一、前言
上两节介绍了Antlr4的简单使用以及spark中如何构建SessionState,如果没有看过建议先了解上两节的使用,否则看本节会比较吃力
[SPARKSQL3.0-Antlr4由浅入深&SparkSQL语法解析]
[SPARKSQL3.0-SessionState构建源码剖析]
那么在Unresolved阶段,spark主要做了两件事:
1、将sql字符串通过antrl4转化成AST语法树
2、将AST语法树经过spark自定义访问者模式转化成logicalPlan【logicalPlan可以理解为精简版的语法树】
注意:该阶段中语法树中仅仅是数据结构,不包含任何数据信息
二、sql -> antlr4阶段
先来一个简单的示例:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder()
.config(sparkConf)
.getOrCreate()
case class Person(name: String, age: Int)
Seq(Person("Jack", 12), Person("James", 21), Person("Mac", 30)).toDS().createTempView("person")
spark.sql("SELECT * FROM PERSON WHERE AGE > 18").explain(true) // 打印执行计划
在示例中我们创建了一张person,并写了一个简单的sql语句,执行后结果打印:
== Parsed Logical Plan ==
'Project [*]
+- 'Filter ('AGE > 18)
+- 'UnresolvedRelation `PERSON`
== Analyzed Logical Plan ==
name: string, age: int
Project [name#10, age#11]
+- Filter (AGE#11 > 18)
+- SubqueryAlias person
+- LocalRelation [name#10, age#11]
......
其中 == Parsed Logical Plan == 就是Unresolved阶段,那么sql语句是如何转换成上面的样子呢?
先来看一下sql语句经过antlr4之后生成的AST语法树:
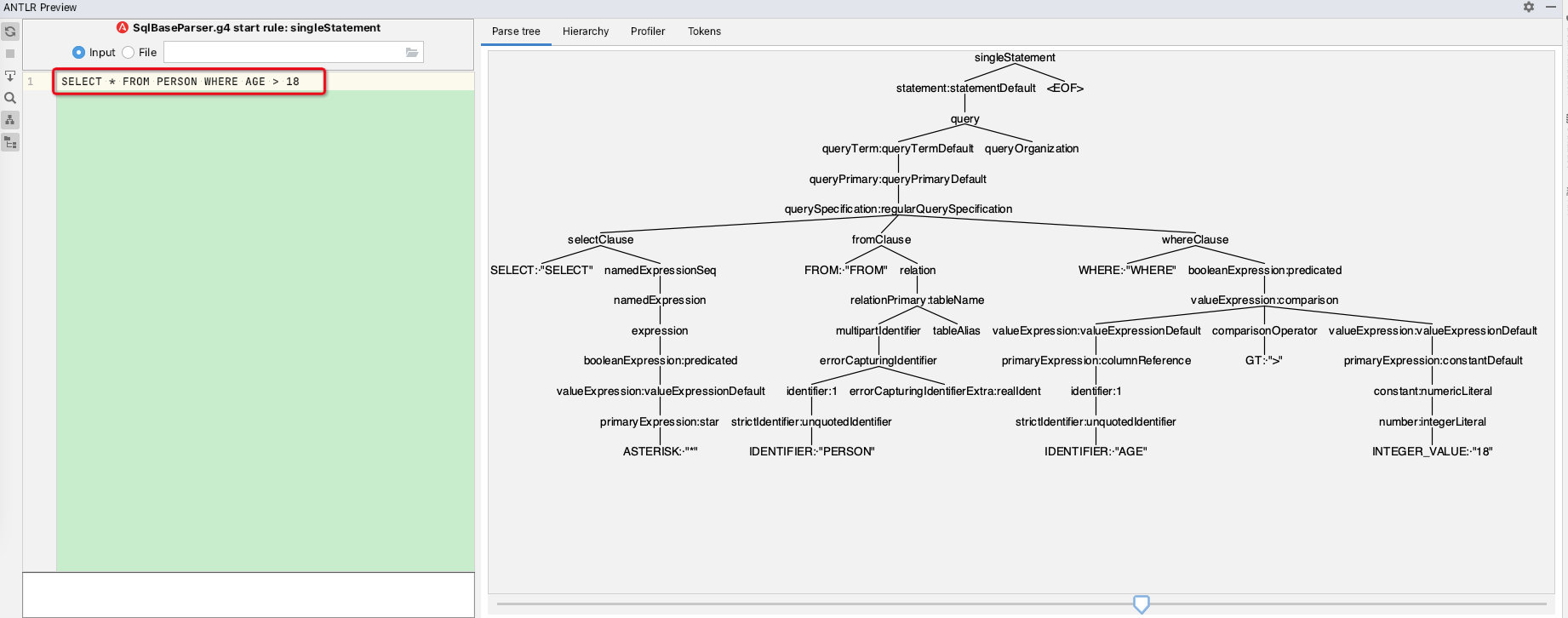
这是由IDEA的antlr4插件根据spark的SqlBaseParser.g4文件形成的语法树,详细看Antlr4一节
接下来我们debug一下看生成此树的过程,首先进入spark.sql函数:
def sql(sqlText: String): DataFrame = withActive {
val tracker = new QueryPlanningTracker
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) { // measurePhase函数用来统计各个阶段的耗时
sessionState.sqlParser.parsePlan(sqlText) // 真正执行parse
}
Dataset.ofRows(self, plan, tracker)
}
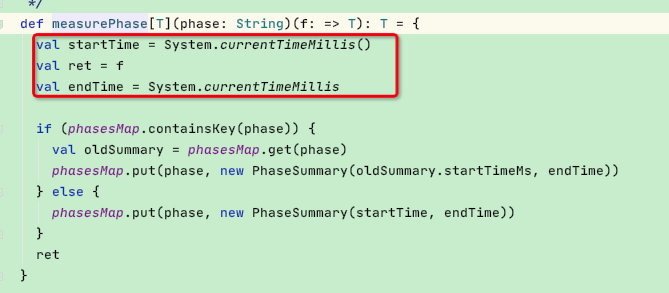
tracker.measurePhase函数主要用于统计spark-sql各个阶段的耗时,如下:
真正执行的是sessionState.sqlParser.parsePlan(sqlText),sessionState.sqlParser变量实际上是SparkSqlParser,这在SessionState创建一节已经讲过
SparkSqlParser类中并没有parsePlan函数,此处是由父类AbstractSqlParser实现:
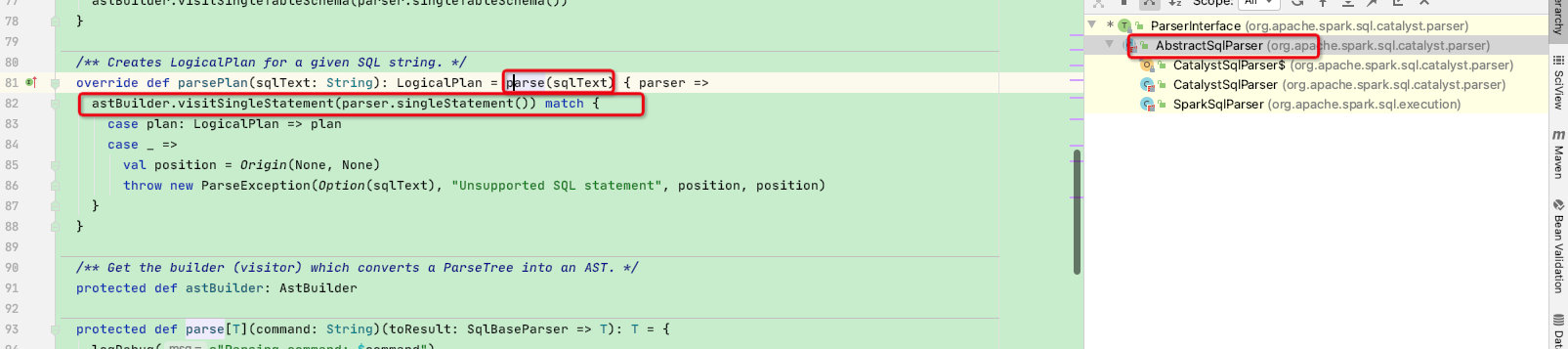
parsePlan函数调用了parse函数,并且代入一个函数参数,函数中的变量astBuilder为抽象函数,并要求类型为AstBuilder
protected def astBuilder: AstBuilder
此函数由子类SparkSqlParser实现:构建SparkSqlAstBuilder
class SparkSqlParser(conf: SQLConf) extends AbstractSqlParser(conf) {
val astBuilder = new SparkSqlAstBuilder(conf)
private val substitutor = new VariableSubstitution(conf)
protected override def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
super.parse(substitutor.substitute(command))(toResult)
}
}
SparkSqlAstBuilder是AstBuilder的子类,而AstBuilder正是spark-antlr4生成的访问器父类SqlBaseBaseVisitor,继承关系如下:
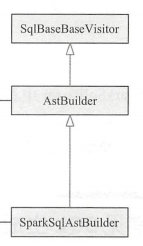
在AstBuilder 和 SparkSqlAstBuilder类中,spark实现了自定义解析AST语法树函数
回过头我们再来看AbstractSqlParser的parsePlan函数,其执行是调用了parse函数:
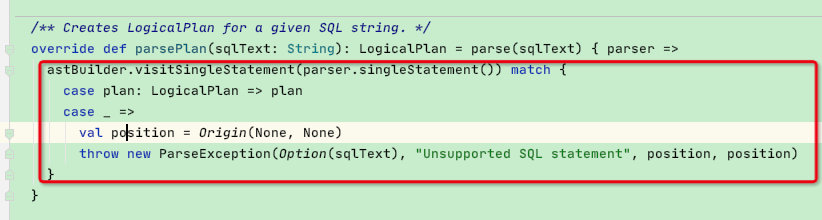
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match { // spark的g4文件所有语法的根节点就是singleStatement
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
// SqlBaseLexer,解析关键词及各种标识符
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
lexer.legacy_setops_precedence_enbled = conf.setOpsPrecedenceEnforced
lexer.legacy_exponent_literal_as_decimal_enabled = conf.exponentLiteralAsDecimalEnabled
lexer.SQL_standard_keyword_behavior = conf.ansiEnabled
// 词法符号的缓冲器,存储词法分析器生成的词法符号
val tokenStream = new CommonTokenStream(lexer)
// SqlBaseParser,构建antlr4的语法解析器
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
parser.legacy_setops_precedence_enbled = conf.setOpsPrecedenceEnforced
