1、摘要
本项目分为两部分,第一个部分是人脸表情识别任务,第二部分是根据表情变化不同AR脸谱效果。
本文将第一部分,如何使用Keras训练一个人脸表情识别的卷积神经网络。
2、数据集处理
数据集我们使用FER2013PLUS人脸表情识别数据集,大概有35000张图片,每张图片是48*48分辨率的灰度图。

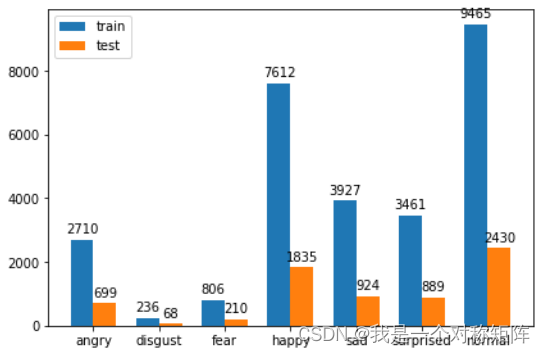
下图展示7个表情类别的数据集样本量,可以看出类别 angry、happy、sad、surprised、normal 这 5 种表情数量较多,而 disgust、fear这 2 种表情较少。
在实验中为了防止出现过拟合现象需要进行数据集扩充,提高模型的泛化能力。数据增强是指对输入的图像进行随机的图像处理,比如旋转、位移、光照强度、裁剪等,对于计算机而言,经过位移后的图像和原图像是两幅不同的图像,但具有相同的标签,从而扩充了已有的数据集。而通过使用大量不同的数据集来训练网络,进一步提高深度模型的泛化能力,使得网络即不过拟合也不欠拟合,达到最佳状态。
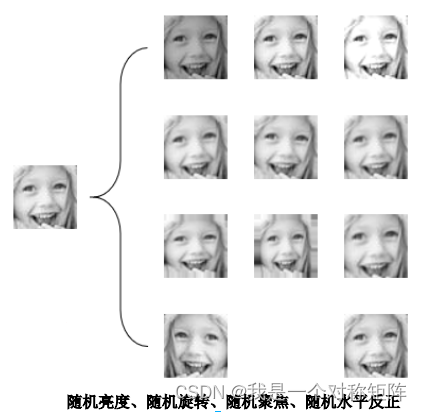
模型的实际使用常见是自由场景,自由场景中光照亮度的不同会影响模型的性能,添加随机光照,同时为了扩充数据集和对非正常角度人脸的识别增加随机旋转、随机聚焦和水平翻转。下图 展示对一张 48*48 尺寸,表情为 happy 的灰度图进行随机亮度、随机旋转、随机聚焦和随机水平翻转的效果。可以看出,小型数据集借此技术可以实现数十倍的规模扩充,而数据集规模的提升可以提升网络的泛化能力和鲁棒性,提高网络在场景下的识别准确率。
在Keras中,我们需要使用数据加载器加载数据,最大化硬件利用率,幸运的是Keras已经提供了方法,我们直接使用即可:
def getDenerator(fer2013plus_path="datasets/fer2013plus", batch_size=32):
