目录
- 为什么需要消息队列
- 1.异步处理
- 2.服务解耦
- 3.流量控制
- 消息队列
- 1.两种模型
- 2.基本原理
- 3.常见问题
本篇文章参考文献如下:
面试题:如何保证消息不丢失?处理重复消息?消息有序性?消息堆积处理? (qq.com)
超详细的RabbitMQ入门,看这篇就够了!-阿里云开发者社区 (aliyun.com)

为什么需要消息队列
在日常当中,消息队列往往指的是消息中间件,它主要的功能就是用来存放消息,便于应用之间的消息通信
”对象之间的关系远比对象本身要重要“
在过去业务量小的时候,企业用的都是单机架构,直接一台单机就能满足日常业务的需求了
随着互联网的不断发展,公司的业务体量不断扩大,老旧的单机架构已经不能满足日常需求了,于是分布式、微服务这些新架构新方法不断涌现出来
这也意味着成千上百服务之间的依赖、调用关系越来越复杂,这时候我们迫切的需要一个【中间件】来解耦服务之间的关系,控制资源的合理合时分配以及缓冲流量高峰等等
消息队列应运而生,消息队列的三大经典场景——异步处理、服务解耦、流量控制
1.异步处理
你负责公司的一个电商项目,业务初期只是一个很简单的流程:用户下单支付—>扣库存—>下单成功
后面来了个产品经理跟你说要搞个积分系统,问题不大,流程里多加一步就行了
结果你发现产品经理并不满足于此,又来找你说要搞个优惠券系统,你咬咬牙说:行!整就完事了
再后来产品经理一脸邪笑的找到你,下单成功之后我们需要给用户发送短信,再搞个短信服务吧嘿嘿嘿
你薅了薅自己日渐稀疏的发顶,不禁感叹世事无常大肠包小肠…
到后面你的项目流程就如下图右边所示(在现实的电商项目中,涉及到的流程可比这个复杂多了)
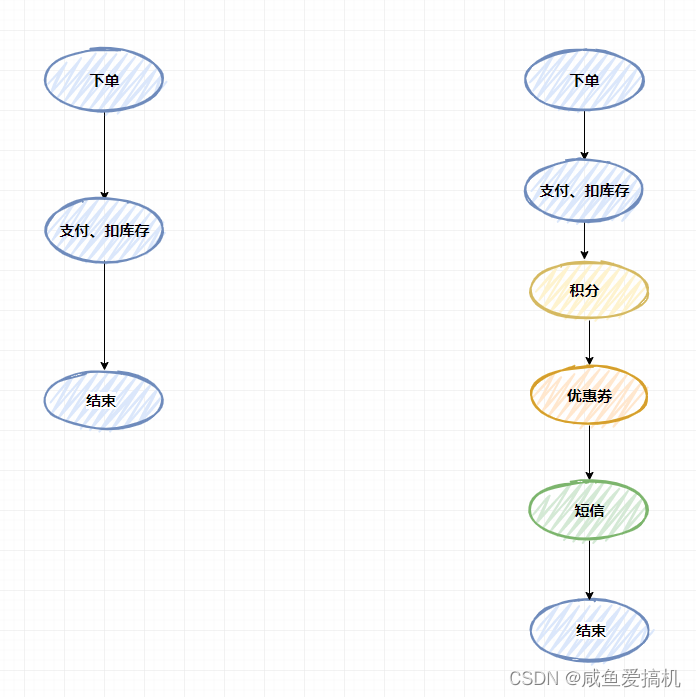
如果按照这个流程来执行,时间可不是一般的长,用户到时候就会发现我在你这买个东西要花几十秒,什么垃圾软件,爬!
既然流程长了会导致时间变长,但我们可以将其中一些流程同时做呀——用户下单成功之后,我去检验优惠券的同时还能去增减积分,还能发个短信
怎么实现异步呢?消息队列!
