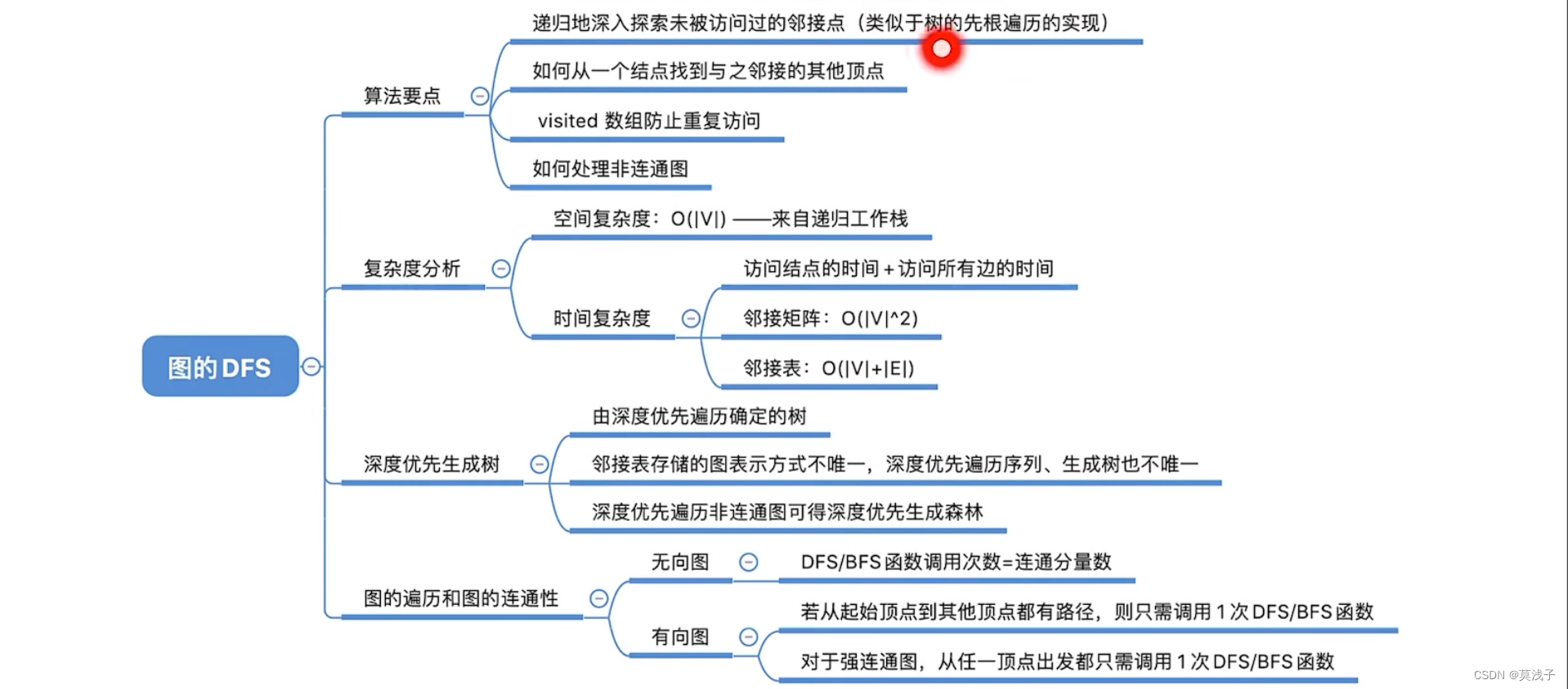
这篇博客将介绍如何使用PyTorch深度学习库训练第一个卷积神经网络(CNN)。训练CNN使用 KMNIST 数据集(MNIST digits数据集的替代品,内置在PyTorch中)识别手写平假名字符(handwritten Hiragana characters)。
在图像数据集上训练CNN与在数字数据上训练基本的多层感知器(MLP)并没有什么不同。将包括:
- 定义模型架构
- 从磁盘加载数据集
- 熟练使用PyTorch的数据加载器DataLoader
- 循环纪元和数据批次
- 预测并计算损失
- 将梯度适当归零,执行反向传播,并更新模型参数
- 将训练完成的PyTorch模型保存到磁盘
- 在单独的Python脚本中从磁盘加载模型
- 使用PyTorch模型对图像进行预测
