全部学习汇总: GreyZhang/g_tricore_architecture: some learning note about tricore architecture. (github.com)
继续前面的内核架构学习,这次看一下任务以及函数的描述。

1. 在嵌入式系统中,内核以及函数的设计其实是有一定的模型或者说是模式的。通常来说这个模型有一定的相似之处,都是让中断服务子程序或者是操作系统的任务运行在自己的虚拟MCU上,感觉自己拥有一切MCU的资源。如何实现这样环境的虚拟呢?很大程度是依赖于RTOS对于上下文信息的管理。
2. 在TriCore的内核上,这样的操作系统实现的时候是非常容易的,可以做到非常轻量化。因为,很多上下文的切换工作会由硬件直接处理掉。
3. 这里再次说了一下,上下文CSA其实是16个字节,主要是寄存器的信息。

这张图可以很清楚看到上下文,不管是高区还是低区的内容。其中,A11还有PCXI在两个模块中都有。A11是返回地址寄存器,而PXCI是链接字寄存器,后面可以理解这个链接字的作用其实是指明一块CSA的地址。

1. 链接字的功能作用是把不同的CSA连接起来。至于如何形成关联,后面会有更进一步的描述。
2. 上下文的上区保存是硬件自动完成的,下去通过指令来处理。
1. 感觉这里的描述有点让我糊涂,我自己理解了一下感觉这样的描述不见得是靠纯字面的信息去理解。可能,拆分一下会有更为清晰的理解。首先需要明确,为什么上下文的低区需要保存,这是因为每一个运行的任务使用的这部分信息都是不同的。这些信息可能是函数的传递参数,也可能是函数的返回值。如果要保证这样的一致性,那么中断或者trap在执行处理结束之后就得考虑对这边付恩信息的恢复和实现。
2. 不同的任务或者中断处理程序之间的寄存器不具备信息的继承性,这个也是前面描述的模型的一点体现。每一个任务的中断后的恢复,都应该有自己完整的继承性。这样,每一个任务以及ISR都可能感觉自己独占了一个MCU。
3. 高区的上下文寄存器在没有写入之前久长时去读取,其行为是未定义的。
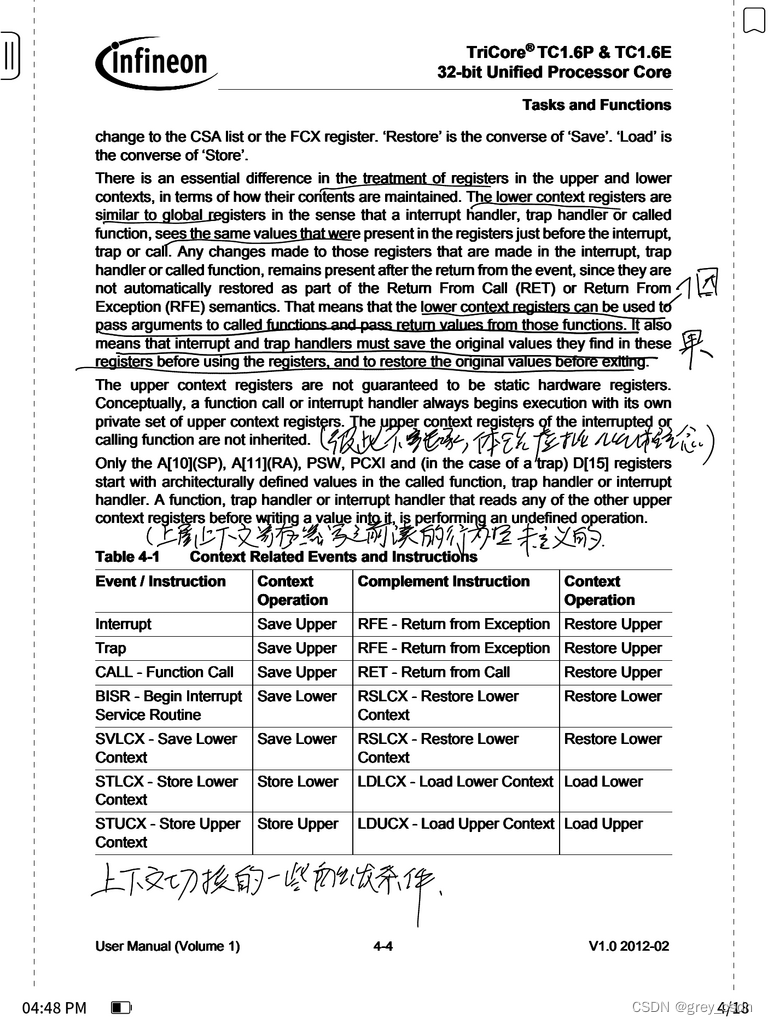
4. 这个表格给出来了上下文切换的一些条件。
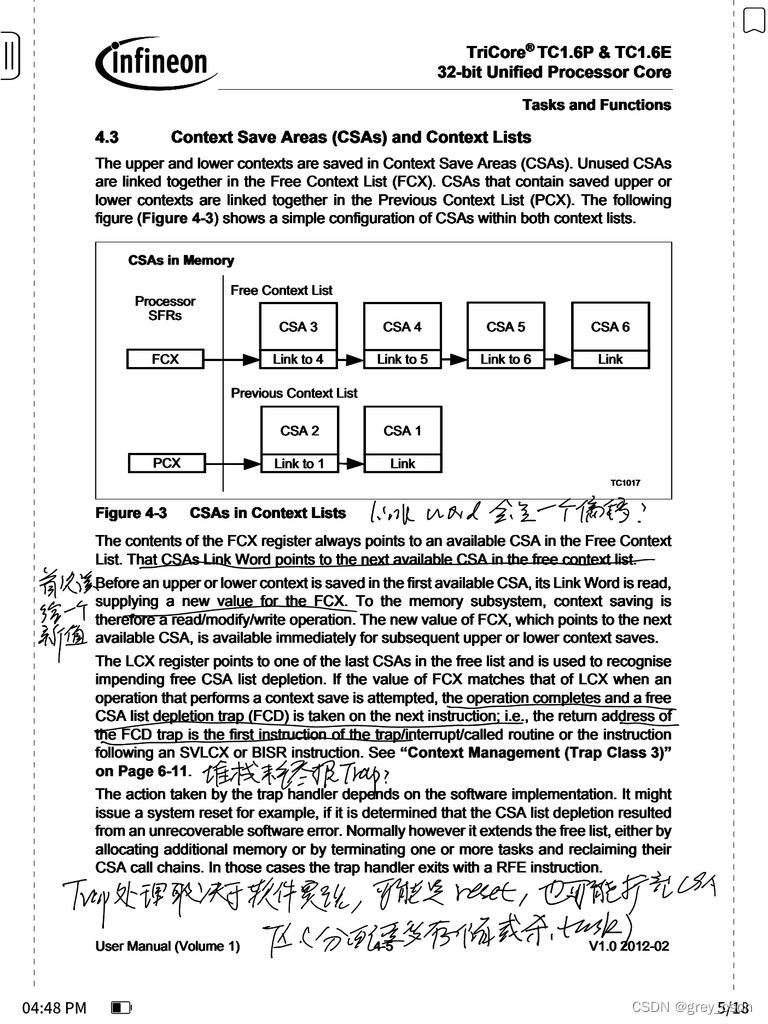
1. 链接字在功能上来说可能会是一个偏移,只要是基地址确定就可以。但是是地址的话,处理或许会更方便。
2. FCX在第一次读取的时候会给出一个全新的数值。
3. 从中间的额信息描述看,如果堆栈耗尽CSA没法继续分配,应该会报一个trap。
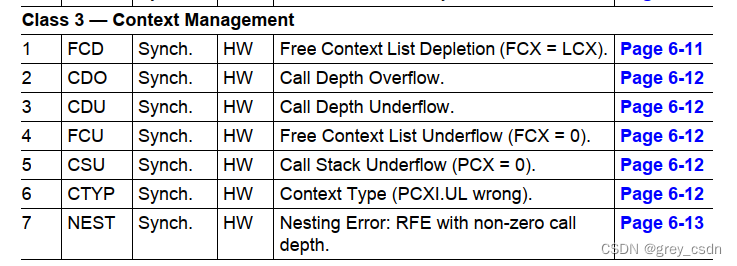
上面提到的上下文切换的trap信息,在这里能够看到很好的解释。
4. Trap的处理行为取决于软件实现,可能是reset,也可能扩充CSA区域。至于扩充的方法,可能是分配新的内存,也可能是杀死task来释放内存。

