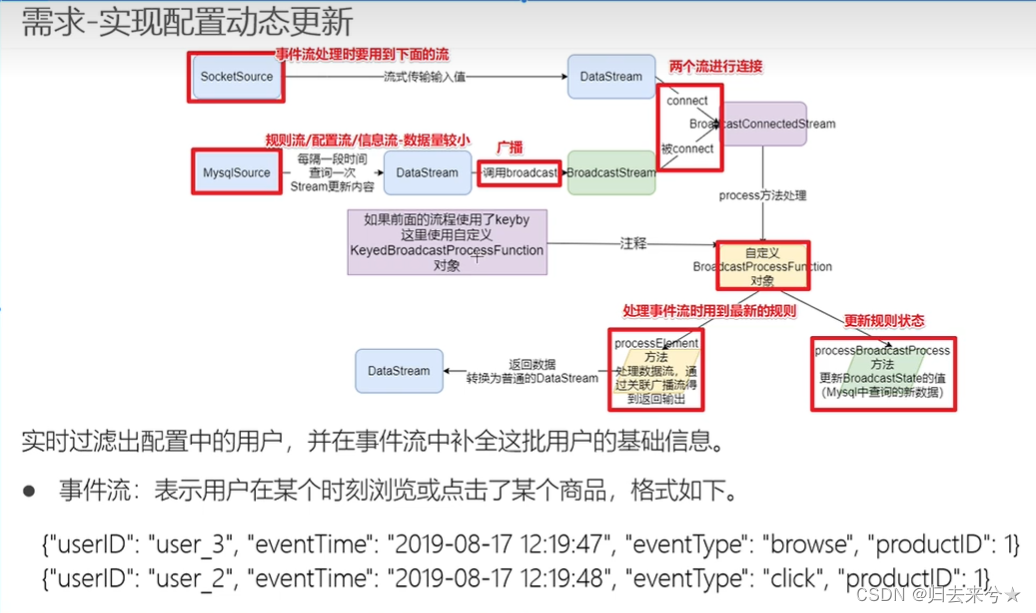
//注:绿色为正确答案,红色为错误答案,粉色为本人做错之后,系统给出的答案,可能有些题本人未标记,但是是可以区分的,题目中存在重复题目,下面有三张图的代码建议交代码块,本人也懒得修改了。
- 数据分析与可视化概述
1 . 单选题 简单 10分
Jupyter notebook不具备的功能是 ()
A.
Jupyter notebook可以直接生成一份交互式文档
B.
Jupyter notebook可以安装Python库
C.
Jupyter notebook可以导出HTML文件
D.
Jupyter notebook可以将文件分享给他人
2 . 单选题 简单 10分
在Jupyter notebook的命令模式下,要查看所有快捷键应该按下的快捷键是 ( )
A.
M
B.
ESC
C.
H
D.
A
3 . 单选题 简单 10分
在Jupyter notebook的cell中安装包语句正确的是 ( C )
A.
pip install 包名
B.
conda install 包名
C.
!pip install 包名
D.
!conda install 包名
4 . 单选题 简单 10分
在Jupyter notebook的cell中安装包语句正确的是( )。
A.
pip install 包名
B.
conda install 包名
C.
!pip install 包名
D.
!conda install 包名
5 . 单选题 简单 10分
Jupyter notebook不具备的功能是( )。
A.
Jupyter notebook可以直接生成一份交互式文档
B.
Jupyter notebook可以安装Python库
C.
Jupyter notebook可以导出HTML文件
D.
