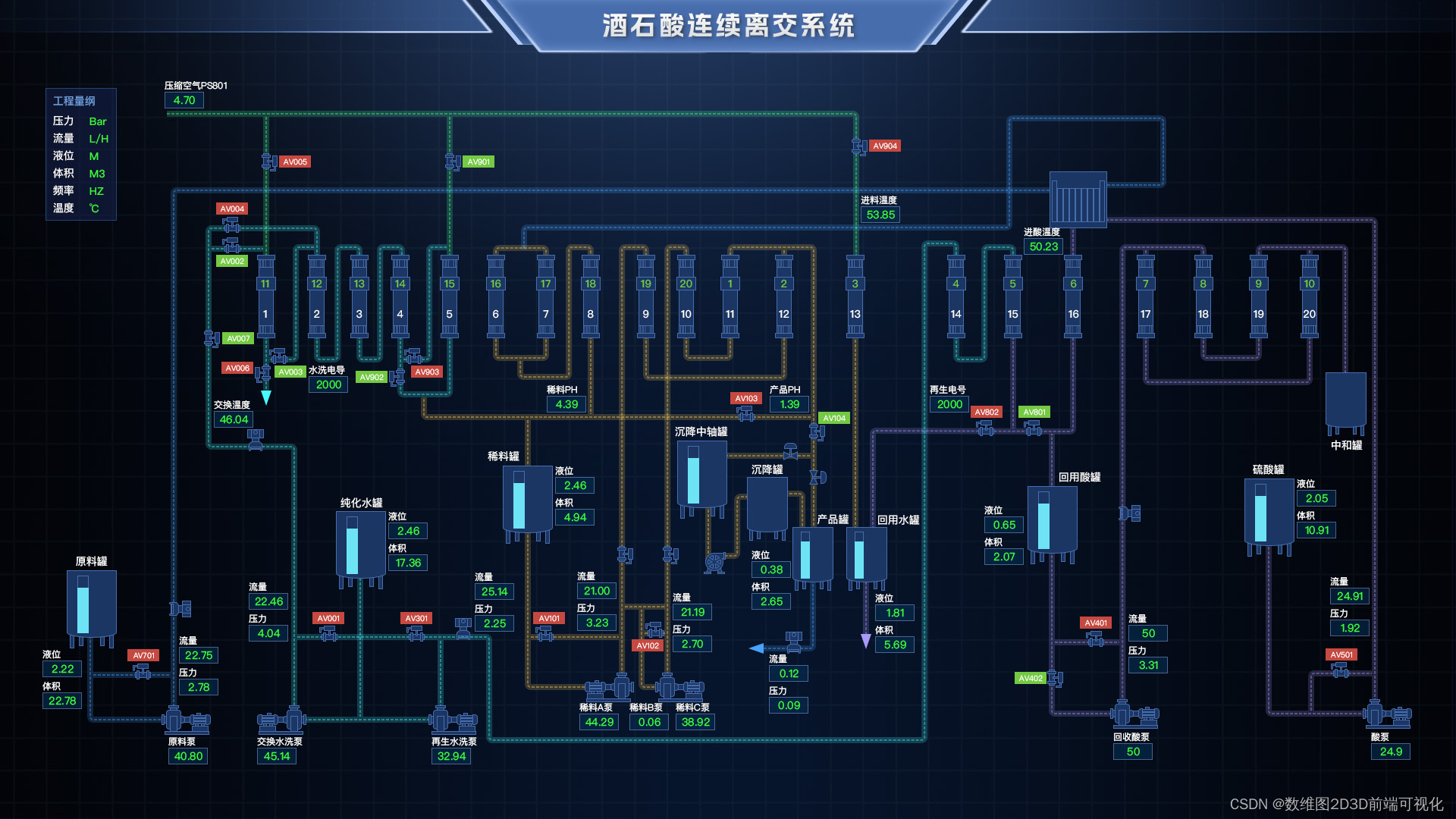
推荐系统实战3——推荐系统中Embedding层工作原理浅析
- 学习前言
- 什么是Embedding
- 一、为什么要有Embedding
- 二、推荐系统中常见的Embedding处理方式
- 1、字符串形式的输入
- 2、连续值(特定范围值)的输入
- 三、Embedding的注意点
学习前言
Embedding层是推荐系统特征转换的精髓,有必要简单了解一下他的原理。

