文章目录
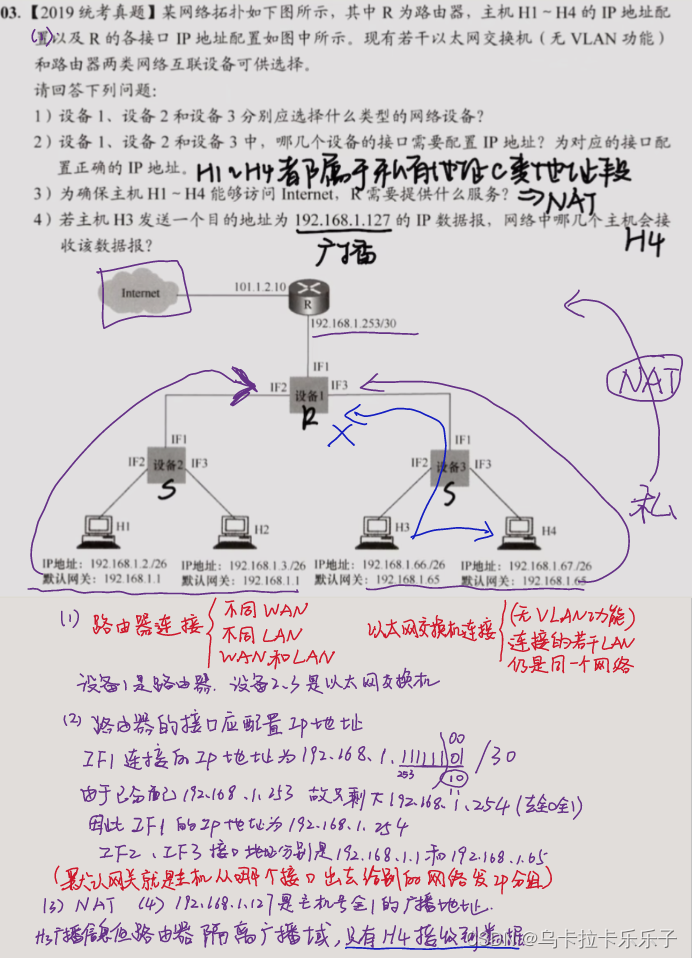
- 8.1 Attention结构
- 8.1.1 seq2seq存在的问题
- 8.1.2 编码器的改进
- 8.1.3 解码器的改进
- 8.2 Attention的应用
- 8.3 总结
之前文章链接:
开篇介绍:《深度学习进阶 自然语言处理》书籍介绍
第一章:《深度学习进阶 自然语言处理》第一章:神经网络的复习
第二章:《深度学习进阶 自然语言处理》第二章:自然语言和单词的分布式表示
第三章:《深度学习进阶 自然语言处理》第三章:word2vec
第四章:《深度学习进阶 自然语言处理》第四章:Embedding层和负采样介绍
第五章:《深度学习进阶 自然语言处理》第五章:RNN通俗介绍
第六章:《深度学习进阶 自然语言处理》第六章:LSTM介绍
第七章:《深度学习进阶 自然语言处理》第七章:seq2seq介绍
写在开头,本章中提到的Attention概念和我们现在常谈的Attention有些差别,此处Attention概念更加广泛。
我们现在常提的Attention,大多数人会想到《Attention Is All You Need》中提出的transformer中的内容;
本书出版于2018年7月,当时《Attention Is All You Need》已经发表,但是火遍整个NLP行业的BERT模型还没有被Google提出(2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩),BERT问世后,《Attention Is All You Need》这篇文章才受到更多人的关注。
本章内容梳理,主要是整理当时基于RNN等时序模型的Attention相关内容。
8.1 Attention结构