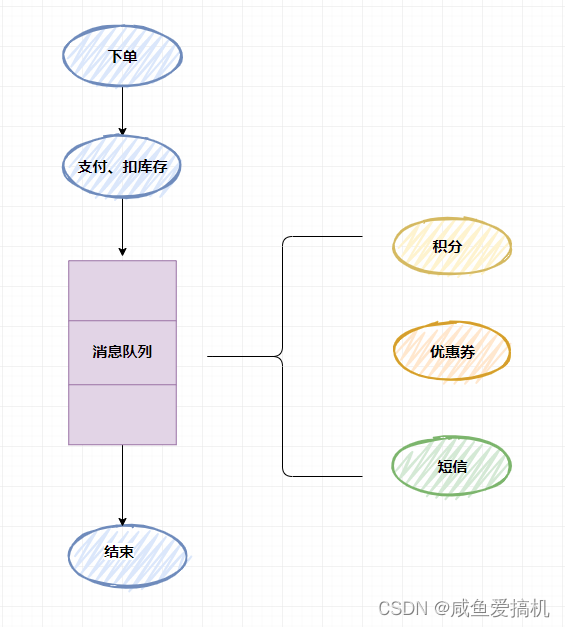
相对于扣库存和下单,积分和短信是没有必要这么的“及时”,因此你只需要在支付后的那个流程,扔个消息到消息队列当中就可以直接返回响应给客户端了,不需要再等待积分、优惠券、短信服务
而积分、优惠券、短信服务就可以去消费这条消息,执行之后的流程
有了消息队列,用户只需要很短时间内就知道自己支付成功了,至于短信和积分这些非必要服务,迟几秒并不会特别影响用户的使用体验
2.服务解耦
上面的电商场景中已经有了——积分服务、优惠券服务、短信服务
万一后面可能又来个营销服务、活动期间再弄个促销服务等等等等…
随着服务越来越多,就需要经常的修改支付服务的下游接口,任何一个下游服务接口的变更都可能会影响到订单服务的代码
为了解决服务之间的依赖关系,降低服务间的耦合度,我们可以在支付服务和下游的服务中间加一个消息队列
支付服务只需要把订单、支付相关消息塞到消息队列当中,下游的服务谁需要这个消息自己去获取就行了
这样无论下游添加了什么服务,都不会影响上游的订单服务

3.流量控制
在平常的业务场景中,你的流量很低,但是一旦遇到秒杀活动、双十一活动这些大流量的场景
尤其是在某一时刻(例如 00:00)流量如洪水猛兽一样疯狂怼进来,你的服务器、MySQL、Redis各自的性能都是不一样的
你肯定不能将全部的流量请求照单全收,很容易会将性能低的服务器直接打挂
所以需要引入一个中间件来做缓冲,消息队列是一个很好的选择
先将请求放到消息队列当中,后端服务就尽自己最大的能力去消息队列中消费请求,对于超时的请求,可以直接返回错误。这样可以防止在高峰期大量的请求直接导致后端服务器崩溃
总结:
- 消息队列通常指的是消息队列中间件,它负责存放消息,便于应用之间的消息通信(可以理解为情报中转站)
- 消息队列三大应用场景:异步、削峰、解耦
消息队列
看看维基百科是怎么描述的
In computer science, message queues and mailboxes are software-engineering components typically used for inter-process communication (IPC), or for inter-thread communication within the same process. They use a queue for messaging – the passing of control or of content. Group communication systems provide similar kinds of functionality.
