wy的leetcode刷题记录_Day47
声明
本文章的所有题目信息都来源于leetcode
如有侵权请联系我删掉!
时间:2022-11-20
前言
补
目录
- wy的leetcode刷题记录_Day47
- 声明
- 前言
- 799. 香槟塔
- 题目介绍
- 思路
- 代码
- 收获
- 105. 从前序与中序遍历序列构造二叉树
- 题目介绍
- 思路
- 代码
- 收获
799. 香槟塔
今天的每日一题是:799. 香槟塔
题目介绍
我们把玻璃杯摆成金字塔的形状,其中 第一层 有 1 个玻璃杯, 第二层 有 2 个,依次类推到第 100 层,每个玻璃杯 (250ml) 将盛有香槟。
从顶层的第一个玻璃杯开始倾倒一些香槟,当顶层的杯子满了,任何溢出的香槟都会立刻等流量的流向左右两侧的玻璃杯。当左右两边的杯子也满了,就会等流量的流向它们左右两边的杯子,依次类推。(当最底层的玻璃杯满了,香槟会流到地板上)
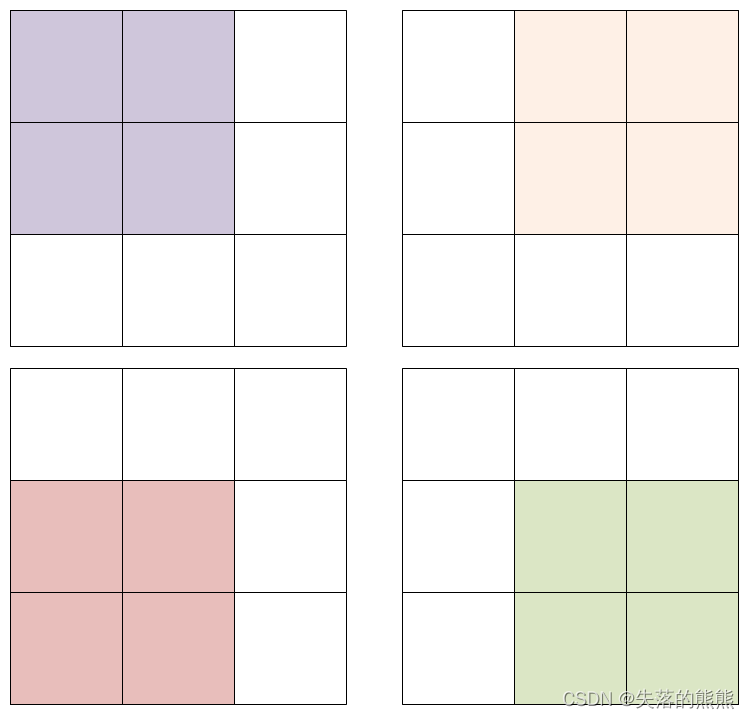
例如,在倾倒一杯香槟后,最顶层的玻璃杯满了。倾倒了两杯香槟后,第二层的两个玻璃杯各自盛放一半的香槟。在倒三杯香槟后,第二层的香槟满了 - 此时总共有三个满的玻璃杯。在倒第四杯后,第三层中间的玻璃杯盛放了一半的香槟,他两边的玻璃杯各自盛放了四分之一的香槟,如下图所示。
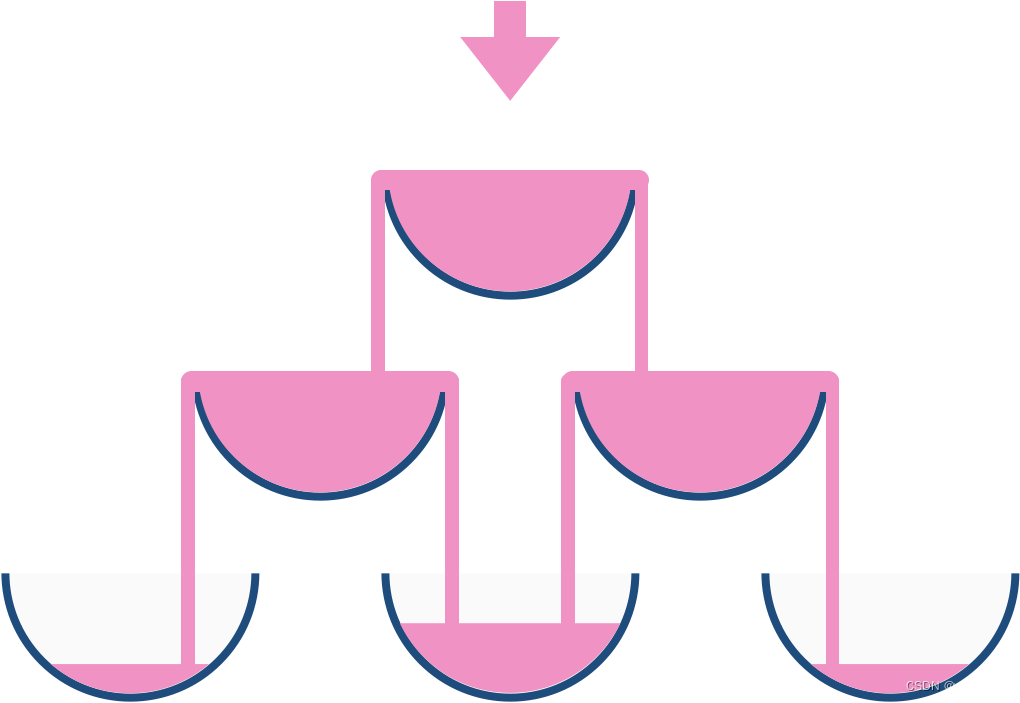
现在当倾倒了非负整数杯香槟后,返回第 i 行 j 个玻璃杯所盛放的香槟占玻璃杯容积的比例( i 和 j 都从0开始)。
示例 1:
输入: poured(倾倒香槟总杯数) = 1, query_glass(杯子的位置数) = 1, query_row(行数)= 1
输出: 0.00000
解释: 我们在顶层(下标是(0,0))倒了一杯香槟后,没有溢出,因此所有在顶层以下的玻璃杯都是空的。
示例 2:
输入: poured(倾倒香槟总杯数) = 2, query_glass(杯子的位置数) = 1, query_row(行数)= 1
输出: 0.50000
解释: 我们在顶层(下标是(0,0)倒了两杯香槟后,有一杯量的香槟将从顶层溢出,位于(1,0)的玻璃杯和(1,1)的玻璃杯平分了这一杯香槟,所以每个玻璃杯有一半的香槟。
思路
方法一:简单模拟思路(线性DP):首先我们将所有的香槟全部导入最上面那一层。然后往下流到下一层,这里的操作就是将将上一层杯子的容量-1\2然后赋值给下面那一层接住他流出的香槟的那个杯子。依次类推,特别注意的是位于每一层起始位置和结束位置的杯子,只能接收上一层一个杯子(也是最边上的)流出的香槟,而中间的杯子可以接收上一层的俩个杯子(处于中间)。
代码
class Solution {
public:
double champagneTower(int poured, int query_row, int query_glass) {
vector<double> count={(double)poured};//上一层的余量 可以>1的 相当于递归 从这个杯子开始有这么多的量往下倒
for(int i=1;i<=query_row;i++){
vector<double> arr(i+1);
arr[0]=max(0.0,count[0]-1)/2;
arr[i]=max(0.0,count[i-1]-1)/2;
for(int j=1;j<i;j++)
{
arr[j]=(max(0.0,count[j-1]-1)+max(0.0,count[j]-1))/2;
}
count=arr;
}
return min(1.0,count[query_glass]);
}
};
收获
简单模拟题,需要读通题意,一开始没理解题目就以为每一层的每个杯子都是来着上面一层的俩个杯子的香槟,然后一直想着用数学方法搞定…
105. 从前序与中序遍历序列构造二叉树
105. 从前序与中序遍历序列构造二叉树
题目介绍
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出:[3,9,20,null,null,15,7]