在上一章讲到, seq2seq是一个非常强大的框架,应用面很广。本章我们将介绍进一步强化seq2seq的注意力机制(Afttention mechanism,简称Attention )。基于Attention 机制, seq2seq可以像我们人类一样,将“注意力”集中在必要的信息上。此外,使用Attention可以解决当前seq2seq面临的问题。
8.1.1 seq2seq存在的问题
seq2seq中使用编码器对时序数据进行编码,然后将编码信息传递给解码器。此时,编码器的输出是固定长度的向量。实际上,这个“固定长度”存在很大问题。因为固定长度的向量意味着,无论输入语句的长度如何(无论多长),都会被转换为长度相同的向量。这种情况会导致有用的信息从向量中溢出。
接下来依次通过改进编码器、解码器来避免这种情况的发生。
8.1.2 编码器的改进
到目前为止,我们都只将LSTM层的最后的隐藏状态传递给解码器,但是编码器的输出的长度应该根据输入文本的长度相应地改变。这是编码器的一个可以改进的地方。具体而言,如下图所示,使用各个时刻(各个单词)的LSTM层的隐藏状态。通过这种方式可以获得和输入的单词数相同数量的向量。在下图的例子中,输入了5个单词,此时编码器输出5个向量。这样一来,编码器就摆脱了“一个固定长度的向量”的制约。
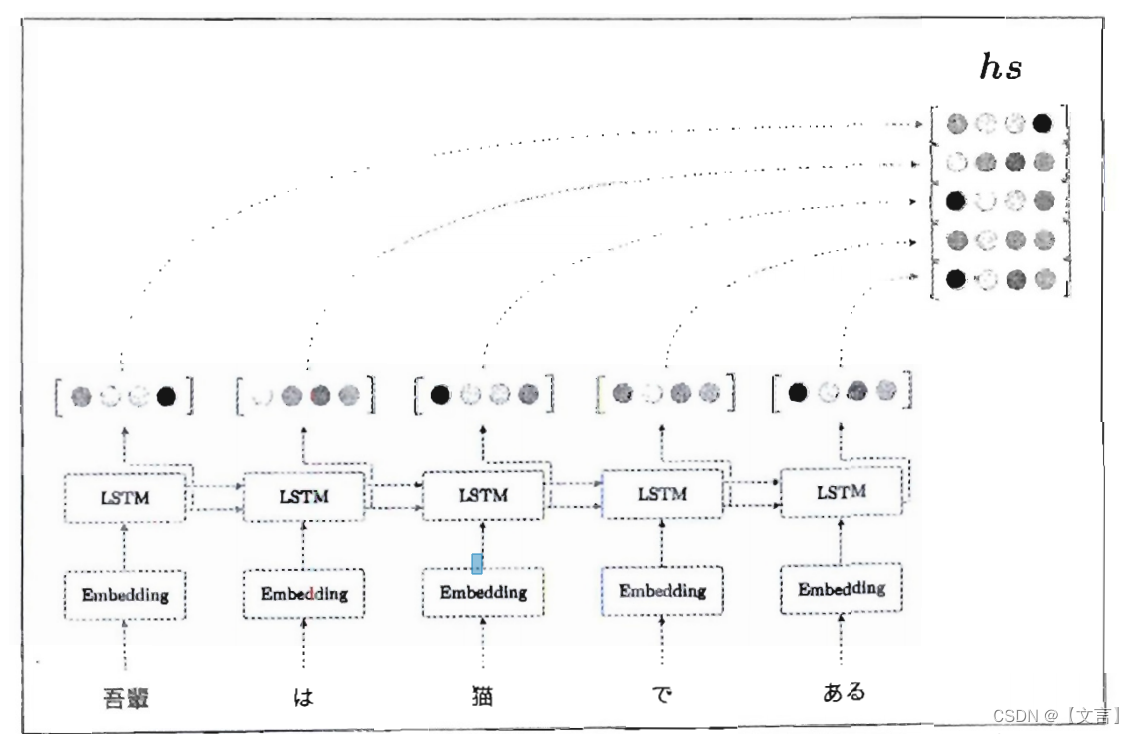
以上是对编码器的改进。这里我们所做的改进只是将编码器的全部时刻的隐藏状态取出来而已。通过这个小改动,编码器可以根据输入语句的长度,成比例地编码信息。那么,解码器又将如何处理这个编码器的输出呢?
8.1.3 解码器的改进
解码器的改进,主要是把编码器的输出hs输入到各个时刻的Attention层。另外,这里将LSTM层的隐藏状态向量输入Affine层。具体内容如下图:
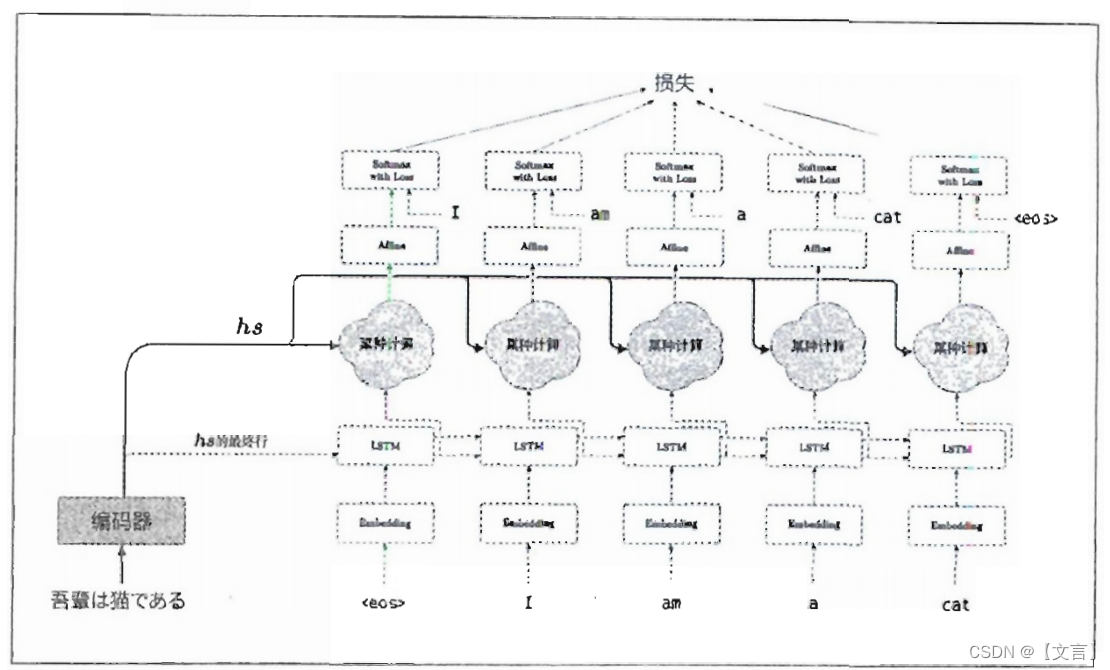
以上内容概述了关于编码器和解码器部分的改进,其代码实现见书本P344,在此不做详述。