谈到从磁盘加载保存的PyTorch模型,下篇博客将介绍如何使用预先训练的PyTorch模型来识别日常生活中经常遇到的1000个图像类。这些模型可以节省大量时间和麻烦-它们非常精确,不需要手动训练它们。
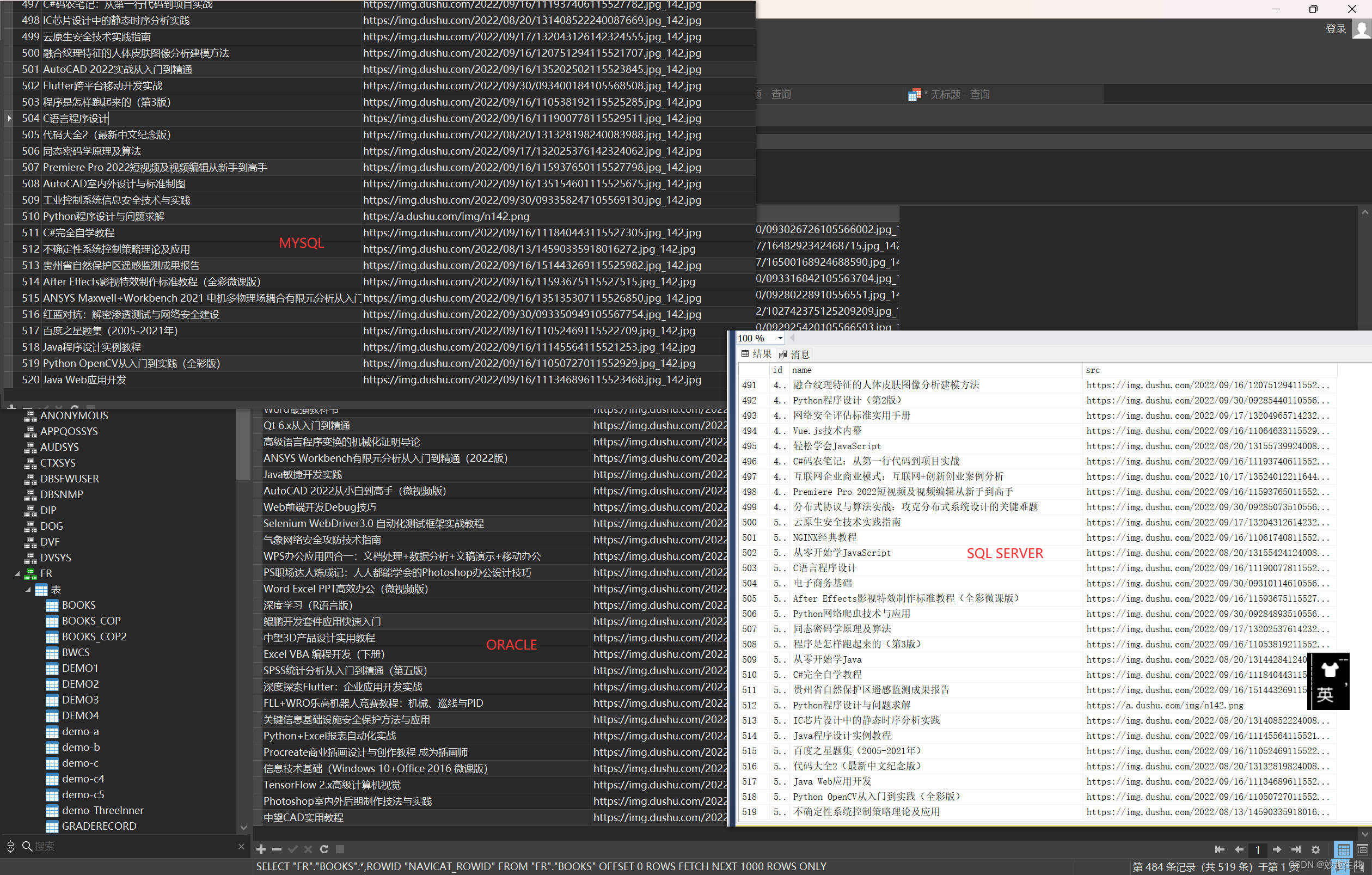
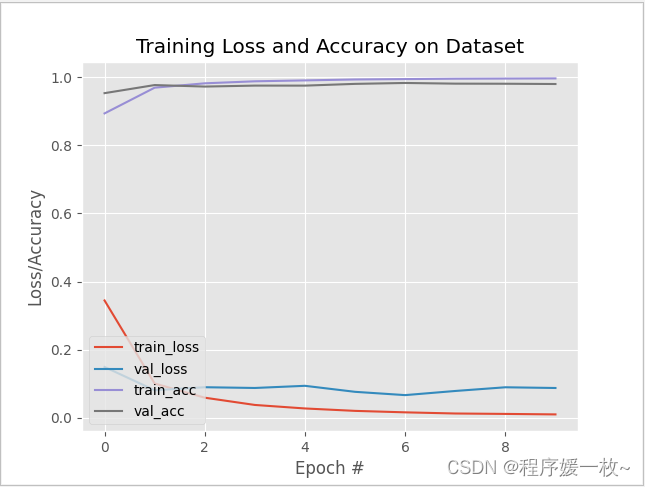
1. 效果图
训练CNN≈我的CPU上有271秒。使用GPU的培训时间减少到≈130秒。
在最后一个阶段结束时,获得了99.68%的训练精度和98.03%的验证精度。
当在测试集上进行评估时,达到了≈94%的准确率。考虑到平假名字符的复杂性和浅层网络架构的简单性,这是非常好的(使用更深层次的网络,如VGG启发的模型或类似ResNet的模型,可以获得更高的准确率,但这些模型更复杂)。
[INFO] loading the KMNIST dataset...
