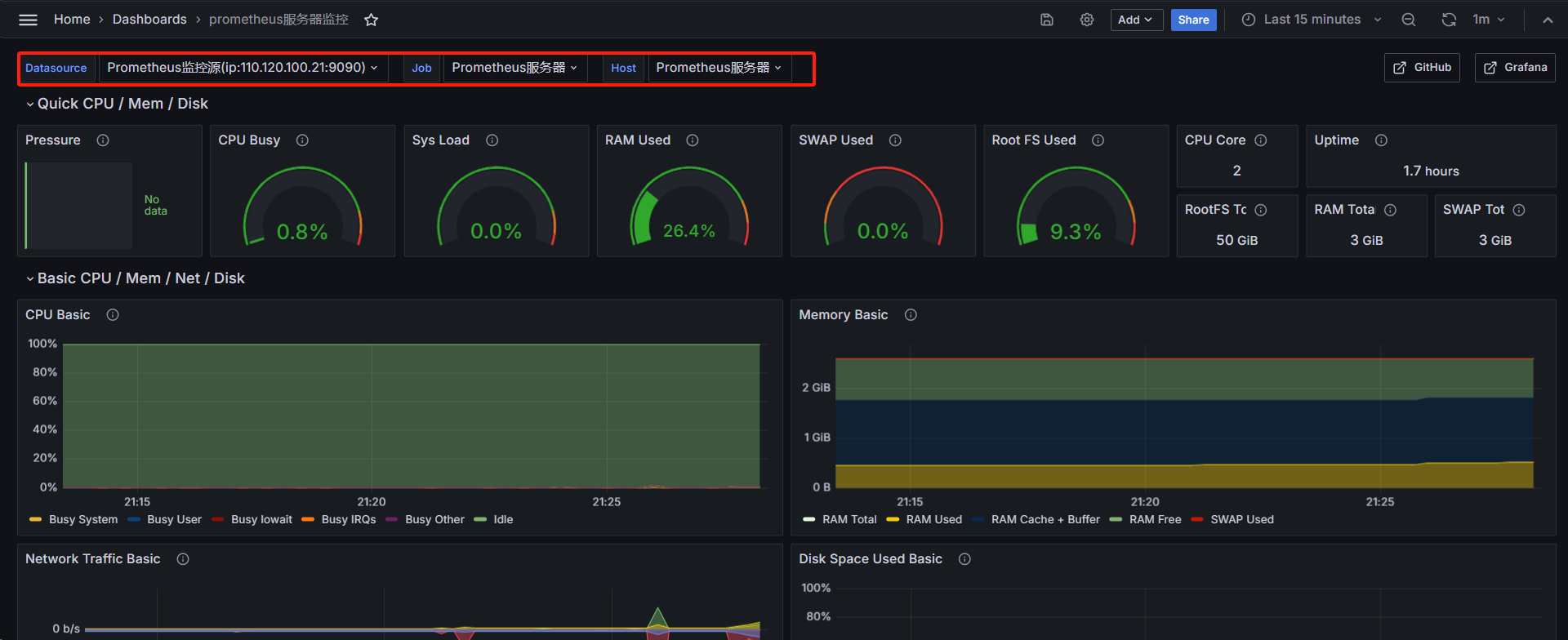
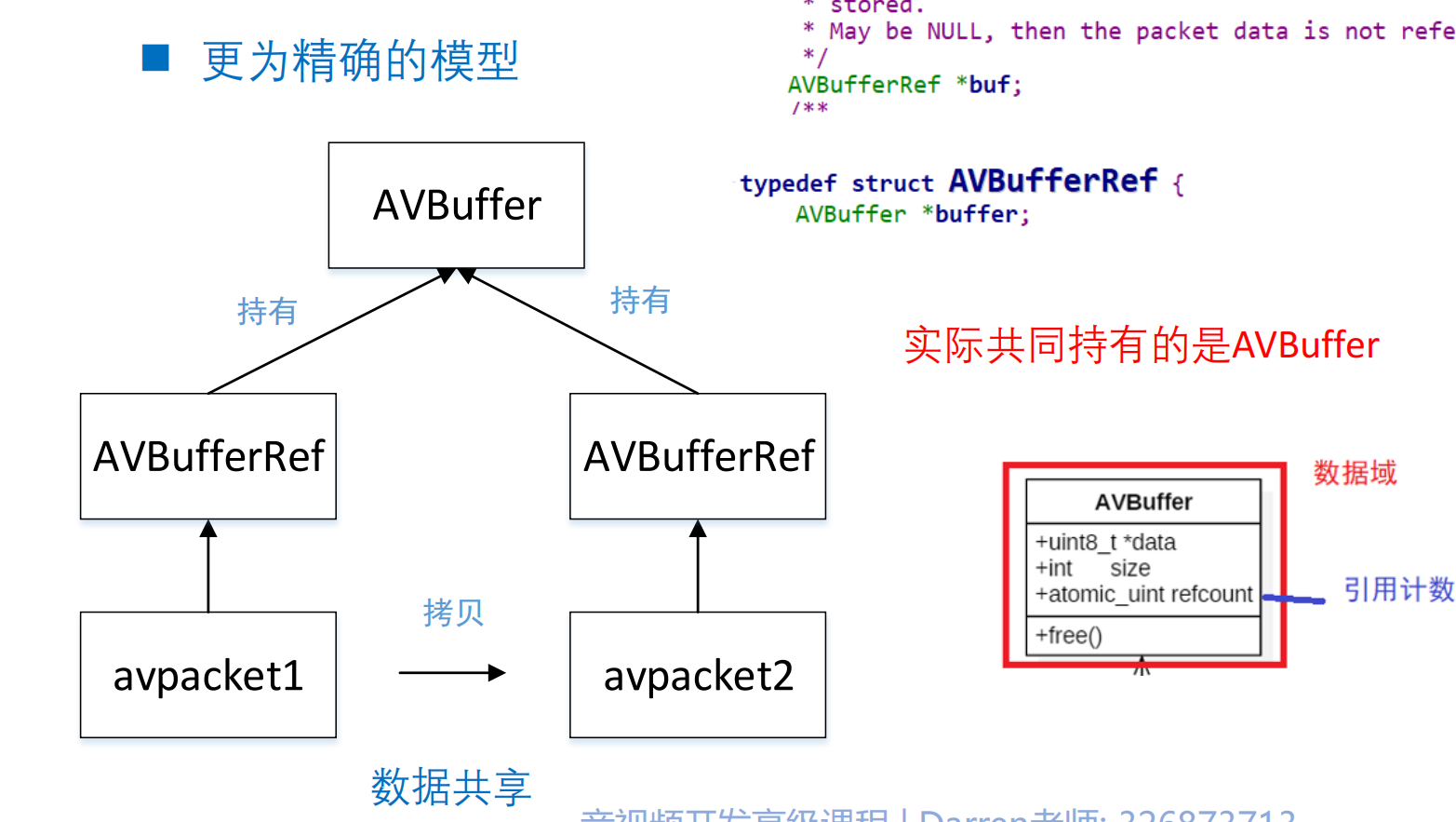
在现代自然语言处理领域,BERT 系列模型不断演进,衍生出多种变体,它们通过改进预训练任务、模型结构和训练策略,在不同应用场景下取得了更优表现。本文首先概览主要 BERT 变体(如 ALBERT、RoBERTa、ELECTRA、SpanBERT、Transformer-XL 等),随后针对以下几个关键问题逐一展开:句序预测(SOP)与下句预测(NSP)的区别;ALBERT 的参数缩减技术及跨层参数共享;RoBERTa 与 BERT 的差异;ELECTRA 中的替换标记检测任务;SpanBERT 的掩码策略;以及 Transformer-XL 如何实现长文本依赖建模。
BERT 变体篇
BERT(Bidirectional Encoder Representations from Transformers)自 2018 年提出以来,其双向 Transformer 架构与掩码语言模型(MLM)+下句预测(NSP)任务的设计,为文本理解任务奠定了基石。在此基础上,各种变体针对模型效率、预训练任务及长文本建模提出了创新:
- ALBERT:引入跨层参数共享与因式分解嵌入,替换 NSP 为句序预测(SOP)任务&#