目录
- 深层神经网络
- 1. 异或门问题
- 1.1 异或代码实现
- 2.神经网络的层
- 2.1 去除激活函数的异或门
- 2.2 使用sigmoid函数的异或门
- 3.从0实现深度神经网络的正向传播
深层神经网络
1. 异或门问题
在第一篇的博客中,我们使用代码实现了与门
import torch
X = torch.tensor([[1,0,0],[1,1,0],[1,0,1],[1,1,1]], dtype = torch.float32)
andgate = torch.tensor([0,0,0,1], dtype = torch.float32)
w = torch.tensor([-0.2,0.15,0.15], dtype = torch.float32)
def LogisticR(X,w):
zhat = torch.mv(X,w)
sigma = torch.sigmoid(zhat)
andhat = torch.tensor([int(x) for x in sigma >= 0.5], dtype = torch.float32)
return sigma, andhat
sigma, andhat = LogisticR(X,w)
考虑到与门的数据只有两维,我们可以将数据可视化,其中,特征x1为横坐标,特征x2为纵坐标,紫色点代表了类别0,红色点代表类别1,绘制出来的图如下所示:
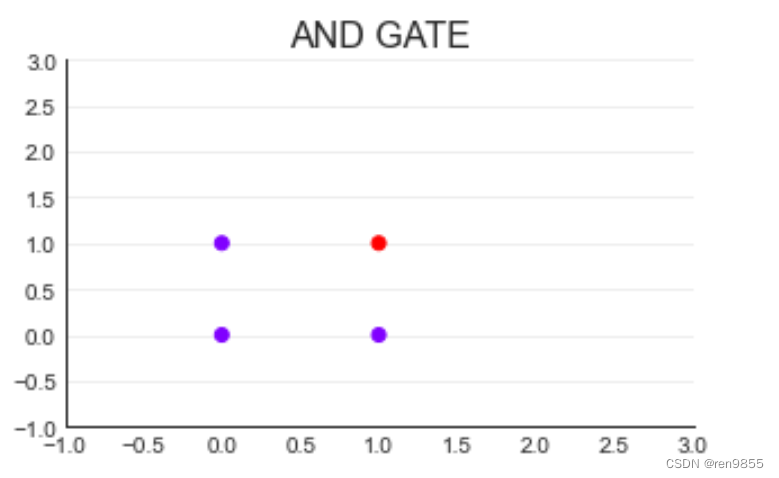
我们可以使用一条直线将紫色和红色的圆点分开,如下图所示:
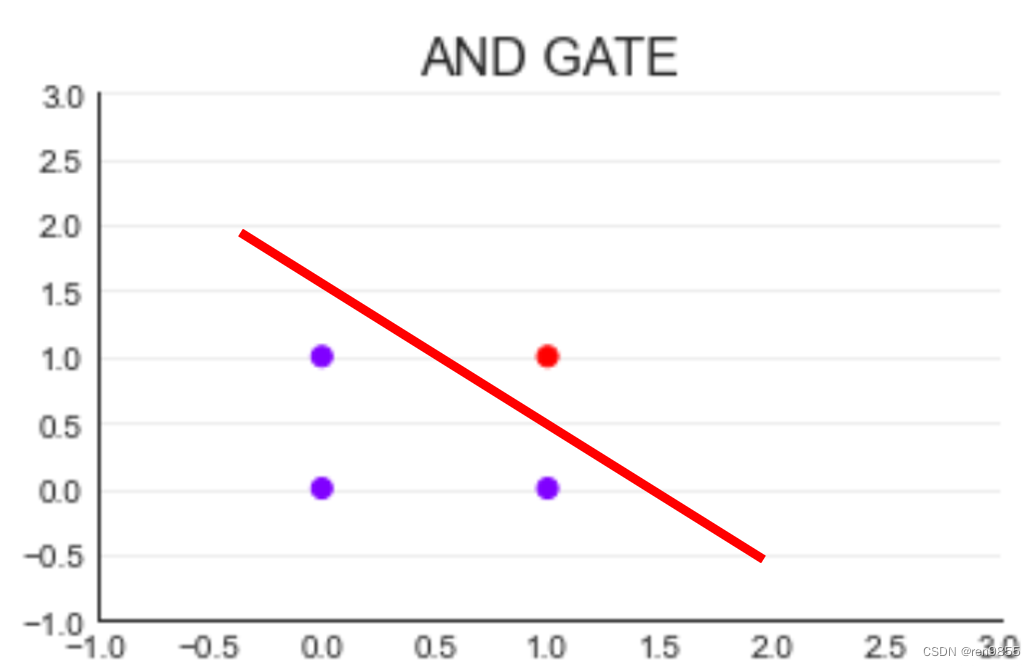
