目录
一、什么是索引
二、索引由来
三、索引本质
四、索引数据结构
1、hsah
2、B+tree
五、myISAM 和Innodb这两个数据库的索引是如何实现的呢?
1、首先看 MYSAM
1、以主键Id字段建立索引
2、以name字段来建立索引
2、在看Innodb数据库引擎的数据库
1、以主键id字段建立索引
2、以及name字段来建立索引
3、为什么要用自增ID作为主键呢?
六、索引分类
七、索引优缺点
八、索引的设计原则
九、索引相关问题
一、什么是索引
肯定是一个数据结构,帮助高效获取数据的数据结构
作用:
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容,提高性能(查询速度)。
官方介绍:What is Indexx?
- 索引是帮助高效获取数据的数据结构
- 索引也可能是一个文件
- 其他类型
-hash Map
-二叉树
-红黑树
二、索引由来
数据库数据最终是存在文件中
因此数据库底层是一个文件系统
当我们查询时
table
| id | name |
| 1 | zhangsan |
| 2 | lisi |
| 3 | wanger |
文件
Raw
select * from table where id=1;

我们的数据库表就是在ibd文件格式中的,当我们查询数据库时,就是去通过IO 流获取本地文件,通过柱面,磁道,扇面三个维度来找到我们要查询的数据,比如右边红色就代表我们的table.ibd表,当开始读时,就去扫描这个表获取数据。
上面这个是机械运动
如果在我们的内存总线中去读,他是非常快的,因为他是一个电信号,而我们如果要到磁盘去读,他就是一个机械运动,他们差两个数量集,所以说IO贵,所以常说避免IO
所以索引从操作系统层面他有哪些优化呢?
操作系统有一个概念:page
page他基于两个原理:
- 时间局部性原理
- 空间局部性原理
在CPU访问寄存器时,无论是存取数据亦或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
1、时间局部性(temporal locality)
时间局部性指的是:被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
2、空间局部性(spatial locality)
如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
都说IO贵,那么我们一下子读四块还不行吗?

可以简单理解为四条数据。
那么我们就不需要读四次。
读完把他放入内存中。
那么怎么理解时间局部性和空间局部性呢?
就是一个概率问题
在此基础上提出了page概念,来提高我们读取的性能
基于刚刚的认知,基于文件系统给我们打了个样
我们是不是可以建一个这样的索引,什么样的索引呢?
基于ID建一个索引

那么这个索引就是一个数据结构,做了两个维度,一个是ID 一个是地址 1是ID,0x12是地址。
当我们在查询的时候
select * from table where id =1;
就不用在磁盘所在的区域从头去读,直接找到。
这就是我们最原始索引概念的由来,基于文件系统。类比抽象出来的。
这就是索引
三、索引本质
索引也是一个文件,为什么呢?
因为他是存储数据的嘛,当他存储的数据够大的时候,不可能一直存储在我们的内存当中,所以可能也是一个文件存储。比如下面的MYI文件

四、索引数据结构
还支持其他类型数据结构的索引:
Hash ,红黑,二叉树他们也可以来做索引。
1、hsah
哈希索引的优势:
(1)等值查询。哈希索引具有绝对优势(前提是:没有大量重复键值,如果大量重复键值时,哈希索引的效率很低,因为存在所谓的哈希碰撞问题。)
哈希索引不适用的场景:
(1)不支持范围查询
(2)不支持索引完成排序
(3)不支持联合索引的最左前缀匹配规则
Hash索引的弊端
一般来说,索引的检索效率非常高,可以一次定位,不像B-Tree索引需要进行从根节点到叶节点的多次IO操作。有利必有弊,Hash算法在索引的应用也有很多弊端。
a、Hash索引仅仅能满足等值的查询,范围查询不保证结果正确。因为数据在经过Hash算法后,其大小关系就可能发生变化。
b、Hash索引不能被排序。同样是因为数据经过Hash算法后,大小关系就可能发生变化,排序是没有意义的。
c、Hash索引不能避免表数据的扫描。因为发生Hash碰撞时,仅仅比较Hash值是不够的,需要比较实际的值以判定是否符合要求。
d、Hash索引在发生大量Hash值相同的情况时性能不一定比B-Tree索引高。因为碰撞情况会导致多次的表数据的扫描,造成整体性能的低下,可以通过采用合适的Hash算法一定程度解决这个问题。
e、Hash索引不能使用部分索引键查询。因为当使用组合索引情况时,是把多个数据库列数据合并后再计算Hash值,所以对单独列数据计算Hash值是没有意义的。
2、B+tree
2、为什么要用B+tree 来存储我们的索引呢?
因为数据库底层是有一个engine(数据库引擎)概念,不同的engin底层实现也是不一样的.
今天所将的myISAM 和Innodb为什么用的是B+tree,而不用上面所讲的Hash,红黑等等这些结构呢?
比如hash 只能针对部分查询,范围查询没法实现
判断好的索引依据是:IO渐进复杂度
理解B tree和B+tree