Jupyter notebook可以将文件分享给他人
6 . 简答题 中等 10分
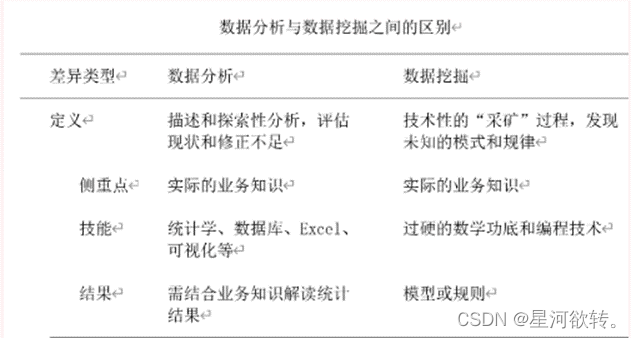
简述数据分析与数据挖掘的区别与联系。
7 . 简答题 中等 10分
简述数据可视化分析的基本过程。
包括数据处理、视觉编码和可视化生成。数据处理聚焦于数据的采集、清理、预处理、分析和挖掘;视觉编码聚焦于解决对光学图像进行接收、提取信息、加工变换、模式识别及存储显示;可视化生成则聚焦于解决将数据转换成图形,并进行交互处理。数据可视化分析通过对数据不断地观察、分析从而发现有用的信息模式。
8 . 简答题 中等 10分
简述Jupyter Notebook的安装及第三方包的安装过程。
Python第三方包的安装方式较多,本书建议采用以下方式进行安装和管理。 (1)在CMD命令窗口中,使用conda命令进行自动下载安装,用法如下: conda install <包名称列表> #安装包 conda remove <包名称列表> #卸载包 conda search<搜索项> #搜索包 conda list #查看所有包 conda update<包名称> #升级包 (2)在CMD命令窗口中使用pip命令,用法如下: pip install <包名> #安装包 pip install--upgrade <包名> #更新包 pip uninstall <包名> #删除包 也可以在Jupyter notebook的cell中运行pip命令执行相应的命令,只需在命令前加“!”,如执行 ! pip install 包名 进行包的安装。
9 . 单选题 简单 10分
在Jupyter notebook的命令模式下,查看所有快捷键应该按下的键是( )。
A.
M
B.
ESC
C.
H
D.
A
10 . 简答题 中等 10分
简述Jupyter Notebook中编辑模式与命令模式之间的切换方法。
按esc键切换为命令模式,按enter键进入编辑模式
- Python编程基础
1 . 判断题 简单 3分
列表是不可变对象,支持在原处修改。 ( )
是否
2 . 判断题 简单 3分
元组是不可变的,不能直接修改元组中元素的值,也不能为元组增删元素。( )
是否
3 . 判断题 简单 3分
Python使用lambda创建匿名函数,匿名函数拥有自己的命名空间。( )
是否
4 . 判断题 简单 3分
同一个列表中的元素的数据类型可以各不相同。( )
是否
5 . 判断题 简单 3分