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/train-images-idx3-ubyte.gz
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/train-images-idx3-ubyte.gz to data\KMNIST\raw\train-images-idx3-ubyte.gz
18165760it [00:40, 443555.23it/s]
Extracting data\KMNIST\raw\train-images-idx3-ubyte.gz to data\KMNIST\raw
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/train-labels-idx1-ubyte.gz
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/train-labels-idx1-ubyte.gz to data\KMNIST\raw\train-labels-idx1-ubyte.gz
29696it [00:00, 298773.88it/s]
Extracting data\KMNIST\raw\train-labels-idx1-ubyte.gz to data\KMNIST\raw
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/t10k-images-idx3-ubyte.gz
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/t10k-images-idx3-ubyte.gz to data\KMNIST\raw\t10k-images-idx3-ubyte.gz
3041280it [00:13, 222871.32it/s]
Extracting data\KMNIST\raw\t10k-images-idx3-ubyte.gz to data\KMNIST\raw
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/t10k-labels-idx1-ubyte.gz
Downloading http://codh.rois.ac.jp/kmnist/dataset/kmnist/t10k-labels-idx1-ubyte.gz to data\KMNIST\raw\t10k-labels-idx1-ubyte.gz
100%|██████████| 5120/5120 [00:00<?, ?it/s]
Extracting data\KMNIST\raw\t10k-labels-idx1-ubyte.gz to data\KMNIST\raw
[INFO] generating the train/validation split...
[INFO] initializing the LeNet model...
[INFO] training the network...
[INFO] EPOCH: 1/10
Train loss: 0.344304, Train accuracy: 0.8940
Val loss: 0.148819, Val accuracy: 0.9535
[INFO] EPOCH: 2/10
Train loss: 0.100273, Train accuracy: 0.9696
Val loss: 0.080464, Val accuracy: 0.9773
[INFO] EPOCH: 3/10
Train loss: 0.058563, Train accuracy: 0.9824
Val loss: 0.089331, Val accuracy: 0.9728
[INFO] EPOCH: 4/10
Train loss: 0.037242, Train accuracy: 0.9883
Val loss: 0.087128, Val accuracy: 0.9757
[INFO] EPOCH: 5/10
Train loss: 0.026911, Train accuracy: 0.9910
Val loss: 0.093474, Val accuracy: 0.9756
[INFO] EPOCH: 6/10
Train loss: 0.019837, Train accuracy: 0.9937
Val loss: 0.075803, Val accuracy: 0.9807
[INFO] EPOCH: 7/10
Train loss: 0.015524, Train accuracy: 0.9948
Val loss: 0.066136, Val accuracy: 0.9834
[INFO] EPOCH: 8/10
Train loss: 0.012120, Train accuracy: 0.9959
Val loss: 0.078302, Val accuracy: 0.9814
[INFO] EPOCH: 9/10
Train loss: 0.010891, Train accuracy: 0.9964
Val loss: 0.089176, Val accuracy: 0.9811
[INFO] EPOCH: 10/10
Train loss: 0.009471, Train accuracy: 0.9968
Val loss: 0.087064, Val accuracy: 0.9803
[INFO] total time taken to train the model: 271.64s
[INFO] evaluating network...
