文章目录
- RDD缓存
- RDD缓存API介绍
- RDD缓存代码演示示例
- RDD缓存执行原理
- RDD CheckPoint
- CheckPoint代码演示示例
- CheckPoint与Cache对比
RDD缓存
- RDD之间进行Transformation计算,当执行开启之后,就会有新的RDD生成,而之前老的RDD就会消失,所以RDD是过程数据,只在处理过程中存在,一旦处理完成,就会消失。这样的特性就是可以最大化利用资源,内存得到释放能腾出更多的空间以便后续的使用。
- 以上场景也会出现一个问题,就是如果一个程序中,运行了两个job。而我们在执行第一个之后,由于RDD的消失,在执行第二个任务时,又得重头再去执行,这样就显得有些麻烦了。
- 对于以上场景Spark提供了RDD缓存的API,我们可以通过调用API来讲指定的RDD保留在内存或者磁盘中。
RDD缓存API介绍
# 缓存到内存中
rdd.cache()
# 仅内存缓存
rdd.persist(StorageLevel.MEMORY_ONLY)
# 仅内存缓存,2副本
rdd.persist(StorageLevel.MEMORY_ONLY_2)
# 仅缓存到磁盘
rdd.persist(StorageLevel.DISK_ONLY)
# 仅缓存到磁盘,2副本
rdd.persist(StorageLevel.DISK_ONLY_2)
# 仅缓存到磁盘,3副本
rdd.persist(StorageLevel.DISK_ONLY_3)
# 先放内存不够再放磁盘
rdd.persist(StorageLevel.MEMORY_AND_DISK)
# 先放内存,不够再放磁盘,2副本
rdd.persist(StorageLevel.MEMORY_AND_DISK_2)
# 堆外内存(系统内存)
rdd.persist(StorageLevel.OFF_HEAP)
# 主动清理缓存
rdd.unpersist()
RDD缓存代码演示示例
- 以WordCount为例,不加缓存
import time
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster('local[*]').setAppName('test')
