一、前言
阅读本节需要先掌握【SPARKSQL3.0-Optimizer阶段源码剖析】
本质:物理计划阶段将optimizer阶段优化后的逻辑算子树【LogicalPlan】进行进一步转换,生成物理算子树【SparkPlan】,物理算子树的节点可以直接生成 RDD 或对 RDD 进行 transformation 操作
最终完成了从sql字符串到生成可执行的RDD算子,再由RDD算子去执行操作的过程
这也正是为何spark官网强烈建议使用sparksql,而不是底层RDD算子,因为sparksql模块在执行rdd操作之上做了很多的优化
二、示例
这里沿用一开始的示例,将action操作改为collect,代码:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder()
.config(sparkConf)
.getOrCreate()
case class Person(name: String, age: Int)
Seq(Person("Jack", 12), Person("James", 21), Person("Mac", 30)).toDS().createTempView("person")
spark.sql("SELECT * FROM PERSON WHERE AGE > 18").collect // action执行操作
打印:
== Parsed Logical Plan ==
'Project [*]
+- 'Filter ('AGE > 18)
+- 'UnresolvedRelation [PERSON]
== Analyzed Logical Plan ==
name: string, age: int
Project [name#2, age#3]
+- Filter (AGE#3 > 18)
+- SubqueryAlias person
+- LocalRelation [name#2, age#3]
== Optimized Logical Plan ==
LocalRelation [name#2, age#3]
== Physical Plan ==
LocalTableScan [name#2, age#3]
三、源码
我们debug进入到collect算子中,其中将queryExecution[执行sql的关键类]和collectFromPlan函数作为参数传入到withAction函数中

collectFromPlan函数

withAction函数

随后将qe.executedPlan变量值的结果传递给action函数【也就是上面的collectFromPlan函数】

我们先来看executedPlan变量,是在QueryExecution类中;
sql物理执行计划过程是首先调用executedPlan函数 -> 调用sparkPlan函数,可以看到sparkPlan变量的返回值是SparkPlan,我们之前接触的都是logicalPlan,那么就需要先来了解一下SparkPlan
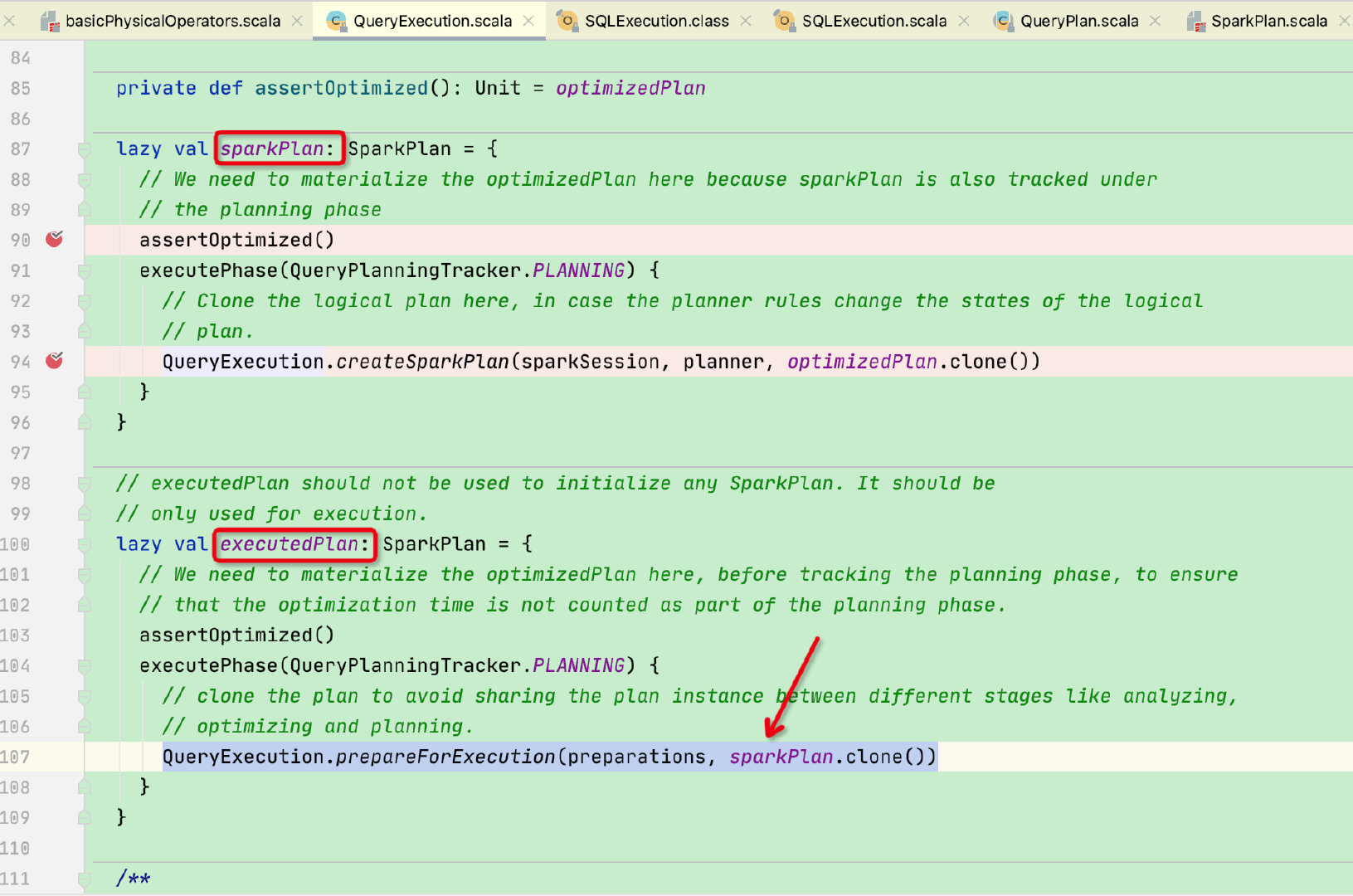
在optimized阶段我们的sql还是logicalPlan逻辑树,但经过了sparkPlan函数则变成SparkPlan物理树,这里需要先介绍一下SparkPlan,先看结构:sparkPlan 和 LogicalPlan是并列关系
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UWbhiF7F-1669101955160)(https://segmentfault.com/img/remote/1460000039649880/view)]