precision recall f1-score support
o 0.93 0.97 0.95 1000
ki 0.97 0.92 0.94 1000
su 0.90 0.91 0.90 1000
tsu 0.96 0.96 0.96 1000
na 0.97 0.91 0.94 1000
ha 0.97 0.92 0.94 1000
ma 0.87 0.98 0.92 1000
ya 0.98 0.94 0.96 1000
re 0.97 0.96 0.97 1000
wo 0.96 0.96 0.96 1000
accuracy 0.94 10000
macro avg 0.95 0.94 0.94 10000
weighted avg 0.95 0.94 0.94 10000
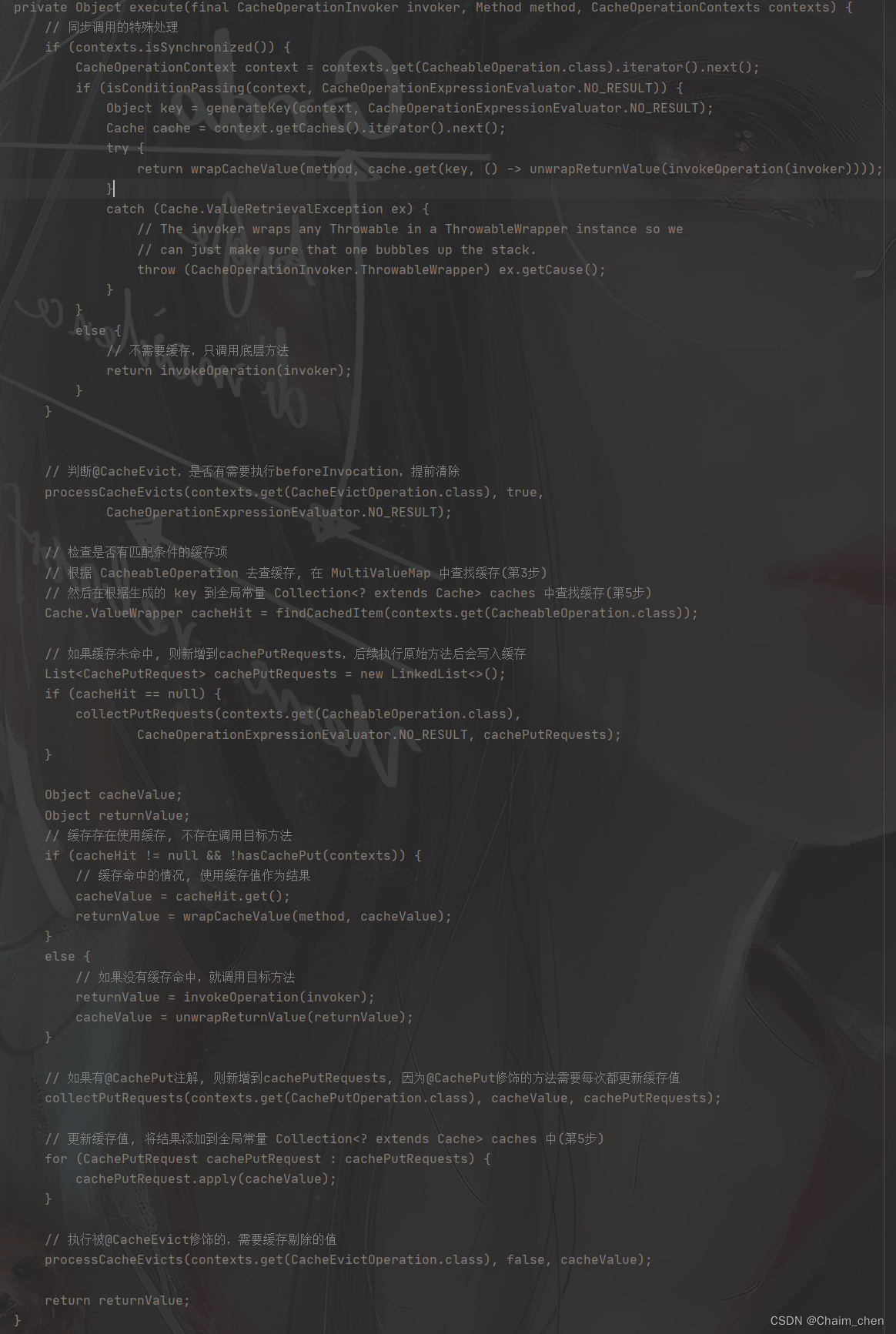
如下图所示,训练损失/准确度的历史图是平滑的,表明几乎没有发生过拟合。
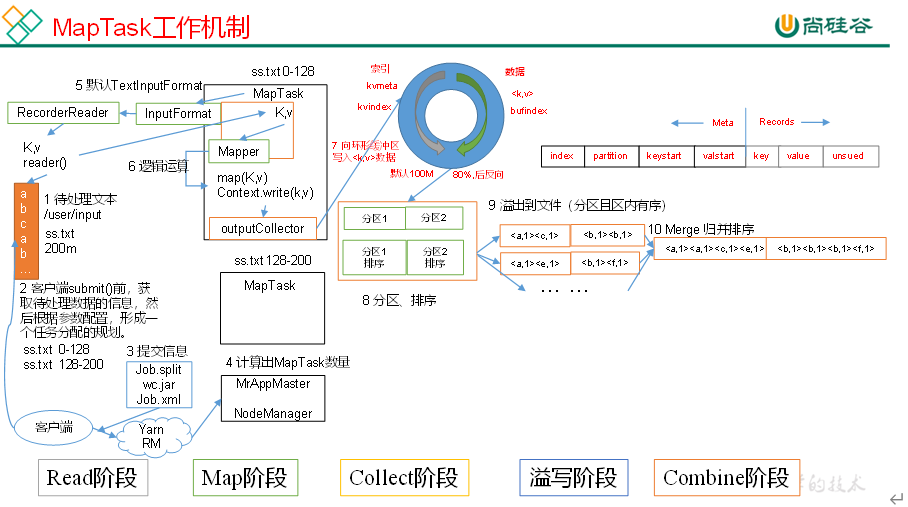
在测试集上随机选取10个样本,可以看到均能成功检测,效果图如下:、
识别正确蓝色,识别错误红色。

2. 环境配置
pip install torch torchvision
pip install opencv-contrib-python
pip install scikit-learn
3. KMNIST数据集
-
使用Kuzushiji MNIST数据集,简称KMNIST(MNIST digits数据集的替代品)。此数据集旨在替代标准MNIST数字识别数据集。
-
KMNIST数据集由70000张图像及其相应标签组成(60000张用于培训,10000张用于测试)。
-
KMNIST数据集中共有10个类(表示10个字符),每个类都是均匀分布和表示的。目标是训练一个能够准确分类这10个字符的CNN。
-
KMNIST数据集内置在PyTorch中。
4. 源码
lenet.py: 使用PyTorch实现了著名的LeNet CNN结构
train_lenet.py: 使用PyTorch在KMNIST数据集上训练LeNet CNN网络,并将训练过的模型序列化到磁盘
predict.py: 从磁盘加载模型,在测试集照片上预测结果,展示结果到屏幕
output/: 存放训练/验证损失/准确度图和模型;
4.1 lenet.py
# lenet.py
# 这里用PyTorch实现的卷积神经网络(CNN)是一种开创性的LeNet架构
# LeNet是一个非常浅层的神经网络,由以下几层组成:(CONV=>RELU=>POOL)*2=>FC=>RELU=>FC=>SOFTMAX
# 导入必要的包
from torch import flatten # 展平多维卷(例如CONV或POOL层)的输出,以便可以对其应用完全连接的层
from torch.nn import Conv2d # PyTorch实现卷积层
from torch.nn import Linear # 完全连接的层
from torch.nn import LogSoftmax # 用于构建softmax分类器以返回每个类的预测概率
from torch.nn import MaxPool2d # 应用MaxPool2d以减少输入层的空间维度
from torch.nn import Module # 与使用Sequential PyTorch类来实现LeNet不同,将对模块对象进行子类化,以便可以看到PyTorch如何使用类来实现神经网络
from torch.nn import ReLU # ReLU激活函数
class LeNet(Module):
# 模块的构造函数仅初始化层类型。PyTorch跟踪这些变量,但它不知道这些层是如何相互连接的。
# 为了让PyTorch了解您正在构建的网络架构,需要定义forward功能。
# 在forward函数中,获取构造函数中初始化的变量并连接它们。
# 借助autograd模块,PyTorch可以使用您的网络进行预测并执行自动反向传播
def __init__(self, numChannels, classes):
