随着最大的人工智能研究会议(NeurIPS 2022)即将到来,我们进入了2022年的最后阶段。让我们回顾一下人工智能世界最近发生了什么。
在介绍推荐论文之前,先说一个很有意思的项目:
img-to-music:想象图像听起来是什么样的模型! https://huggingface.co/spaces/fffiloni/img-to-music。有兴趣的可以看看。
下面我们开始介绍10篇推荐的论文。这里将涵盖强化学习(RL)、扩散模型、自动驾驶、语言模型等主题。
1、Scaling Instruction-Finetuned Language Models
https://arxiv.org/abs/2210.11416
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay et al.
一年前Google 的 FLAN¹ 展示了如何通过将带标签的 NLP 示例重新表述为自然语言指令并将它们包含在预训练语料库中来提高语言模型 (LM) 的通用性。这篇论文则扩大该技术应用。
OpenAI 著名的 GPT系列的模型的一个成功关键是使用未标记数据进行训练。但这并不意味着自回归 LM 不能使用标记数据进行训练:注释可以注入到模型的训练中而无需任何架构更改。这里的关键思想是:不是让分类头为输入输出标签,而是将带标签的例子重新表述为用自然语言编写的指令。例如,可以将带有标签的情感分类示例转换为具有以下模板的语句:
文本:The film had a terrific plot and magnific acting. 标签[POSITIVE]
改为:
The film [is good because it] had a terrific plot and magnific acting.
这里有一个问题,就是要将零样本性能与 GPT-3 等完全自监督模型进行比较,必须确保评估中使用的任务不包含在训练集中!(也就是数据泄露的问题)
最初的 FLAN 论文在 137B 参数模型上,使用了有来自几十个 NLP 任务的 30k 额外指令展示了这种技术的强大功能。 在本文中,他们通过将 (1) 任务数量扩展到 1836,(2) 模型大小扩展到 540B 参数,以及 (3) 添加思维链提示来进入下一个级别。
结果表明,添加指令会提高性能,尤其是对于较小的模型,但模型规模仍然是最大的因素。

完整的模型在谷歌的Research Github Repository上公开发布:
https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints
2、Recitation-Augmented Language Models
https://arxiv.org/abs/2210.01296
Zhiqing Sun, Xuezhi Wang, Yi Tay, Yiming Yang, and Denny Zhou.
提示技术还在继续扩展预训练的语言模型的能力,而不需要新的复杂的建模技术。
检索增强语言模型(Retrieval Augmented Language Models)³通常从语料库中检索段落,并将它们作为文本附加到提示文本中。这使它们更加高效和正确,但代价是增加了训练和实施的复杂性。
RECITE是语言模型是prompting的一个新版本,通过提示模板使模型在生成答案之前从记忆中找到其训练语料库中的相关段落。通过在包含训练语料库段落的提示中提供示例,模型通常会正确地找到其中的确切段落。
这种方法利用了大型lm的记忆能力,无需从语料库中进行显式检索,提高了回答问题的性能,。与之前现成的高级提示技术chain-of-thought²类似。

但有一个重要的问题!这种方法不会开箱即用。为了让它运行良好通常需要多路径解码⁴,这包括在给定提示的情况下对多个结果进行采样,然后根据多数票选择答案,并且采样更多路径通常会带来更好的性能,但缺点是更高的推理成本。

3、Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
https://arxiv.org/abs/2210.08340
Anthony Zador and 26 other renowned researchers in AI and Neuroscience.
人工智能的创始人物,如Turin 或Minsky,是出于对大脑如何工作以及机器如何复制大脑的方向进行研究的。相比之下现代 ML 从业者大多是以计算机科学家、逻辑学家和统计学家的身份思考,与大脑工作原理的研究脱节。该领域会从更紧密的合作中受益吗?
更好地了解大脑将提供对如何构建智能机器的见解的想法并不新鲜,因为人脑和人工智能从一开始就联系在一起的。这个理论强调了人工智能的现有挑战,特别是在以合理的方式与世界互动方面。尽管语言是经常描绘成人类智慧的顶峰,但学习人类感官能力还远未解决,但自然语言生成一直有惊人的进展。
更好地理解神经计算将揭示智能的基本成分,并催化人工智能的下一次革命。
作为对这一挑战的回应,论文的作者建议将具象图灵测试作为原始图灵测试的继承者:一个更全面的测试,包括评估除显式推理能力外的感官技能。
解决下一代图灵测试的路线图依赖于3个主要支柱。(1)一个对两个领域同等重视的人工智能课程,这样新一代的人工智能研究人员就像对待神经科学一样对待计算机科学,(2)一个测试代理的共享平台,(3)增加对神经计算基础理论研究的资助。
4、You Only Live Once: Single-Life Reinforcement Learning
https://arxiv.org/abs/2210.08863
Annie S. Chen, Archit Sharma, Sergey Levine, and Chelsea Finn.
代理在部署时能否即时适应新环境?对于需要代理在看不见的环境中表现良好的问题,情景强化学习可能不是一个合适的框架。
论文作者制定了一个强化学习的形式,这是一种在看不见的环境中测试代理运行效果的范例。作者还提出了一种新算法,即 Q 加权对抗性学习 (QWALE),它使用“distribution matching”来利用以前的经验作为新情况下的指导。他们的方法大大优于基线,但与大多数具有范式挑战性的工作一样,目前尚不清楚评估的选择是否是为提出的特定模型量身定制的。
但是无论如何这种 RL 范式与零样本学习和泛化有有趣的相似之处,这些都是 ML 中越来越受欢迎的领域,因为古老的监督学习技术的脆弱性已经被发现。 single-shot RL 会成为 RL 论文中必须包含的新评估机制吗?让我们拭目以待