LogicalPlan主要用于逻辑树的解析和优化,而SparkPlan则用于物理执行计划
Spark SQL 将 SQL 语句经过逻辑算子树转换成物理算子树,在物理算子树中,叶子类型的 SparkPlan 节点负责从无到有地创建 RDD,可以说sql -> rdd中的最后一步就是由SparkPlan节点完成的
在SparkPlan类中有execute函数用于负责将算子转化成RDD,其中调用了doExecute抽象函数,由各个叶子节点子类来实现


不同的子类有不同的doExecute实现,感兴趣的小伙伴可以点进去看看不同的实现

那么sparkPlan物理树又是如何生成的呢?回到最开始sparkPlan函数中:


可以看到是调用planner.plan 来构建SparkPlan,接下来看一下planner是什么:

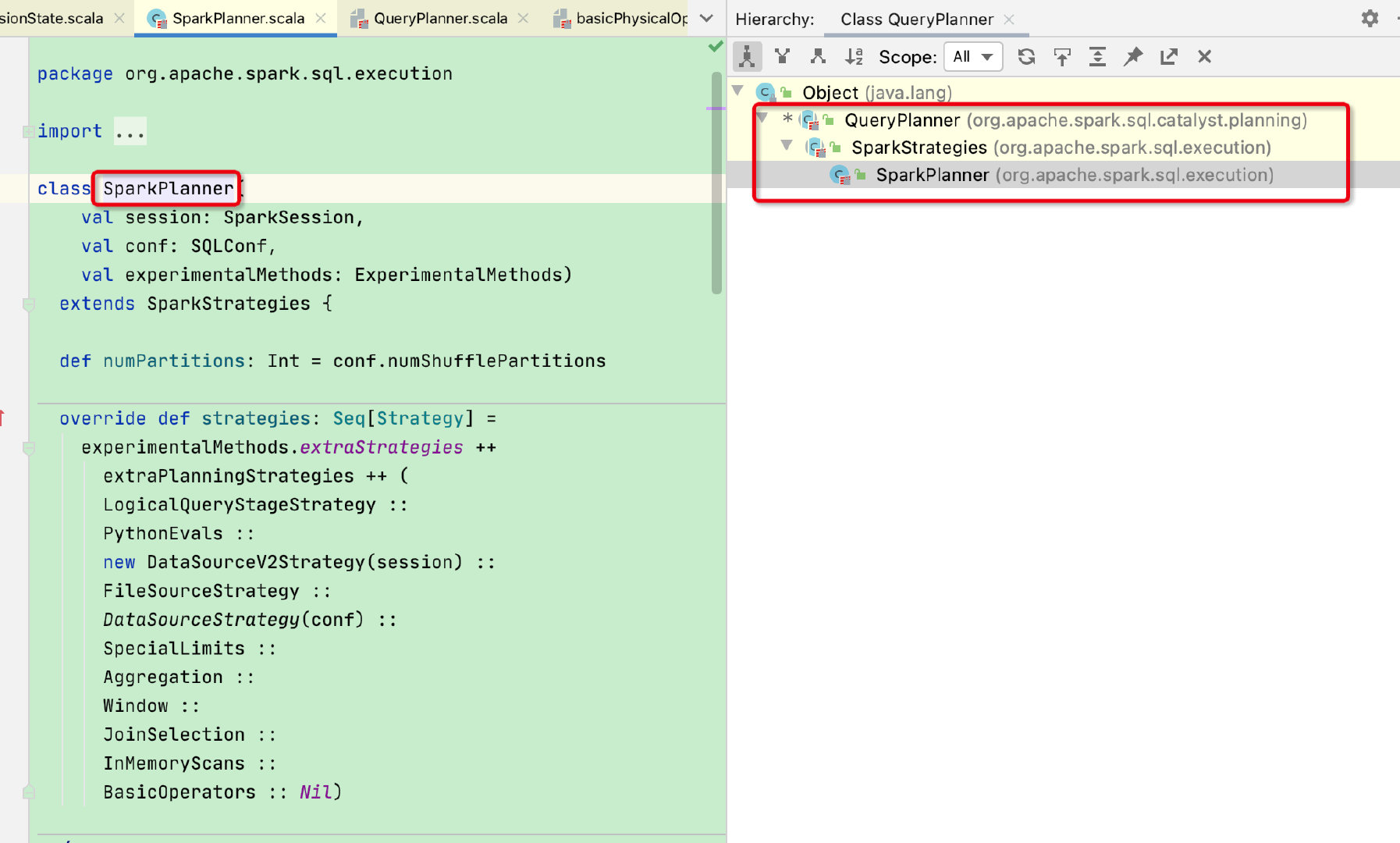
planner来自sessionState中,类型为SparkPlanner

SparkPlanner继承于QueryPlanner,QueryPlanner中的plan函数是将logicalPlan逻辑树转化成SparkPlan物理树的关键
这里贴一下plan的代码: 这块和Analyzer、Optimizer阶段的规则迭代很像,通过strategies策略列表调用localPlan迭代执行,最终得到物理树;
abstract class QueryPlanner[PhysicalPlan <: TreeNode[PhysicalPlan]] {
/** 可以使用的执行策略列表 */
def strategies: Seq[GenericStrategy[PhysicalPlan]]
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] = {
// Obviously a lot to do here still...
// 通过strategies不同的策略来调用logicalPlan
val candidates = strategies.iterator.flatMap(_(plan))
// 如果该集合中存在 PlanLater 类型的
// SparkPlan 通过 aceholder 中间变量取出对应的 LogicalPlan 后,递归调用 plan()方法,将
