目录
一、实验目的和要求
二、实验内容
三、实验环境
四、实验步骤
1、语法分析所依据的文法;
2、给出消除左递归及提取左公因子的LL(1)文法;
3、预测分析表
4、关键代码
五、实验结果与分析
一、实验目的和要求
- 理解自顶向下语法分析方法;
- 用预测分析技术实现语法分析器;
- 熟练掌握预测分析程序的构造方法。
二、实验内容
算术表达式的文法是G[E]:
E→E+T| E-T | T
T→T*F| T/F | F
F→(E)| i
用预测分析法按文法G[E]对算术表达式(包括+、-、*、/、(、)的算术表达式)进行语法分析,判断该表达式是否正确。
三、实验环境
处理器 AMD Ryzen 7 5800H with Radeon Graphics3.20 GHz
机带RAM 16.0 GB(13.9 GB可用)
Win10家庭版20H2 X64
PyCharm 2012.2
Python 3.10
四、实验步骤
1、阅读课本有关章节,将上述算术表达式的文法改造成LL(1)文法G’[E],即消除左递归和提取左公因子;
2、设计出文法G’[E]的预测分析表;
3、按算法4.5(P132)编写预测分析程序。(思考:预测分析程序包括四种动作——推导、匹配、接受、出错,详见P131,这些动作如何实现?)
1、语法分析所依据的文法;
算术表达式的文法是G[E]:
E→E+T| E-T | T
T→T*F| T/F | F
F→(E)| i
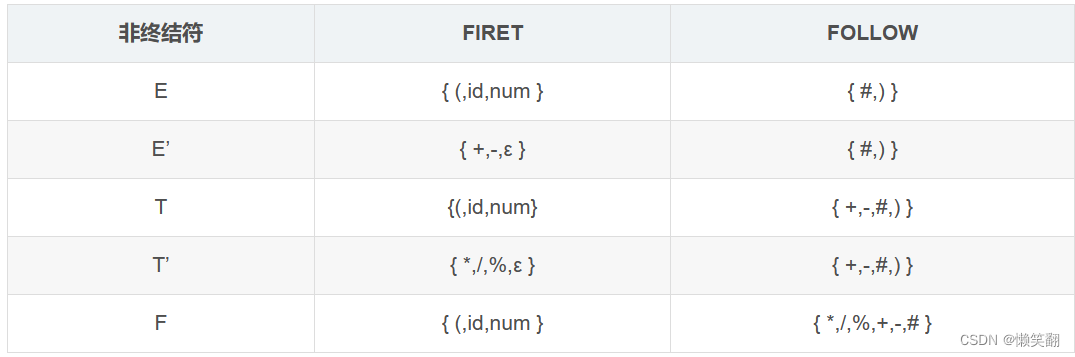
2、给出消除左递归及提取左公因子的LL(1)文法;
将文法G[E]改造为LL(1)文法如下:
G’[E]:
E → TE’
E’ → +TE’| -TE’|ε
T → FT’
T’→ *FT’|/FT’|ε
F → (E)| i
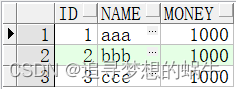
3、预测分析表
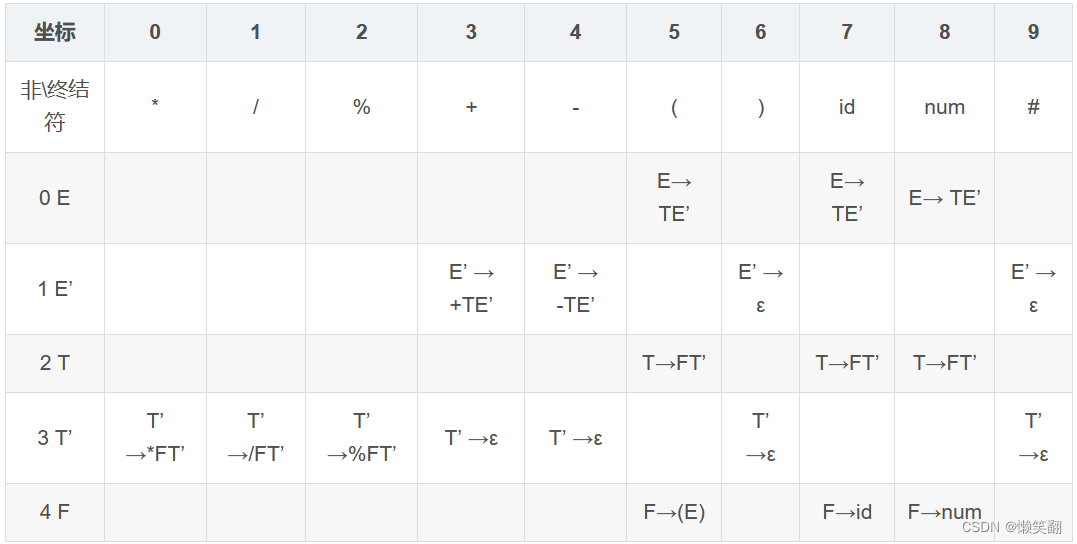
4、关键代码
<简要说明程序中所用到的主要变量、数组的作用,主要函数或过程的功能;给出主要功能实现的关键代码,如推导或匹配动作的实现,并加上适当的注释>
<!--BianYiYuanLiShiYan/yufafenxi_LL1.py-->
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/11 9:58
# @Author : LanXiaoFang
# @Site :
# @File : yufafenxi_LL1.py
# @Software: PyCharm
import cifafenxi_LL1
class Stack(): # 定义类
def __init__(self): # 产生一个空的容器
self.__list = []
def push(self, item): # 入栈
self.__list.append(item)
def pop(self): # 出栈
return self.__list.pop()
def speek(self): # 返回栈顶元素
return self.__list[-1]
def is_empty(self): # 判断是否已为空
return not self.__list
def size(self): # 返回栈中元素个数
return len(self.__list)
# 用来存储从txt文件中读取的字符串
aa = " "
# 用来标记字符
pp = 0
# 非终结符表
VN = ["E", "e", "T", "t", "F"]
# 终结符表 l->/ m->% i->id n->num
VT = ['*', 'l', 'm', '+', '-', '(', ')', 'i', 'num', '#']
Fa = ["Te", "+Te", "-Te", "", "Ft", "*Ft", "nFt", "mFt", "", "(E)", "i", "num"]
F = ["E->", "E'->", "E'->", "E'->", "T->", "T'->", "T'->", "T'->", "T'->", "F->", "F->", "F->"]
# 构造预测分析表,-1表示出错,-2表示该行终结符的follow集合,用于错误处理
analysis_table = [
[-2, -2, -2, -2, -2, 0, -1, 0, 0, -1],
[-2, -2, -2, 1, 2, -2, 3, -2, -2, 3],
[-2, -2, -2, -1, -1, 4, -1, 4, 4, -1],
[5, 6, 7, 8, 8, -2, 8, -2, -2, 8],
[-2, -2, -1, -1, -1, 9, -1, 10, 11, -2]
]
# 定义栈
stack = Stack()