列表、元组和字符串属于有序序列,其中的元素有严格的先后顺序。 ( )
是否
6 . 判断题 简单 3分
集合中的元素没有特定顺序但可以重复。( )
是否
7 . 判断题 简单 3分
列表推导式在逻辑上等价于一个循环语句,只是形式上更加简洁( )
是否
8 . 判断题 简单 3分
在Python中创建一个空集合,可以直接用 set1={} 。( )
是否
9 . 判断题 简单 3分
列表、元组和字符串都支持双向索引,有效索引的范围为[-L,L],L为列表、元组或字符串的长度。( )
是否
10 . 判断题 简单 3分
包含列表的元组可以作为字典的键。( )
是否
11 . 填空题 中等 3分
CSV(Comma-Separated Values)文件也称为字符分隔值文件,因为分隔字符也可以___ 逗号。不是
12 . 填空题 中等 3分
列表的sort方法没有返回值,或者说返回值为______。None
13 . 填空题 中等 3分
Python中要使字符串转义字符不转义,则直接在字符串前加字符______。r
14 . 填空题 中等 3分
已知字典dic={‘w’:97,’a’:19},则dic.get(‘w’, None)的值是______。97
15 . 简答题 困难 3分
输入一个包含若干数据的列表,先将列表中的数由小到大进行排序,然后将值为负数的元素进行平方运算。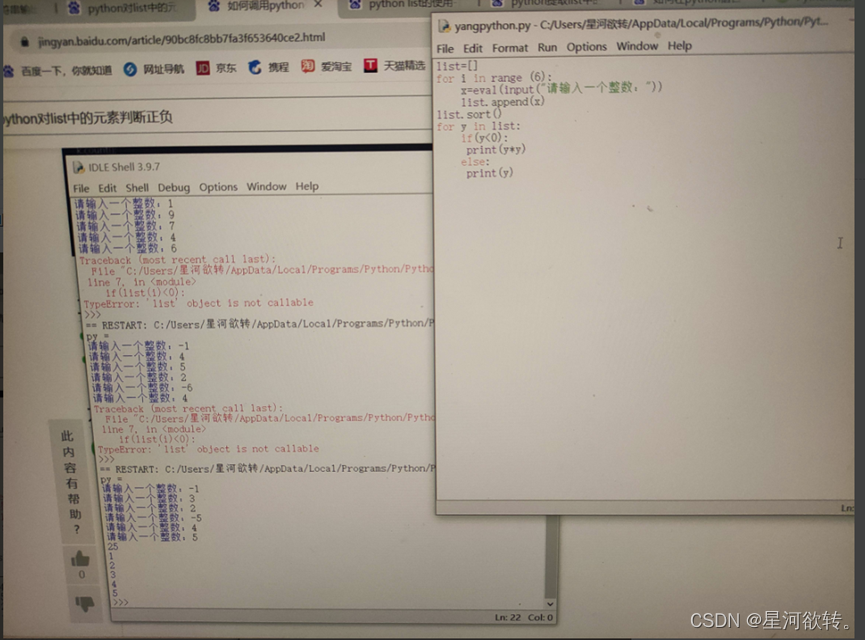
16 . 简答题 困难 3分
输入一个字符串,输出收尾交换翻转后的字符串,如输入“abcd”,输出“dcba”。要求使用内置函数实现。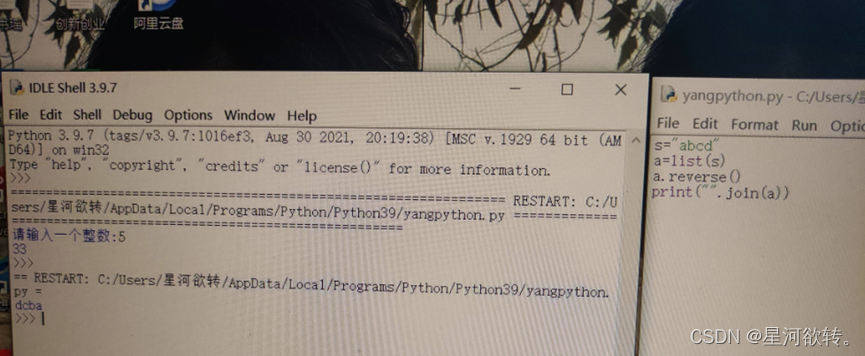
17 . 简答题 困难 3分
计算1!+2!+……+n!(n由键盘输入)。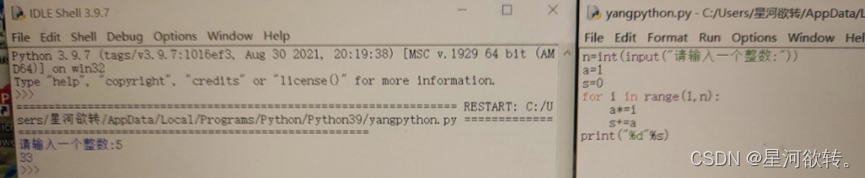
18 . 单选题 简单 3分
下面不属于python特性的是( )。
A.
简单易学
B.
免费开源
C.
属于低级语言
D.
高可移植性
19 . 单选题 简单 3分
以下哪条语句定义了一个Python字典。( )
A.
{}
B.
{1,2}
C.
[1, 2]
D.
(1,2 )
20 . 单选题 简单 3分
字符串是一个字符序列,例如,字符串s,从右侧向左第3个字符用什么索引?( )
A.
s[3]
B.
[-3]
C.
s[0:-3]
D.
s[:-3]
21 . 单选题 简单 3分
循环结构可以使用Python语言中的( )语句实现。
A.