这条具有分类功能直线被我们称为“决策边界”。
但并不是所有的图像都可以用直线来进行分类,如下图的异或门所示:
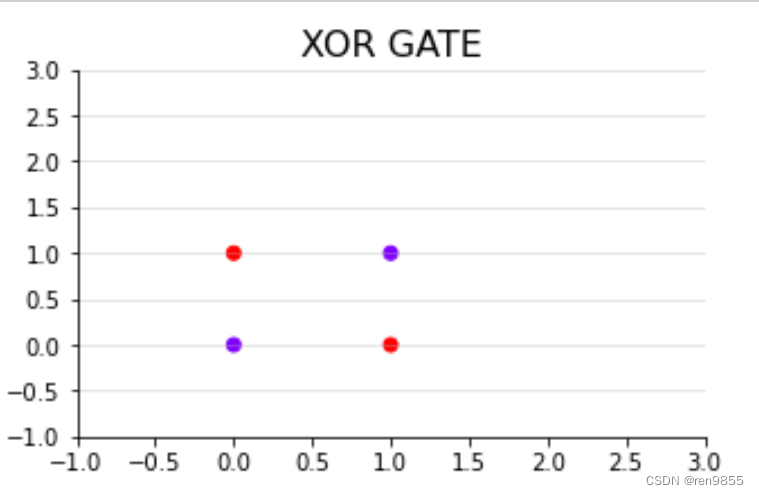
上图没有任意一条直线可以将两类点完美分开,此时我们会需要类似如下的曲线来对数据进行划分.
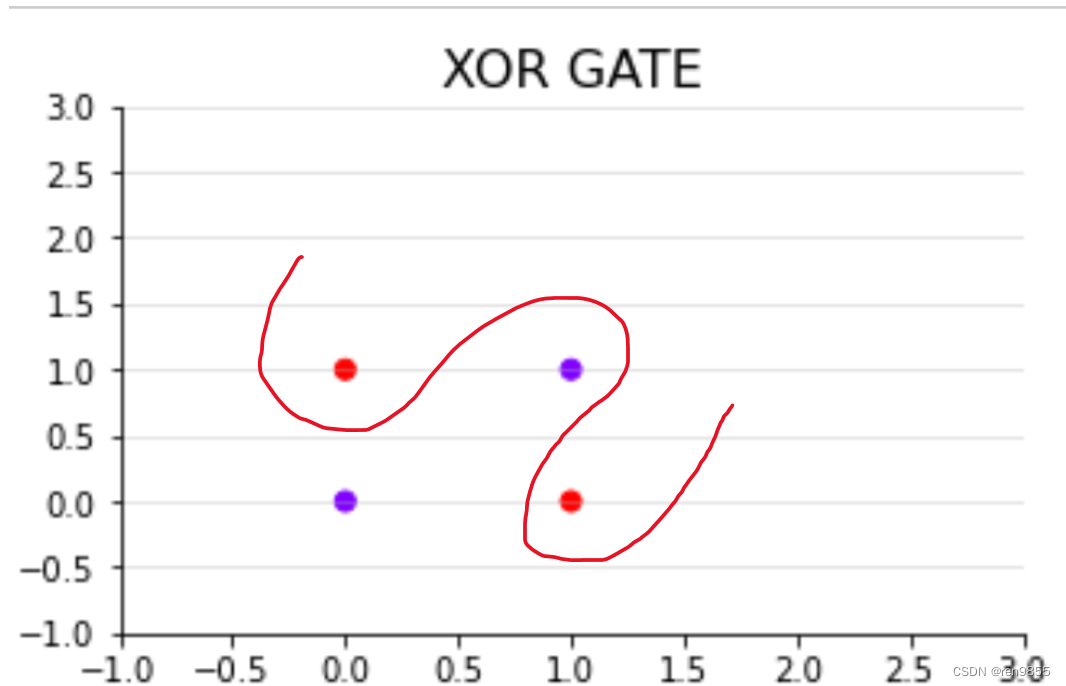
**如何把决策边界从直线转换为曲线,就需要把单层神经网络变成多层**
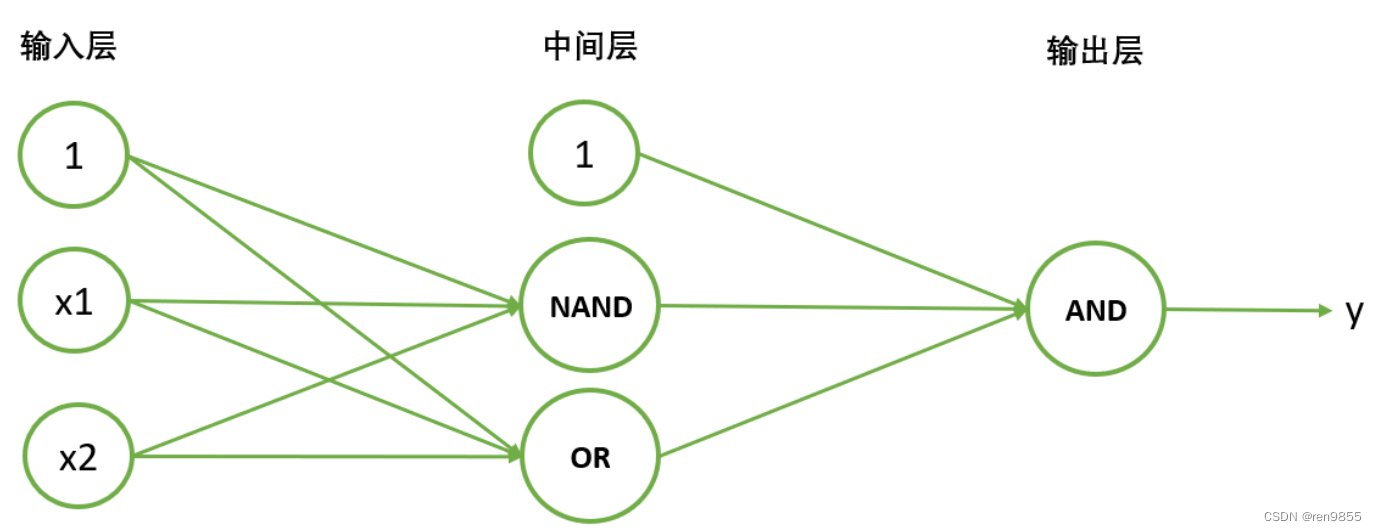
这是一个多层神经网络,除了输入层和输出层,还多了一层“中间层”。
在这个网络中,数据从左侧的输入层进入,特征会分别进入NAND和OR两个中间层的神经元,分别获得NAND函数的结果和OR函数的结果,接着, yNAND和yOR 会继续被输入下一层的神经元AND,经过AND函数的处理,成为最终结果y.
1.1 异或代码实现
import torch
X = torch.tensor([[1,0,0],[1,1,0],[1,0,1],[1,1,1]], dtype = torch.float32)
orgate = torch.tensor([0,1,1,1], dtype = torch.float32)
def OR(X):
w = torch.tensor([-0.08,0.15,0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
yhat = torch.tensor([int(x) for x in zhat >= 0],dtype=torch.float32)
return yhat
def AND(X):
w = torch.tensor([-0.2,0.15, 0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
andhat = torch.tensor([int(x) for x in zhat >= 0],dtype=torch.float32)
return andhat
def NAND(X):
w = torch.tensor([0.23,-0.15,-0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
yhat = torch.tensor([int(x) for x in zhat >= 0],dtype=torch.float32)
return yhat
def XOR(X):
#输入值:
input_1 = X
#中间层:
sigma_nand = NAND(input_1)
sigma_or = OR(input_1)
x0 = torch.tensor([[1],[1],[1],[1]],dtype=torch.float32)
#输出层:
input_2 = torch.cat((x0,sigma_nand.view(4,1),sigma_or.view(4,1)),dim=1)
y_and = AND(input_2)
return y_and
2.神经网络的层
在神经网络的隐藏层中,存在两个关键的元素,一个是加和函数,另一个是h(z)(激活函数) 。
在人工神经网络的神经元上,根据一组输入 定义 该神经元的输出结果的函数,就是激活函数。激活函数一般都是非线性函数,它出现在神经网络中除了输入层以外的每层的每个神经元上.
