深入理解Kafka服务端之索引文件及mmap内存映射 - 墨天轮
一、场景分析
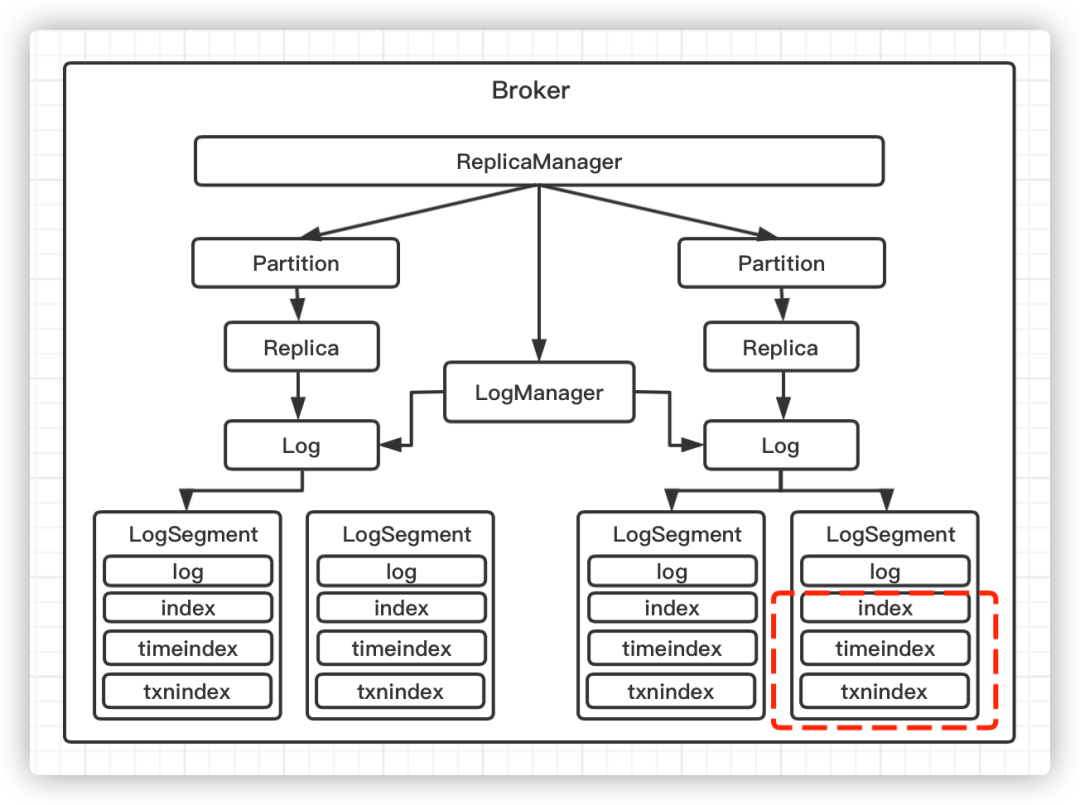
Kafka在滚动生成新日志段的时候,除了生成日志文件(.log),会同时生成一个偏移量索引文件(.index)、一个时间戳索引文件(.timeindex)和一个已中止事务索引文件(.txnindex)。
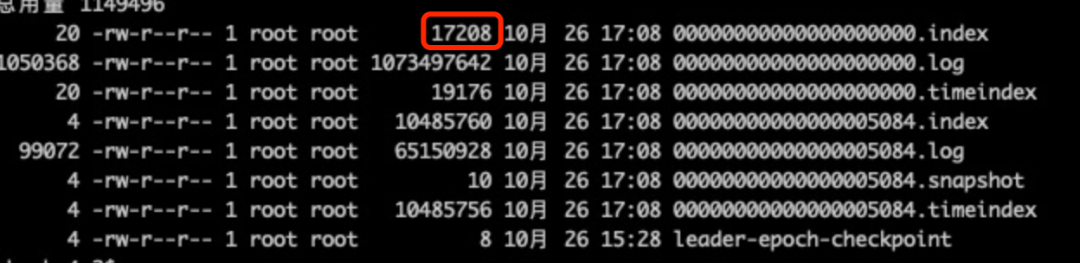
由于索引写入采用的是稀疏索引的方式:即每满足一定条件时写入一个索引项。按理说,索引文件的大小应该远小于日志文件,但是在查看实际文件的时候,发现了一个问题:对于一个新创建的日志段,对应的索引文件要远大于日志文件;而对于一个日志文件已经写满(默认1G)的日志段,索引文件又会变的很小,如下图:

既然是日志索引相关的问题,正好以此来分析存储模块下的索引文件:
二、问题解决
从问题来看,滚动生成新日志段时,新生成的索引文件较大,那么还是看滚动的方法:Log.roll()。
当newOffset为正常值时,对应的处理分支为:
//代码走这里说明newOffset正常val offsetIdxFile = offsetIndexFile(dir, newOffset)//生成index文件val timeIdxFile = timeIndexFile(dir, newOffset)//生成timeindex文件val txnIdxFile = transactionIndexFile(dir, newOffset)//生成txnindex文件//如果文件已存在则删除for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if file.exists) {warn(s"Newly rolled segment file ${file.getAbsolutePath} already exists; deleting it first")Files.delete(file.toPath)}Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())
生成对应的索引文件,并判断日志文件和索引文件是否已经存在,如果存在则先进行删除。
Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())
这里segments保存的是起始偏移量和对应日志段对象的key-value对,获取最后一个日志段对象,即滚动之前的active日志段对象,调用其onBecomeInactiveSegment()方法:
def onBecomeInactiveSegment() {timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar, skipFullCheck = true)offsetIndex.trimToValidSize()timeIndex.trimToValidSize()log.trim()}
这个方法首先会将当前最大时间戳和对应的偏移量作为索引项写入时间戳索引文件,然后对偏移量索引文件、时间戳索引文件、日志文件进行裁剪。
其中:
日志文件进行裁剪调用了FileRecord.trim(),并最终通过truncateTo()调整FileChannel大小为日志文件实际大小。
public void trim() throws IOException {truncateTo(sizeInBytes());}
索引文件进行裁剪调用的是其抽象父类AbstractIndex.trimToValidSize(),并最终通过resize()将索引文件的大小调整为实际值:
