140.1 Horovod
- Horovod是 Uber 开源的又一个深度学习工具,它的发展吸取了 Facebook「一小时训练 ImageNet 论文」与百度 Ring Allreduce 的优点,可为用户实现分布式训练提供帮助。
- Horovod 支持通过用于高性能并行计算的低层次接口 – 消息传递接口 (MPI) 进行分布式模型训练。有了 MPI,就可以利用分布式 Kubernetes 集群来训练 TensorFlow 和 PyTorch 模型。
- 分布式 TensorFlow 的参数服务器模型(parameter server paradigm)通常需要对大量样板代码进行认真的实现。但是 Horovod 仅需要几行。下面是一个分布式 TensorFlow 项目使用 Horovod 的示例:
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model…
loss = …
opt = tf.train.AdagradOptimizer(0.01)
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=“/tmp/train_logs”,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
在该示例中,粗体文字指进行单个 GPU 分布式项目时必须做的改变:
- hvd.init() 初始化 Horovod。
- config.gpu_options.visible_device_list = str(hvd.local_rank()) 向每个 TensorFlow 流程分配一个 GPU。
- opt=hvd.DistributedOptimizer(opt) 使用 Horovod 优化器包裹每一个常规 TensorFlow 优化器,Horovod 优化器使用 ring-allreduce 平均梯度。
- hvd.BroadcastGlobalVariablesHook(0) 将变量从第一个流程向其他流程传播,以实现一致性初始化。如果该项目无法使用 MonitoredTrainingSession,则用户可以运行 hvd.broadcast_global_variables(0)。
- 之后,可以使用 mpirun 命令使该项目的多个拷贝在多个服务器中运行:
$ mpirun -np 16 -x LD_LIBRARY_PATH -H
server1:4,server2:4,server3:4,server4:4 python train.py
- mpirun 命令向四个节点分布 train.py,然后在每个节点的四个 GPU 上运行 train.py。
140.2 BigDL
- BigDL是一种基于Apache Spark的分布式深度学习框架。它可以无缝的直接运行在现有的Apache Spark和Hadoop集群之上。BigDL的设计吸取了Torch框架许多方面的知识,为深度学习提供了全面的支持;包括数值计算和高级神经网络;借助现有的Spark集群来运行深度学习计算,并简化存储在Hadoop中的大数据集的数据加载。
- BigDL优点:
- 丰富的深度学习支持。模拟Torch之后,BigDL为深入学习提供全面支持,包括数字计算(通过Tensor)和高级神经网络 ; 此外,用户可以使用BigDL将预先训练好的Caffe或Torch模型加载到Spark程序中。
- 极高的性能。为了实现高性能,BigDL在每个Spark任务中使用英特尔MKL和多线程编程。因此,在单节点Xeon(即与主流GPU 相当)上,它比开箱即用开源Caffe,Torch或TensorFlow快了数量级。
- 有效地横向扩展。BigDL可以通过利用Apache Spark(快速分布式数据处理框架),以及高效实施同步SGD和全面减少Spark的通信,从而有效地扩展到“大数据规模”上的数据分析
- BigDL缺点:
- 对机器要求高 jdk7上运行性能差 在CentOS 6和7上,要将最大用户进程增加到更大的值(例如514585); 否则,可能会看到错误,如“无法创建新的本机线程”。
- 训练和验证的数据会加载到内存,挤占内存
- BigDL满足的应用场景:
- 直接在Hadoop/Spark框架下使用深度学习进行大数据分析(即将数据存储在HDFS、HBase、Hive等数据库上);
- 在Spark程序中/工作流中加入深度学习功能;
- 利用现有的 Hadoop/Spark 集群来运行深度学习程序,然后将代码与其他的应用场景进行动态共享,例如ETL(Extract、Transform、Load,即通常所说的数据抽取)、数据仓库(data warehouse)、功能引擎、经典机器学习、图表分析等。
140.3 Petastorm
- Petastorm是一个由 Uber ATG 开发的开源数据访问库。这个库可以直接基于数 TB Parquet 格式的数据集进行单机或分布式训练和深度学习模型评估。Petastorm 支持基于 Python 的机器学习框架,如 Tensorflow、Pytorch 和 PySpark,也可以直接用在 Python 代码中。
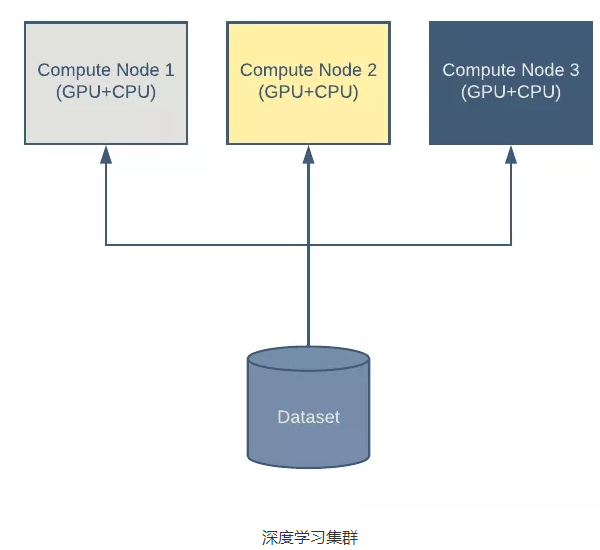
- 即使是在现代硬件上训练深度模型也很耗时,而且在很多情况下,很有必要在多台机器上分配训练负载。典型的深度学习集群需要执行以下几个步骤:
- 一台或多台机器读取集中式或本地数据集。
- 每台机器计算损失函数的值,并根据模型参数计算梯度。在这一步通常会使用 GPU。
- 通过组合估计的梯度(通常由多台机器以分布式的方式计算得出)来更新模型系数。
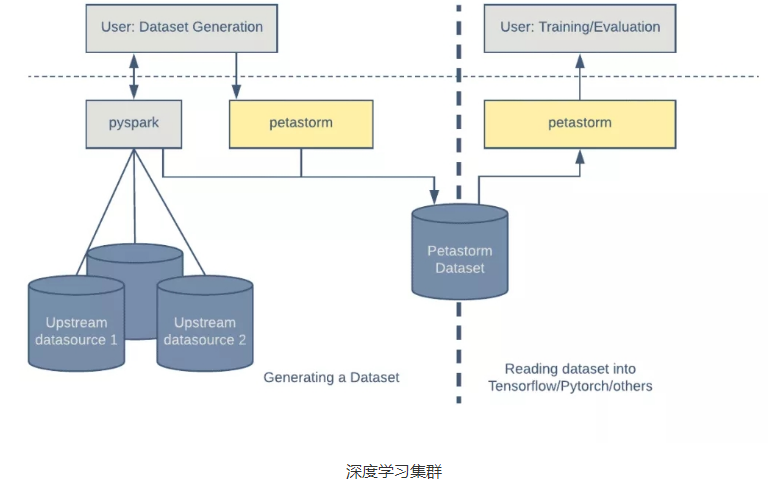
- 通常,一个数据集是通过连接多个数据源的记录而生成的。这个由 Apache Spark 的 Python 接口 PySpark 生成的数据集稍后将被用在机器学习训练中。Petastorm 提供了一个简单的功能,使用 Petastorm 特定的元数据对标准的 Parquet 进行了扩展,从而让它可以与 Petastorm 兼容。
- 有了 Petastorm,消费数据就像在 HDFS 或文件系统中创建和迭代读取对象一样简单。Petastorm 使用 PyArrow 来读取 Parquet 文件。
- 将多个数据源组合到单个表格结构中,从而生成数据集。可以多次使用相同的数据集进行模型训练和评估。
- 为分布式训练进行分片