1. 函数调用的时候,RA是返回地址。
2. 如果是同步的trap,RA中是触发trap的指令PC。
3. 如果是异步的trap或者中断,RA中会是接下来要执行的指令的PC。
4. 我曾经怀疑过这个调用的层级是否会影响递归的层级,现在看到了解释,这个是故意如此设计的,这样的设计是为了避免软件出现失控的递归。
5. 剩余的信息,之前看过一次了。此外,介绍了中断管理系统管理的内容。

1. 中断优先级等信息不在上下文切换的内容当中。
2. 中断中的上下文处理,一定程度上可以看出中断嵌套功能的实现。
3. 如果中断ISR用到的寄存器少,上下文的切换处理可以硬件直接实现。如果使用的寄存器很多,可能处理的过程中是一个软硬结合的过程。

指令之中有一个函数的快速调用以及快速返回的功能,这两条指令虽然是触发了函数调用,但是不会进行上下文的切换。

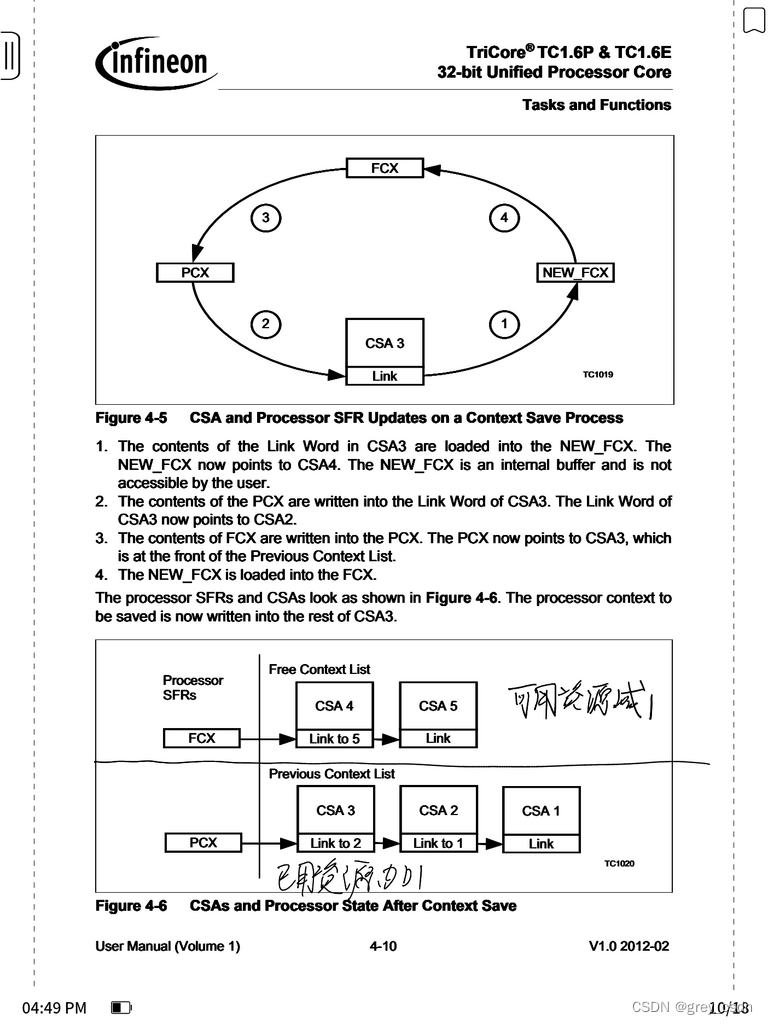

