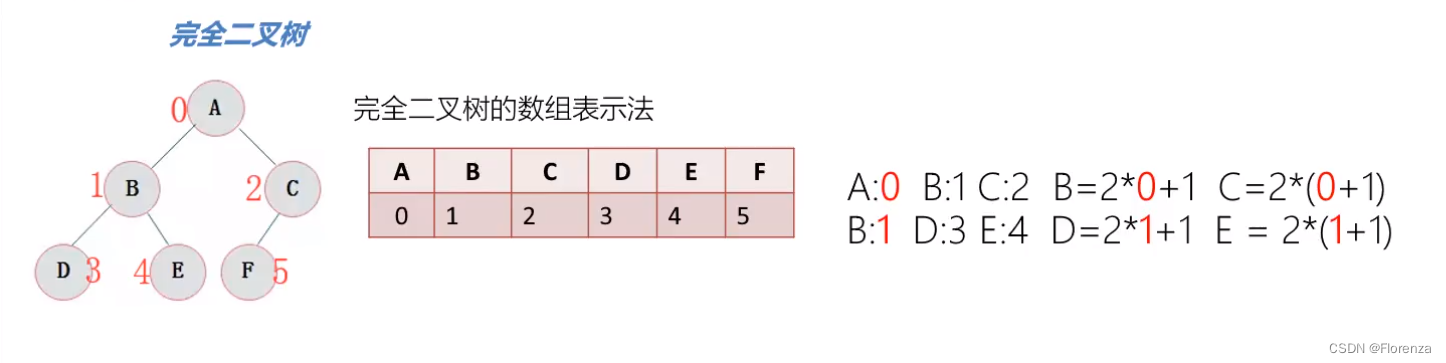
文章目录
- 1. Efficientnet的学习
- 1.1 网络模型
- 1.2 MBConv卷积块
- 1.3 模型规模
- 1.4 模型训练方式
- 2. Efficientnet-pytorch代码
- 3.参考
1. Efficientnet的学习
论文:https://arxiv.org/abs/1905.11946
1.1 网络模型
主要结构:
- 基线模型EfficientNet-B0
- EfficientNet-B0进行复合缩放(深度、宽度(特征通道数)、图片大小)
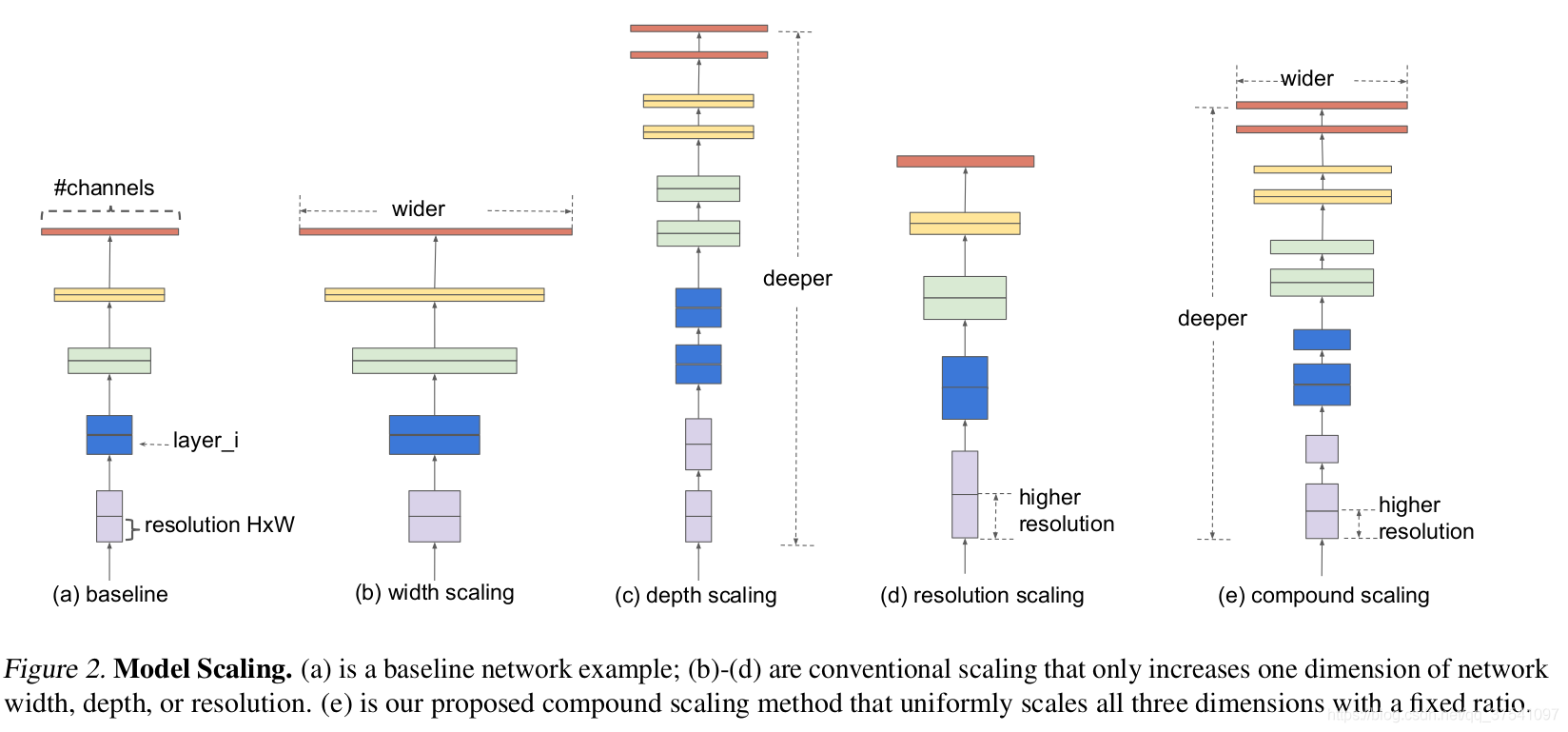
思考:
1.网络越深,学习到的特征越丰富、复杂。但太深容易造成梯度消失,导致训练困难。
2.网络越宽,网络能得到更高粒度的特征,且容易训练。但仅加宽不加深的话,学习不到深层次的特征,需综合衡量计算量的问题。
3.图像分辨率越高,网络能得到 潜在的 更高细粒度的特征channel。但会增加计算量。
1.2 MBConv卷积块
- Relu替换为Swish
f(x)=x⋅sigmoid(βx),β是个常数或可训练的参数.Swish 具备无上界有下界、平滑、非单调的特性。Swish 在深层模型上的效果优于 ReLU。
https://blog.csdn.net/m0_38065572/article/details/106210576 - 增加SE模块
SE模块为注意力网络,学习通道之间的相关性。
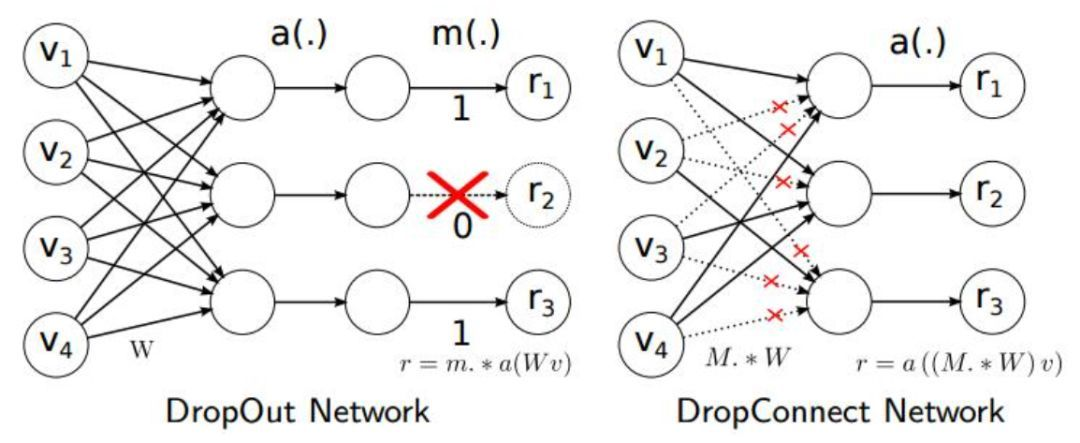
https://zhuanlan.zhihu.com/p/102035721 - Dropout替换成DropConnect