parser.legacy_exponent_literal_as_decimal_enabled = conf.exponentLiteralAsDecimalEnabled
parser.SQL_standard_keyword_behavior = conf.ansiEnabled
try {
try {
// 首先,尝试使用可能更快的SLL预测模式进行解析
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser) // 此处就用到了第二个传参函数
}
catch {
case e: ParseCancellationException =>
// if we fail, parse with LL mode
tokenStream.seek(0) // rewind input stream
parser.reset()
// 如果失败,用LL模式解析
parser.getInterpreter.setPredictionMode(PredictionMode.LL)
toResult(parser)
}
}
catch {
case e: ParseException if e.command.isDefined =>
throw e
case e: ParseException =>
throw e.withCommand(command)
case e: AnalysisException =>
val position = Origin(e.line, e.startPosition)
throw new ParseException(Option(command), e.message, position, position)
}
}
}
以上代码中核心是toResult(parser)函数,toResult函数便是AbstractSqlParser-parsePlan函数中的第二个参数:
而toResult(parser)函数中调用了astBuilder.visitSingleStatement(parser.singleStatement()),如下:
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
visit(ctx.statement).asInstanceOf[LogicalPlan] // 到这就开始调用visit函数,不断的递归调用到各种节点
}
那么到这我们可以debug一下生成的SingleStatementContext节点是什么:
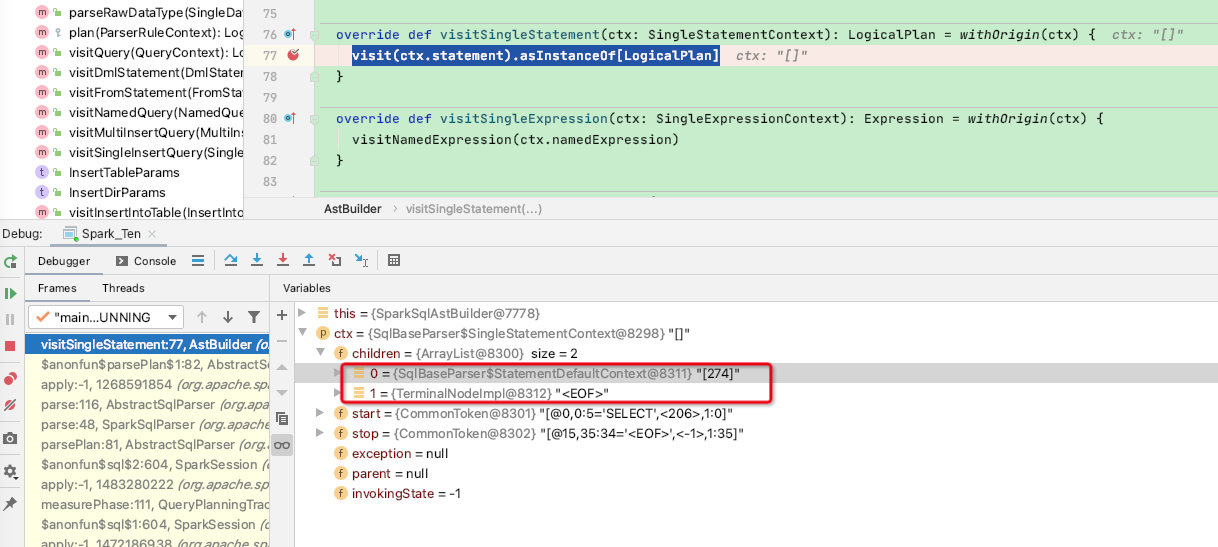
可以看到其children有两个节点,正好对应语法树:
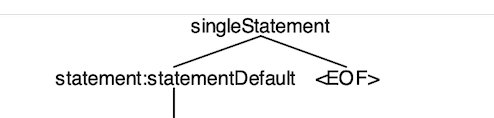
再往下看:我们直接到RegularQuerySpecificationContext节点,至此可以看到antlr4生成语法树的整体结构
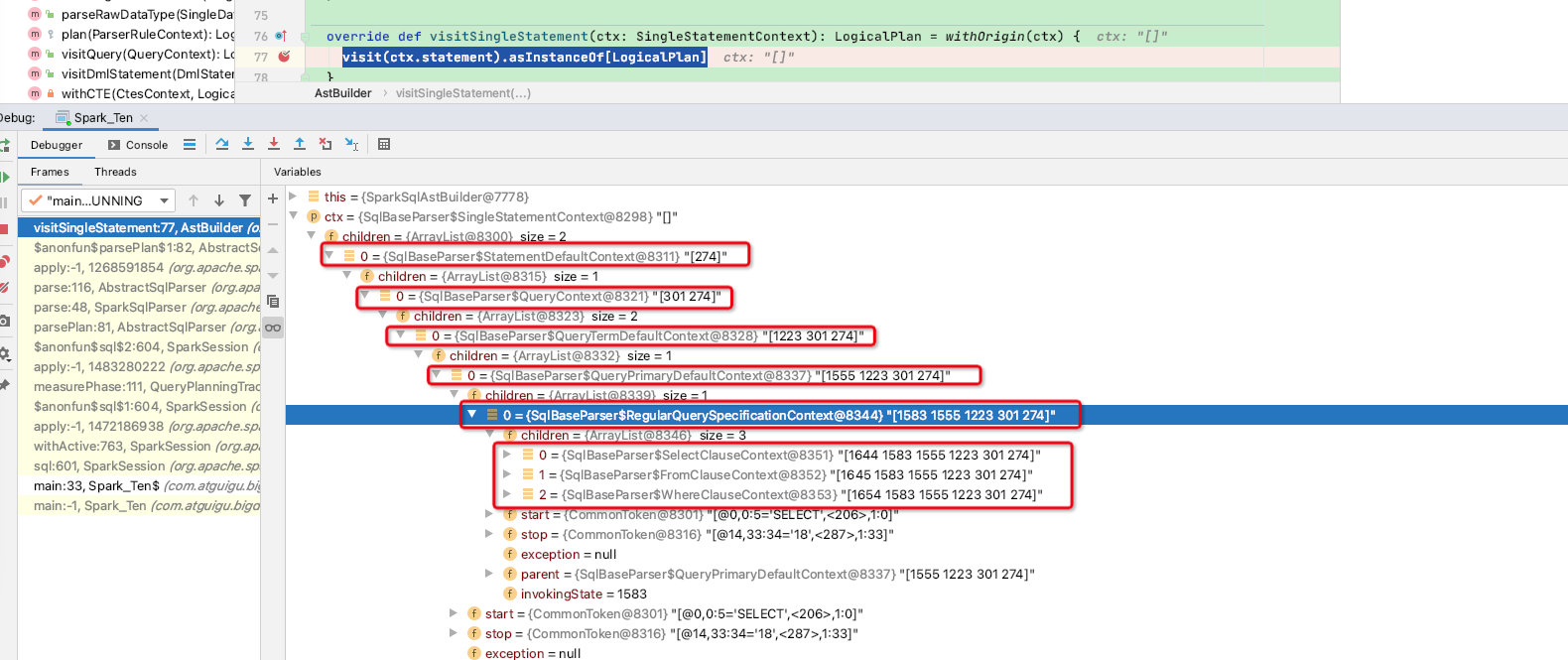
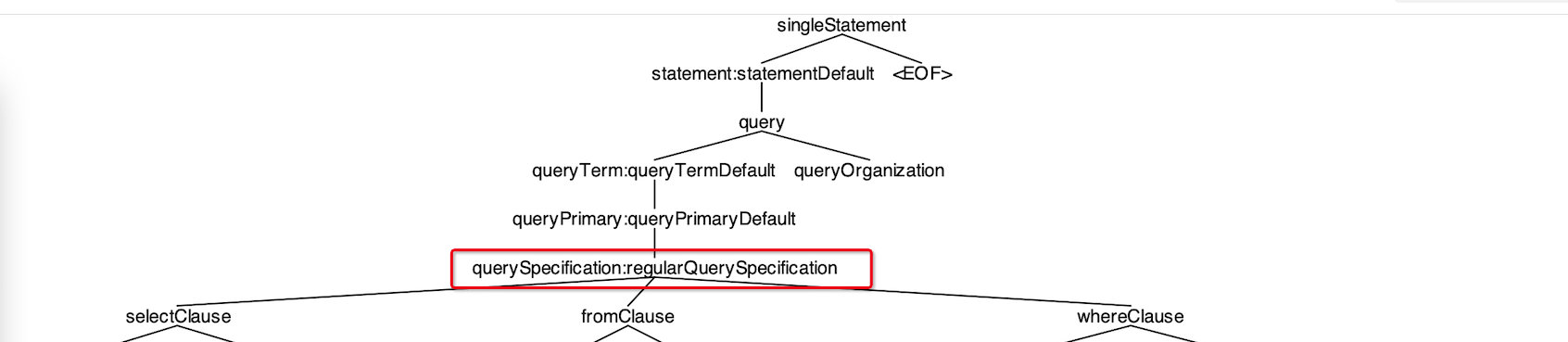
至此我们看到antlr4生成的SPARK-AST语法树全貌,但这只是根据.g4文件生成的语法树,而我们最终返回的是logicalPlan:
== Parsed Logical Plan ==
'Project [*]
+- 'Filter ('AGE > 18)
+- 'UnresolvedRelation `PERSON`
这中间的变化就涉及到了antlr4 -> logicalPlan阶段