def trimToValidSize() {inLock(lock) {//这里的_entries就是这个索引文件中索引项的数量//entrySize是索引项占用字节数。偏移量索引占用8字节,时间戳索引占用12字节resize(entrySize * _entries)}}
这里看一下resize()方法,该方法的注释和代码如下:
/*** Reset the size of the memory map and the underneath file. This is used in two kinds of cases: (1) in* trimToValidSize() which is called at closing the segment or new segment being rolled; (2) at* loading segments from disk or truncating back to an old segment where a new log segment became active;* we want to reset the index size to maximum index size to avoid rolling new segment.*/def resize(newSize: Int): Boolean = {inLock(lock) {//将给定的newSize调整为entrySize的整数倍val roundedNewSize = roundDownToExactMultiple(newSize, entrySize)if (_length == roundedNewSize) {debug(s"Index ${file.getAbsolutePath} was not resized because it already has size $roundedNewSize")false} else {//val raf = new RandomAccessFile(file, "rw")try {//获取内存映射MappedByteBuffer的positionval position = mmap.position()/* Windows won't let us modify the file length while the file is mmapped :-( */if (OperatingSystem.IS_WINDOWS)safeForceUnmap()//设置文件大小raf.setLength(roundedNewSize)_length = roundedNewSize//根据实际大小调整mmap内存映射的大小mmap = raf.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, roundedNewSize)//计算entry数量_maxEntries = mmap.limit() entrySize//更新position值mmap.position(position)debug(s"Resized ${file.getAbsolutePath} to $roundedNewSize, position is ${mmap.position()} " +s"and limit is ${mmap.limit()}")true} finally {CoreUtils.swallow(raf.close(), AbstractIndex)}}}}
该方法会根据给定的值,调整内存映射和索引文件大小为entrySize的整数倍,即实际占用的空间。
这就解释了为什么日志段滚动后,之前旧的日志段的索引文件变小了。
那么新滚动生成的日志段对应的索引文件为何比较大?我们继续看一下resize()方法的注释:从中可以知道,这个方法的作用和调用时机如下:
作用:重置内存映射和对应文件的大小。这个方法在两种情况下使用:(1)在trimToValidSize()方法中,该方法在关闭正在滚动的日志段或生成新日志段时被调用(2)在从磁盘加载日志段或者一个新的日志段成为active截断旧日志段时调用此时会重新调整索引文件的大小,避免因为索引文件大小达到阈值而滚动生成新日志段
既然新生成日志段时也会调用trimToValidSize()方法,那么还是回到Log.roll(),里面生成新日志段对象的代码如下:
val segment = LogSegment.open(dir,baseOffset = newOffset,config,time = time,fileAlreadyExists = false,initFileSize = initFileSize,preallocate = config.preallocate)
对应的open()方法如下:
def open(dir: File, baseOffset: Long, config: LogConfig, time: Time, fileAlreadyExists: Boolean = false,initFileSize: Int = 0, preallocate: Boolean = false, fileSuffix: String = ""): LogSegment = {//这里设置了索引文件的大小,由参数:segment.index.bytes 决定,默认为10Mval maxIndexSize = config.maxIndexSizenew LogSegment(FileRecords.open(Log.logFile(dir, baseOffset, fileSuffix), fileAlreadyExists, initFileSize, preallocate),LazyIndex.forOffset(Log.offsetIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),LazyIndex.forTime(Log.timeIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),new TransactionIndex(baseOffset, Log.transactionIndexFile(dir, baseOffset, fileSuffix)),baseOffset,indexIntervalBytes = config.indexInterval,rollJitterMs = config.randomSegmentJitter,time)}
这个方法中创建了LogSegment对象,而生成的偏移量索引文件和时间戳索引文件的大小则由服务端参数 segment.index.bytes 决定,默认为10M。
LazyIndex.forOffset(Log.offsetIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),LazyIndex.forTime(Log.timeIndexFile(dir, baseOffset, fileSuffix), baseOffset = baseOffset, maxIndexSize = maxIndexSize),
这就解释了为什么新生成的日志段的索引文件较大。
总结:
综上,对于active日志段,不管索引项具体有多少,都先生成10M的索引文件(包括偏移量索引文件和时间戳索引文件)来存储索引,当滚动生成新的日志段时,会将这个索引文件调整为实际大小。
三、索引文件扩展
Kafka中的索引文件以稀疏索引的方式添加索引项,每当写入一定量(由broker端参数log.index.interval.bytes指定,默认为4k)的消息时,就会在偏移量索引文件和时间戳索引文件中增加一个索引项。