// planLater 替换为子节点的物理计划
val plans = candidates.flatMap { candidate =>
val placeholders = collectPlaceholders(candidate)
// 对物理计划列表进行过滤,去掉一些不够高效的物理计划
if (placeholders.isEmpty) {
// Take the candidate as is because it does not contain placeholders.
Iterator(candidate)
} else {
// Plan the logical plan marked as [[planLater]] and replace the placeholders.
placeholders.iterator.foldLeft(Iterator(candidate)) {
case (candidatesWithPlaceholders, (placeholder, logicalPlan)) =>
// Plan the logical plan for the placeholder.
val childPlans = this.plan(logicalPlan)
candidatesWithPlaceholders.flatMap { candidateWithPlaceholders =>
childPlans.map { childPlan =>
// Replace the placeholder by the child plan
candidateWithPlaceholders.transformUp {
case p if p.eq(placeholder) => childPlan
}
}
}
}
}
}
val pruned = prunePlans(plans)
assert(pruned.hasNext, s"No plan for $plan")
pruned
}
}
可以看到strategies集合中包含logicalPlan转化成sparkPlan的策略,strategies集合由SparkPlanner子类实现:其中extraStrategies是可以让用户指定的额外策略,每一个策略都有其实现的apply函数,感兴趣的话可以看一下不同策略的实现。