消息是指两个应用间传递的数据,数据的类型有很多种,可能只是文本、也有可能是对象
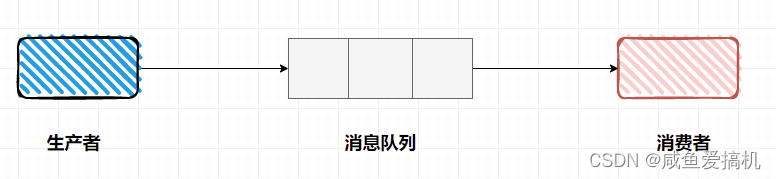
消息队列指的是在消息传输的过程中用来保存消息的容器(组件)
消息队列中,有下面两个角色:
- 生产者(producer):负责生产数据并传输到消息队列,至于谁去取消息,生产者并不关心
- 消费者(consumer):负责从消息队列中取出数据,至于数据是谁生产的,消费者并不关心
市面上主流的消息队列中间件
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级;比RaabitMQ、Kafka低一个数量级 | 同ActiveMQ | 十万级;支持高吞吐 | 十万级、高吞吐;一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 | \ | \ | topic可以达到几百/几千级别,吞吐量会有较小幅度的下降 | topic从几十到几百的时候,吞吐量会大幅度下降;同等机器下尽量保证topic 数量不要过多 |
| 时效性 | 毫秒级 | 微秒级、延迟最低 RabbitMQ特性 | 毫秒级 | 毫秒级以内 |
| 可用性 | 高,基于主从架构 | 高,基于主从架构 | 非常高 分布式架构 | 非常高、分布式、一个数据多个副本 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 可以通过参数优化做到零丢失 | 基本不丢 |
| 功能支持 | 功能完备 | 性能好,延时低 | 功能完善 | 功能简单 |
| 社区活跃度 | 低 | 中 | 高 | 高 |
1.两种模型
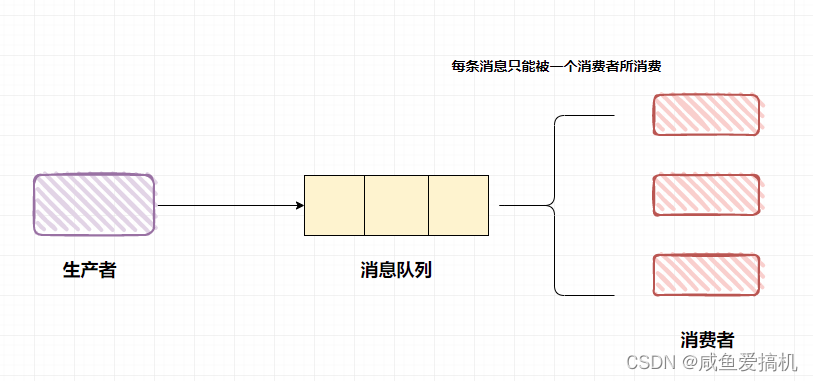
- 队列模型
生产者往某个队列里发送消息,一个队列可以存储多个生产者的消息,一个队列也可以有多个消费者
但是消费者之间是竞争关系,即每条消息只能被一个消费者消费
- 发布/订阅模型
在队列模型中,每条消息只能被一个消费者所消费,为了解决这一问题,让一条消息能被多个消费者消费,发布/订阅模型诞生了
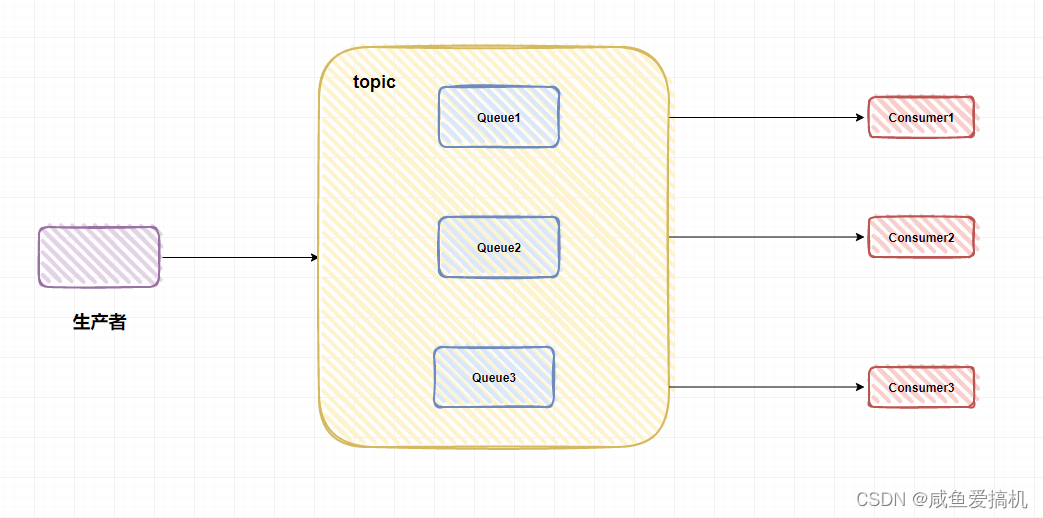
在发布/订阅模型当中,会将消息发送到一个 topic(主题)中,所有订阅了这个 topic 的消费者都能消费到这条消息
