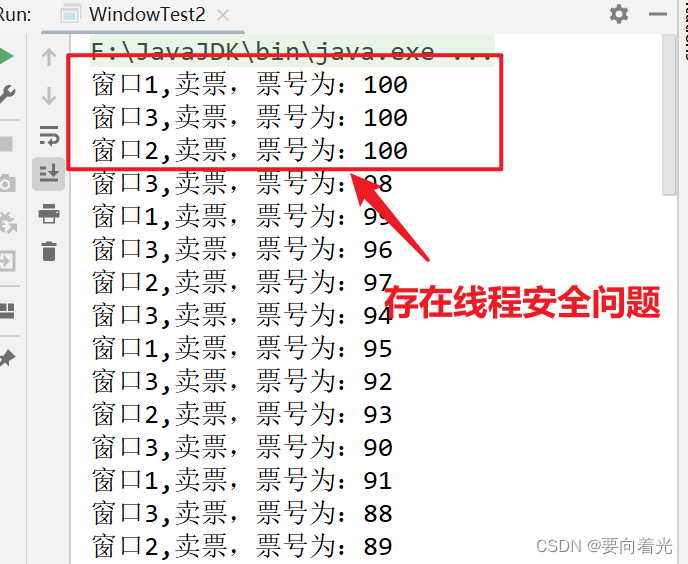
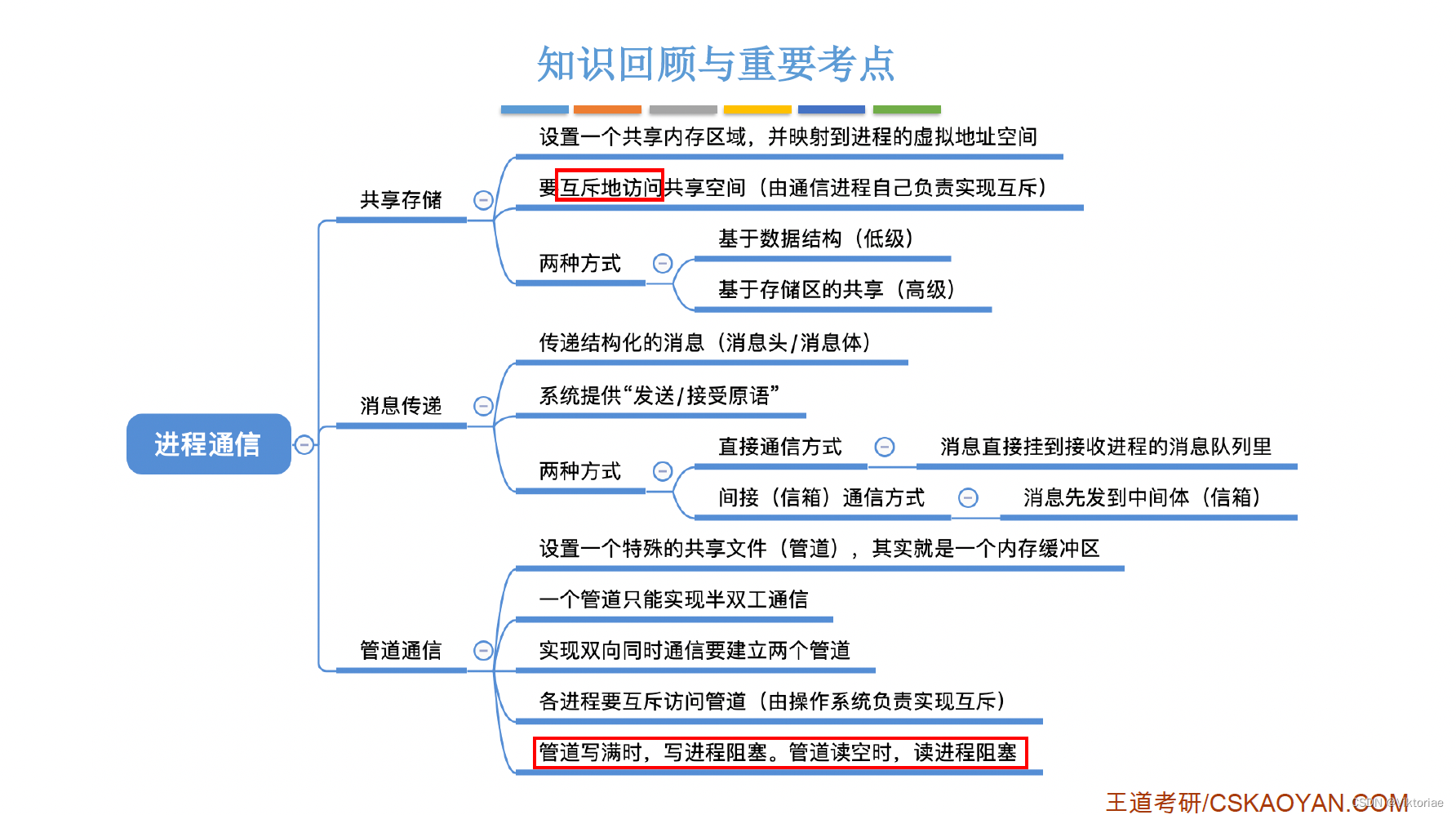
一种词库的比对、保存方式
词库以树状链表存储,示意图如下:
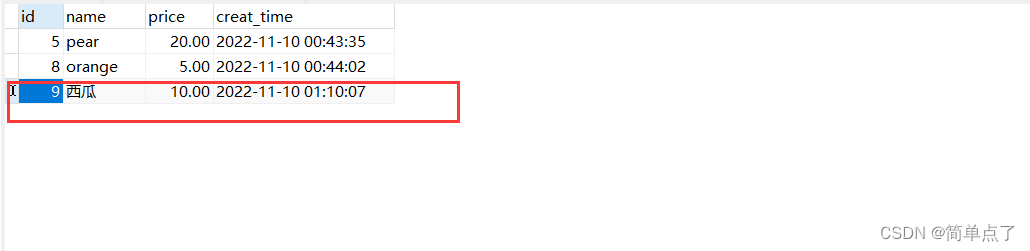
对于词库:{A,AB,ABC,ADE}可以按以下方式存储
注:每个链表在末尾添加\0表示结束

1 数组形式存储的空间复杂度为O(N^2) 即O(N*M) -N为敏感词长度,M是敏感词个数
2 而用这个树状链表 空间复杂度为 O( N) 即O( K*N) -k为字符种类数为常数,N敏感词长度。
在检索时:
1 数组形式检索 时间复杂度为 O(N^3);
这时用三重循环
- 第一重 是遍历文章,
- 第二重 是从第i个字出发,与之后j个字组成词。
- 第三重 是将词与敏感词比对。
2 将文章和树状链表的关键词比对,时间复杂度为 O(f(N^2))
详细为O(f(K*N*M)) K为常数,是单个字符的种类数;N是文章的字数,M是关键词的长度
算法采用两重循环:
- 第一重 是遍历文章
- 第二重 是同时从文章第i位开始和 和树状链表的中 同时提取出j长度的词来对比。
具体代码如下:
树状链表如下:
public class WordNode
{
public char word;
public List<WordNode> children;
}比对方法如下:
/// <summary>
/// 查找敏感词
/// </summary>
/// <param name="txt">要处理的文章</param>
/// <returns>处理后的文章</returns>
public string HandleTxt(string txt)
{
_txt_Compare = txt;
for (int i = 0; i < txt.Length; i++)
{
int len = IsMacthTree2(i, _wordTree);
if (len > 0)
{
// 对i开始,长度len的敏感词处理。
}
}
return txt;