三、antlr4 -> logicalPlan阶段
上面我们看到了RegularQuerySpecificationContext节点,在此示例中整个语法树中就RegularQuerySpecificationContext节点的访问函数最有用,上面的节点实现函数都是不断递归往下级寻找,如下:
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
visit(ctx.statement).asInstanceOf[LogicalPlan] // 递归子类,并且强转为LogicalPlan类型
}
@Override public T visitStatementDefault(SqlBaseParser.StatementDefaultContext ctx) {
return visitChildren(ctx); // 递归子类
}
@Override public T visitQuery(SqlBaseParser.QueryContext ctx) {
return visitChildren(ctx); // 递归子类
}
@Override public T visitQueryTermDefault(SqlBaseParser.QueryTermDefaultContext ctx) {
return visitChildren(ctx); // 递归子类
}
......
那么直到RegularQuerySpecificationContext节点才真正实现了如何构建logicalPlan
override def visitRegularQuerySpecification(
ctx: RegularQuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause) // 首先取出fromClause节点,直接访问visitFromClause函数
}
// 调用withSelectQuerySpecification函数,将selectClause、whereClause等可能包含的节点传入
withSelectQuerySpecification(
ctx,
ctx.selectClause,
ctx.lateralView,
ctx.whereClause,
ctx.aggregationClause,
ctx.havingClause,
ctx.windowClause,
from
)
}
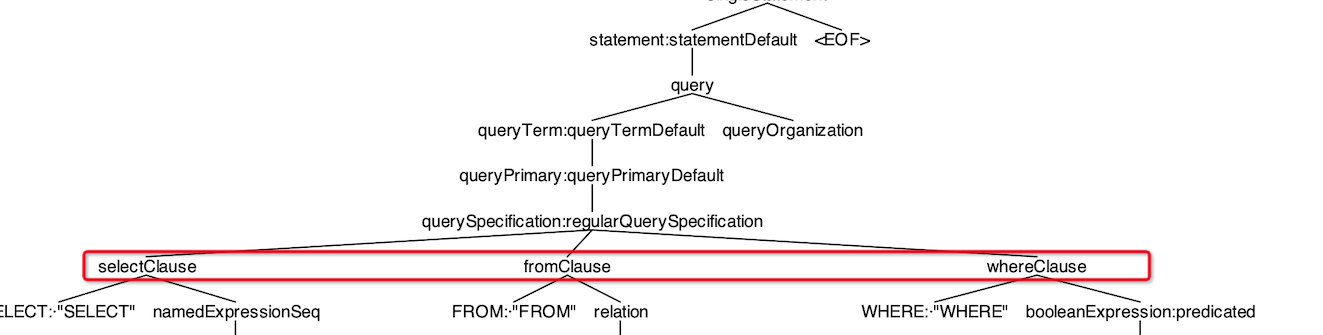
先看visitFromClause函数:此函数是所有from语法的主要执行函数,包括了sql-from语法中的:表名/left/right/inner/ join等解析
override def visitFromClause(ctx: FromClauseContext): LogicalPlan = withOrigin(ctx) {
val from = ctx.relation.asScala.foldLeft(null: LogicalPlan) { (left, relation) =>
val right = plan(relation.relationPrimary)
val join = right.optionalMap(left)(Join(_, _, Inner, None, JoinHint.NONE))
// 是对 relation 语法规则内部的 JOIN 语句进行处理,由于本示例sql不包含join语法此函数不做过多介绍