sc = SparkContext(conf=conf)
rdd1 = sc.textFile("../Data/input/words.txt")
rdd2 = rdd1.flatMap(lambda line : line.split(" "))
rdd3 = rdd2.map(lambda x : (x, 1))
rdd4 = rdd3.reduceByKey(lambda a,b : a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x : sum(x))
print(rdd6.collect())
time.sleep(10000)
- 在spark4040界面的DAG图中我们可以看出第二个job的DAG图又是从textFile开始又执行了一次,如下图
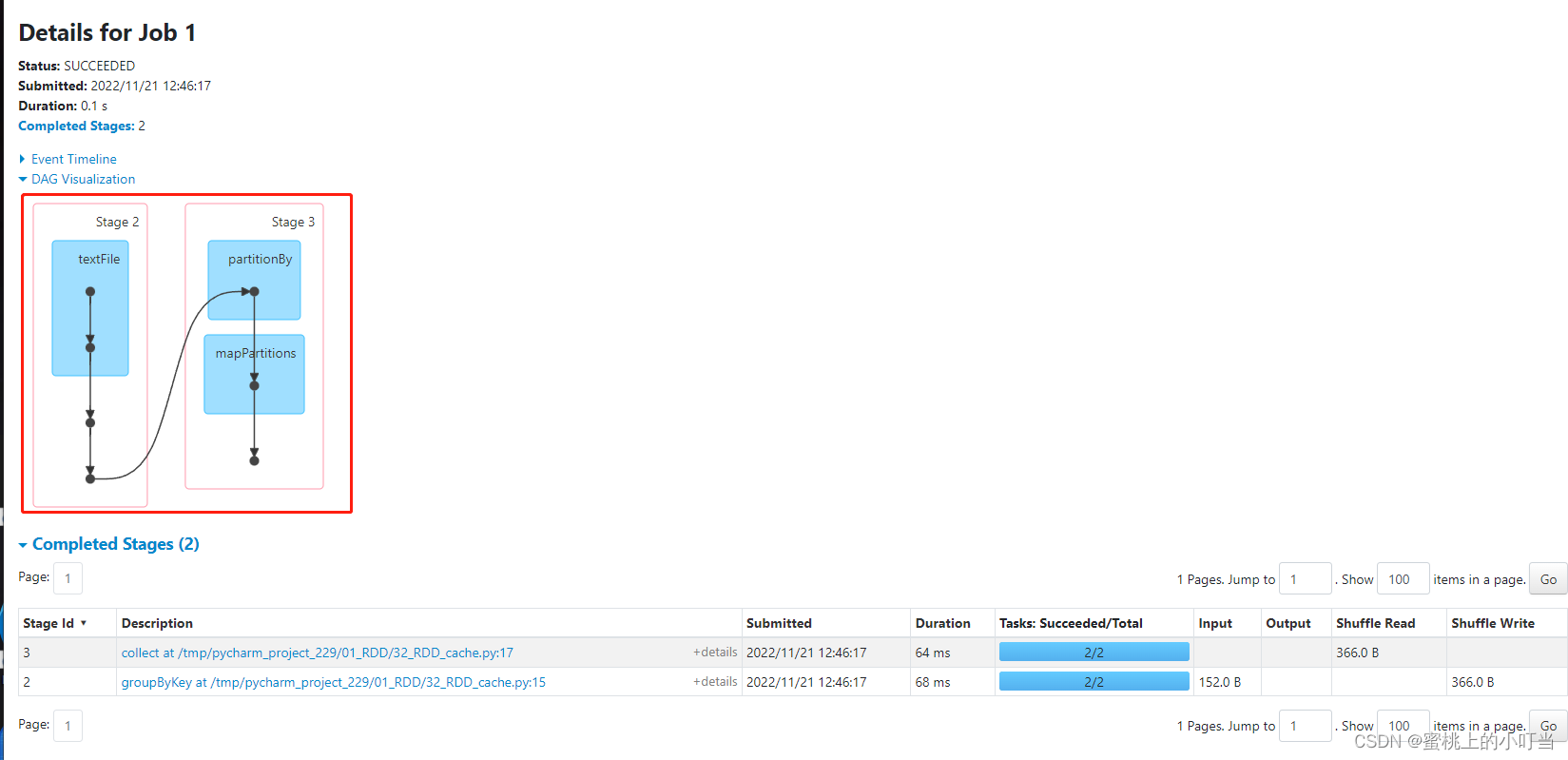
- 加入缓存之后的代码:
在这里插入代码片
# coding: utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
if __name__ == '__main__':
conf = SparkConf().setMaster('local[*]').setAppName('test')
sc = SparkContext(conf=conf)
rdd1 = sc.textFile("../Data/input/words.txt")
rdd2 = rdd1.flatMap(lambda line : line.split(" "))
rdd3 = rdd2.map(lambda x : (x, 1))
rdd3.cache()
rdd3.persist(StorageLevel.MEMORY_ONLY)
rdd4 = rdd3.reduceByKey(lambda a,b : a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x : sum(x))
print(rdd6.collect())
rdd3.unpersist()