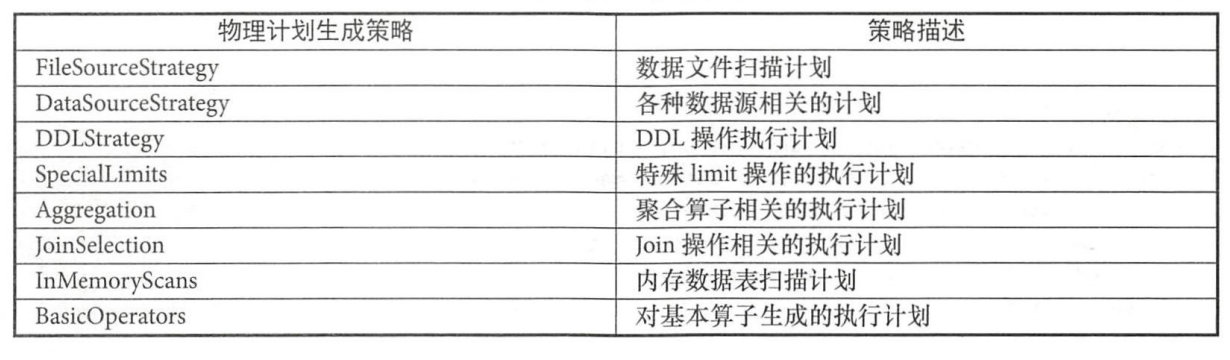
这里贴一下常见的策略描述
那么将logicalPlan转化为SparkPlan后,我们在网上会经常看到如下图片内容:costModel阶段

Cost Model 对应的就是基于代价的优化(Cost-based Optimizations,CBO,详见 SPARK-16026 ),核心思想是计算每个物理计划的代价,然后得到最优的物理计划。但是截止到spark3.0,这一部分并没有实现,直接返回多个物理计划列表的第一个作为最优的物理计划,如下:
在QueryPlanner中的plan函数中会调用prunePlans抽象函数,此函数便是cost Model计划,由SparkPlanner实现