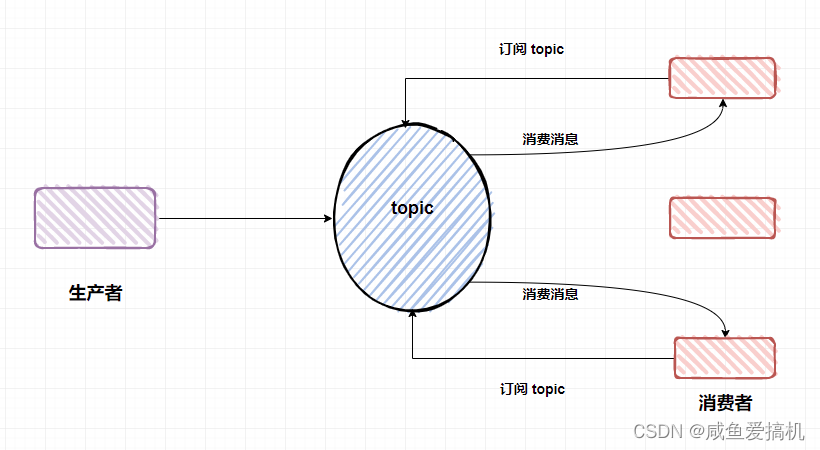
就好比队列模型就是你在微信上跟别人私聊,你发送的消息只能被你私聊的那个人收到;发布/订阅模型就相当于你创建了一个群聊,把大家都拉进群里,只要是在群里的(订阅了 topic)都能收到你发的消息
那有的人就会想,我对好多人私聊,并且发的都是相同的信息,不是也能够实现一条消息被多个消费者消费的功能吗
很聪明!在队列模型里,可以使用多队列来全量存储相同的消息,然后不同的消费者去不同的队列里消费
通过数据的冗余实现一条消息被多个消费者消费的功能
RabbitMQ 中通过 exchange 模块将消息发送到多个队列,解决一条消息能被多个消费者消费的问题
总结:
- 队列模型中,一条消息只能被一个消费者消费;发布/订阅模型中,一条消息可以被多个消费者消费
- 队列模型中,可以通过数据冗余(一条消息存储到多个队列当中)来实现一条消息可以被多个消费者消费(RabbitMQ就是采用这种模式)
- RabbitMQ 采用队列模型、RocketMQ 和 Kafka 采用发布/订阅模型
2.基本原理
生产者:Producer
消费者:Consumer
消息队列服务端:Broker
消息由 Producer 发往 Broker,Broker 将消息存储至本地,然后 Consumer 从 Broker拉取消息,或者由 Broker 推送消息给 Consumer,最后实现消费
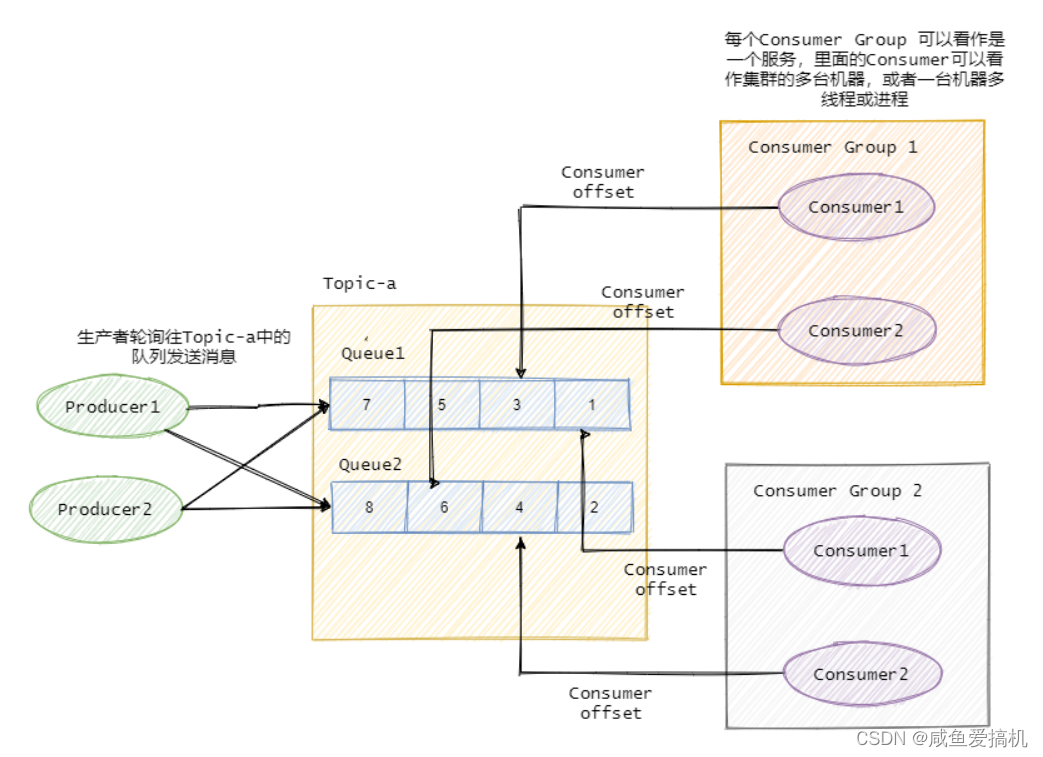
在发布/订阅模型中,为了提高并发,还会引入队列或者分区的概念——将消息发往一个 topic 中的某个队列或者某个分区(队列和分区本质一样,叫法不一样)
例如某个 topic 下有 n 个队列,那么这个主题的并发度就提高 n,同时可以支持 n 个消费者并行消费该 topic 中的消息
通常采用轮询 或者 key hash 取余等策略来将同一个 topic 的消息分配到不同的队列当中
既然是一对多的关系,那么消费者一般都有组的概念(Consumer group),即一条消息会发送到订阅了这个 topic 的消费组
例如现在有 Group1 和 Group 2 两个消费组,都订阅了 topic1 ,如果有一条消息发送到 topic1,那么这两个消费组都能接收到这条消息;消息其实是存储到了 topic1 中的某个队列当中,消费组的某个消费者对应消费一个队列的消息