Btree是一个二元组 ,每个node数据节点都是一个二元组,有一个key和data, 2是key,绿色是data,key是主键,data是整个数据
2是key,绿色是data,key是主键,data是整个数据
B+tree的区别就是:不是每个节点都会存储数据的,他的数据会存储在我们的叶子节点上,
第二个点是,我们相邻的叶子节点都是有指向的,但并不是每个B+tree都有,这里是在mysql做了处理。好处是,可以做hash做不了的事,范围查询,比如:大于。(那么怎么处理小于?)
五、myISAM 和Innodb这两个数据库的索引是如何实现的呢?
myISAM 和Innodb的底层到底是怎么存储的?
打开我们本地安装文件

我们分别建立一个test表,但产生的文件却不同?为什么呢?

1、首先看 MYSAM
我们的MYI文件字面上降的就是我们index(索引)文件; MYD文件是data文件,FRM是我们原始数据文件。
MYSAM的底层是由我们B+tree存储我们的索引的。
那么MYI就是一个B+tree,那么他是怎么来存储数据的呢?
1、以主键Id字段建立索引

如果MYD表中有索引,我们的MYI就有内容。如果我们建一个以ID为索引的时候,就会在MYI建立一个以ID为索引的B+tree。结构如上图,那么B+tree的叶子节点就是来存储数据的。是存的地址,这就是我们建立索引情况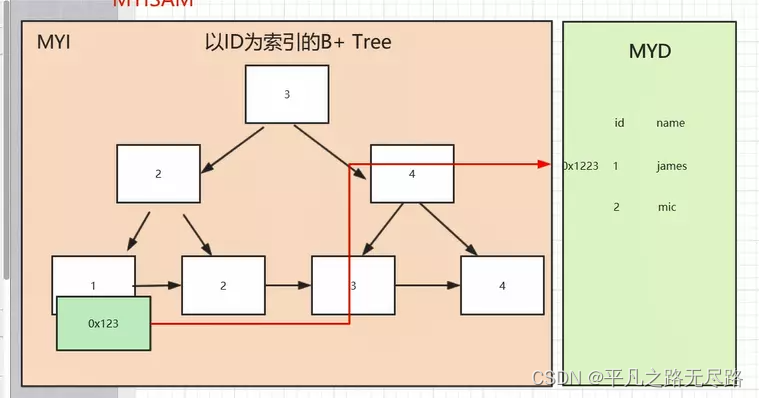
当执行上面查询的时候,查询过程就是先判断MYI里面是否有,基于ID建立的索引,如果找到了,他就会根据从开始节点开始找,然后找到1这个叶子节点,就找到了。然后根据key对应的地址,去表中找ID等于1的数据。这个就是检索的过程。

像这样的索引,他有一个名字:叫非聚集索引。
2、以name字段来建立索引


这个就是以name为索引,组织的一个树,以name为节点的树,同样的,只有叶子节点才存储数据。同理叶子节点也是指向一个地址的。

![]()
查询时跟上面id过程一样。
这个就是MYSAM底层的数据存储。当存储一个简单的表时,他的底层结构就是这样的,
他的底层是非聚集索引。
2、在看Innodb数据库引擎的数据库
![]()
他产生的表文件只有两个?为什么呢?看起来好像没有index文件的感觉。为什么他不需要这样一个东西呢?
InnoDB底层是聚集索引,什么是聚集索引的,就是说他没有索引,或者没有MYI文件。
他只有一个IBD文件,它里面的数据是怎么存储的呢?如下
1、以主键id字段建立索引