在SparkPlanner中的实现是将集合原封不动返回,注释解释到会在后期实现此函数

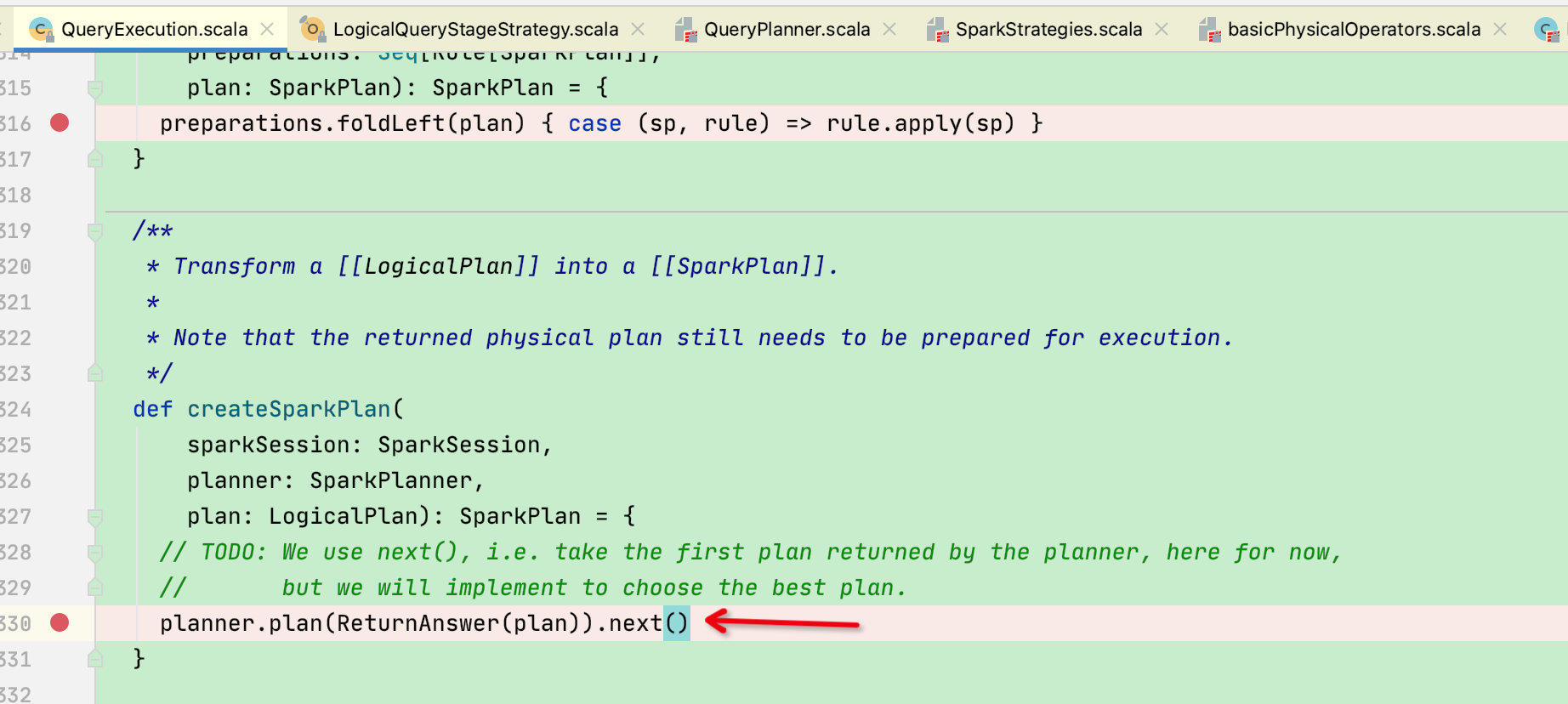
回到前面QueryExecution的createSparkPlan函数,将planner.plan得到的集合中第一个计划[next]返回
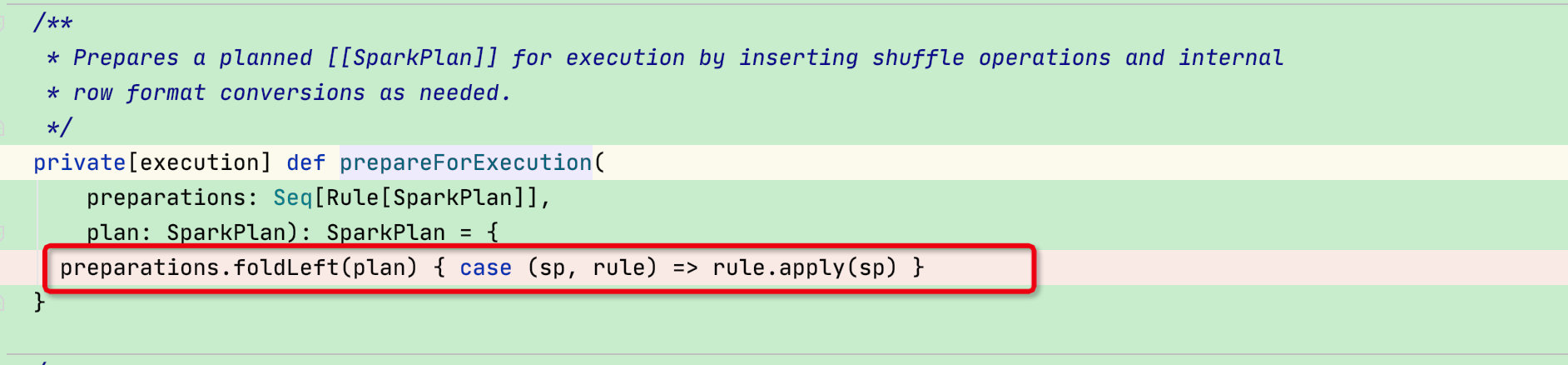
此时sparkPlan阶段结束,我们回到executionPlan函数:可以看到有一个prepareForExecution准备执行函数,此函数是将preparations集合中不同的规则作用在sparkPlan物理树,从而获得优化后的可执行的sparkPlan