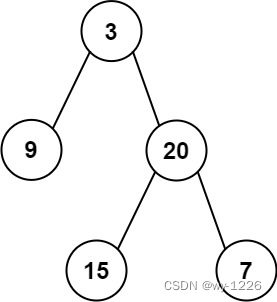
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
思路
跟昨天的根据中后序来构造树一样,关于中序的特征我就不说了,对于前序序列来说第一个元素就是本序列所代表的树的根节点,于是后续过程其实就跟后序序列一样了,将前序序列中的第一个元素切割掉,然后根据中序序列中寻找出来的左子树和右子树序列的长度按顺序分割前序序列。
代码
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if(preorder.size()==0||inorder.size()==0)
return nullptr;
return travel(inorder, 0, inorder.size(), preorder, 0, preorder.size());
}
TreeNode* travel (vector<int>& inorder, int inorderBegin, int inorderEnd,vector<int>& preorder, int preorderBegin, int preorderEnd) {
if (preorderBegin == preorderEnd)
return NULL;
int rootValue = preorder[preorderBegin]; // 注意⽤preorderBegin 不要⽤0
TreeNode* root = new TreeNode(rootValue);
if (preorderEnd - preorderBegin == 1)
return root;
int delimiterIndex;
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd;delimiterIndex++)
{
if (inorder[delimiterIndex] == rootValue)
break;
}
// 切割中序数组
// 中序左区间,左闭右开[leftInorderBegin, leftInorderEnd)
int leftInorderBegin = inorderBegin;
int leftInorderEnd = delimiterIndex;
// 中序右区间,左闭右开[rightInorderBegin, rightInorderEnd)
int rightInorderBegin = delimiterIndex + 1;
int rightInorderEnd = inorderEnd;
// 切割前序数组
// 前序左区间,左闭右开[leftPreorderBegin, leftPreorderEnd)
int leftPreorderBegin = preorderBegin + 1;
int leftPreorderEnd = preorderBegin + 1 + delimiterIndex - inorderBegin; // 终⽌位置是起始位置加上中序左区间的⼤⼩size
// 前序右区间, 左闭右开[rightPreorderBegin, rightPreorderEnd)
int rightPreorderBegin = preorderBegin + 1 + (delimiterIndex - inorderBegin);
int rightPreorderEnd = preorderEnd;
root->left = travel(inorder, leftInorderBegin, leftInorderEnd, preorder,leftPreorderBegin, leftPreorderEnd);
root->right = travel(inorder, rightInorderBegin, rightInorderEnd, preorder,rightPreorderBegin, rightPreorderEnd);
return root;
}
};
收获
更加深入的了解了前序遍历的一个过程,以及其生成的前序序列的特点。