神经元有“多进单出”的性质,可以一次性输入多个信号,但是输出只能有一个,因此输入神经元的信息必须以某种方式进行整合,否则神经元就无法将信息传递下去,而最容易的整合方式就是加和。
我们可以认为加和是神经元自带的性质,只要增加更多的层,就会有更多的加和。但是激活函数的存在却不是如此,假设隐藏层上没有激活函数的话,输出的结果都会是线性的
2.1 去除激活函数的异或门
import torch
X = torch.tensor([[1,0,0],[1,1,0],[1,0,1],[1,1,1]], dtype = torch.float32)
orgate = torch.tensor([0,1,1,1], dtype = torch.float32)
def OR(X):
w = torch.tensor([-0.08,0.15,0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
# yhat = torch.tensor([int(x) for x in zhat >= 0],dtype=torch.float32)
return yhat
def AND(X):
w = torch.tensor([-0.2,0.15, 0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
andhat = torch.tensor([int(x) for x in zhat >= 0],dtype=torch.float32)
return andhat
def NAND(X):
w = torch.tensor([0.23,-0.15,-0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
# yhat = torch.tensor([int(x) for x in zhat >= 0],dtype=torch.float32)
return yhat
def XOR(X):
#输入值:
input_1 = X
#中间层:
sigma_nand = NAND(input_1)
sigma_or = OR(input_1)
x0 = torch.tensor([[1],[1],[1],[1]],dtype=torch.float32)
#输出层:
input_2 = torch.cat((x0,sigma_nand.view(4,1),sigma_or.view(4,1)),dim=1)
y_and = AND(input_2)
return y_and
y_and=XOR(X)
输出结果:

可见,神经网络的层数本身不是神经网络解决非线性问题的关键,隐藏层上的激活函数才是,如果 h(z)是线性函数,或不存在,那增加再多的层也没有用。
如果换成sigmoid函数,神经网络同样会失效,可见,即便是使用了,也不一定能够解决曲线分类的问题。
在不适合的非线性函数加持下神经网络的层数再多也无法起效。所以,真正能够让神经网络算法“活起来”的关键,是神经网络中的激活函数.
2.2 使用sigmoid函数的异或门
def OR(X):
w = torch.tensor([-0.08,0.15,0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
sigma = torch.sigmoid(zhat)
return sigma
def AND(X):
w = torch.tensor([-0.2,0.15, 0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
sigma = torch.sigmoid(zhat)
return sigma
def NAND(X):
w = torch.tensor([0.23,-0.15,-0.15], dtype = torch.float32)
zhat = torch.mv(X,w)
sigma = torch.sigmoid(zhat)
return sigma
def XOR(X):
#输入值:
input_1 = X
#中间层:
sigma_nand = NAND(input_1)
sigma_or = OR(input_1)
x0 = torch.tensor([[1],[1],[1],[1]],dtype=torch.float32)
#输出层:
input_2 = torch.cat((x0,sigma_nand.view(4,1),sigma_or.view(4,1)),dim=1)
y_and = AND(input_2)
return y_and
输出结果:

3.从0实现深度神经网络的正向传播
假设我们有500条数据,20个特征,标签为3分类。我们现在要实现一个三层神经网络.
这个神经网络的架构如下:第一层有13个神经元,第二层有8个神经元,第三层是输出层。其中,第一层的激活函数是relu,第二层是sigmoid。
import torch
import torch.nn as nn
from torch.nn import functional as F
torch.manual_seed(100)
X=torch.rand((500,20),dtype=torch.float32)
y=torch.randint(low=0,high=3,size=(500,1),dtype=torch.float32)
class Model(nn.Module):
def __init__(self,in_features=10,out_features=2):
super(Model,self).__init__()
self.linear1=nn.Linear(in_features,13,bias=True)
self.linear2=nn.Linear(13,8,bias=True)
self.output = nn.Linear(8,out_features,bias=True)
def forward(self,x):
z1=self.linear1(x)
sigma1=torch.relu(z1)
z2=self.linear2(sigma1)
sigma2=torch.sigmoid(z2)
z3 = self.output(sigma2)
sigma3=F.softmax(z3,dim=1)
return sigma3
input_ = X.shape[1] #特征的数目
output_ = len(y.unique()) #分类的数目
torch.manual_seed(420)
net = Model(in_features=input_, out_features=output_)
net(X)