5、Model-Based Imitation Learning for Urban Driving
https://arxiv.org/abs/2210.07729
Anthony Hu, Gianluca Corrado, Nicolas Griffiths, Zak Murez, Corina Gurau, Hudson Yeo, Alex Kendall, Roberto Cipolla, and Jamie Shotton.
自动驾驶性能的飞跃(在模拟环境中!)
从与世界的互动中在线学习与从演示(模仿学习)中离线学习是RL中最基本的划分之一。广义上讲,前者是稳健但低效的,后者是高效但脆弱的。
本文在CARLA 35模拟器上对模仿学习在自动驾驶中的应用进行了研究。模仿学习的进步特别有用,因为它们可以更好地转化为现实世界所用。在现实世界中在线学习驾驶政策通常是非常危险和昂贵的。没人愿意每一次重置环境就买一辆新车!
论文提出的模型 (MILE) 通过尝试推断哪些潜在特征导致了训练中提供的专家观察结果,从而学习潜在空间中的世界动态。 可以在下图中找到模型工作原理的概述。

MILE在域外评估方面尤其突出:例如数据集中不包含的的城镇道路和天气条件。

6、DreamFusion: Text-to-3D using 2D Diffusion
https://arxiv.org/abs/2209.14988
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall.
扩散模型的迅速崛起超越了以前的简单的文本到图像生成。
3D生成是困难的,因为不像2D图像没有那么多的3D模型来训练端到端3D生成器。在这项工作中,论文作者通过利用现有2D图像生成器来引导3D物体的生成,从而绕过了这一限制。
使用 Score Distillation Sampling(SDS)。这种方法允许将2D文本到图像模型的输出转换为任何参数空间——例如3D模型(只要转换是可微的)。为了从文本合成一个场景,该方法随机初始化一个NeRF模型,并从不同的摄像机位置和角度为该NeRF重复渲染视图,然后使用这些渲染图作为扩散模型+SDS损失的输入再通过NeRF反向传播。这些视图看起来像噪音,但通过足够的扩散步骤,它们最终能够正确地表示3D对象的视图。
官方提供了演示:https://dreamfusion3d.github.io/,还有一个非官方的开源实现:https://github.com/ashawkey/stable-dreamfusion 有兴趣的可以看看,还挺好玩的

7、Imagic: Text-Based Real Image Editing with Diffusion Models
https://arxiv.org/abs/2210.09276
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, Michal Irani.
使用扩散模型进行p图
扩散模型的强大应用又被发现了:可以进行特定的图像编辑,例如条件修复或风格转移。 这项工作展示了对图像应用不受约束的、复杂的、语义相关的、文本引导的编辑的能力。

该技术依赖于在输入图像和目标图像之间的嵌入空间的内插值。首先它们对齐文本和图像嵌入,这样在给定冻结的预训练扩散模型的情况下,相似的嵌入会产生相似的图像生成。然后在对齐嵌入上对扩散模型进行微调,最后对目标和对齐嵌入进行©插值,生成编辑后的图像。