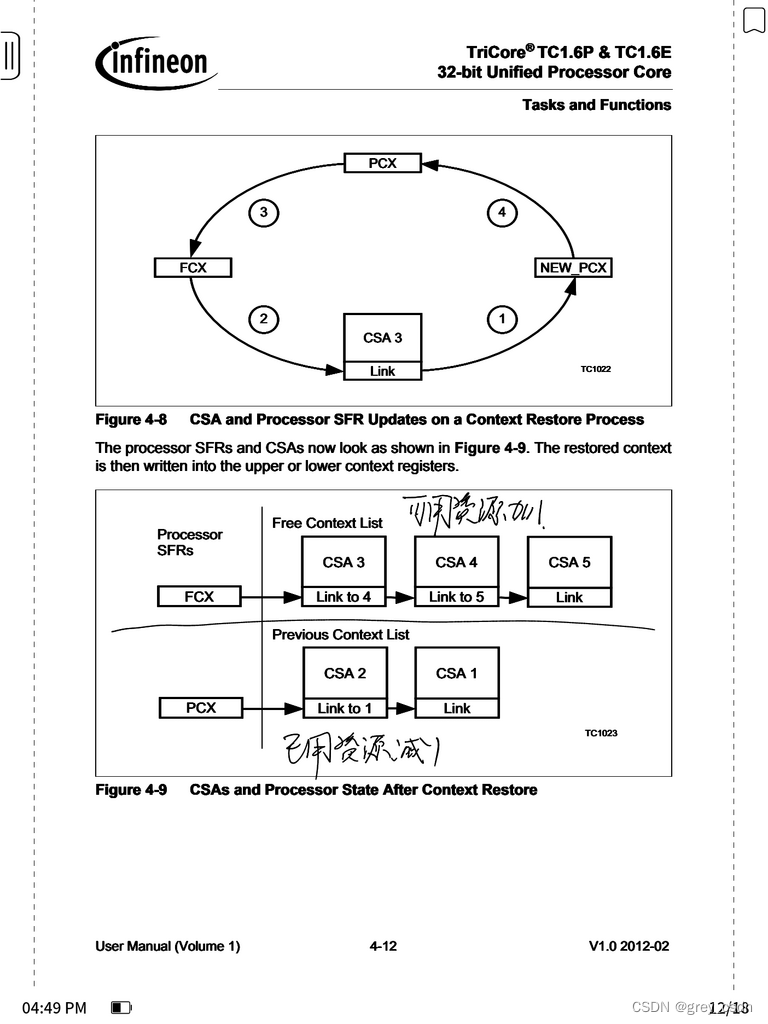
这几张图结合在一块儿,可以比较清晰地看出来CSA空间的分配以及回收过程。

几个概念强化理解下:
1. FCX,这个是CSA空间中还可以继续用的部分相应的指针。
2. PCX,这个是已经用掉的CSA的部分相应的指针。
3. LCX,这个是CSA存储的大小限制。


这两个寄存器,本质上来说是一个指针信息。

既然是一个限制值,那么肯定是可以设置并且读取进行判断的。这个信息来自于存储分配的结果,而这个分配是软件指定的,因此内核硬件本身判断不出来。

1. 内核设计的时候,可能会考虑硬件上的加速手段增强性能。因此,为了保证CSA的一致性,在CSA存储访问之前强制使用DSYNC来进行同步。
2. CSA不能是虚拟地址,因此从安全考虑,如果用了外置的存储尽量也用作通用RAM,不要考虑用在CSA的空间。