实际上,一条消息在 Broker 中只会有一份,每个 Consumer group 会有自己的 offset (偏移量)来标识消费到的位置
在 offset 前的消息表示已经消费过了,每个 Consumer group 都会维订阅的 topic 下的每个队列的 offset
3.常见问题
如何保证消息不丢失
我们知道,从生产者生产消息到消费者消费消息,会经历三个阶段——生产消息、存储消息、消费消息。为了让消息不丢失,我们需要从这三个阶段进行考虑
- 生产消息
producer 发送消息到 broker ,需要处理 broker 的响应,无论是同步还是异步发送消息,都需要处理好 broker 的响应
如果 broker 返回写入失败等错误消息,需重新发送,当多次发送失败后需要进行故障处理
- 存储消息
在这个阶段,broker 需要在消息刷盘之后再给 producer 响应
假设消息写到缓存中就给 producer 响应,这个时候 broker 突然断电或者故障,就会导致消息丢失,而 producer 接收到 broker 的响应就会认为该消息已经发送成功了
如果 broker 是分布式架构的话,有副本机制(即消息不仅要写入当前 broker,还要写入副本机)那就应该设置成至少写入两台 broker 后再给 producer 响应
这样基本上就能保证存储的可靠性了
- 消费消息
Consumer 应该在执行完过程之后再给 broker 返回响应,而不是在拿到消息并放到内存后就立马给 broker 返回响应,这才是真正的消费了
万一这个时候 Consumer 出现故障或者断电,这条消息其实是没有走完整个业务流程的,而 broker 以为 Consumer 已经拿到数据并处理了
如何处理重复消息
先来看看为什么会有消息重复
假设 producer 发送消息不管 broker 的响应,只管生产,这样的情况下是不会出现消息重复的
但这样会导致另一个问题——消息不可靠
所以我们规定消息至少得发到 broker 上,并等待 broker 的响应,那么就有可能出现这个问题——消息已经发送到 broker 上并且 broker 返回响应给 producer ,但是由于网络问题这个响应并没有被 producer 收到,然后 producer 由重发了一次,这时候消息就会重复了
