_techniques, arguments.templatePath, arguments.outputPath)
else:
print("Unknown running mode!")
4、最后两个模块没时间好好看啦,要去跑步啦
1606
三、SVM&RF
今天要看看svm调参的问题&RF的原理~
(一)SVM
1、先跑一下~
2、其他笔记写电脑文档上啦
-------1357
上午写着写着被叫去吃饭啦~
简单试了一下核函数
还差一个多项式核没试~试一下,然后就继续去看KG的代码啦
3、没怎么调的情况下,还是高斯核是最好的
4、之后看下别人是怎么调svm的~ 动手试一试~
接着去看AttacKG啦
-----------1851
今天跑了6km欸,速度比昨天还快一点~运动完心情真的会好!磨磨唧唧看视频吃完饭后,没想到这么自觉开始学习emmmm要被自己感动哭了
看会图谱的书叭~明天晚上还有个讲座捏捏捏
四、KGBOOK
—2057
感觉晚上效率不高哇~不过适当休息也蛮好呀!轻松学习!
刚刚看了3.2知识建模和3.3知识抽取,主要讲的是相关工具。
我的重点放在工具实现的原理上,借此机会去了解,这些任务的工程化实现方法~
(一)知识建模(7步)
1、确定本体的领域和范围
2、考虑使用已有本体
3、列举本体中的关键项
4、确定类和类的结构
5、确定类的属性(对象属性、数据属性)
6、确定属性特点(数据属性的数据类型)
7、创建实例(实体)
五、RCE
(一)安装BURPSUITE
我感觉时间会静止在这个安装时刻
先下着叭~
去看看php漏洞视频叭~
emmm为什么56 这么长呀~还是休息叭hhh
(二)知识抽取
1、导入先验数据(labeled)
2、导入待抽取数据
3、文本预处理(token,词根还原,词性标注,ner,依存句法分析)
4、实体抽取(mention_text,doc_id,sentence_index,begin_index,end_index)
5、候选实体对生成
6、特征抽取
7、样本标注(远程监督&启发式)
8、因子图构建(好像就是个模型???用来生成关系的)
好啦好啦,总结完了,我去看看ctf了~
N、杂
(一)spacy
emm一笔都没写哦~









![[附源码]计算机毕业设计JAVA考研部落](https://img-blog.csdnimg.cn/7f9961dfc6da467fa6fca3a63fd2f412.png)