- 在分布式训练环境中,每个进程通常负责训练数据的一个子集。一个进程的数据子集与其他进程的数据子集正交。Petastorm 支持将数据集的读时分片转换为正交的样本集。
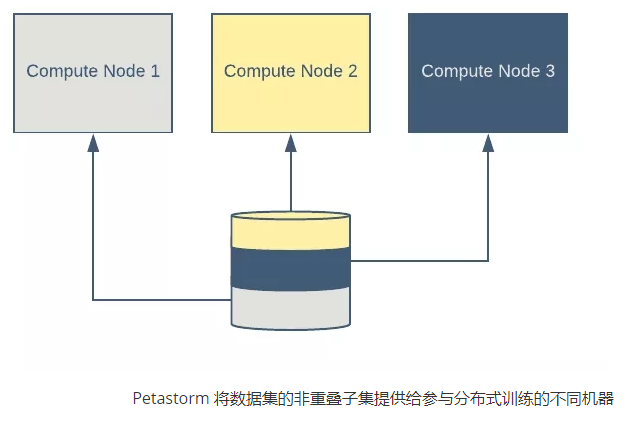
- 在分布式训练环境中,每个进程通常负责训练数据的一个子集。一个进程的数据子集与其他进程的数据子集正交。Petastorm 支持将数据集的读时分片转换为正交的样本集。
- 本地缓存
- Petastorm 支持在本地存储中缓存数据。当网络连接速度较慢或带宽很昂贵时,这会派上用场。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sapkxS3X-1669085154833)(https://upload-images.jianshu.io/upload_images/19745945-bf69005adbadb39e.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
- Petastorm 支持在本地存储中缓存数据。当网络连接速度较慢或带宽很昂贵时,这会派上用场。
140.4 TensorFlowOnSpark
- TensorFlowOnSpark为 Apache Hadoop 和 Apache Spark 集群带来可扩展的深度学习。 通过结合深入学习框架 TensorFlow 和大数据框架 Apache Spark 、Apache Hadoop 的显着特征,TensorFlowOnSpark 能够在 GPU 和 CPU 服务器集群上实现分布式深度学习。
- 满足的应用场景:
- 为了利用TensorFlow在现有的Spark和Hadoop集群上进行深度学习。而不需要为深度学习设置单独的集群。

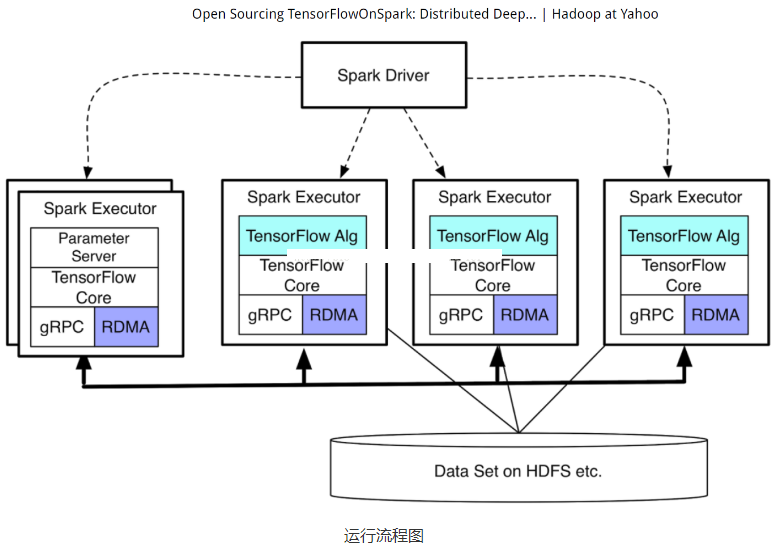
- 为了利用TensorFlow在现有的Spark和Hadoop集群上进行深度学习。而不需要为深度学习设置单独的集群。
- 优点:
- 轻松迁移所有现有的TensorFlow程序,<10行代码更改;
- 支持所有TensorFlow功能:同步/异步训练,模型/数据并行,推理和TensorBoard;
- 服务器到服务器的直接通信在可用时实现更快的学习;
- 允许数据集在HDFS和由Spark推动的其他来源或由TensorFlow拖动;
- 轻松集成您现有的数据处理流水线和机器学习算法(例如,MLlib,CaffeOnSpark);
- 轻松部署在云或内部部署:CPU和GPU,以太网和Infiniband。
- TensorFlowOnSpark是基于google的TensorFlow的实现,而TensorFlow有着一套完善的教程,内容丰富。
- 劣势:
- 开源时间不长,未得到充分的验证。
大数据视频推荐:
网易云课堂
CSDN
人工智能算法竞赛实战
AIops智能运维机器学习算法实战
ELK7 stack开发运维实战
PySpark机器学习从入门到精通
AIOps智能运维实战
腾讯课堂
大数据语音推荐:
ELK7 stack开发运维
企业级大数据技术应用
大数据机器学习案例之推荐系统
自然语言处理
大数据基础
人工智能:深度学习入门到精通