为什么叫聚集索引?因为他是以主键为索引来组织数据的,他的叶子节点是存储整个数据的
innoDB数据是可以不建主键的,如果我们没有建立,数据库底层会帮我们去默认生成一个。
为什么我们用的时候一定要建立呢?是因为mysql连接器客户端自己做了校验。必须我们去建立所以,我们以为一定要建立主键。
这就是聚合索引,这就是为什么只有两个文件,因为我们本身存储数据的树就是一个索引。
2、以及name字段来建立索引
这时候我们叶子节点存储的数据是主键。为什么呢?

因为他是一个聚集索引。所以这里不再需要地址去查找数据,他们在一个文件中,不需要地址。
![]()
查询时,去看name是不是索引,如果是,就去找到james所在的主键,然后就去我们的树上这里面找到主键对应的数据。

3、为什么要用自增ID作为主键呢?
因为和UUID比,查询检索的时候,字符串比较和数字比较那个效率更快。
还有就是插入的时候,uuid是按字母排序,他的每个节点都会重组,重新排序,你要插入某个节点,就要别人给你挪位置等等。而数字,都会在最右边追加,而且每次都是填满每个空间,连续的,不会再由变更,而且是顺序读写,由kafka可知顺序读写是最快的。效率也相对高。如图
六、索引分类
分类:聚集索引和非聚集索引
使用索引分类:
1)普通索引:不附加任何限制条件,可创建在任何数据类型中,其值是否唯一和非空由字段本 身的完整性约束条件决定。
2)唯一性索引:使用UNIQUE参数设置索引。索引的值是唯一的。
3)全文索引:使用FULLTEXT参数设置索引。只能创建在CHAR、VARCHAR或TEXT类型字段上。查询数据量较大的字符串类型的字段时,使用全文索引可提高查询速度。
4)单列索引:在表中的单个字段上创建索引。只根据该字段进行索引(索引对应一个字段)。单列索引可以是普通索引或者唯一性索引或者全文索引。
5)多列索引:在表的多个字段上创建一个索引。可通过几个字段进行查询。
只有查询条件使用多列关键字最左边的前缀时,才可以使用索引,否则将不能使用索引。
6)空间索引:使用SPATIAL参数设置。
只能建立在空间数据类型上,可提高系统获取空间数据的效率。
只有MyISAM存储引擎支持空间检索,索引字段不为空。
七、索引优缺点
优点:
1.通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
2.可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
3.可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
4.在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
5.通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
2.索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚集索引那么需要的空间就会更大。
3.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
因为索引非常占内存,所以索引也需要谨慎添加,那些字段需要索引。
八、索引的设计原则
1)选择唯一性索引。索引的列的基数越大,索引效果越好。
2)为经常需要排序、分组和联合操作的字段建立索引(避免排序操作,浪费时间)
3)为常作为查询条件的字段建立索引(提高查询速度)
4)限制索引的数目,不要过度索引(每个索引都需要占用磁盘空间,会降低写操作的性能。)
5)尽量使用短索引。如果对字符串进行索引,应该指定一个前缀长度。
6)尽量使用左前缀来索引(字段值很长,使用值的前缀索引)
7)删除不再使用或者很少使用的索引(减少索引对更新操作的影响)
8)对于InnoDB存储引擎的表,记录默认会按照一定的顺序保存。
InnoDB表的普通索引会保存主键的键值,主键应选择较短的数据类型,减少索引的磁盘占用,提高索引的缓存效果。
9)辅助索引,叶子结点存放着索引字段的值及对应的主键值
10)对查询where条件中区分度高的字段加索引;对查询分组和排序分组加索引。
11)一下情况无法使用到索引:like通配符在最左,not in, !=, <>, 队列做函数运算, 隐式数据类型转换,OR子句。
12)FORCE INDEX强制加索引
数据库-sql执行深度剖析以及redo log和undo log(下)(二)_平凡之路无尽路的博客-CSDN博客