B.
while
C.
loop
D.
if
22 . 单选题 简单 3分
Python中定义函数的关键字是( )。
A.
def
B.
define
C.
function
D.
defunc
23 . 判断题 简单 3分
列表是不可变对象,支持在原处修改。( )
是否
24 . 判断题 简单 3分
元组是不可变的,不能直接修改元组中元素的值,也不能为元组增删元素。( )
是否
25 . 判断题 简单 3分
Python使用lambda创建匿名函数,匿名函数拥有自己的命名空间。( )
是否
26 . 判断题 简单 3分
同一个列表中的元素的数据类型可以各不相同。( )
是否
27 . 判断题 简单 3分
集合中的元素没有特定顺序但可以重复。( )
是否
28 . 判断题 简单 3分
列表推导式在逻辑上等价于一个循环语句,只是形式上更加简洁。( )
是否
29 . 判断题 简单 3分
在Python中创建一个空集合,可以直接用 set1={}。( )
是否
30 . 判断题 简单 3分
列表、元组和字符串都支持双向索引,有效索引的范围为[-L,L],L为列表、元组或字符串的长度。( )
是否
31 . 判断题 简单 2分
列表是包含0个或多个对象引用的有序序列,属于序列类型。( )
是否
32 . 判断题 简单 2分
字典是存储可变数量键值对的数据结构,键和值可以是任意类型数据结构。( )
是否
33 . 填空题 中等 2分
Python中要使字符串转义字符不转义,则直接在字符串前加字符___。r
34 . 填空题 中等 2分
已知字典dic={‘w’:97,’a’:19},则dic.get(‘w’, None)的值是___。97
35 . 填空题 中等 2分
字典中的键值对用___分割。:
- NumPy数值计算基础
1 . 单选题 简单 3分
Numpy提供了两种基本对象,一种是ndarray,另一种是( )
A.
array
B.
func
C.
matrix
D.
Series
2 . 单选题 简单 3分
创建一个3*3的数组,下列代码中错误的是( )
A.
np.arange(0,9).reshape(3,3)
B.
np.eye(3)
C.
np.random.random([3,3,3])
D.
np.mat(“1,2,3;4,5,6;7,8,9”)
3 . 单选题 简单 3分
Numpy中统计数组元素个数的方法是( )
A.
ndim
B.
shape
C.
size
D.
itemsize
4 . 填空题 中等 3分
有arr = np.arange(12).reshape(3,4),则arr[(0,1),(1,3)]对应的值是______和______;arr[1:2,(0, 3)]对应的元素是______和______;arr.ndim的值是______。1、7、4、7、2
5 . 填空题 中等 3分
对于上题中的arr,若定义mask = np.array([1,0,1],dtype = np.bool),则arr[mask,1] 对应的元素是______和______。1、9
6 . 填空题 中等 3分
a=np.arange(8).reshape(2,4),np.hsplit(a,2)返回值是______。array([[0, 1], [4, 5]]), array([[2, 3], [6, 7]])]
7 . 填空题 中等 3分
数组转置是数据重塑的一种特殊形式,可以通过 ___方法或数组的T属性实现。transpose
8 . 填空题 中等 3分
创建一个范围在(0,1)之间的长度为12的等差数列的语句是 ___。np.linspace(0,1,12)
9 . 填空题 中等 3分
Numpy中数组的方法sort、argsort和lexsort分别是指 ___、 将___和___ 。
直接排序、x中的元素从小到大排列,提取其对应的index(索引)、对数组或列表按照某一行或列进行排序
10 . 填空题 中等 3分
实现创建一个10*10的ndarray对象,满足矩阵边界全为1,里面全为0对应的代码是______。
a= np.zeros((10,10), dtype =int) a[0,:]=1 a[:,9]=1 a[:,0]=1 a[9,:]=1
11 . 填空题 中等 3分
将数组arr中所有的奇数置为-1对应的语句是______。arr[arr%2!=0]=-1
12 . 单选题 简单 3分
Numpy提供了两种基本对象,一种是ndarray,另一种是( )。
A.
array
B.
func
C.
matrix
D.
Series
13 . 单选题 简单 3分
创建一个3*3的数组,下列代码中错误的是( )。
A.
np.arange(0,9).reshape(3,3)
B.
np.eye(3)
C.
np.random.random([3,3,3])
D.
np.mat(“ 1,2,3;4,5,6;7,8,9”)
14 . 单选题 简单 3分
Numpy中统计数组元素个数的方法是( )。
A.
ndim
B.
shape
C.
size
D.
itemsize
15 . 单选题 简单 3分
Numpy中的diag函数用于创建( )。
A.
对角矩阵
B.
三角矩阵
C.
值为1的矩阵
D.