# 判断字符x是否是终结符
def includevt(x):
if x in VT:
return 1
else:
return 0
# 查找非终结符,终结符 在预测分析表中的坐标,返回坐标对应信息
def includean(x, a):
# 非终结符
for i in range(len(VN)):
if VN[i] == x:
break
# 终结符
for j in range(len(VT)):
if VT[j] == a:
break
return analysis_table[i][j]
# 错误处理
def destory():
flag = 0
flagg = 0
# 将 "#"和文法开始符依次压入栈中
stack.push('#')
# 将第一个非终结符入栈
stack.push(VN[0])
# 把第一个输入符号读入a, aa
global pp
a = aa[pp]
x = ""
while x != '#':
# print(stack.__dict__.values())
if flag == 0:
# 把栈顶符号弹出并放入
x = stack.pop()
flag = 0
# 如果a是终结符
if includevt(a) == 1:
if includevt(x) == 1:
if a == x:
if a == '#':
flagg = 1
print(x, "\t\t", a, "\t\t", " 结束")
return 1
else:
print(x, "\t\t", a, "\t\t", " 匹配终结符", x)
pp = pp + 1
# 将下一输入符号读入a
a = aa[pp]
else:
flag = 1
print(x, "\t\t", a, "\t\t", " 出错 ,跳过", a)
pp = pp + 1
a = aa[pp]
elif includean(x, a) >= 0:
h = includean(x, a)
print(x, "\t\t", a, "\t\t", " 展开非终结符 ", F[h], Fa[h])
if Fa[h] in aa:
stack.push(Fa[h])
else:
aF = Fa[h][::-1]
for i in range(len(aF)):
stack.push(aF[i])
elif includean(x, a) == -1:
flag = 1
print(x, "\t\t", a, "\t\t", " 出错 ,从栈顶弹出", x)
x = stack.pop()
else:
flag = 1
print(x, "\t\t", a, "\t\t", " 出错 ,跳过", a)
pp = pp + 1
a = aa[pp]
else:
flag = 1
print(x, "\t\t", a, "\t\t", " 出错 ,跳过", a)
pp = pp + 1
a = aa[pp]
if flagg == 0:
print(x, "\t\t", a, "\t\t", " 结束 \n")
aa = cifafenxi_LL1.main()
print("语法分析工程如下 :")
print('-' * 20, '文法如下', '-' * 20)
print("E->TE'")
print("E'->+TE'|-TE'|~")
print("T->FT'")
print("T'->*FT'|/FT'|%FT'|~")
print("F->(E)|id|num")
print("要分析的语句是 :", aa)
print("语法分析工程如下 :")
print("栈顶元素 \t\t 当前单词记号 \t\t 动作 ")
print("-" * 50)
destory()<!--BianYiYuanLiShiYan/cifafenxi_LL1.py-->
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/11 9:57
# @Author : LanXiaoFang
# @Site :
# @File : cifafenxi_LL1.py
# @Software: PyCharm
import re
class Token(object):
# 初始化
def __init__(this):
# 存储分词的列表
this.results = []
# 行号
this.lineno = 1
# 关键字
this.keywords = ['auto', 'struct', 'if', 'else', 'for', 'do', 'while', 'const',
'int', 'double', 'float', 'long', 'char', 'short', 'unsigned',
'switch', 'break', 'defalut', 'continue', 'return', 'void', 'static',