# 调用构造器
super(LeNet, self).__init__()
# 第一个CONV层共学习20个过滤器,每个过滤器为5×5。然后应用ReLU激活函数,然后是2×2最大池层和2×2步幅,以减少输入图像的空间维度。
# 初始化第一层:CONV => RELU => POOL layers
self.conv1 = Conv2d(in_channels=numChannels, out_channels=20,
kernel_size=(5, 5))
self.relu1 = ReLU()
self.maxpool1 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# 第二组CONV=>RELU=>POOL层。我们将CONV层中学习的过滤器数量增加到50个,但保持5×5的内核大小。再次应用ReLU激活,然后是最大池。
# 初始化第二层:CONV => RELU => POOL layers
self.conv2 = Conv2d(in_channels=20, out_channels=50,
kernel_size=(5, 5))
self.relu2 = ReLU()
self.maxpool2 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# 初始化第一组(也是唯一一组) FC => RELU layers
# 第一组也是唯一一组完全连接的层。定义层的输入数量(800)以及所需的输出节点数量(500)。在FC层之后进行ReLu激活。
self.fc1 = Linear(in_features=800, out_features=500)
self.relu3 = ReLU()
# 初始化 softmax 分类器
# 最后应用softmax分类器。features的数量设置为500,这是前一层的输出维度。
# 然后应用LogSoftmax,以便在评估期间获得预测概率。
self.fc2 = Linear(in_features=500, out_features=classes)
self.logSoftmax = LogSoftmax(dim=1)
# forward方法接受单个参数x,它是网络的一批输入数据。
# 然后,将conv1、relu1和maxpool1层连接在一起,形成网络的第一个CONV=>RELU=>POOL层。
# 构建了第二组CONV=>RELU=>POOL层。
# 此时,变量x是多维张量;然而,为了创建完全连接的层,需要将这个张量“展平”为基本上相当于1D值列表的张量。
# 将fc1和relu3层连接到网络架构,然后连接最终的fc2和logSoftmax。
#
# 重要的是要理解,__init__所做的只是初始化变量。PyTorch完全不知道网络架构是什么,只知道LeNet类定义中存在一些变量。
# 为了构建网络体系结构本身(即输入到其他层的是哪一层),需要重写模块类的forward方法。
# forward功能有:
# 将层/子网络从类的构造函数(即__init__)中定义的变量连接在一起
# 定义了网络体系结构本身
# 允许模型向前传递,从而产生输出预测
# 由于PyTorch的autograd模块,它允许执行自动微分并更新模型权重
def forward(self, x):
# 将input输入到第一层 CONV => RELU => POOL layers
x = self.conv1(x)
x = self.relu1(x)
x = self.maxpool1(x)
# 将上一层的输出传递到第二层 CONV => RELU => POOL layers
x = self.conv2(x)
x = self.relu2(x)
x = self.maxpool2(x)