Kafka通过MappedByteBuffer将索引文件映射到内存中,来加快索引的查询速度。
-
偏移量索引文件:
定义:
对于偏移量索引文件,保存的是 <相对偏移量,物理地址> 的对应关系,文件中的相对偏移量是单调递增的。
查找:
查询指定偏移量对应的消息时,使用改进的二分查找算法来快速定位偏移量的位置,如果指定的偏移量不在索引文件中,则会返回文件中小于指定偏移量的最大偏移量及对应的物理地址,该逻辑通过OffsetIndex.lookup()方法实现。
索引项:
偏移量索引文件的索引项结构如下图所示,每个索引项记录了相对偏移量relativeOffset和对应消息的第一个字节在日志段文件中的物理地址position,共占用8个字节。

为什么使用相对偏移量?这样可以节约存储空间。每条消息的绝对偏移量占用8个字节,而相对偏移量只占用4个字节(relativeOffset=offset-baseOffset)。在日志段文件滚动的条件中,有一个是:追加消息的最大偏移量和当前日志段的baseOffset的差值大于Int.MaxValue,因为如果大于这个值,4个字节就无法存储相对偏移量了。
偏移量索引文件的查找原理:
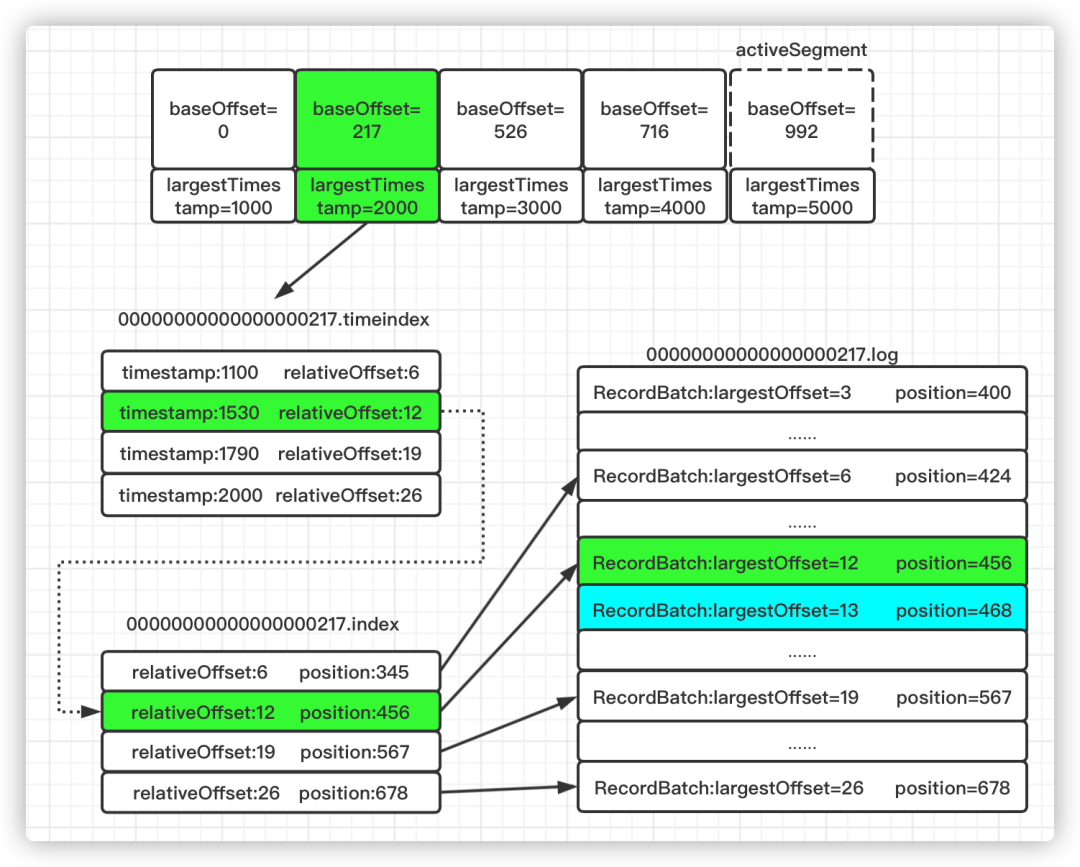
假设要查找偏移量为230的消息,查找过程如下:

-
首先找到baseOffset=217的日志段文件(这里使用了跳跃表的结构来加速查找)
-
计算相对偏移量relativeOffset=230-217=13
-
在索引文件中查找不大于13的最大相对偏移量对应的索引项,即[12,456]
-
根据12对应的物理地址456,在日志文件.log中定位到准确位置
-
从日志文件物理位置456继续向后查找找到相对偏移量为13,即绝对偏移量为230,物理地址为468的消息
注意:
-
消息在log文件中是以批次存储的,而不是单条消息进行存储。索引文件中的偏移量保存的是该批次消息的最大偏移量,而不是最小的。
-
Kafka强制要求索引文件大小必须是索引项大小(8B)的整数倍,假设broker端参数log.index.size.max.bytes设置的是67,那么Kafka内部也会将其转为64,即不大于67的8的最大整数倍。
-
时间戳索引文件
定义:
对于时间戳索引文件,保存的是 <时间戳,相对偏移量> 的对应关系,文件中的时间戳和相对偏移量都是单调递增的。
查找:
查询指定时间戳对应的消息时, 需要配合偏移量索引文件进行查找。首先通过改进的二分查找在时间戳索引文件中找到不大于目标时间戳的索引项,然后根据索引项的相对偏移量在偏移量索引文件中查找,查找方式就是上面指定偏移量的方式。
索引项:
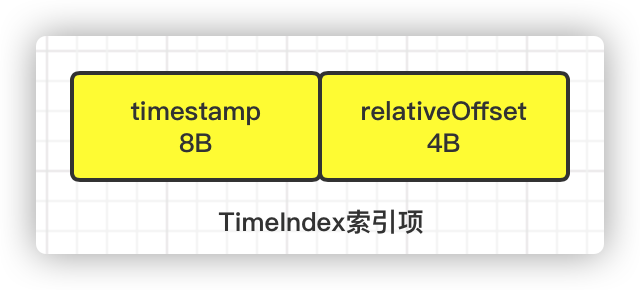
时间戳索引文件的索引项结构如下图所示,每个索引项记录了时间戳timestamp和相对偏移量relativeOffset的对应关系,共占用12个字节。
时间戳索引文件的查找原理:
假设要查找时间戳为1540的消息,查找过程如下(这里时间戳只是一个示意值):
-
将要查找的时间戳1540和每个日志段的最大时间戳逐一对比,直到找到最大时间戳不小于1540的日志段。(日志段的最大时间戳:获取时间戳索引文件最后一个索引项的时间戳,如果大于0,取该值;否则取日志段的最近修改时间)
-
找到对应的日志段后,在时间戳索引文件中使用二分查找找到不大于目标时间戳1540的最大索引项,即图中的[1530,12],获取对应的相对偏移量12
-
在该日志段的偏移量索引文件中找到相对偏移量不大于12的索引项,即图中的[12,456]
-
在日志文件中从物理位置456开始查找时间戳不小于1540的消息
注意:
-