这是一个非常有意思的项目,可惜目前没有找到代码和演示
8、GoalsEye: Learning High-Speed Precision Table Tennis on a Physical Robot
https://arxiv.org/abs/2210.03662
Tianli Ding, Laura Graesser, Saminda Abeyruwan, David B. D’Ambrosio, Anish Shankar, Pierre Sermanet, Pannag R. Sanketi, Corey Lynch.
这是模仿学习的又一展示,它可以将出色的性能转移到物理机器人上。
目前RL的最大挑战之一是让它们在真实世界中工作,而不是在模拟环境中。这一点尤其相关——正如我们刚刚在自动驾驶汽车的论文种所提到的——因为RL中的在线学习通常在物理世界中是不可实现的:它仍然是效率低下的,并且我们的设备会坏太多次。
本文展示了如何使用迭代监督模仿学习来教机器人打网球,即将自我对弈与目标导向行为克隆相结合。论文成功的关键是: (1) 从一个非目标导向的引导数据集开始,该数据集展示了机器人刚刚击球的演示,这样可以改善低效的初始探索阶段。 (2) 然后重新标记目标条件行为复制(例如,记录球的击打方式和落地位置,然后将其用作目标)。 (3) 以击中目标导向的迭代自监督游戏。

9、MTEB: Massive Text Embedding Benchmark
https://arxiv.org/abs/2210.07316
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers.
由于目前已有大量现成的NLP嵌入模型,在其中进行选择已成为一项挑战。这项工作则改善了这个过程。
泛化语言嵌入非常受欢迎的主要原因之一是其方便性:在将文本转换为向量之后,执行诸如分类、语义相似、检索或聚类等NLP任务变得很容易。但是,让一个嵌入来统治所有任务还远远没有实现,这就是为什么对各种任务进行基准测试是为通用用例找到最佳模型的关键。
论文提出的基准由8个嵌入任务组成,覆盖了总共56个数据集和112种语言,并考虑了4个基本原则:
- 多样性(8个任务):分类、聚类、配对分类、重排序、检索、语义文本相似性和摘要。
- 简单性:基准可以通过即插即用的API访问。
- 可扩展性:有一个特定的语法和过程,可以通过HuggingFace hub轻松地向现有基准测试添加新数据集。
- 可复现性:版本控制是该基准的发行版的一个内置特性,使得在基准的任何版本上重新运行任何评估成为可能。
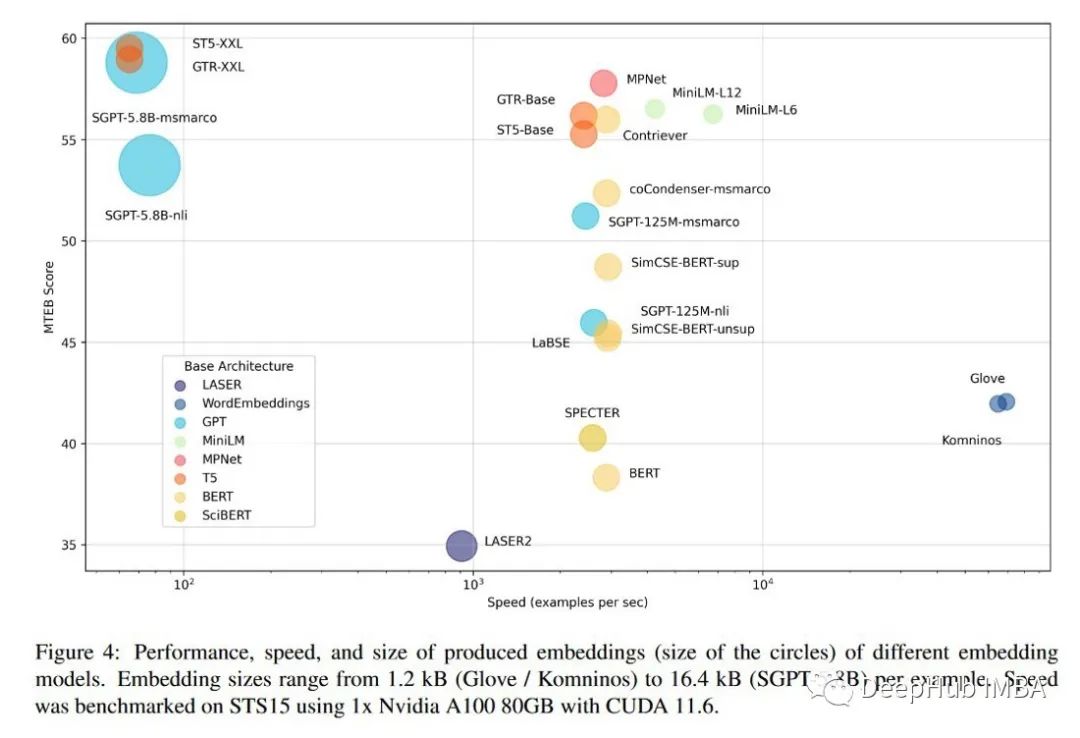
论文结果显示了基于transformer的现代模型如何优于GloVe等经典模型,但也显示了性能如何常常以速度为代价,这对某些应用程序来说是不可接受的。可以在HuggingFace排行榜上查看最新的结果。