值为0的矩阵
16 . 单选题 简单 3分
Numpy.random模块中用于对一个序列进行随机排序的函数是( )。
A.
uniform
B.
shuffle
C.
permutation
D.
normal
17 . 单选题 简单 3分
在NumPy中创建一个元素均为0的数组可以使用( )函数。
A.
zeros( )
B.
arange( )
C.
linspace( )
D.
logspace( )
18 . 填空题 中等 3分
有arr = np.arange(12).reshape(3,4),则arr[(0,1),(1,3)]对应的值是___和___。1、7
19 . 填空题 中等 3分
有arr = np.arange(12).reshape(3,4),若定义mask = np.array([1,0,1],dtype = np.bool),则arr[mask,1] 对应的元素是___和___。1、9
20 . 填空题 中等 3分
数组转置是数据重塑的一种特殊形式,可以通过___ 方法或数组的T属性实现。Transpose
21 . 填空题 中等 2分
创建一个元素为从10到49的ndarray对象d1=___。np.arrange(10,49,1)
22 . 填空题 中等 2分
创建一个4*4的全零矩阵对象d2= ___。np.zeros([4,4])
23 . 填空题 中等 2分
Numpy中的ndarray的size属性返回的是___。数组元素个数
24 . 填空题 中等 2分
属性shape返回的是___。数组的维度
25 . 填空题 中等 2分
Numpy中的random模块中的函数shuffle的功能是对一个序列进行___。随机排序
26 . 填空题 中等 2分
补全计算数组a = np.array([1,2,3,2,3,4,3,4,5,6])和数组b = np.array([7,2,10,2,7,4,9,4,9,8])之间的欧式距离distance的代码。
a = np.array([1,2,3,2,3,4,3,4,5,6])
b = np.array([7,2,10,2,7,4,9,4,9,8])
distance=___ np.sqrt(np.sum((a-b)**2))
27 . 填空题 中等 2分
补全从数组np.arange(15)中提取5到10之间的所有数字的代码。
array=np.arange(15)
index=np.where((array>=5) & (array<=10))
nums=___ array[index]
28 . 填空题 中等 2分
补全从数组np.arange(15)中提取5到10之间的所有数字的代码。
array=np.arange(15)
nums=___ array[(array>=5) & (array<=10)]
29 . 填空题 中等 2分
补充实现将数组a = np.arange(10).reshape(2,-1)和数组b = np.repeat(1, 10).reshape(2,-1)水平堆叠的代码。
a = np.arange(10).reshape(2,-1)
b = np.repeat(1, 10).reshape(2,-1)
array=___ np.hstack((a,b))
30 . 填空题 中等 2分
补充实现交换数组np.arange(9).reshape(3,3)中的第1列和第2列的代码。
array=np.arange(9).reshape(3,3)
array=___ array[:,[1,0,2]]
31 . 填空题 中等 2分
补全查找数组np.array([1,2,3,2,3,4,3,4,5,6])中的唯一值的数量的代码。
array=np.array([1,2,3,2,3,4,3,4,5,6])
counts=___
np.unique(array,return_counts=True)
32 . 填空题 中等 2分
补全找出数组np.array([1,2,1,1,3,4, 3,1,1,2,1,1,2])中第五个1出现的位置的代码。
array=np.array([1, 2, 1, 1, 3, 4, 3, 1, 1, 2, 1, 1, 2])
loc=__ _np.argsort(array)[4]
33 . 填空题 中等 2分
补全找到二维数组np.arange(9).reshape(3,3)每一行中的最大值的代码。
array=np.arange(9).reshape(3,3)
max_num=___ np.max(array,axis=0)
34 . 填空题 中等 2分
补全找出数组np.array([7,2,10,2,7,4,9,4,9,8])中的第二大值的代码。
array=np.array([7,2,10,2,7,4,9,4,9,8])
num=___ np.unique(array)[-2]
35 . 单选题 简单 2分
下列选项中不能创建Numpy数组的选项是( )。
A.
a = numpy.array([1,2,3])
B.
a = numpy.array([1,[1,2,3],3])
C.
a = numpy.array([[1,2,3],[4,5,6]])
D.
a = numpy.array([[‘xiao’,’qian’],[‘xiao’,’feng’]])
36 . 单选题 简单 2分
下列代码运行的结果是( )。
a = numpy.array([1,2,3])
b = numpy.array([4,5,6])
a+b
A.