调用preparations函数,并将InsertAdaptiveSparkPlan传递进去

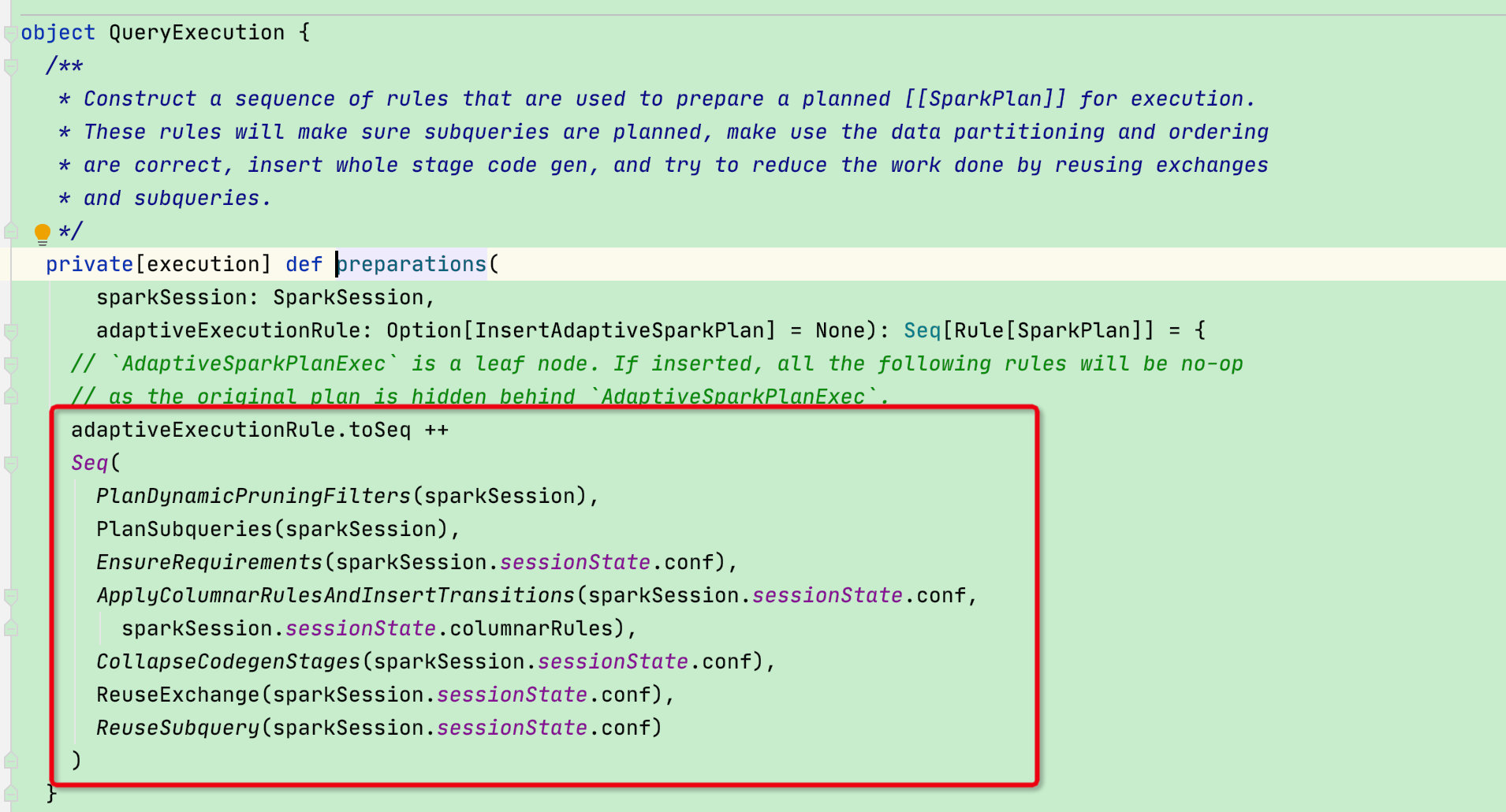
在上面的规则中有几个重头戏,一个是传进来的参数InsertAdaptiveSparkPlan 就是spark3.0中新增功能AQE【自适应执行】,SPARK-9850 在 Spark 中提出了自适应执行的基本思想,关于功能实现不在这里过多陈述,可查看相关文献;由此可以看出AQE功能目前只能通过sparksql才能使用
上面的 Rule 中还有一个 CollapseCodegenStages 也是重头戏,这就全代码阶段生成,Catalyst 全阶段代码生成的入口就是这个规则。当然,如果需要 Spark 进行全阶段代码生成,需要将 spark.sql.codegen.wholeStage 设置为 true(默认)。
剩余常用的规则参考下图
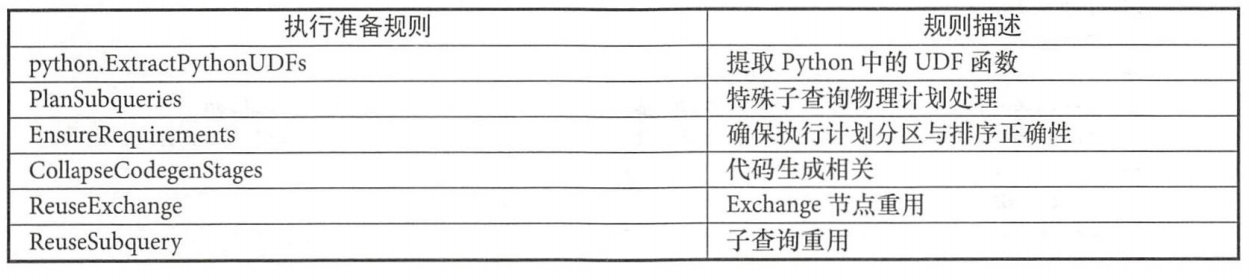
CollapseCodegenStages这一阶段也叫做Tungsten阶段,这部分机制实现较为复杂,会在后面单独开一节讲解,这里简单提一下:Tungsten阶段是建立在现代编译器和MPP数据库的基础上,并且应用到数据的处理中。主要的思想是将那些拖慢整个程序执行速度的代码放到一个单独的函数中,消除虚拟函数的调用,并使用寄存器来存放中间结果。这项技术被称作“whole-stage code generation.
经过了prepareForExecution函数后,executedPlan的任务就完成了,我们回到一开始的withAction函数中:

此时会调用action【collectFromPlan】函数,并将executedPlan生成的sparkPlan传递过去,collectFromPlan函数中调用了sparkPlan的executeCollect函数【此函数在部分子类中有重写】

在executeCollect中主要是通过getByteArrayRdd函数获得RDD
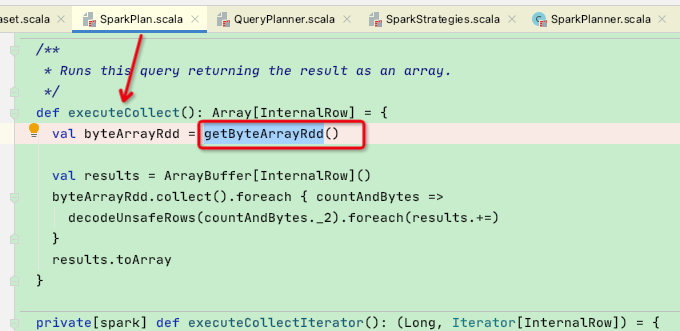
可以看到getByteArrayRdd函数中调用了execute函数,而execute函数中又调用了doExecute抽象函数,从而让sparkPlan的子类迭代生成所需要的RDD


生成好RDD后,再回到executeCollect函数中,通过byteArrayRdd.collect()函数提交runJob到达RDD提交阶段,到此sparksql阶段结束。
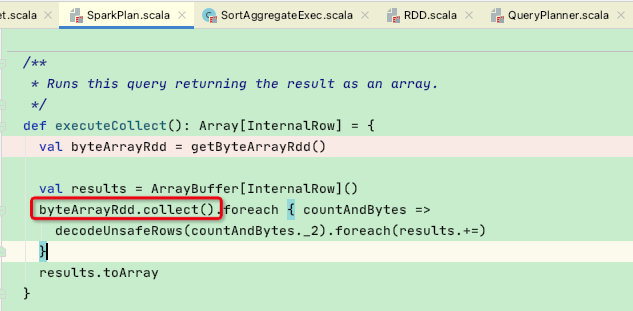
至此PhysicalPlan物理阶段结束