8.2 Attention的应用
我们在前面介绍了如何将Attention应用在seq2seq上,但是Attention这一想法本身是通用的,在应用上还有更多的可能性。接下来我们介绍一下如何在transformer中使用Attention机制(书中讲到关于GNMT、NTM在此不做介绍,感兴趣读者可以翻阅原书)。
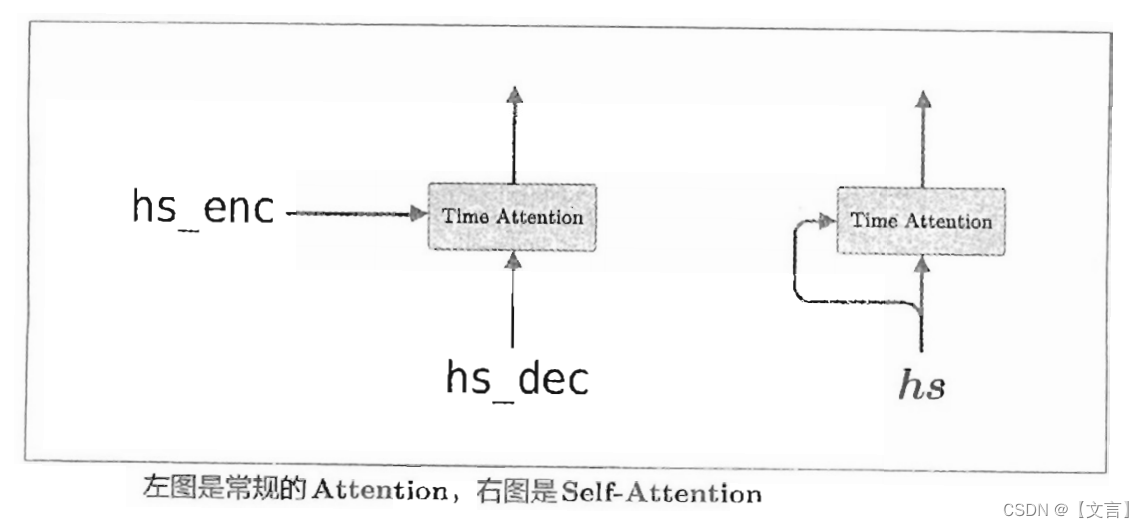
Transformer是基于Attention构成的,其中使用了Self-Attention技巧,这一点很重要。Self-Attention直译为“自己对自己的Attention",也就是说,这是以一个时序数据为对象的Attention,旨在观察一个时序数据中每个元素与其他元素的关系,Self-Attention如下图所示。
整个tansformer结构如下图:
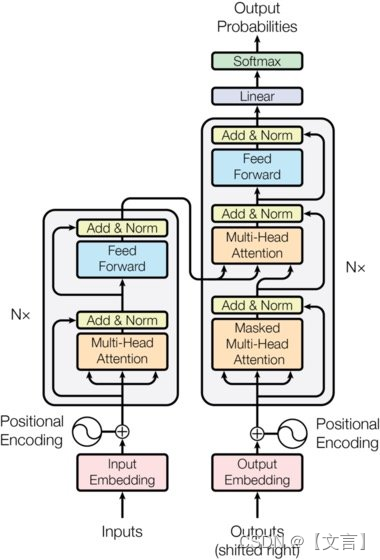
Transformer中用Attention代替了RNN。实际上,由上图可知,编码器和解码器两者都使用了Self-Attention。Feed Forward层表示前馈神经网络(在时间方向上独立的网络)。具体而言,使用具有一个隐藏层、激活函数为ReLU的全连接的神经网络。另外,图中的Nx表示灰色背景包围的元素被堆叠了N次。
关于transformer详细介绍,参考之前整理资料:
-
01-transformer简介
-
02-transformer架构
8.3 总结
本章简单介绍了Attention实现的机制,然后以transformer为例,介绍了Attention在模型中的应用。









![[ Linux ] 如何查看Linux系统版本](https://img-blog.csdnimg.cn/d06b21579bc848d1b791227527bba7e4.png)