"""
我们传递数据集的位置和batch_size,然后函数返回用于训练和测试的数据加载器,用于训练时投喂数据
:param fer2013plus_path:fer2013plus数据集目录
:param batch_size:
:return:
"""
train_datagen = ImageDataGenerator( # 定义数据增强的方式
brightness_range=(0.7, 1.3), # 随机亮度
featurewise_center=False,
featurewise_std_normalization=False,
rotation_range=10, # 随机旋转
zoom_range=(0.7, 1.3), # 聚焦
horizontal_flip=True) # 水平翻转
train_generator = train_datagen.flow_from_directory(fer2013plus_path+"/train", # 告诉Keras图片的位置
target_size=(48, 48), # 将图片缩放到指定大小
color_mode="grayscale", # 因为是灰度图
batch_size=batch_size, # 一次性加载多少图片,越大训练越快,但是需要更多的显存
class_mode='categorical')
test_datagen = ImageDataGenerator() # 水平翻转
test_generator = test_datagen.flow_from_directory(fer2013plus_path+"/test",
target_size=(48, 48),
color_mode="grayscale",
batch_size=batch_size,
class_mode='categorical')
return train_generator,test_generator
3、模型设计
模型设计参考VGG网络,也就是Conv+Conv+Pool式的堆叠。
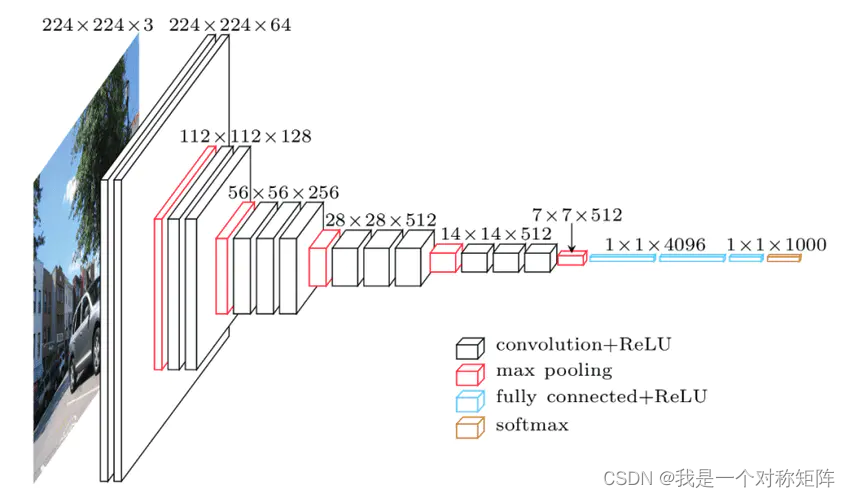
如下图是VGG的结构,可以看出就是Conv+Conv+Pool式的堆叠,最后使用全连接层,实现1000类别的分类。
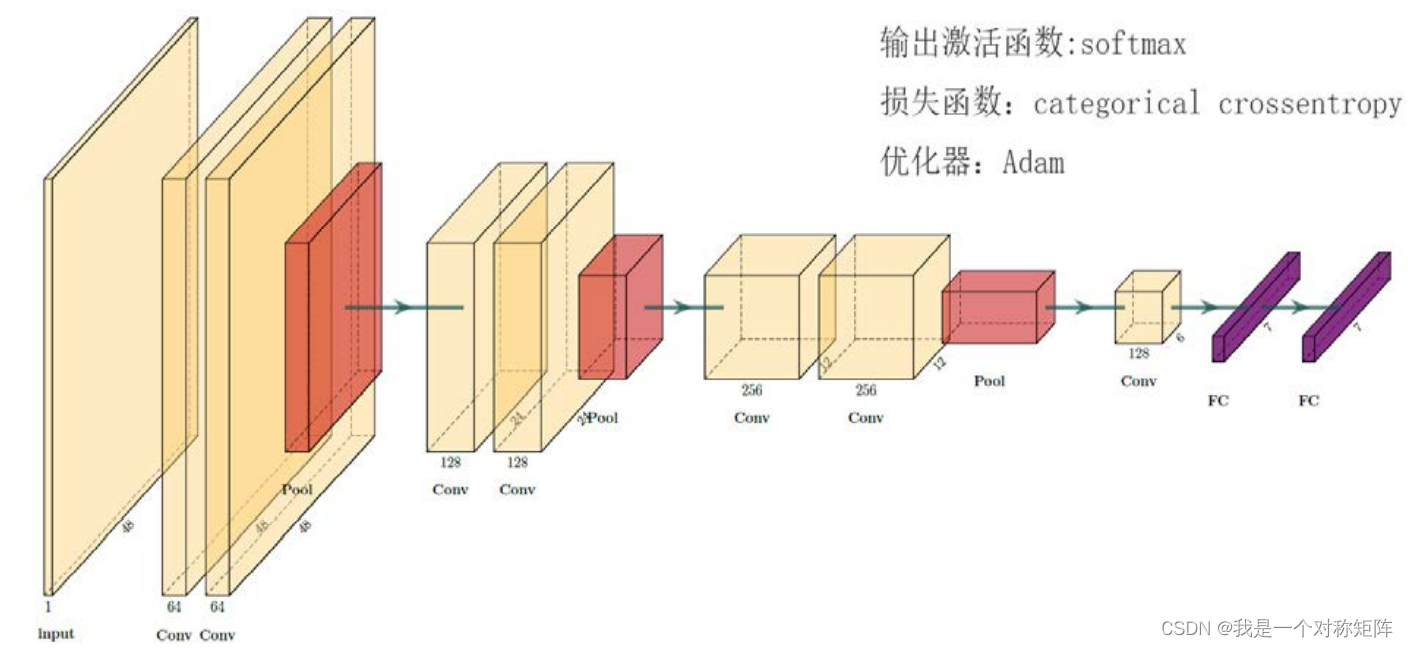
但是我们人脸表情识别数据集比较小,仅有3万多张图片,模型太大容易过拟合,所以以VGGNet为蓝本,设计一个比较小的模型,如下图所示,也是conv+conv+pool式,但是更小。
因为我们的表情是7中分类,所以输出的全连接层长度是7。
在Keras中定义模型结构其实而很简单,代码如下:
def getVXSlim():
model = Sequential()
# block1
model.add(Conv2D(64, (5, 5), input_shape=(48, 48, 1), activation='relu', padding='same'))
model.add(Conv2D(64, (5, 5), activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
# block2
model.add(Conv2D(128, (5, 5), activation='relu', padding='same'))
model.add(Conv2D(128, (5, 5), activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
# block3
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