# 展开上一层的输出,传递到唯一的完全连接层 FC => RELU layers
x = flatten(x, 1)
x = self.fc1(x)
x = self.relu3(x)
# 传递输出到sofmax分类器,以获取预测结果
x = self.fc2(x)
output = self.logSoftmax(x)
# 返回预测的输出结果
return output
4.2 train_lenet.py
# USAGE
# python train_lenet.py --model output/model.pth --plot output/plot.png
# 设置matplotlib backend以保存图片到磁盘
import matplotlib
matplotlib.use("Agg")
# 导入必要的包
from p220625.pyimagesearch.lenet import LeNet # LeNet CNN的PyTorch实现
from sklearn.metrics import classification_report # 用于在测试集上显示详细的分类报告
from torch.utils.data import random_split # 从输入数据集构造随机训练/测试集拆分
from torch.utils.data import DataLoader # 强大的数据加载器允许轻松构建数据管道来训练CNN
from torchvision.transforms import ToTensor # 预处理函数,可自动将输入数据转换为PyTorch张量
from torchvision.datasets import KMNIST # Kuzushiji MNIST数据集加载器内置在PyTorch库中
from torch.optim import Adam # 用来训练神经网络的优化器
from torch import nn # PyTorch的神经网络实现
import matplotlib.pyplot as plt
import numpy as np
import argparse
import torch
import time
# 构建命令行参数及解析
# --model 序列化模型的存放路径
# --plot 损失/准确度图存放路径
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=False, default='output/model.pth',
help="path to output trained model")
ap.add_argument("-p", "--plot", type=str, required=False, default='output/plot.png',
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
# 定义训练超参数(hyperparameters)初始学习率、批量大小和要训练的纪元数
INIT_LR = 1e-3
BATCH_SIZE = 64
EPOCHS = 10
# 定义训练和测试级拆分比率 75%训练集,25%测试集
TRAIN_SPLIT = 0.75
VAL_SPLIT = 1 - TRAIN_SPLIT
# 设置训练模型要使用的设备(CPU or GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用PyTorch的内置KMNIST类加载KMNIST数据集
# download=True标志表示,如果之前没有下载KMNIST数据集,PyTorch将自动下载并将其缓存到磁盘。
# 还要注意transform参数-这里可以应用许多数据转换。这里需要的唯一转换是将PyTorch加载的NumPy数组转换为张量数据类型。
print("[INFO] loading the KMNIST dataset...")
