目录
1. 介绍
2. 代码详解
3. 代码
1. 介绍
分割的目的是将图像分为多个区域
常用的分割方法基于两个属性:不同区域间的灰度不连续性质(Canny边缘检测等等)、相同区域灰度的相似特征(阈值处理、区域生长等等)
区域生长就是基于同一区域的灰度相似特性展开的,通过预先设定的生长准则,将像素种子生长到更大区域的过程。基本的方法是,对于一组预设的点(这里称为种子),通过和其周围邻域灰度值比较,满足相同特性的(灰度值差异较小)像素点添加到新的种子,进而增长区域
区域生长的步骤为:
1. 先定义一组种子
2. 找到每一个种子的八邻域,判断它们的灰度值是否相似,相似的区域也划为新的种子
3. 循环这个过程,直到种子全部遍历完
2. 代码详解
这里不同的地方在于传入的种子是一副图像。
例如将原图进行二值化处理,然后找到这二值化的图像传入seeds里面,通过np.where(seeds > 0) 来找到具体的种子点,然后保存在seed_list里面。这里的种子列表应该是一组这样 [x,y] 的点

循环停止的条件是种子列表里面没有种子。
将每一个种子取出,然后将对应的位置作为区域分割的结果 dst[x,y] = 255 。
根据之前定义的connects 周围8个点的相对位置偏差,找到周围的 8邻域

如果 8邻域不在图像上的话,就跳过这次判断
如果在图像上的话,判断是否满足灰度值相似的条件,并且这里要判断这个区域是否已经处理过,要不然会进入死循环
想象一下,相邻的两个点AB,在A是种子的时候,B作为A的邻域满足相似性,所以B为储存到种子列表。判断B的时候,A作为B的邻域,也会被储存到种子列表。那么这里就会出现死循环
但是,如果A已经被处理过了,dst 对应的A点已经是区域生长的区域的话。那么A作为B邻域的时候,A就不会作为新的种子了
如果都满足的话,保存到种子列表里面