[1,2,3,4,5,6]
B.
[5,7,9]
C.
21
D.
12
37 . 多选题 简单 2分
a = numpy.array([[1,2,3],[4,5,6]])下列选项中可以选取数字5的索引的是( )。
A.
a[1][1]
B.
a[2][2]
C.
a[1,1]
D.
a[2,2]
38 . 填空题 中等 2分
Numpy的主要数据类型是_________,用于计算的主要数据类型是_________。
ndarray数据类型、矩阵
39 . 填空题 中等 2分
使用_________、_________函数可以创矩阵。mat、matrix
40 . 简答题 简单 2分
Numpy中reshape( )函数主要作用是?重置数组的形状
第四章 Pandas统计分析基础
1 . 判断题 简单 2分
创建Series时如果指定了index,则只能用index访问数据。( )
是否
2 . 判断题 简单 2分
创建DataFrame时会自动加上索引,且全部列会被有序排列。( )
是否
3 . 判断题 简单 2分
Pandas中数据对象的索引可以随时被修改。 ( )
是否
4 . 判断题 简单 2分
Pandas中数据的重建索引指对索引重新排序而不是修改。( )
是否
5 . 判断题 简单 2分
交叉表是一种特殊的透视表,主要用于计算分组频率。 ( )
是否
6 . 判断题 简单 2分
两个索引不一致的series进行算数运算会出错。( )
是否
7 . 填空题 中等 2分
Pandas中与set_index方法相关用于还原索引的方法是 ___。
reset_index
8 . 填空题 中等 2分
Series是一种一维数组对象,包含一个值序列。Series中的数据通过______访问。
索引
9 . 填空题 中等 2分
Series有两种描述某条数据的手段,即______和标签。位置
10 . 填空题 中等 2分
一个DataFrame对象的属性values和ndim分别指___ 和 ___。数据元素、维度
11 . 填空题 中等 2分
reindex方法中的参数method可以取值为‘ffill’和‘bfill’,分别指___ 和______。
前向填充、后向填充
12 . 填空题 中等 2分
随机抽取数据的语句sample(frac=0.7)中的frac参数的含义是______。
抽取比例
13 . 填空题 中等 2分
修改数据中的参数“inplace”的含义是______。是否在原数据上修改
14 . 填空题 中等 2分
Pandas的数据对象在进行算术运算时如果存在不同索引会进行数据对齐,但会引入______。
NAN值
15 . 填空题 中等 2分
Pandas中的applymap方法的作用是______。
将函数套用到数据的的行与列上
16 . 填空题 中等 2分
Pandas中绘图时可以只用plot方法,具体绘图可以用参数 ___设置。Kind
17 . 单选题 简单 2分
在以下Pandas方法中不能实现实现合并数据的函数是( )。
A.
agg()函数
B.
concat()函数
C.
join()方法
D.
merge()函数
18 . 单选题 简单 2分
设置索引使用哪种方法。( )
A.
merge()方法
B.
concat()方法
C.
to_datetime()方法
D.