time.sleep(10000)
- 在spark4040界面的DAG图中我们可以看出第二个job的DAG图又是从绿色小点之后开始执行,证明已经添加了缓存机制。

RDD缓存执行原理
- 以三分区的RDD为例,如下图所示,根据调用的API来设定
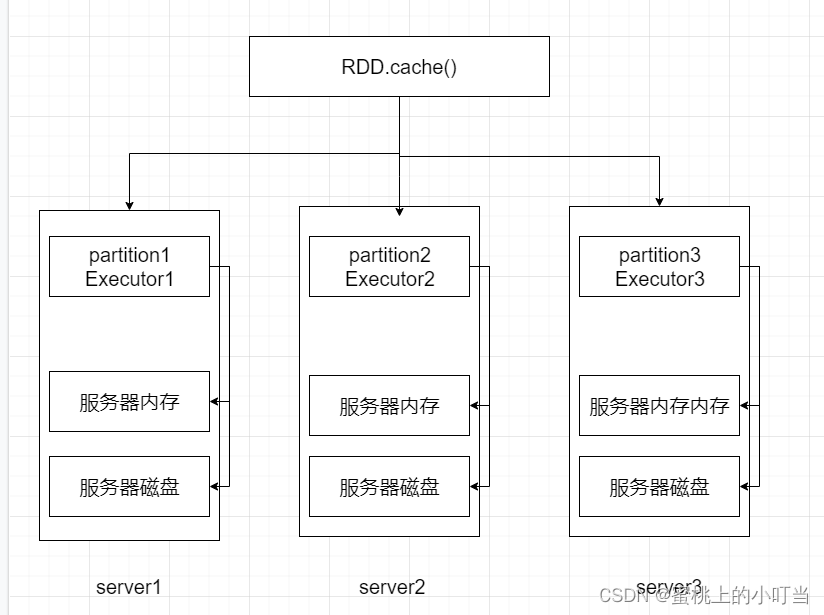
- RDD将自己分区的数据按照每一个分区自行保留在其所在Executor服务器的内存和硬盘上,这就是RDD的缓存分散存储。缓存一定要保留被缓存RDD前置的血缘关系。
RDD CheckPoint
- CheckPoint技术也是将RDD的数据保存起来,但是它仅支持硬盘存储。在设计的角度上讲,CheckPoint是安全的,但是并不保留血缘关系。
- CheckPoint保存数据原理图,以三分区保存到HDFS为例:
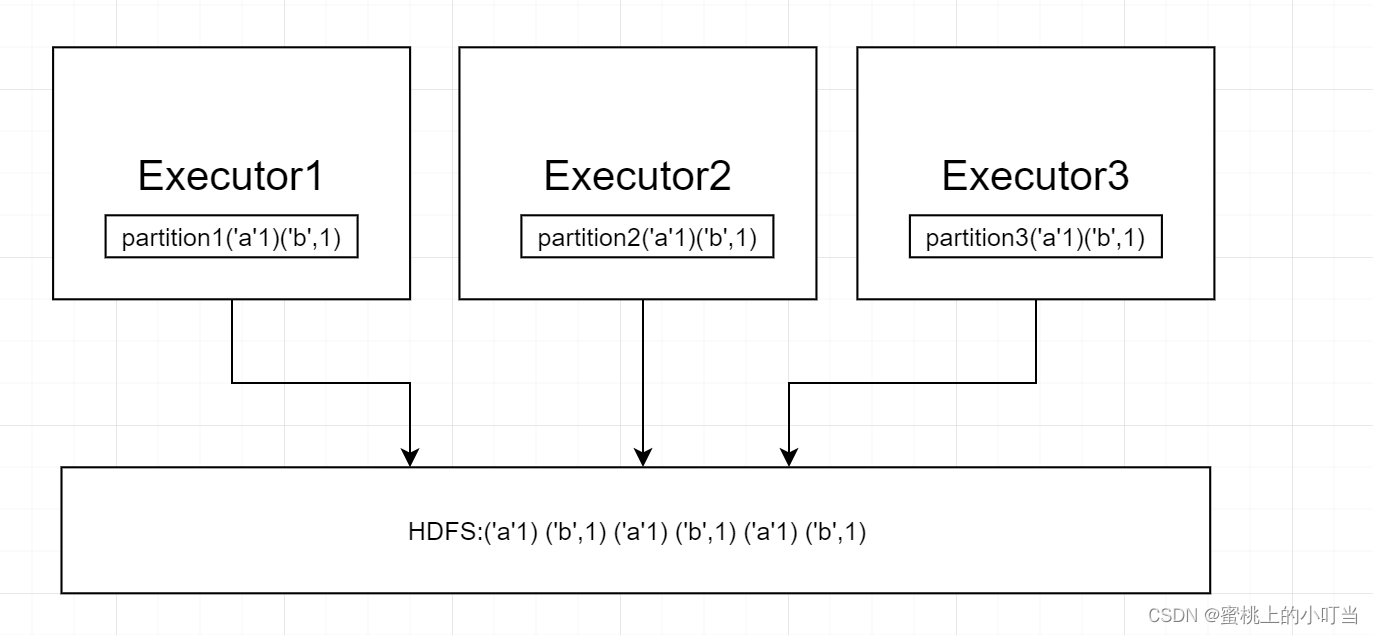
- CheckPoint存储RDD数据是集中收集各个分区的数据进行存储,也叫集中存储。
CheckPoint代码演示示例
- API:
# 设置路径既可以是local模式下的本地文件系统,又可以选用HDFS
sc.setCheckpointDir()
# 直接调用CheckPoint算子
rdd.checkpoint()
# coding: utf8
import time
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster('local[*]').setAppName('test')
sc = SparkContext(conf=conf)
# 开启CheckPoint功能
sc.setCheckpointDir("hdfs://node1:8020/Test/CheckPoint")
rdd1 = sc.textFile("../Data/input/words.txt")
rdd2 = rdd1.flatMap(lambda line : line.split(" "))
rdd3 = rdd2.map(lambda x : (x, 1))
# 调用CheckPoint API
rdd3.checkpoint()