Kafka强制要求索引文件大小必须是索引项大小(12B)的整数倍,假设broker端参数log.index.size.max.bytes设置的是67,那么Kafka内部也会将其转为60,即不大于67的12的最大整数倍。
-
虽然写数据时偏移量索引文件和时间戳索引文件会同时写入一个索引项,但是两个索引项的相对偏移量不一定是一样的,这是因为:生产者生产消息时可以指定时间戳,导致一个批次中的消息,偏移量最大的对应的时间戳不一定最大,而时间戳索引文件中保存的是一个批次中最大的时间戳及对应消息的相对偏移量
-
这里查找目标时间戳对应的日志段时,就无法采用跳表来快速查找了,好在日志段的最大时间戳是递增的,依次查看就行了。至于为什么不单独写一个数据结构保存最大时间戳和日志段对象的对应关系,大概是通过时间戳查找消息的操作用的很少吧。
四、索引文件具体操作源码解析
偏移量索引和时间戳索引对应的类分别为:OffsetIndex 和 TimeIndex,其公共的抽象父类为AbstractIndex:
1.索引项大小定义:
//偏移量索引文件索引项override def entrySize = 8//时间戳索引文件索引项override def entrySize = 12
2.根据绝对偏移量计算相对偏移量:relativeOffset
def relativeOffset(offset: Long): Int = {val relativeOffset = toRelative(offset)if (relativeOffset.isEmpty)throw new IndexOffsetOverflowException(s"Integer overflow for offset: $offset (${file.getAbsoluteFile})")relativeOffset.get}
relativeOffset方法内部调用了toRelative方法:用给定的偏移量-日志段起始偏移量,如果结果合法则返回
private def toRelative(offset: Long): Option[Int] = {val relativeOffset = offset - baseOffsetif (relativeOffset < 0 || relativeOffset > Int.MaxValue)NoneelseSome(relativeOffset.toInt)}
3.将相对偏移量还原成绝对偏移量:parseEntry
偏移量索引:
override protected def parseEntry(buffer: ByteBuffer, n: Int): OffsetPosition = {OffsetPosition(baseOffset + relativeOffset(buffer, n), physical(buffer, n))}
这个方法返回一个 OffsetPosition 类型。该类有两个方法,分别返回索引项的 Key 和 Value。这里的 parseEntry 方法,就是要构造 OffsetPosition 所需的 Key 和 Value。Key 是绝对偏移量,根据索引项中的相对偏移量计算,代码使用 baseOffset + relativeOffset(buffer, n) 的方式将相对偏移量还原成绝对偏移量;Value 是这个偏移量上消息在日志段文件中的物理位置,代码调用 physical 方法计算这个物理位置并把它作为 Value。最后,parseEntry 方法把 Key 和 Value 封装到一个 OffsetPosition 实例中,然后将这个实例返回。
时间戳索引:
override def parseEntry(buffer: ByteBuffer, n: Int): TimestampOffset = {TimestampOffset(timestamp(buffer, n), baseOffset + relativeOffset(buffer, n))}