set_index()方法
19 . 判断题 简单 2分
创建Series时如果指定了index,则只能用index访问数据。 ( )
是否
20 . 判断题 简单 2分
Pandas中的apply方法能将函数应用于每一列。( )
是否
20 . 判断题 简单 2分
Pandas中的apply方法能将函数应用于每一列。( )
是否
22 . 判断题 简单 2分
Pandas中数据的重建索引指对索引重新排序而不是修改。( )
是否
23 . 判断题 简单 2分
交叉表是一种特殊的透视表,主要用于计算分组频率。( )
是否
24 . 判断题 简单 2分
两个索引不一致的series进行算数运算会出错。( )
是否
25 . 判断题 简单 2分
Pandas中可以通过行索引或行索引位置的切片形式选取行数据。( )
是否
26 . 判断题 简单 2分
Pandas中可以通过query方法查询数据。( )
是否
27 . 判断题 简单 2分
Pandas中使用loc和isin两个函数配合使用,按指定条件对数据进行提取。( )
是否
28 . 判断题 简单 2分
线性图一般用于描述两组数据之间的趋势。Pandas中的Plot方法默认绘制线形图。( )
是否
29 . 填空题 中等 2分
Pandas中与set_index方法相关用于还原索引的方法是___。
reset_index
30 . 填空题 中等 2分
Series是一种一维数组对象,包含一个值序列。Series中的数据通过___访问。
索引
31 . 填空题 中等 2分
Series有两种描述某条数据的手段,即___和标签。
位置
32 . 填空题 中等 2分
一个DataFrame对象的属性values和ndim分别指___和 ___。
值、维度
33 . 填空题 中等 2分
reindex方法中的参数method可以取值为‘ffill’和‘bfill’,分别指 ___和 ___。
前向值填充、后向值填充
34 . 填空题 中等 2分
随机抽取数据的语句sample(frac=0.7)中的frac参数的含义是 ___。
抽取数据的比率
35 . 填空题 中等 2分
修改数据中的参数“inplace”的含义是___。
源数据就地修改
36 . 填空题 中等 2分
Pandas的数据对象在进行算术运算时如果存在不同索引会进行数据对齐,但会引入___ 。
Nan值
37 . 填空题 中等 2分
Pandas中的applymap方法的作用是___。
函数作用于每个元素
38 . 填空题 中等 2分
Pandas中绘图时可以只用plot方法,具体绘图可以用参数___设置。
Kind
39 . 填空题 中等 2分
交叉表是一种特殊的透视表,主要用于计算___ 。
分组频率
40 . 填空题 中等 2分
Pandas的plot绘制直方图时,kind取值为___。
Hist
41 . 填空题 中等 2分
Pandas的plot绘制密度图时,kind取值为 ___。
Kde
42 . 填空题 中等 2分
Pandas的plot绘制散点图时,kind取值为___。
Scatter
43 . 填空题 中等 2分
Pandas的plot绘制柱状图时,kind取值为___。
bar
44 . 填空题 中等 2分
Pandas中直接删除数据的方法是___。
Drop
45 . 填空题 中等 2分
Pandas中删除数据时,行列数据通过参数___确定删除的是行还是列。
axis
46 . 填空题 中等 2分
DataFrame.replace({'B':'E','C':'F'})表示将表中的B替换为___ ,C替换为______。
E、F
47 . 填空题 中等 1分
Pandas通过DataFrame.rename()函数传入需要修改列名的字典形式来修改______。
列名
48 . 填空题 中等 1分
Pandas中的______方法可以根据索引或字段对数据进行分组。
groupby
49 . 单选题 简单 1分
下列说法正确的是( )。
A.
Series对象的结构比DataFrame对象的结构简单
B.
DataFrame可以看成Series的子集
C.
sort_index用作索引重建
D.
HDF4格式文件可以与HDF5文件兼容
50 . 单选题 简单 1分
下列说法正确的是( )。
A.
count函数用于数据中的所有数据
B.
统计时使用descript函数,最后结果不会出现min项
C.
diff表示三阶差分
D.
var函数用作方差统计
51 . 单选题 简单 1分
下列说法不正确的是( )。
A.
union用于计算索引的交集
B.
isin用于数据是否包含在其中
C.
insert函数可以插入索引
D.
unique用于计算索引中的唯一数组
52 . 填空题 中等 1分
读取数据库的操作有_______、_________、_________。
read_sql_table 、read_sql_query 、read_sql
53 . 填空题 中等 1分
处理数据缺陷的常用方法______、_________、_________。dropna、fillna、isnull或 notnull
54 . 简答题 简单 1分
本章主要讲述的Pandas数据的基本类型是?Frame和Series
第5章Pandas数据载入与预处理
1 . 单选题 简单 4分
利用下面哪个可视化绘图可以发现数据的异常点。 ( )
A.
密度图
B.
直方图
C.
盒图
D.
概率图
2 . 单选题 简单 4分
以下关于缺失值检测的说法中,正确的是( )
A.
null和notnull可以对缺失值进行处理
B.
dropna方法既可以删除观测记录,还可以删除特征
C.
fillna方法中用来替换缺失值的值只能是数据框
D.