trainData = KMNIST(root="data", train=True, download=True,
transform=ToTensor())
testData = KMNIST(root="data", train=False, download=True,
transform=ToTensor())
# 计算训练/测试样本数
print("[INFO] generating the train/validation split...")
numTrainSamples = int(len(trainData) * TRAIN_SPLIT)
numValSamples = int(len(trainData) * VAL_SPLIT)
(trainData, valData) = random_split(trainData,
[numTrainSamples, numValSamples],
generator=torch.Generator().manual_seed(42))
# 现在有三组数据:训练、验证、测试
# 为每个数据集创建一个数据加载器
# 仅为trainDataLoader设置shuffle=True,因为验证和测试集不需要洗牌。
trainDataLoader = DataLoader(trainData, shuffle=True,
batch_size=BATCH_SIZE)
valDataLoader = DataLoader(valData, batch_size=BATCH_SIZE)
testDataLoader = DataLoader(testData, batch_size=BATCH_SIZE)
# 为训练和验证集计算每个纪元的步长
trainSteps = len(trainDataLoader.dataset) // BATCH_SIZE
valSteps = len(valDataLoader.dataset) // BATCH_SIZE
# 初始化LeNet模型
print("[INFO] initializing the LeNet model...")
model = LeNet(
numChannels=1,
classes=len(trainData.dataset.classes)).to(device)
# 初始化优化器和损失函数
# 在模型定义中,组合nn.NLLLoss类与LogSoftmax,得到了分类交叉熵损失(这相当于训练一个具有输出线性层和nn.CrossEntropyLoss损失的模型)
opt = Adam(model.parameters(), lr=INIT_LR)
lossFn = nn.NLLLoss()
# 初始化字典存储训练历史
H = {
"train_loss": [],
"train_acc": [],
"val_loss": [],
"val_acc": []
}
# 计算训练模型耗时
print("[INFO] training the network...")
startTime = time.time()
# 遍历纪元
for e in range(0, EPOCHS):
# 设置模型为训练模式
model.train()
# 初始化总的训练损失和验证损失
totalTrainLoss = 0
totalValLoss = 0
# 初始化训练准确率和验证准确率
trainCorrect = 0
valCorrect = 0
# 在DataLoader上遍历训练集
# PyTorch自动生成一批训练数据。在幕后数据加载器也在洗牌训练数据(如果做任何额外的预处理或数据扩充,也在这里进行)。
for (x, y) in trainDataLoader:
# 传递输入到设备
(x, y) = (x.to(device), y.to(device))
# 执行预测,计算训练损失
pred = model(x)
loss = lossFn(pred, y)
# 梯度归零,执行反向传播,更新模型参数(权重)
opt.zero_grad()
loss.backward()
opt.step()
# 将损失添加到迄今为止的培训总损失中,并计算正确预测的数量
totalTrainLoss += loss
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# 训练完,在验证集上验证模型
# 转换到自动微分以进行验证
with torch.no_grad(): # 使用torch.no_grad()以关闭梯度追踪和计算的上下文
# 设置模型到验证模式
model.eval()
# 遍历验证数据集
for (x, y) in valDataLoader:
# 传递输入到设备
(x, y) = (x.to(device), y.to(device))
# 预测并计算验证损失
pred = model(x)
totalValLoss += lossFn(pred, y)
# 计算正确的预测数
valCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# 计算平均验证和训练损失
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# 计算平均训练和验证准确率
trainCorrect = trainCorrect / len(trainDataLoader.dataset)
valCorrect = valCorrect / len(valDataLoader.dataset)
# 更新训练历史字典
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
# 打印模型训练和验证信息
# 在终端上显示训练损失、训练精度、验证损失和验证精度
print("[INFO] EPOCH: {}/{}".format(e + 1, EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}\n".format(
avgValLoss, valCorrect))
# 结束耗时统计,并显示耗时
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
# 在测试集上验证cnn模型
print("[INFO] evaluating network...")