'auto', 'enum', 'register', 'typeof', 'volatile', 'union', 'extern']
'''
regex中:*表示从0-, +表示1-, ?表示0-1。对应的需要转义
{ 表示限定符表达式开始的地方 \{
() 标记一个子表达式的开始和结束位置。子表达式可以获取共以后使用:\( \)
r表示原生字符串。
'''
Keyword = r'(?P<Keyword>(auto){1}|(double){1}|(int){1}|(if){1}|' \
r'(#include){1}|(return){1}|(char){1}|(stdio\.h){1}|(const){1})'
# 运算符
Operator = r'(?P<Operator>\+\+|\+=|\+|--|-=|-|\*|#|\*=|/=|/|%=|%)'
# 分隔符/界符
Separator = r'(?P<Separator>[,:\{}:)(<>])'
# 数字: 例如:1 1.9
Number = r'(?P<Number>\d+[.]?\d+)'
# 变量名 不能使用关键字命名
ID = r'(?P<ID>[a-zA-Z_][a-zA-Z_0-9]*)'
# 方法名 {1} 重复n次
Method = r'(?P<Method>(main){1}|(printf){1})'
# 错误 \S 匹配任意不是空白符的字符
# Error = r'(?P<Error>.*\S+)'
Error = r'\"(?P<Error>.*)\"'
# 注释 ^匹配行的开始 .匹配换行符以外的任意字符 \r回车符 \n换行符
Annotation = r'(?P<Annotation>/\*(.|[\r\n])*/|//[^\n]*)'
# 进行组装,将上述正则表达式以逻辑的方式进行拼接, 按照一定的逻辑顺序
# compile函数用于编译正则表达式,生成一个正则表达式对象
this.patterns = re.compile('|'.join([Annotation, Keyword, Method, ID, Number, Separator, Operator, Error]))
# 读文件
def read_file(this, filename):
with open(filename, "r", encoding="UTF-8") as f_input:
return [line.strip() for line in f_input]
# 结果写入文件
def write_file(this, lines, filename='results.txt'):
with open(filename, "a") as f_output:
for line in lines:
if line:
f_output.write(line)
else:
continue
def get_token(this, line):
# finditer : 在字符串中找到正则表达式所匹配的所有字串, 并把他们作为一个迭代器返回
for match in re.finditer(this.patterns, line):
# group():匹配的整个表达式的字符 # yield 关键字:类似return ,返回的是一个生成器,generator
yield (match.lastgroup, match.group())
def run(this, line, flag=True):
tokens = []
for token in this.get_token(line):
if flag:
tokens.append(token)
print("line %3d :" % this.lineno, token)
'''
else:
yield "line %3d :" % this.lineno + str(token) + "\n"
'''
return tokens
def printrun(this, line, flag=True):
for token in this.get_token(line):
if flag:
print("lines x: ", token)
def main():
token = Token()
filepath = input("请输入文件路径:")
print('-' * 20, '词法分析', '-' * 20)
lines = token.read_file(filepath)
tokenss = []
for line in lines:
tokens = token.run(line, True)
for i in tokens:
tokenss.append(i[1])
return tokenss五、实验结果与分析