3. 代码
import cv2
import numpy as np
# 区域生长算法
def regional_growth(image, seeds, thresh=5): # 这里的seeds是一副图像
height, weight = image.shape[0], image.shape[1] # 图像的 height和 width
dst= np.zeros(image.shape, dtype=np.uint8) # 处理的结果
seed_list = [] # 种子列表
x,y = np.where(seeds > 0) # 找到种子seeds里面的种子
for i in range(len(x)):
seed_list.append((x[i],y[i]))
connects = [(-1, -1), (0, -1), (1, -1), (1, 0), (1, 1), (0, 1), (-1, 1), (-1, 0)] # 8 邻域
while len(seed_list) > 0: # 判断种子受否剩余
point = seed_list.pop(0) # 取出第一个
x, y = point[0],point[1]
dst[x, y] = 255 # 将对应位置的点标记为 255
for i in range(8): # 对种子周围的 8个点一次进行相似性判断
connects_tmp = connects[i] # 8 邻域
x_tmp= x+ connects_tmp[0]
y_tmp= y+ connects_tmp[1]
if (x_tmp < 0) or (y_tmp < 0) or (x_tmp >= height) or (y_tmp >= weight): # 是否超出限定阈值
continue
gray_diff = np.abs(int(image[x, y]) - int(image[x_tmp, y_tmp])) # 判断相似性
if (gray_diff <= thresh) and (dst[x_tmp, y_tmp] == 0): # 相似的话储存为新的种子
dst[x_tmp,y_tmp] = 255
seed_list.append((x_tmp,y_tmp))
return dst
# 区域生长 主程序
img = cv2.imread("./img.tif", flags=0)
_, img_bin = cv2.threshold(img, 254, 255, cv2.THRESH_BINARY) # 阈值处理产生种子区域
dst = regional_growth(img, img_bin)
cv2.imshow('img', np.hstack((img,dst)))
cv2.waitKey()
cv2.destroyAllWindows()
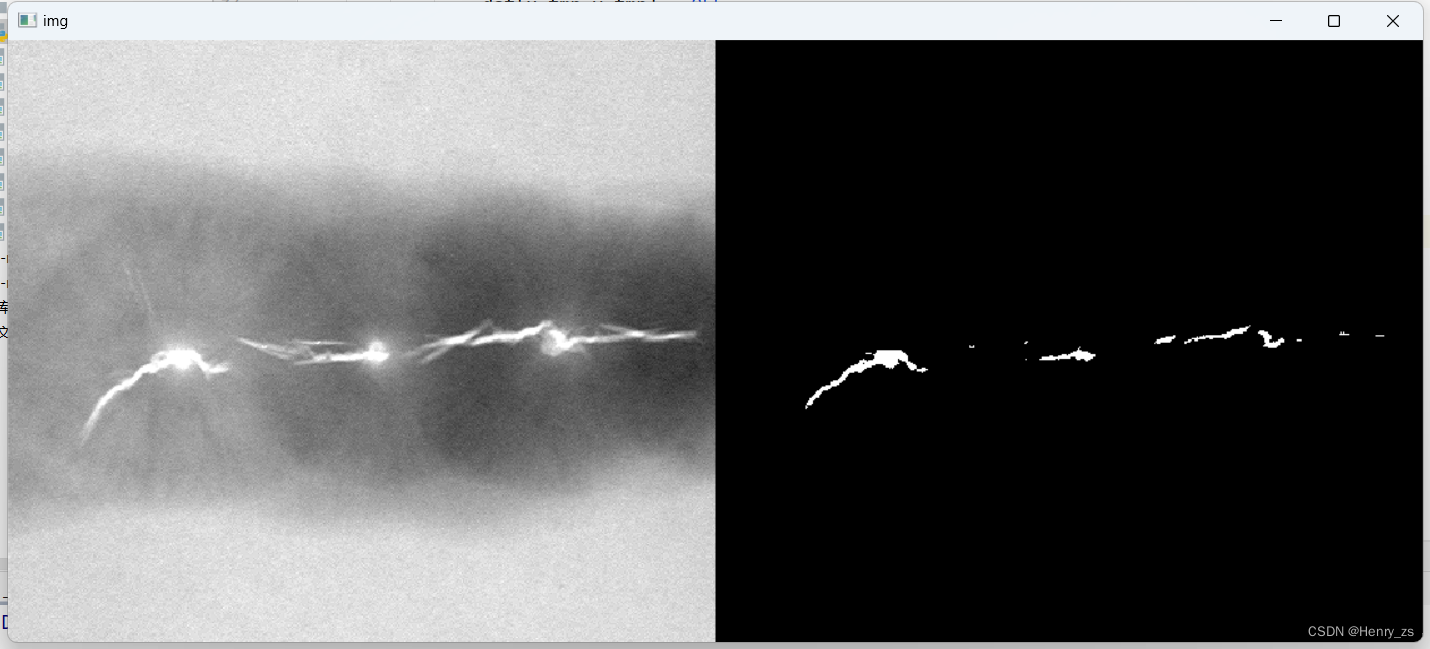
处理结果:
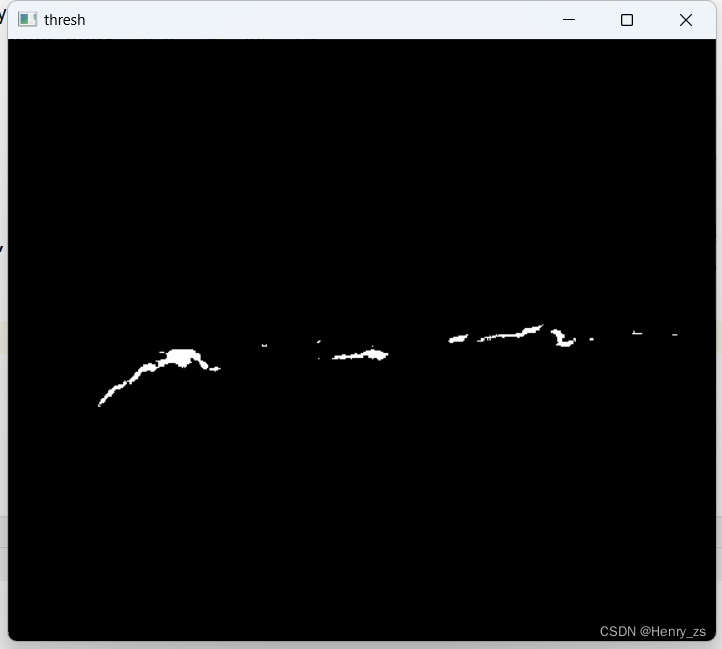
这里阈值产生的种子图像为:



![[MySQL]事务ACID详解](https://img-blog.csdnimg.cn/fc9367d3361843ada90717e1b3016bf1.png)