# single conv
model.add(Conv2D(64, (3, 3), padding='same'))
# classifier
model.add(Flatten()) # 将多维的数据展成一列,可以理解为将图像展开成一列
model.add(Dense(7)) # 堆叠一个全连接层,长度为7
model.add(BatchNormalization())
model.add(Dense(7)) # 堆叠一个全连接层,长度为7
# config
model.add(Activation('softmax')) # 最后使用softmax激活函数,将输出转换为概率
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam') # 定义优化器
return model
在上面的代码中使用了Conv2D、BatchNormalization、MaxPooling2D、Dense:
- Conv2D:提取特征,将图像分解为多个特征的组合
- BatchNormalization:将数据的分布变换为正态分布,再映射到其他分布,可以加快模型的训练速度
- MaxPooling2D:可以缩减图像的尺寸
- Dense:全连接层,用于综合所有特征进行判断类别
4、训练
其实到这里,最重要的数据加载和模型定义就写好了,就可以开始训练了。训练了100个轮次,然后开始训练。
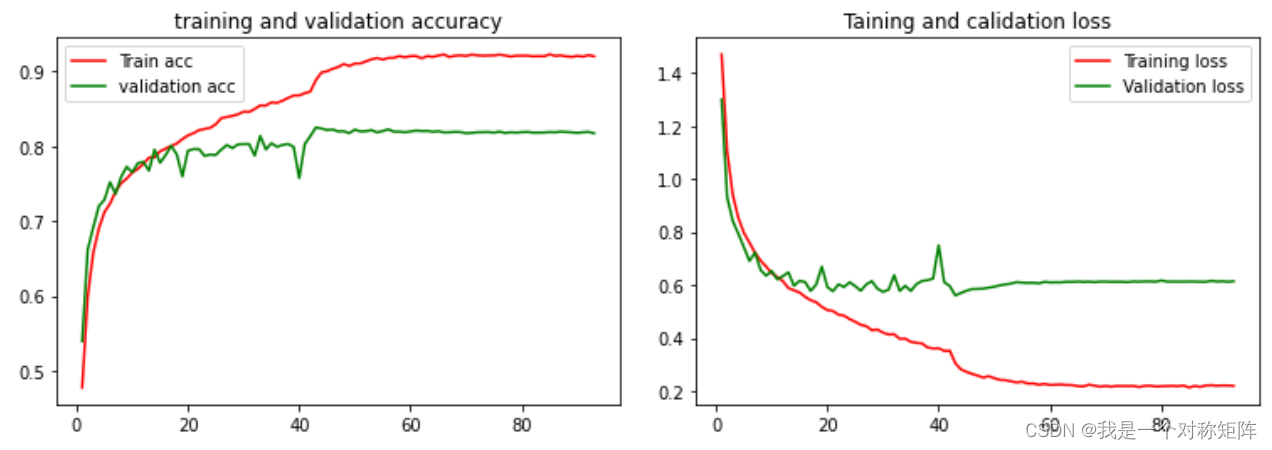
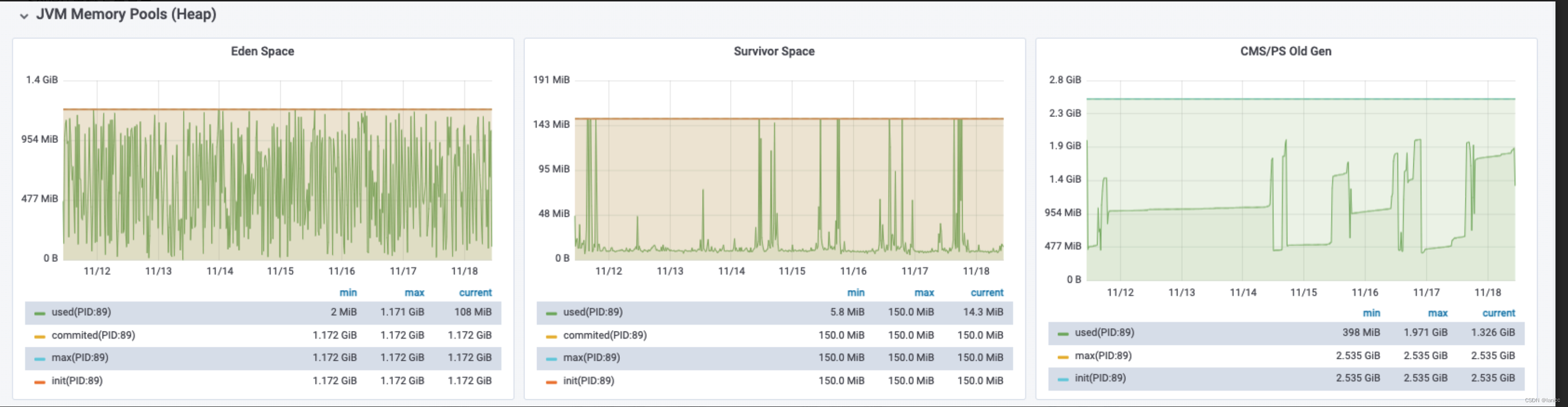
从图中可以看到,训练集精度和损失在 45epoch 左右进入缓慢优化阶段,在 70epoch左右趋于稳定。测试集精度和损失在 45epoch 左右趋于稳定,最终测试集精度达到 83%,损失低于 0.3,取得了较好的表情识别效果。