withJoinRelations(join, relation)
}
if (ctx.pivotClause() != null) {
if (!ctx.lateralView.isEmpty) {
throw new ParseException("LATERAL cannot be used together with PIVOT in FROM clause", ctx)
}
withPivot(ctx.pivotClause, from)
} else {
ctx.lateralView.asScala.foldLeft(from)(withGenerate)
}
}
visitFromClause 方法主要处理 fromClause 规则中的多个 relation节点,根据下图的语法树我们知道每个 relation 的子节点,其中使用了 foldLeft 依次对 relation 的各个节点处理。

在此贴一下 foldLeft 的源码
def foldLeft[B](z: B)(op: (B, A) => B): B = {
var result = z
this foreach (x => result = op(result, x))
result
}
注意,初始值使用的 null,然后迭代 relation 进行处理,此时处理的主要为:val right = plan(relation.relationPrimary)
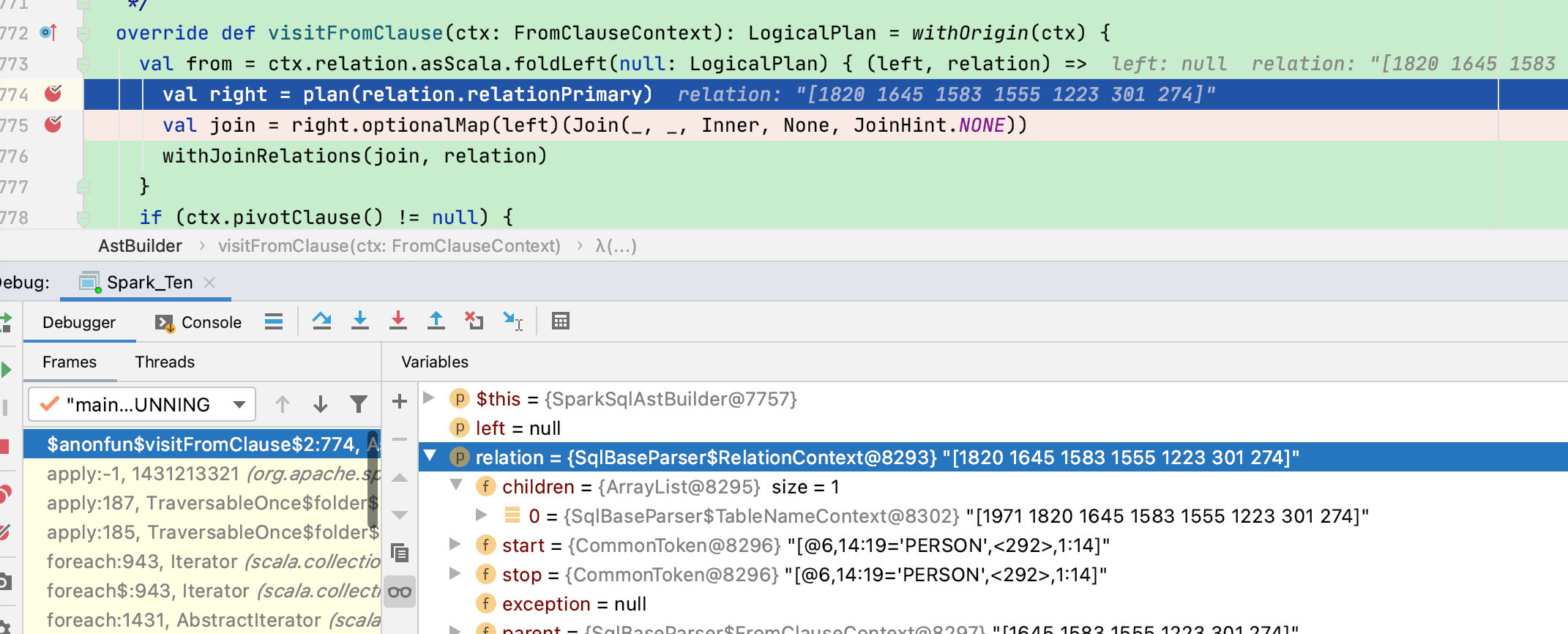
plan函数底层还是调用访问函数:relation.relationPrimary
protected def plan(tree: ParserRuleContext): LogicalPlan = typedVisit(tree)
...
protected def typedVisit[T](ctx: ParseTree): T = {
ctx.accept(this).asInstanceOf[T]
}
...
// 此示例中此函数将返回'UnresolvedRelation [PERSON]
override def visitTableName(ctx: TableNameContext): LogicalPlan = withOrigin(ctx) {
// 不断获子节点字符,最终获得表名
val tableId = visitMultipartIdentifier(ctx.multipartIdentifier)
// 通过表名构建UnresolvedRelation节点, 根据mayApplyAliasPlan函数并判断是否有别名
val table = mayApplyAliasPlan(ctx.tableAlias, UnresolvedRelation(tableId))
table.optionalMap(ctx.sample)(withSample)
}
// 不断获子节点字符,最终获得表名
override def visitMultipartIdentifier(
ctx: MultipartIdentifierContext): Seq[String] = withOrigin(ctx) {
ctx.parts.asScala.map(_.getText)
}
// 返回所有子节点的组合文本, 此示例中会返回表名person字符串
public String getText() {
if (getChildCount() == 0) {
return "";
}
StringBuilder builder = new StringBuilder();