rdd4 = rdd3.reduceByKey(lambda a,b : a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x : sum(x))
print(rdd6.collect())
time.sleep(10000)
- 在spark4040界面的DAG图中我们可以看出,开头是CheckPoint,表示数据从CheckPoint读取了,也能看出CheckPoint不保留血缘关系。
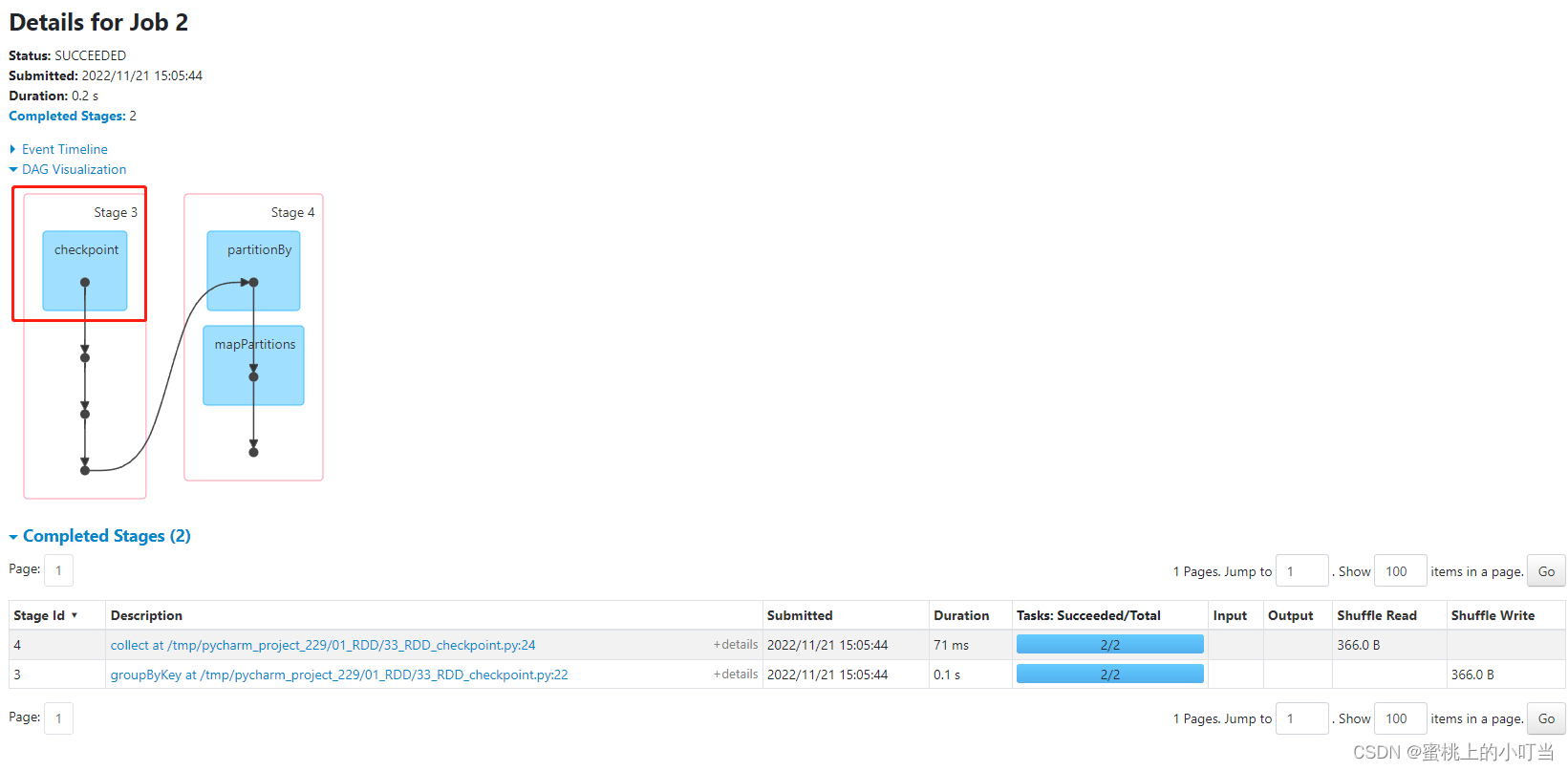
- CheckPoint是一种重量级的使用,当RDD重新计算成本很高的情况下可以使用CheckPoint,如果是小数据量并且对RDD重新计算无可厚非的情况,直接使用cache最好。
- 不管是CheckPoint还是cache都是Acition类型,如果想要这两个api工作后续必须添加Action算子。
CheckPoint与Cache对比
- CheckPoint不管分区数量是多少,所承担的风险是一样的;而缓存分区越多,风险越高。
- CheckPoint支持写入HDFS,缓存则不行,HDFS属于高可靠存储,所以CheckPoint安全性比缓存高。
- CheckPoint不支持内存,缓存则可以,性能上缓存要比CheckPoint好。
- CheckPoint因为安全,所以其不保留血缘关系,缓存反之。



![[SUCTF 2019]Pythonginx](https://img-blog.csdnimg.cn/7765c3b4fbf340c38dda0d69ecabf1ad.png#pic_center)
![[论文评析]Densely Connected Convolutional Networks,CVPR,2017](https://img-blog.csdnimg.cn/0e5568daa26a49faac10c815a973b7d1.png)



![SPARKSQL3.0-Unresolved[Parsed]阶段源码剖析](https://img-blog.csdnimg.cn/img_convert/db48b562adbc63cd1ec56f33f8e3d78d.jpeg)