都说深度学习是黑盒,我们来看看训练出来的模型的可视化效果。
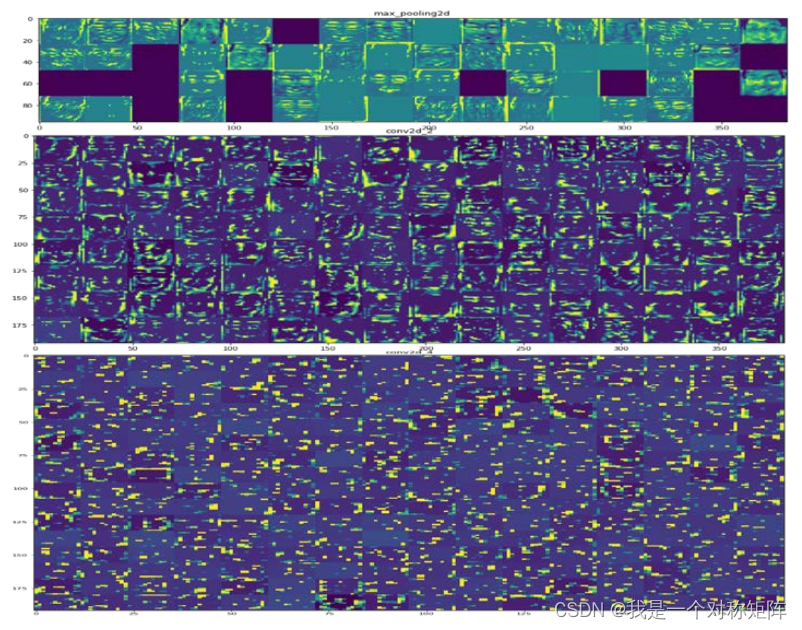
在可视化中间输出部分,通过卷积网络的每层都会输出结果,通过将结果可视化可以看到输入图片在网络中的流动形式,在这里展示第 3 层的 max_pooling2d、第 4 层的conv2d_2 和第 8 层的 conv2d_4 的输出结果。在图 中可以看出,在开始阶段实际上是各种边缘检测器的集合,在这一阶段,激活几乎保留了输入图像中所有的信息。在第二幅中,虽然仍有边缘检测的痕迹,但是此时更加像是对某些局部部位的特征检测,随着层数的加深,中间激活的结果变得越来越抽象,也更加难以直观地理解。在第三层中几乎无法和原图联系起来。所以抽象是卷积神经网络的一大能力,而这种能力也正是人类所拥有的。
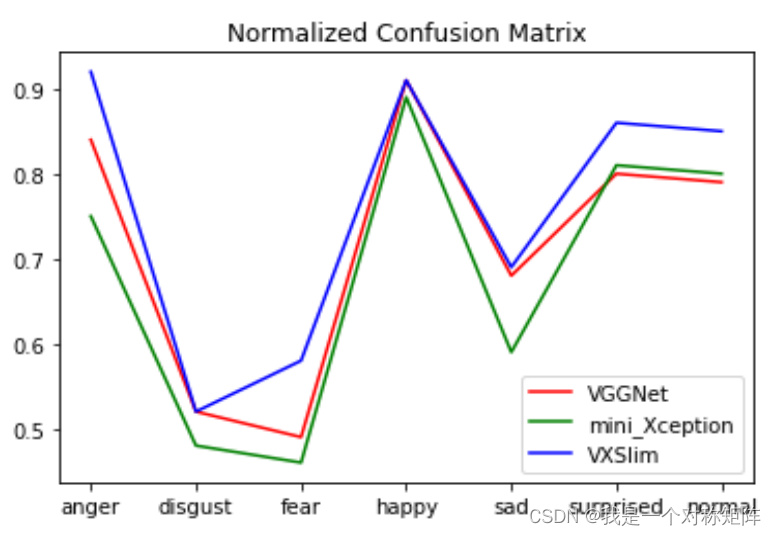
我们将本文设计的模型和VGG9,以及mini_Xception进行对比:

从图中可以看出,本文的VXSlim网络的验证集精度最高,达到了 83%,VGG9 达到了 82%,mini_Xception 最低,只有79%
那么本文的模型在7种表情类别上的效果如何?可以看到最好的是开心类别,正确率达到了91%!
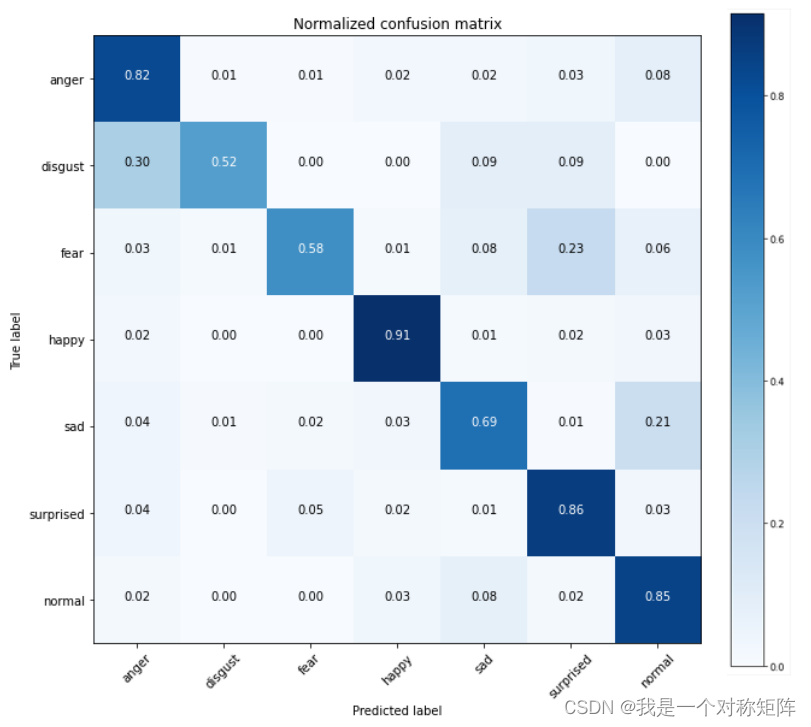
我们把每一个类的正确识别率用曲线表示,可以看到本文设计的模型在7种类别上的正确率都是最高的,很nice!
5、效果展示
通过摄像头进行表情识别效果展示
VXSlim演示_x264












![[附源码]计算机毕业设计JAVA基于web旅游网站的设计与实现](https://img-blog.csdnimg.cn/507ed4bd98ba4f22861e52a1ffb57da8.png)