for (int i = 0; i < getChildCount(); i++) {
builder.append(getChild(i).getText());
}
return builder.toString();
}
递归后返回字符串Person
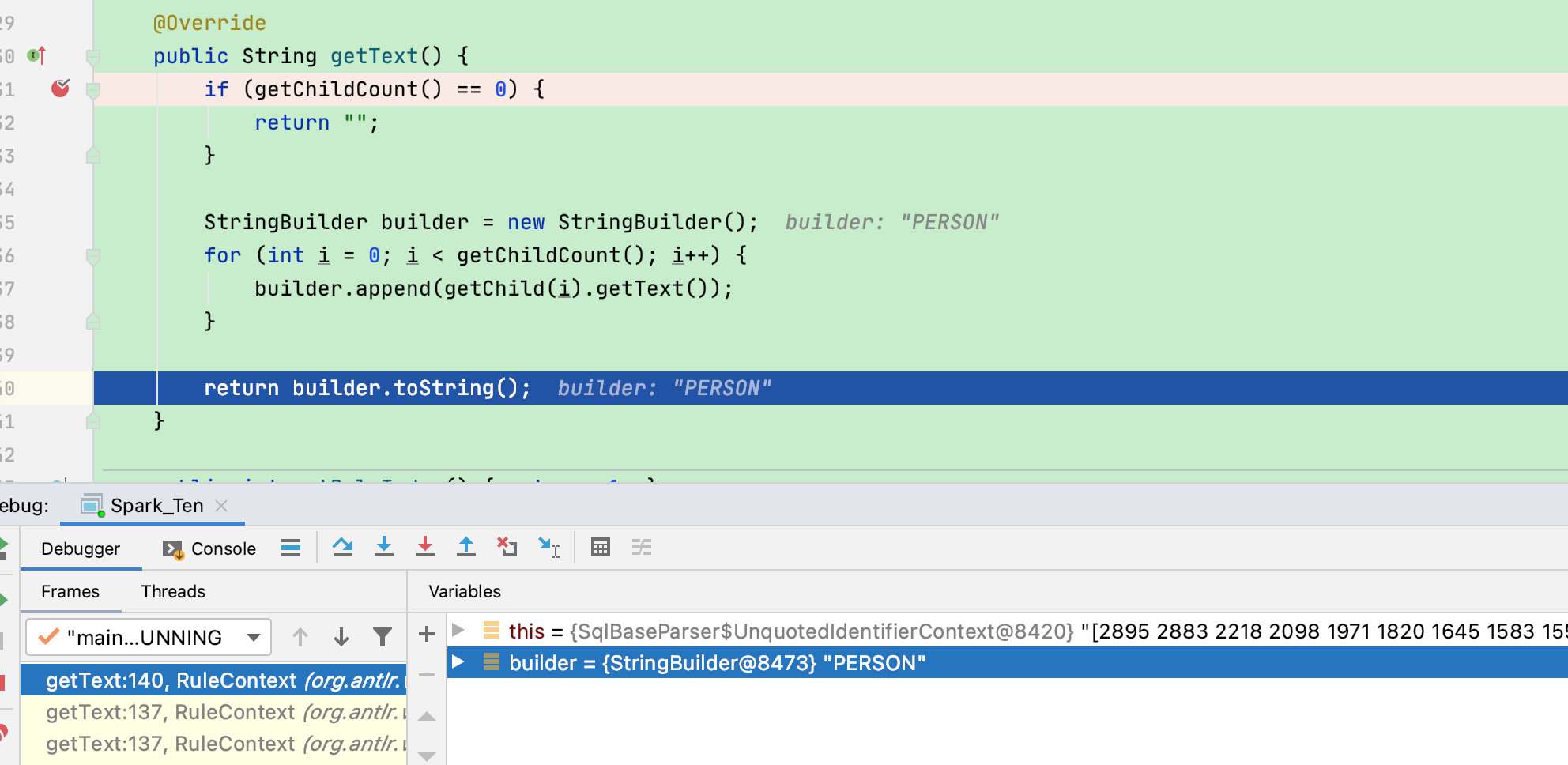
visitTableName函数最终返回UnresolvedRelation [PERSON]
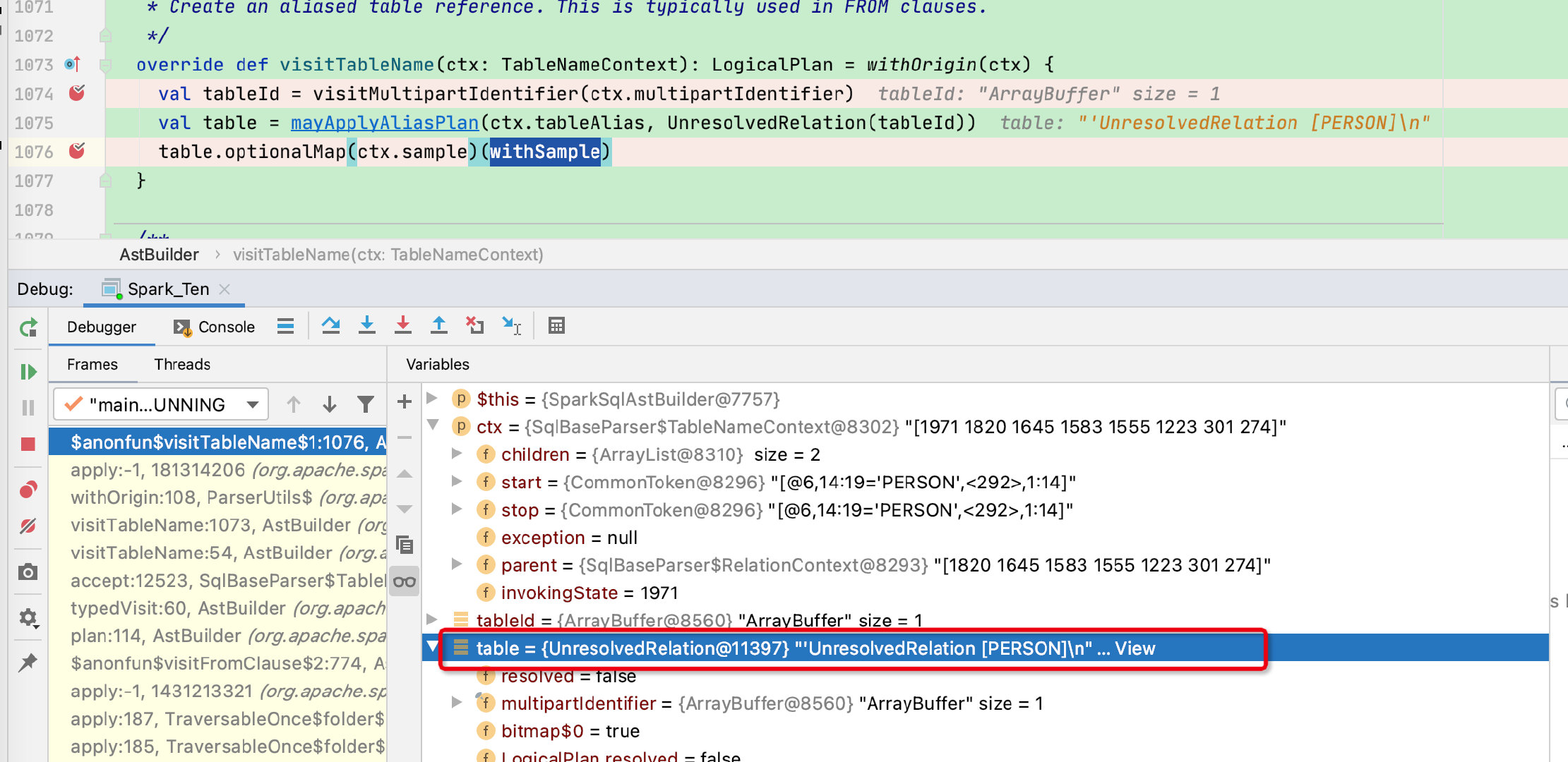
最终visitTableName函数返回的logicalPlan = UnresolvedRelation [PERSON],再回到visitFromClause函数,可以看到from返回值正是UnresolvedRelation
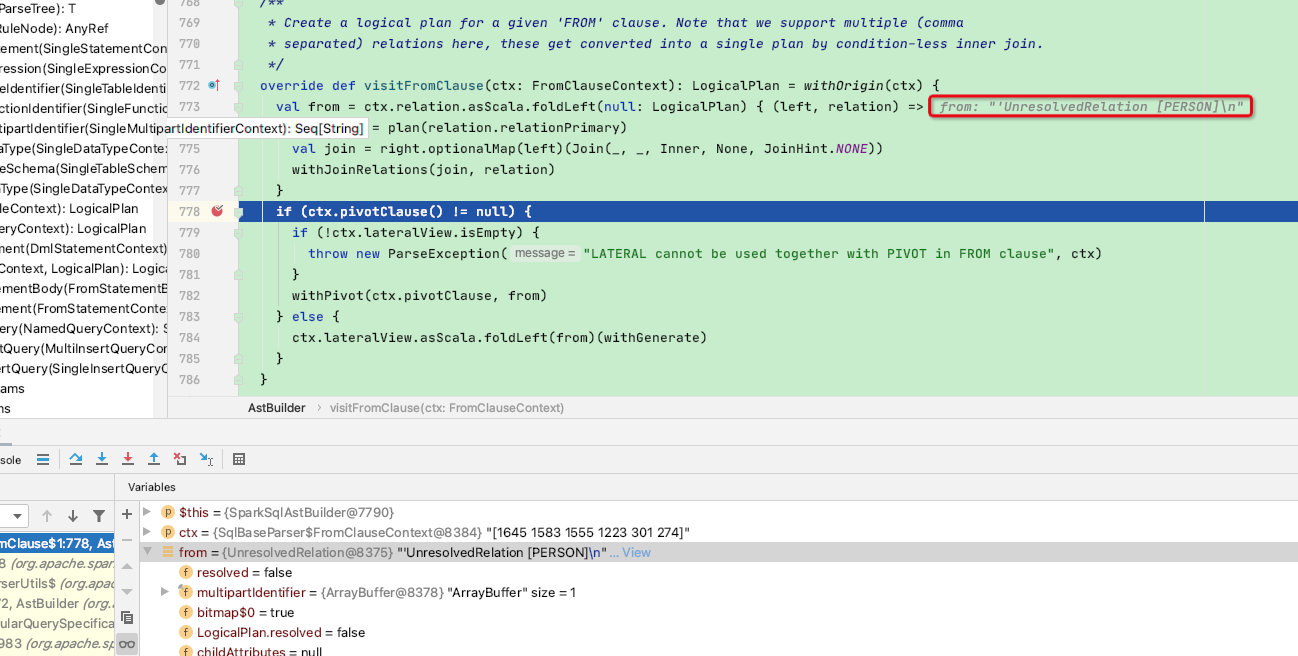
而ctx并没有ctx.pivotClause()节点,且ctx.lateralView返回的集合为0,故visitFromClause函数最终返回UnresolvedRelation [PERSON]
回到再上一层visitRegularQuerySpecification函数,可以看出from最终为:UnresolvedRelation [PERSON]
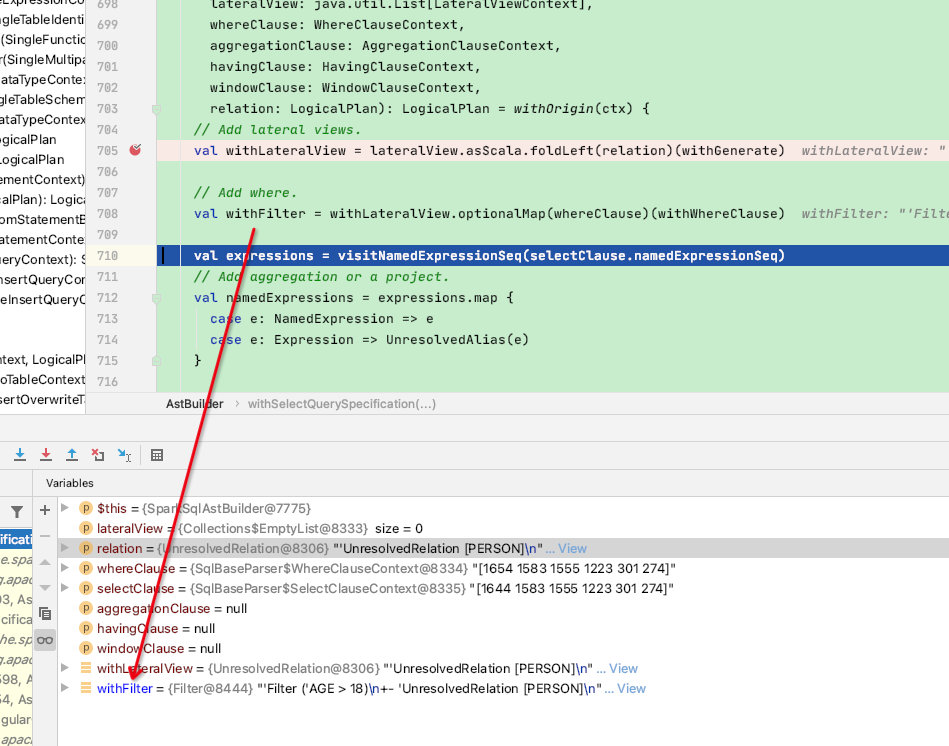
接下来看withSelectQuerySpecification函数,可以看出其将selectClause、whereClause和刚才得到的from节点 等可能包含的节点传入
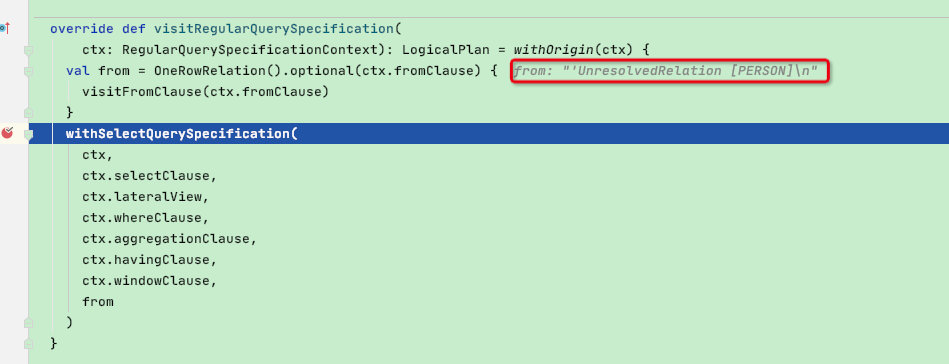
此函数的功能是将from、select、where等各个部分组装成一个logicalPlan,贴一下源码:
private def withSelectQuerySpecification(
ctx: ParserRuleContext,
selectClause: SelectClauseContext,
lateralView: java.util.List[LateralViewContext],
whereClause: WhereClauseContext,
aggregationClause: AggregationClauseContext,
havingClause: HavingClauseContext,
windowClause: WindowClauseContext,
relation: LogicalPlan): LogicalPlan = withOrigin(ctx) {
// Add lateral views.
val withLateralView = lateralView.asScala.foldLeft(relation)(withGenerate)
// Add where.
val withFilter = withLateralView.optionalMap(whereClause)(withWhereClause)
val expressions = visitNamedExpressionSeq(selectClause.namedExpressionSeq)
// Add aggregation or a project.
val namedExpressions = expressions.map {
case e: NamedExpression => e
case e: Expression => UnresolvedAlias(e)