dropconnect将对输出的隐层神经元随意丢弃变为对输入的神经元进行随意丢弃。其防止模型产生过拟合的效果更好。
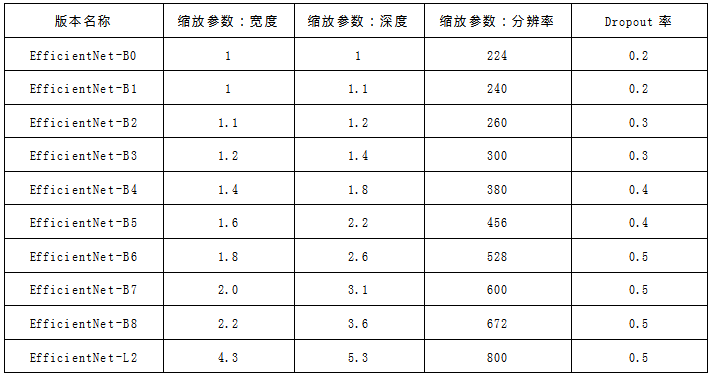
1.3 模型规模
1.4 模型训练方式
- RandAugment
数据增强方式,相较于AutoAugment更易用,将AutoAugment的30种变化方式简化为2个参数(N个变换和M个转换,M表示增强失真的大小,范围0-10),其增强效果可控。 - AdvProp
对抗样本算法(PGD、I-FGSM和GD),增强样本泛化能力 - Noisy Studen
分类效果表现最佳
2. Efficientnet-pytorch代码
- https://gitcode.net/mirrors/lukemelas/efficientnet-pytorch?utm_source=csdn_github_accelerator
- https://github.com/yakhyo/EfficientNet-pt
- https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/Test9_efficientNet
3.参考
- https://cloud.tencent.com/developer/article/1580853
- https://blog.csdn.net/weixin_45377629/article/details/124430796
- https://blog.csdn.net/qq_37541097/article/details/114434046







![[附源码]计算机毕业设计JAVA考研部落](https://img-blog.csdnimg.cn/7f9961dfc6da467fa6fca3a63fd2f412.png)