逻辑和偏移量索引大同小异,只是最后返回的是一个TimestampOffset类型。key为索引项中的时间戳,value是根据索引中的相对偏移量计算出的绝对偏移量。
4.快速定位消息所在的物理文件位置
偏移量索引:
def lookup(targetOffset: Long): OffsetPosition = {maybeLock(lock) {//复制出整个索引映射区val idx = mmap.duplicate// largestLowerBoundSlotFor方法底层使用了改进版的二分查找算法寻找对应的槽val slot = largestLowerBoundSlotFor(idx, targetOffset, IndexSearchType.KEY)// 如果没找到,返回一个空的位置,即物理文件位置从0开始,表示从头读日志文件// 否则返回slot槽对应的索引项if(slot == -1)OffsetPosition(baseOffset, 0)elseparseEntry(idx, slot)}}
时间戳索引:
def lookup(targetTimestamp: Long): TimestampOffset = {maybeLock(lock) {val idx = mmap.duplicateval slot = largestLowerBoundSlotFor(idx, targetTimestamp, IndexSearchType.KEY)if (slot == -1)TimestampOffset(RecordBatch.NO_TIMESTAMP, baseOffset)elseparseEntry(idx, slot)}}
由于时间戳索引必须搭配偏移量索引进行查找,所以调用TimeIndex.lookup方法后,还会再调用OffsetIndex.lookup方法查找消息的物理地址,如logSegment.findOffsetByTimestamp方法:
def findOffsetByTimestamp(timestamp: Long, startingOffset: Long = baseOffset): Option[TimestampAndOffset] = {val timestampOffset = timeIndex.lookup(timestamp)val position = offsetIndex.lookup(math.max(timestampOffset.offset, startingOffset)).positionOption(log.searchForTimestamp(timestamp, position, startingOffset))}
5.写入索引项的方法:
偏移量索引:append
def append(offset: Long, position: Int): Unit = {inLock(lock) {// 索引文件如果已经写满,直接抛出异常require(!isFull, "Attempt to append to a full index (size = " + _entries + ").")// 要保证待写入的位移值offset比当前索引文件中所有现存的位移值都要大// 这主要是为了维护索引的单调增加性if (_entries == 0 || offset > _lastOffset) {trace(s"Adding index entry $offset => $position to ${file.getAbsolutePath}")// 向mmap写入相对位移值mmap.putInt(relativeOffset(offset))// 向mmap写入物理文件位置mmap.putInt(position)//更新索引项数量_entries += 1// 更新当前索引文件最大位移值_lastOffset = offset// 确保写入索引项格式符合要求require(_entries * entrySize == mmap.position(), s"$entries entries but file position in index is ${mmap.position()}.")