}
def createProject() = if (namedExpressions.nonEmpty) {
Project(namedExpressions, withFilter)
} else {
withFilter
}
val withProject = if (aggregationClause == null && havingClause != null) {
if (conf.getConf(SQLConf.LEGACY_HAVING_WITHOUT_GROUP_BY_AS_WHERE)) {
// If the legacy conf is set, treat HAVING without GROUP BY as WHERE.
withHavingClause(havingClause, createProject())
} else {
// According to SQL standard, HAVING without GROUP BY means global aggregate.
withHavingClause(havingClause, Aggregate(Nil, namedExpressions, withFilter))
}
} else if (aggregationClause != null) {
val aggregate = withAggregationClause(aggregationClause, namedExpressions, withFilter)
aggregate.optionalMap(havingClause)(withHavingClause)
} else {
// When hitting this branch, `having` must be null.
createProject()
}
// Distinct
val withDistinct = if (
selectClause.setQuantifier() != null &&
selectClause.setQuantifier().DISTINCT() != null) {
Distinct(withProject)
} else {
withProject
}
// Window
val withWindow = withDistinct.optionalMap(windowClause)(withWindowClause)
// Hint
selectClause.hints.asScala.foldRight(withWindow)(withHints)
}
可以看出由于示例中只有select/from/where三个节点,此函数中除了这三个节点外都为null
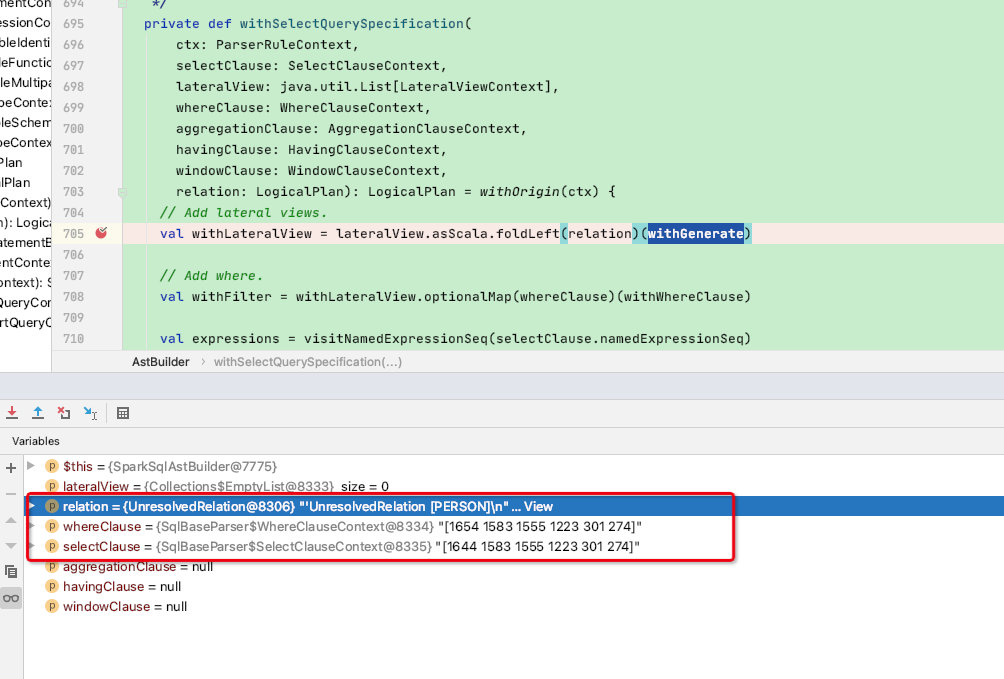
由于lateralView长度为0,故withLateralView = UnresolvedRelation [PERSON]
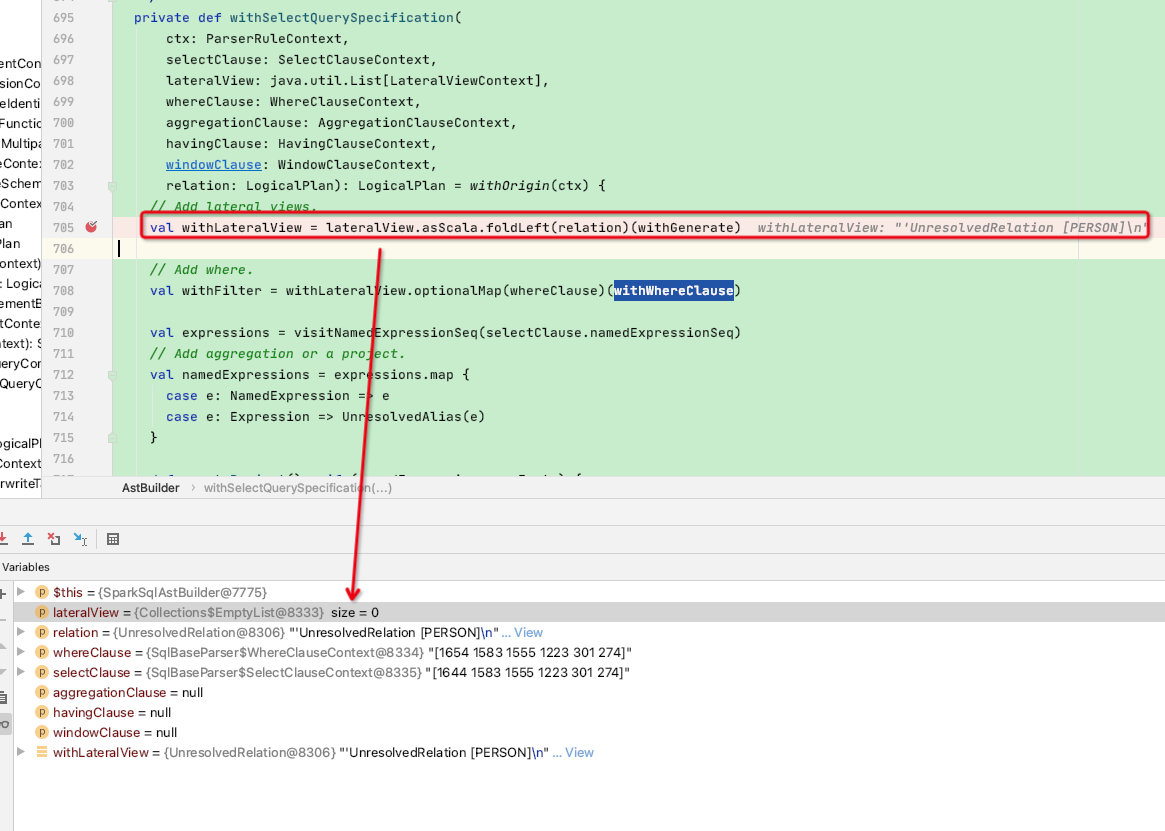
变量withFilter 主要由withWhereClause函数进行拼接:
val withFilter = withLateralView.optionalMap(whereClause)(withWhereClause) // 调用withWhereClause函数进行拼接
...
private def withWhereClause(ctx: WhereClauseContext, plan: LogicalPlan): LogicalPlan = {