Pandas库中的interpolate模块包含了多种插值方法
3 . 判断题 简单 4分
Pandas中利用merge函数合并数据表时默认的是内连接方式。( )
是否
4 . 判断题 简单 4分
Pandas中的描述性统计一般会包括缺失数据。 ( )
是否
5 . 判断题 简单 4分
语句dataframe.dropna(thresh=len(df)*0.9,axis=1) 表示如果某列的缺失值超过90%则删除该列。 ( )
是否
6 . 判断题 简单 4分
利用merge方法合并数据时允许合并的DataFrame之间没有连接键。 ( )
是否
7 . 判断题 简单 4分
哑变量(Dummy Variables)又称虚拟变量,是用以反映质的属性的一个人工变量。( )
是否
8 . 简答题 中等 4分
简述Pandas删除空缺值方法dropna中参数thresh的使用方法。
dropna中的参数thresh当传入thresh = N时,表示要求一行至少具有N个非NaN才能存活。
9 . 简答题 中等 4分
简述Python中利用数据统计方法检测异常值的常用方法及其原理。
- 散点图方法观察 b. 箱线图分析 c. 3σ法则,原理略,见课本。
10 . 简答题 中等 4分
简述数据分析中要进行数据标准化的主要原因。
不同特征之间往往具有不同的量纲,由此造成数值间的差异很大。因此为了消除特征之间量纲和取值范围的差异可能会造成的影响,需要对数据进行标准化处理。
11 . 简答题 中等 4分
简述Pandas中利用cut方法进行数据离散化的用法。
将数据的值域划分成具有相同宽度的区间,区间个数由数据本身的特点决定或由用户指定。Pandas提供了cut函数,可以进行连续型数据的等宽离散化。cut函数的基础语法格式为: pandas.cut(x,bins,right=True,labels=None,retbins=False,precision=3)
12 . 单选题 简单 4分
利用下面哪个可视化绘图可以发现数据的异常点。( )
A.
密度图
B.
直方图
C.
盒图
D.
概率图
13 . 单选题 简单 4分
以下关于缺失值检测的说法中,正确的是( )
A.
null和notnull可以对缺失值进行处理
B.
dropna方法既可以删除观测记录,还可以删除特征
C.
fillna方法中用来替换缺失值的值只能是数据框
D.
Pandas库中的interpolate模块包含了多种插值方法
14 . 多选题 中等 4分
在现实世界的数据中,缺失值是常有的,一般的处理方法有( )。
A.
忽略
B.
删除
C.
平均值填充
D.
最大值填充
15 . 判断题 简单 4分
Pandas中使用isnull().sum()可以统计缺失值。( )
是否
16 . 判断题 简单 4分
Pandas中的dropna中的thresh=N时表明要求一行有N个NaN值时该数据才能保留。( )
是否
17 . 判断题 简单 3分
Pandas中利用merge函数合并数据表时默认的是内连接方式。( )
是否
18 . 判断题 简单 3分
Pandas中的描述性统计一般会包括缺失数据。( )
是否
19 . 判断题 简单 3分
语句dataframe.dropna(thresh=len(df)*0.9,axis=1) 表示如果某列的缺失值超过90%则删除该列。( )
是否
20 . 判断题 简单 3分
利用merge方法合并数据时允许合并的DataFrame之间没有连接键。( )
是否
21 . 判断题 简单 3分
哑变量(Dummy Variables)又称虚拟变量,是用以反映质的属性的一个人工变量。( )
是否
22 . 判断题 简单 3分
DataFrame的duplicates方法可以用来删除重复数据。( )
是否
23 . 判断题 简单 3分
网络关联关系在大数据中是一种常见的关系。( )
是否
24 . 填空题 中等 3分
Pandas中drop方法中的参数how取值为 ___时表示只要某行有缺失值就将改行丢弃。
any
25 . 填空题 中等 3分
Pandas中drop方法中的参数how取值为 ___时表示某行全部为缺失值就将改行丢弃。
all
26 . 填空题 中等 3分
Pandas通过read_json函数读取___数据。
JSON
27 . 填空题 中等 3分
Pandas要读取Mysql中的数据,首先要安装 ___包,然后进行数据文件读取。
Mysqldb
28 . 填空题 中等 3分
Pandas要读取SQL sever中的数据,首先要安装 ___包,然后进行数据文件读取。
pymssql

![[附源码]Python计算机毕业设计出版社样书申请管理系统](https://img-blog.csdnimg.cn/52e37ea1aaa44fb79b9fdcc135c11ebb.png)