# 关闭自动微分以进行测试集验证
with torch.no_grad():
# 设置模型为验证模式
model.eval()
# 初始化list以存储预测结果
preds = []
# 遍历测试集
for (x, y) in testDataLoader:
# 传递数据到设备
x = x.to(device)
# 预测并将顶级预测结果添加到结果list
pred = model(x)
preds.extend(pred.argmax(axis=1).cpu().numpy())
# 生成分类报告
print(classification_report(testData.targets.cpu().numpy(),
np.array(preds), target_names=testData.classes))
# 为训练历史生成matplotlib图(绘制训练损失和准确度图)
# 然后将模型权重序列化到磁盘:
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
# 序列化模型到磁盘
torch.save(model, args["model"])
4.3 predict.py
# USAGE
# python predict.py --model output/model.pth
# 设置numpy种子以获得更好的再现性 reproducibility(设置NumPy随机种子,以提高跨机器的再现性。)
import numpy as np
np.random.seed(42)
# 导入必要的包
from torch.utils.data import DataLoader # 强大的数据加载器允许轻松构建数据管道来训练CNN,用于加载KMNIST测试数据
from torch.utils.data import Subset # 构建测试数据的子集
from torchvision.transforms import ToTensor # 将输入数据转换为PyTorch张量数据类型
from torchvision.datasets import KMNIST # PyTorch库中内置的Kuzushiji MNIST数据集加载器
import argparse
import imutils
import torch
import cv2 # OpenCV绑定,用于在屏幕上进行基本绘图和显示输出图像
# 构建命令行参数及解析
# --model 磁盘的模型文件路径
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=False, default='output/model.pth',
help="path to the trained PyTorch model")
args = vars(ap.parse_args())
# 设置训练模型要使用的设备(CPU or GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载KMNIST数据集,随机获取10个数据点
print("[INFO] loading the KMNIST test dataset...")
testData = KMNIST(root="data", train=False, download=True,
transform=ToTensor())
idxs = np.random.choice(range(0, len(testData)), size=(10,))
# 使用Subset类(创建完整测试数据的较小“视图”)
testData = Subset(testData, idxs)
# 初始化测试集加载器
testDataLoader = DataLoader(testData, batch_size=1)
# 加载模型,并设置为验证模式
model = torch.load(args["model"]).to(device)
model.eval()
# 转换自动微分
# 使用torch.no_grad()以关闭梯度追踪和计算的上下文
with torch.no_grad():
# 遍历测试集
for i, (image, label) in enumerate(testDataLoader):
# 获取原始图像及实际标签
# 抓取当前图像并将其转换为NumPy数组(以便稍后使用OpenCV绘制)
origImage = image.numpy().squeeze(axis=(0, 1))
gtLabel = testData.dataset.classes[label.numpy()[0]]
# 传递数据到设备,并用经过训练的LeNet模型进行预测
image = image.to(device)
pred = model(image)
# 提取具有最高预测概率的类标签
idx = pred.argmax(axis=1).cpu().numpy()[0]
predLabel = testData.dataset.classes[idx]
# KMNIST数据集中的每个图像都是单通道灰度图像;然而希望使用OpenCV的cv2。putText函数在图像上绘制预测类标签和实际的真实值标签。
# 要在灰度图像上绘制RGB颜色,首先需要通过将灰度图像按深度累计三次来创建灰度图像的RGB表示
# 此外调整了原始图像的大小,以便在屏幕上更容易看到它(默认情况下,KMNIST图像只有28×28像素,这可能很难看到,尤其是在高分辨率监视器上)。
# 转换灰度图为RGB图像以进行绘制
# 保留宽高比的缩放为宽度128
origImage = np.dstack([origImage] * 3)
origImage = imutils.resize(origImage, width=128)
# 绘制预测的类标签在图像上
color = (0, 255, 0) if gtLabel == predLabel else (0, 0, 255)
cv2.putText(origImage, gtLabel, (2, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.95, color, 2)
# 打印结果在终端,并展示原始图像
print("[INFO] ground truth label: {}, predicted label: {}".format(
gtLabel, predLabel))
cv2.imshow("image" + str(i + 1), origImage)
cv2.waitKey(0)
参考
- https://pyimagesearch.com/2021/07/19/pytorch-training-your-first-convolutional-neural-network-cnn/