Filter(expression(ctx.booleanExpression), plan) // 调用expression函数后,创建Filter类
}
...
protected def expression(ctx: ParserRuleContext): Expression = typedVisit(ctx) // 调用访问函数
protected def typedVisit[T](ctx: ParseTree): T = {
ctx.accept(this).asInstanceOf[T] // 内部其实是调用了 visitPredicated函数
}
...
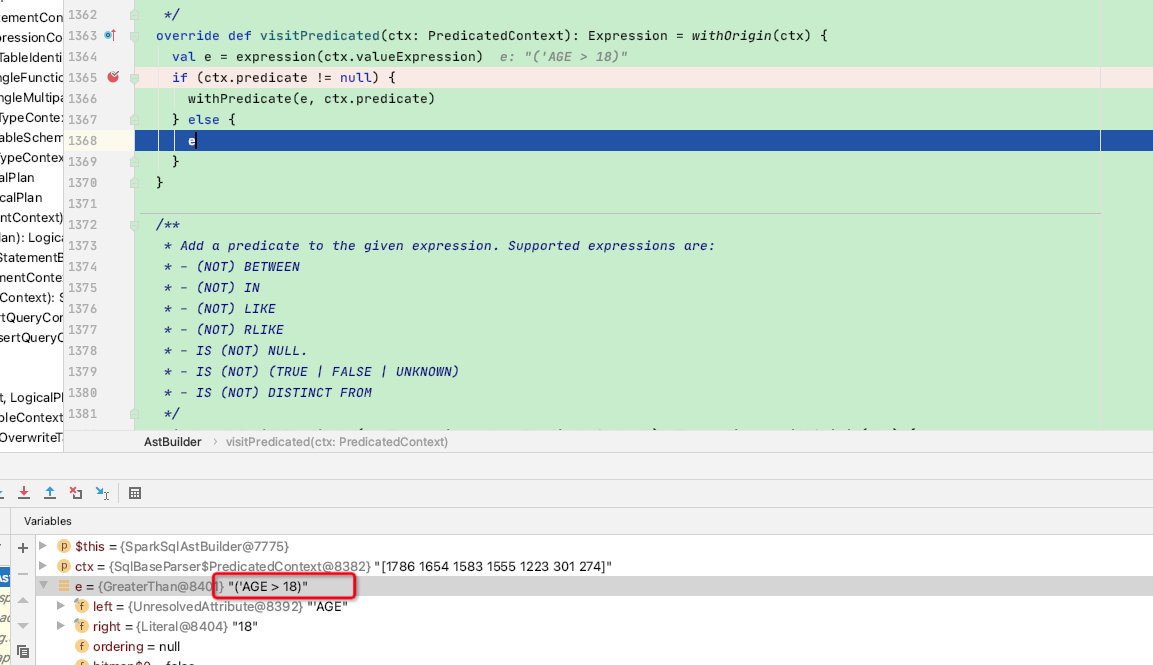
override def visitPredicated(ctx: PredicatedContext): Expression = withOrigin(ctx) {
val e = expression(ctx.valueExpression) // 不断递归调用where的子类
if (ctx.predicate != null) {
withPredicate(e, ctx.predicate)
} else {
e
}
}
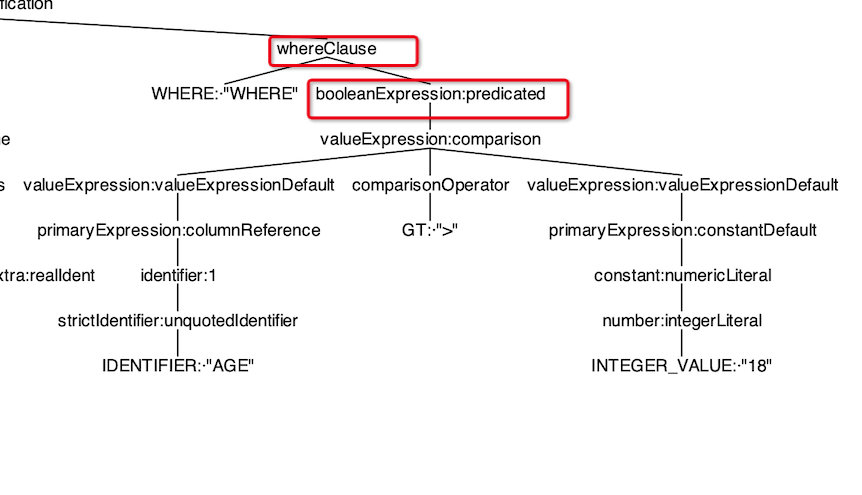
where子节点的递归过程就不再赘述了,最终返回的e = GreaterThan[age > 18]
经过Filter(expression(ctx.booleanExpression), plan)函数,最终拼成一个Filter【logicalPlan】返回给withFilter变量

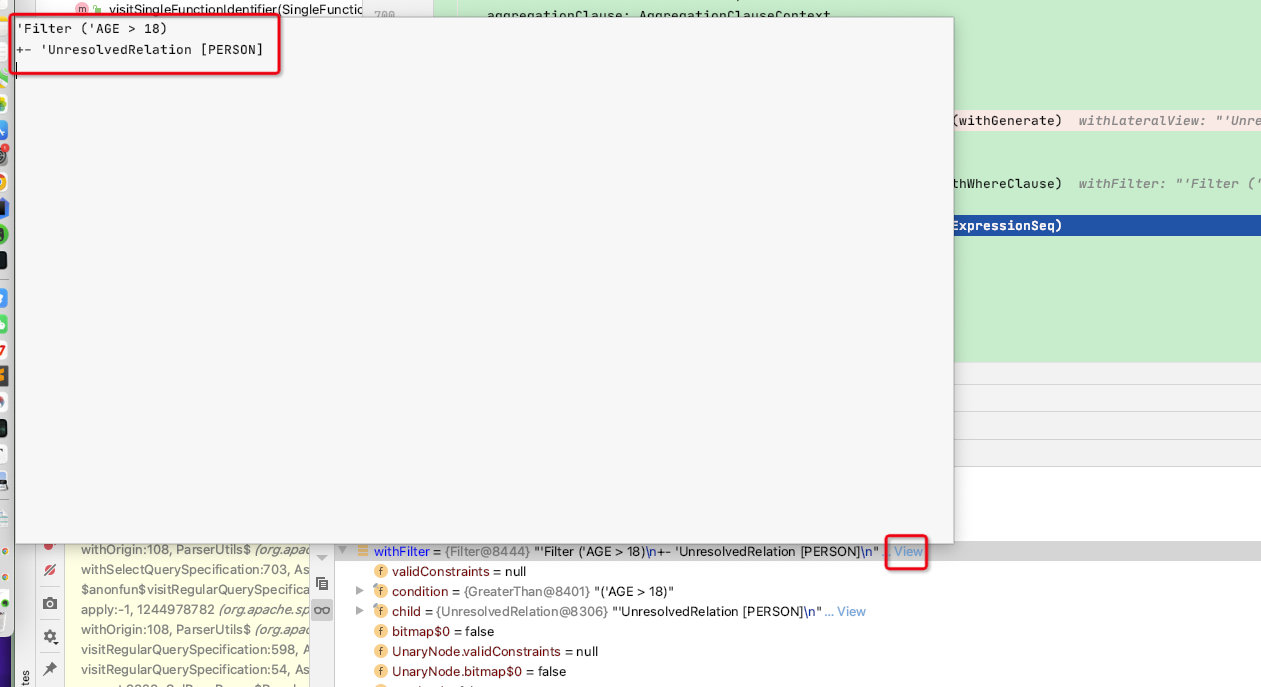
此时的withFilter
然后执行到了expressions变量,调用visitNamedExpressionSeq访问者函数执行namedExpressionSeq子节点:
val expressions = visitNamedExpressionSeq(selectClause.namedExpressionSeq)

此函数依然是递归调用,过程不再赘述,其最终返回:UnresolvedStar
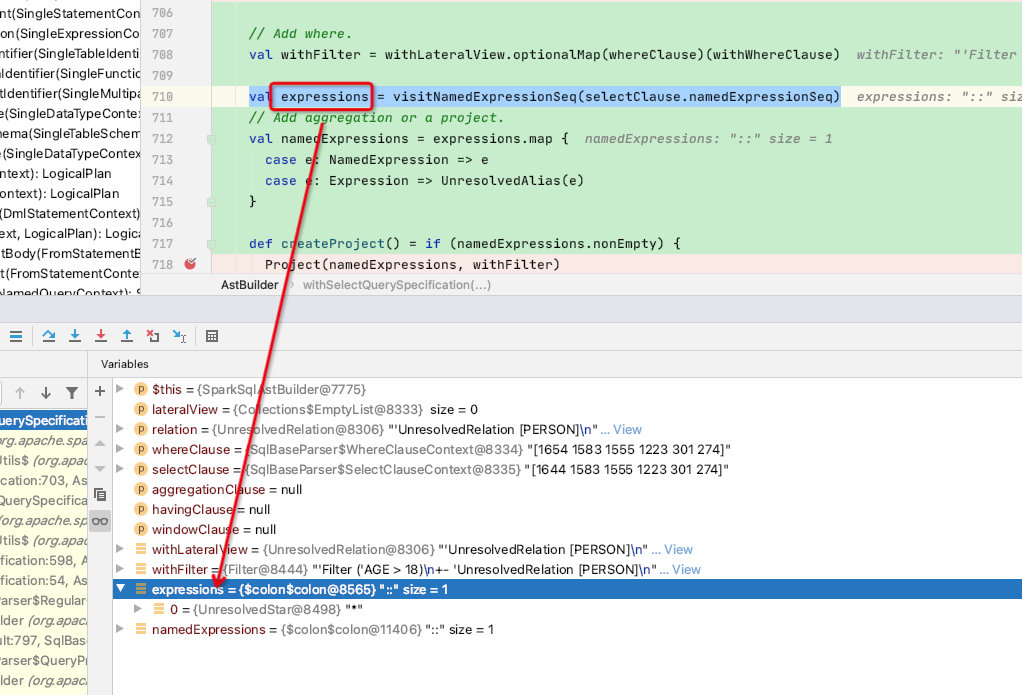
由于聚合函数等条件判断皆不符合,直接访问内部createProject函数
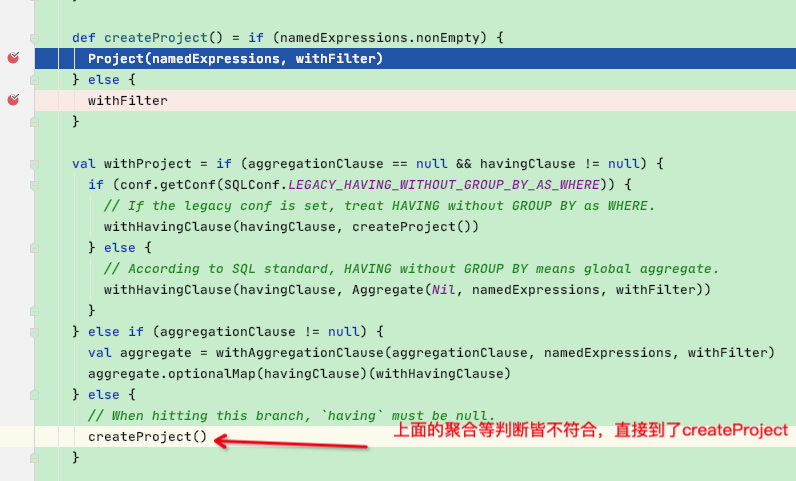
可以看到是将 name 表达式和 filter表达式构成了project【logicalPlan】
Project(namedExpressions, withFilter)
接下来各种语法判断

由于本示例没有用到这些语法,故最终 withSelectQuerySpecification 函数返回为Project【logicalPlan】
同样上层visitRegularQuerySpecification返回为Project【logicalPlan】
层层返回,最终返回到sql函数中,plan返回为 Project【logicalPlan】

可以看出返回的locagicalPlan 完全符合最开始程序打印的explan的结果
== Parsed Logical Plan ==
'Project [*]
+- 'Filter ('AGE > 18)
+- 'UnresolvedRelation `PERSON`
至此sparksql - Unresolved阶段结束
接下来是Analyzer 【resovled logicialPlan】 解析阶段