} else {throw new InvalidOffsetException(s"Attempt to append an offset ($offset) to position $entries no larger than" +s" the last offset appended (${_lastOffset}) to ${file.getAbsolutePath}.")}}}
时间戳索引:maybeAppend
def maybeAppend(timestamp: Long, offset: Long, skipFullCheck: Boolean = false) {inLock(lock) {//如果索引文件已经写满,抛出异常if (!skipFullCheck)require(!isFull, "Attempt to append to a full time index (size = " + _entries + ").")// 确保相对偏移量单调增加性if (_entries != 0 && offset < lastEntry.offset)throw new InvalidOffsetException(s"Attempt to append an offset ($offset) to slot ${_entries} no larger than" +s" the last offset appended (${lastEntry.offset}) to ${file.getAbsolutePath}.")// 确保时间戳的单调增加性if (_entries != 0 && timestamp < lastEntry.timestamp)throw new IllegalStateException(s"Attempt to append a timestamp ($timestamp) to slot ${_entries} no larger" +s" than the last timestamp appended (${lastEntry.timestamp}) to ${file.getAbsolutePath}.")if (timestamp > lastEntry.timestamp) {trace(s"Adding index entry $timestamp => $offset to ${file.getAbsolutePath}.")// 向mmap写入时间戳mmap.putLong(timestamp)// 向mmap写入相对偏移量mmap.putInt(relativeOffset(offset))//更新entry的数量_entries += 1// 更新当前最新的索引项_lastEntry = TimestampOffset(timestamp, offset)require(_entries * entrySize == mmap.position(), _entries + " entries but file position in index is " + mmap.position() + ".")}}}
6.截断索引文件:比如,OffsetIndex 索引文件中当前保存了 1000 个索引项,但我只想保留最开始的 300个索引项。