}
/// <summary>
/// 树状结构的敏感词库
/// </summary>
private List<WordNode> _wordTree
{
get; set;
}
// 用于递归比较方法中的 记录文章变量。用索引分割,避免递归中截取大量字符变量
private string _txt_Compare;
/// <summary>
/// 检测文本中是否存在敏感词
/// </summary>
/// <param name="txtStart">从文章的txtStart位开始匹配</param>
/// <param name="tree">敏感词库</param>
/// <returns>敏感词长度</returns>
private int IsMacthTree(int txtStart, List<WordNode> tree)
{
// txtStart 已经位于文章结束位置。即文章已经检查完。
if (txtStart > _txt_Compare.Length - 1)
return 0;
// 在最大K常量的数组中查找
int idx = tree.FindIndex(t => t.word == _txt_Compare[txtStart]);
// 字不匹配,也就是:abe abc 这种情况
if (idx == -1)
{
return 0;// 这轮递归,没有匹配
}
// 如果有\0 即敏感词比对结束
if (tree[idx].children[0] == Thesaurus.EndSign)
{
return 1; // 这轮递归,匹配了一个字
}
// 文字或关键字未结束,也就是:ab* ab* 这种情况,继续递归
int templen = IsMacthTree2(txtStart + 1, tree[idx].children);
// 有一个不匹配 就固定为0
if (templen == 0)
{
return 0; //匹配失败
}
else
{
return 1 + templen; // 递归匹配成功,然后加上本轮匹配的一个字再返回。
}
}