又假设 consumer 已经拿到消息了,并且走完业务流程此时需要更新 offset ,好巧不巧的是这个 consumer 挂掉了,另一个 consumer 来顶上,但这个 consumer 是没有消费的,于是会拿到刚刚那条消息重新走一遍业务,于是消息又重复了
由此可见——为了保证消息的可靠性,消息重复是无法避免的
那么如何处理重复消息呢?
幂等处理重复消息,幂等指的是任意多次执行所产生的影响均与一次执行的影响相同
通俗来讲,就是说通过幂等的方法来处理重复消息,无论你用同样的参数调用这个接口调用多少次的结果都是一个
比如说:
- 通过数据库的约束(唯一键)
- 记录关键的 key,对于一些关键的 key,给它一个唯一 ID
如何保证消息的有序性
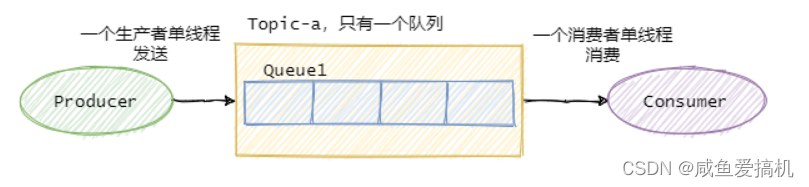
- 全局有序
如果要保证消息的全局有序,首先只能有 producer 往 topic 发送消息,并且一个 topic 内部只能有一个队列(分区)
consumer 也必须是单线程消费这个队列
- 部分有序
为了实现部分有序,我们将 topic 内部划分出多个队列,然后通过特定策略将消息发往固定队列当中
每个队列对应一个单线程处理的 consumer ,这样既能够实现部分有序,又能够提高并发
如何处理消息堆积
往往 consumer 的消费速度跟 producer 的生产速度不一致(consumer消费能力弱 or consumer 消费失败导致反复重试)就会导致消息堆积的问题
一方面,对 consumer 进行优化。先定位消费慢的原因,是因为 consumer 的业务出现 bug 还是说本身消费能力就不太行,例如消费逻辑是一条一条处理或者说是单线程处理,那我们就可以在这方面进行优化
或者增加 consumer 的数量,水平扩容来实现暴力解决问题
另一方面,对 broker 进行优化。增加 topic 的队列(分区)数
PS:队列数增加后要相应地增加 consumer 的数量,不然生产的数据没人来消费
使用消息队列后会带来什么问题
凡是都有两面性,虽然消息队列可以帮助我们很好地提高系统性能,降低耦合度,但是依旧会带来一些不可避免的问题
- 可用性降低
在没有使用消息队列中间件之前,你不需要考虑消息丢失或者消息队列中间件出现故障宕机这些情况,使用了之后你就要去考虑如何保证消息队列中间件的高可用
- 复杂性提高
使用了消息队列中间件之后,需要考虑消息有没有被重复消费、消息是不是有序传递,如何处理消息丢失的情况等等问题