privatedef truncateToEntries(entries: Int): Unit = {inLock(lock) {_entries = entriesmmap.position(_entries * entrySize)_lastOffset = lastEntry.offsetdebug(s"Truncated index ${file.getAbsolutePath} to $entries entries;" +s" position is now ${mmap.position()} and last offset is now ${_lastOffset}")}}
这个方法接收 entries 参数,表示要截取到哪个槽,主要的逻辑实现是调用 mmap 的 position 方法。源码中的 _entries * entrySize 就是 mmap 要截取到的字节处。
五、mmap内存映射
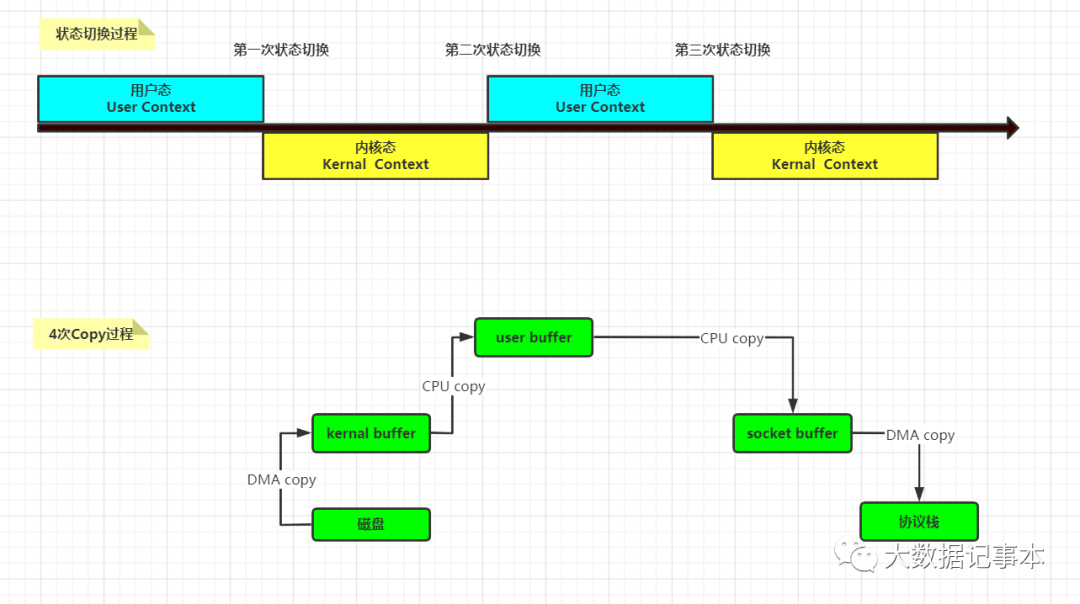
在分析内存映射之前,首先看一下普通网络IO操作是如何进行的,如下图:
-
第一次拷贝是通过DMA从磁盘将数据拷贝到内核缓冲区
-
第二次拷贝是从内核缓冲区拷贝到用户缓冲区
-
第三次拷贝是从用户缓冲区拷贝到sockey缓冲区
-
最后一次再从sockey缓冲区拷贝到协议栈
这个过程经过了两次CPU Copy 和两次DMA Copy,效率不高。采用内存映射后,将用户空间的一段内存区域映射到内核空间,映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也可以直接反映到用户空间。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝次数。示意图如下:
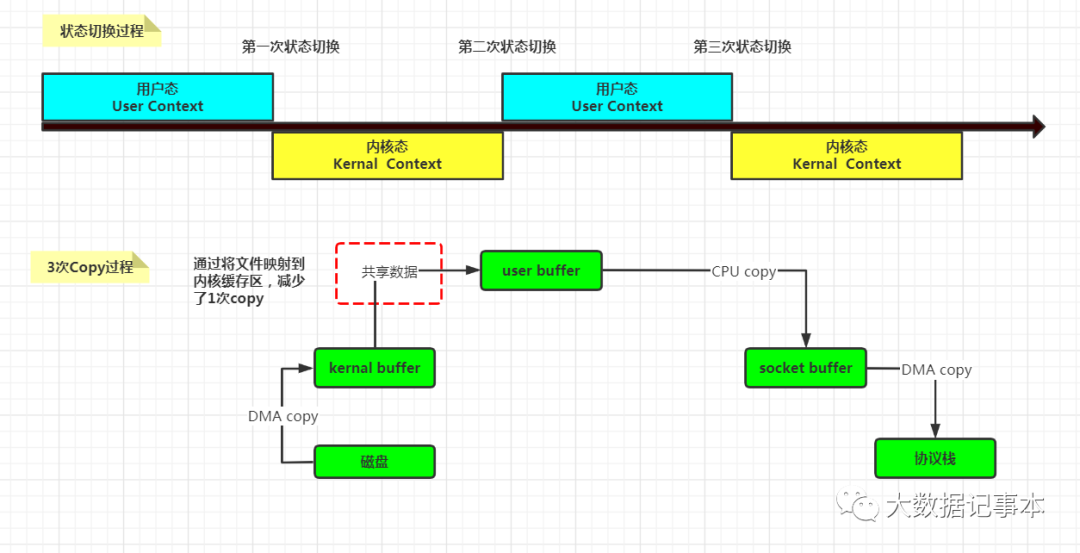
通过使用内存映射可以减少一次CPU Copy,从而提高读写性能。
JavaNIO提供了MappedByteBuffer来实现内存映射,示例代码如下:
public class MappedByteBufferTest {public static void main(String[] args) {File file = new File("/opt/module/mmap.txt");long len = file.length();try {MappedByteBuffer mappedByteBuffer = new RandomAccessFile(file, "r")//获取FileChannel.getChannel()//进行映射,文件类型为只读.map(FileChannel.MapMode.READ_ONLY, 0, len);...} catch (IOException e) {}}}
其中FileChannel.map()方法的三个参数如下:
-
MapModel:内存映射文件的访问方式,分为三种:
-
READ_ONLY:只读
-
READ_WRITE:可读可写
-
PRIVATE:可读可写,但是修改的内容不会写入文件,只是buffer自身的改变,称之为”copy on write”。
-
-
position:文件映射时的起始位置
-
len:文件大小
总结:
-
滚动生成的新日志段,初始的索引文件大小为10M;而滚动时旧的日志段的索引文件会调整为实际大小
-
偏移量索引文件保存的是 <相对偏移量,物理位置> 索引项
-
时间戳索引文件保存的是 <时间戳,相对偏移量> 索引项
-
查找指定偏移量的消息时,只通过偏移量索引文件和日志文件就可以找到
-
查找指定时间戳的消息时,时间戳索引文件必须搭配偏移量索引文件使用
-
索引文件为了提高读写性能,采用了mmap内存映射
参考资料:《深入理解Kafka核心设计与实践原理》