什么是Embedding
一、为什么要有Embedding

Embedding技术是现代推荐系统的标配,它的主要作用是将稀疏向量转换成稠密向量。
简单来讲,Embedding就是用一个低维稠密的向量来表示一个对象,在推荐系统中,这个对象常常指的是一个特征(比如说价格、ID、种类等等),在推荐系统中,很多特征以文本的方式存在,我们可以使用哈希桶或者列表将文本转化成数字,但仅仅是数字是不利于矩阵处理的,如果使用One-hot对类别、Id型特征进行编码,导致样本特征向量极度稀疏,而深度学习的结构特点使其不利于稀疏特征向量的处理。
这个时候Embedding就发挥了非常好的作用,将数字特征转换成稠密向量,向量之间的距离反映了对象之间的相似性。相似性低的对象之间,距离一般较大。这个时候,Embedding后的稠密特征就可以很好的表示当前的特征。
二、推荐系统中常见的Embedding处理方式
1、字符串形式的输入

对于推荐系统而言,输入常常是字符串形式,因为不是矩阵,字符串本身无法被网络直接处理,在推荐系统中,字符串可以通过哈希桶的方式转化成单一数字(hash_bucket),对任意一个字符串,我们都可以将其转化成固定的数字,这个数字处于0到hash_bucket_size之间。
之后在代码中会建立一个可查询的embedding表,他的shape为:
(hash_bucket_size, embedding_dim)
这是一个hash_bucket_size行,embedding_dim列的矩阵,当我们通过一个字符串获得一个固定的数字后,我们会通过这个固定的离散值,获得离散值对应的行。
比如上图的例子中,我们假设hash_bucket_size等于5,embedding_dim等于32。如果输入的字符串为bicycle,我们获得的离散值等于0。我们此时就会获取embedding表的第0行,作为这个特征的embedding。
2、连续值(特定范围值)的输入

除去字符串形式的输入,有些值可能是连续值,比如一个特征的取值范围是1-10,此时连续值类特征可以先使用分箱组件+进行离散化,可以进行等频/等距/自动离散化,变成离散值,此时连续值就变成了存在于特定范围内的离散值。
如果有些值直接存在于特定范围内,那么我们可以直接将其进行规定,举个简单的例子,比如我们现在的物品主要是车辆,那么车辆的种类就可以规定为连续值(特定范围值)的输入。
我们直接就可以将车分为[自行车,越野车,小轿车,公交车,大货车],这里只说了五个,实际上不止这么多,此时,我们就可以设定自行车就是0,越野车就是1,小轿车就是2,公交车就是3,大货车就是4。这样就不会存在hash冲突的问题,几就是几。
如果是连续值,可以先进行离散化,同样是直接进行映射。
之后在代码中会建立一个可查询的embedding表,他的shape为:
(boundaries_size, embedding_dim)
这是一个boundaries_size行,embedding_dim列的矩阵,当我们获得某个个体的cat_id,就可以获得其中第cat_id行。
比如上图的例子中,如果输入的字符串为bicycle,在列表中它的序号为0,此时我们获得的离散值等于0。我们此时就会获取embedding表的第0行,作为这个特征的embedding。
三、Embedding的注意点
一般来讲,尽管Embedding层的工作原理类似于查表的形式,但Embedding表本身也是需要训练的,不训练的话无法保证同一特征的不同值距离较大,embedding的长度一般也不是随便取的,可以通过如下的公式进行计算。其中,x 为不同特征取值的个数:
KaTeX parse error: Undefined control sequence: \ at position 27: …_dim=8+x^{0.25}\̲ ̲
公式参考easyrec文档:
https://easyrec.readthedocs.io/en/latest/feature/feature.html