https://huggingface.co/spaces/mteb/leaderboard
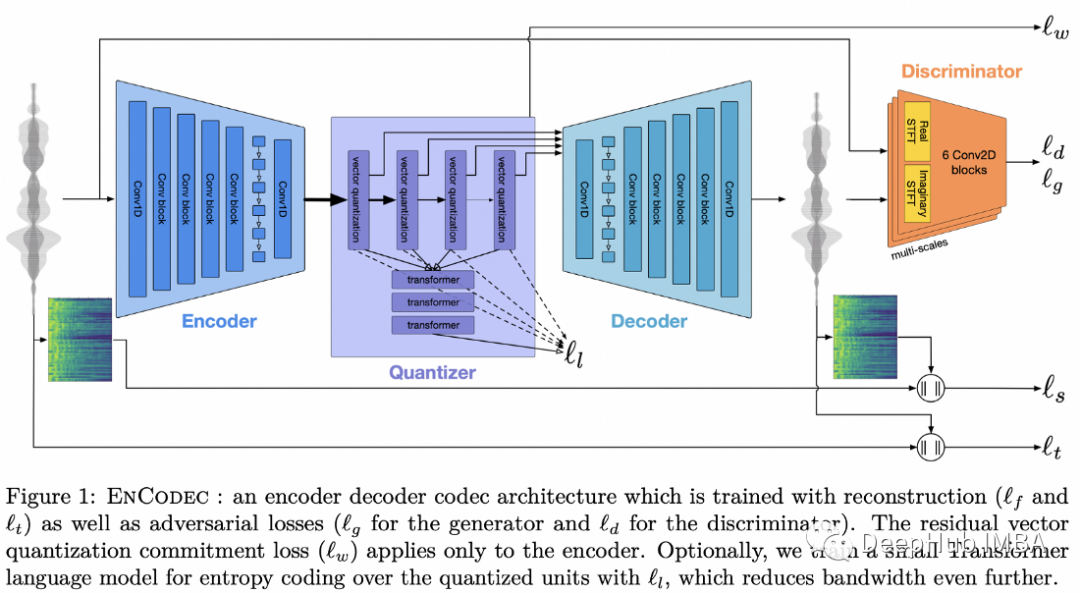
10、High Fidelity Neural Audio Compression
https://arxiv.org/abs/2210.13438
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi.
压缩算法是互联网的面包和黄油。经过多年对神经编解码器的研究,它们不仅在质量上而且在便捷性上都在追赶经典的方案。
Meta提出的压缩音频的方法是由一个量化的自动编码器组成,训练结合了重建和对抗损失。重建损失既存在于原始音频信号上,也存在于mel谱图上,而对抗损失来自于鉴别器,它需要对压缩表示和生成的音频是否相互对应进行分类。最后在量化表示上增加一个额外的正则化损失来防止量化对压缩表示的过度改变。
这个方法不是特别新颖,但却经过了高度优化和并且泛化性非常好,可以在合理的音频质量下实现的压缩增益。音频编码到6kbps,保持与64kbps mp3编解码器相当的质量,而解码大约是10倍的实时因子。
性能并不是影响压缩编解码器的唯一因素,便捷性是经典编解码器难以超越的地方。从Meta关于这项研究的来看,他们认为这是一项关键的使能技术,可以实现他们涉及Metaverse的更广泛的公司使命,所以我们预计该公司将大力推动很快在生产中使用这些模型。
最后本文提到其他论文的引用:
[1] “Finetuned Language Models Are Zero-Shot Learners” by Jason Wei et al, 2021.
[2] “Chain of Thought Prompting Elicits Reasoning in Large Language Models” by Jason Wei et al, 2022.
[3] “REALM: Retrieval-Augmented Language Model Pre-Training” by Kelvin Guu et al. 2020.
[4] “Self-Consistency Improves Chain of Thought Reasoning in Language Models” by Xuezhi Wang et al. 2022.
https://avoid.overfit.cn/post/25ce9e587880476486c151a2920d37e6
作者:Sergi Castella i Sapé



![[附源码]java毕业设计校园快递管理系统](https://img-blog.csdnimg.cn/ddec9ace4fd44ba8af8cb8ff00e612a6.png)