🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、CUDA为何重要:并行计算的时代
2、NVIDIA在GPU计算领域的角色
二、CUDA简介
1、什么是CUDA
2、CUDA的历史与发展
三、CUDA架构解析
1、GPU vs CPU:架构对比
2、CUDA核心组件
四、CUDA编程模型
1、CUDA程序的基本结构
2、Kernel函数与线程层级
3、内存管理与数据传输(Host ↔ Device)
一、引言
1、CUDA为何重要:并行计算的时代
🧠 单核时代的终结
曾几何时,我们对计算性能的追求是这样的:
“CPU 主频越高越好,单核越强越牛!” 🐎
但摩尔定律渐趋放缓,散热瓶颈越来越明显,频率提升也越来越难……
于是,计算行业悄悄转向了一条新路:并行计算。
🔀 串行 vs 并行:一次做一件事 vs 同时做很多事
| 场景 | 串行(CPU) | 并行(GPU) |
|---|---|---|
| 洗100个苹果 | 一人洗100个 🍎 | 100个人各洗一个 🍎 |
| 图像渲染 | 一像素一像素地算 🐢 | 一次处理上万像素 🚀 |
| 视频编解码 | 一帧帧慢慢处理 🎞️ | 多线程同时压缩处理 📽️ |
🎮 CUDA 的登场:让 GPU 不只是打游戏!
NVIDIA 发现:
“嘿,我们家显卡这么猛,为什么不拿来干点科研的活呢?”
于是他们发布了 CUDA(Compute Unified Device Architecture)

2、NVIDIA在GPU计算领域的角色
💬 “为啥大家一提 GPU 计算就想到 NVIDIA?”
🏆 NVIDIA 在 GPU 计算领域的角色
💡 从显卡厂商到计算王者的转型
在很多人眼中,NVIDIA 一开始只是“做显卡的公司”:
🎮 给游戏加速
🎬 给影视渲染
🎨 给设计师画图更丝滑
BUT!
NVIDIA 真正的雄心,从来不止于此 —— 它要让 GPU 成为 通用计算平台,改变整个计算产业的未来。
📊 市场格局:几乎垄断的存在
| 领域 | NVIDIA 份额(粗略估计) | 代表产品 |
|---|---|---|
| 深度学习训练硬件 | 90%+ | A100、H100、DGX |
| 高性能计算(HPC) | 80%+ | Tesla 系列、NVLink |
| AI 推理 & 云计算加速器 | 快速增长中 | L40、T4、Grace Hopper |

二、CUDA简介
1、什么是CUDA
你有没有想过,电脑里的 显卡(GPU) 除了打游戏、看电影,其实还可以帮我们做科学计算、跑 AI 模型、挖矿(没错,就是你听说过的那个)🤯
这背后,有一项“黑科技”功不可没——CUDA!
🧠 简单来说,CUDA 是什么?
CUDA,全称是 Compute Unified Device Architecture,由 NVIDIA 开发。
通俗点说,它是让显卡“听懂”程序员指令的工具,让 GPU 不只是画画图,还能做“正经数学题”。🎨 ➡️ 📐📊
🎮 CPU vs GPU:一场角色扮演大比拼
| 属性 | CPU(中央处理器)🧑💻 | GPU(图形处理器)🕹️ |
|---|---|---|
| 核心数量 | 少(通常 4~16) | 多(上千个) |
| 单核能力 | 强(能干大事) | 弱(擅长干重复的活) |
| 擅长任务 | 串行处理(一步步来) | 并行处理(群体作战) |
| 应用场景 | 系统操作、逻辑控制等 | 图形渲染、AI计算等 |
举个栗子 🌰:
想象一下,CPU 是“全能型学霸”,擅长一心一用,解决复杂逻辑题;
而 GPU 是“搬砖小能手”,擅长一口气搬 100 块砖,非常适合干重复又密集的活儿,比如矩阵运算、图像处理、深度学习。
👷 CUDA:让程序员调动显卡的“千军万马”
以前 GPU 只能画画图,程序员很难直接让它干别的活。
CUDA 的出现就像给程序员发了一把钥匙🔑,可以“呼叫”GPU,让它帮忙处理计算任务!
✅ 支持 C/C++/Python 编程语言
✅ 你写的代码可以运行在 GPU 上,而不是 CPU
✅ 支持大规模并行运算,速度飞快!
🎯 举个实际例子
假如你要给 1 亿个数字都加上 1。
-
用 CPU:你排队慢慢加,每次处理一个(像银行窗口🙃)
-
用 CUDA + GPU:你开 10,000 个窗口一起加(像春运高速收费站🏁)
速度那叫一个快!
🤖 CUDA 用在哪里?
💡 深度学习模型训练(比如 ChatGPT 的训练就靠它)
🧬 生物医学模拟
🎞️ 视频转码、图像处理
🌍 天气预测、地震模拟、金融风险分析……

2、CUDA的历史与发展
🎬 1. 起点:GPU 只是“画面小工”
🔙 时间回到 2000 年前后——那时的 GPU(比如 GeForce2)基本只是负责“画图”的:
-
把游戏渲染得更炫酷
-
把视频播放得更顺滑
完全是为显示服务的「图形小助手」🎨,离“通用计算”还差十万八千里。
💡 2. 萌芽:聪明人发现“GPU 运算能力好猛!”
在科研圈,有人开始偷偷用 GPU 来做“非图形计算”。他们发现:
✨“这玩意居然跑矩阵比 CPU 快多了?”
那时的 GPU 没有专门支持“通用计算”的编程接口,只能用很复杂的 OpenGL/DirectX Shader 技巧“曲线救国”,开发难度堪比修仙⚒️
🚀 3. 决定性转折:2006 年 CUDA 横空出世
NVIDIA 看到机会来了,果断出手!
🗓️ 2006 年:CUDA 1.0 正式发布!
它是全球第一个面向 GPU 的通用计算平台,程序员终于可以用 C 语言控制 GPU 干活了🔥
从此,GPU 不再是“图形工具人”,而成为了“并行计算的加速王”。
📈 4. 快速进化:从 Fermi 到 Hopper,一代更比一代猛
CUDA 平台与 NVIDIA GPU 架构是配套演进的:
| 年份 | 架构代号 | 特点亮点 |
|---|---|---|
| 2008 | Tesla | 第一代 GPGPU,支持双精度浮点 |
| 2010 | Fermi | 引入 L1/L2 缓存,提升通用计算性能 |
| 2012 | Kepler | 提升能效,支持动态并行 |
| 2016 | Pascal | 加入 Tensor 核心前奏,HPC 友好 |
| 2017 | Volta | 初代 Tensor Cores,AI 训练神器 |
| 2020 | Ampere | 强化 AI 计算,支持多精度并行 |
| 2022 | Hopper | 全面 AI 化身,专为 Transformer 打造 |
| 2024 | Blackwell | 最新旗舰,推理性能暴涨 |
每一代 CUDA Toolkit 也在同步升级,支持更强的编译器、更高级的优化、更丰富的库。
🧠 5. 与 AI 深度绑定:CUDA 成为 AI 的发动机
-
2012:AlexNet 横空出世,用 NVIDIA GTX 580 训练,AI 炸裂出圈💥
-
之后:PyTorch、TensorFlow 等深度学习框架,几乎都离不开 CUDA 后端
-
现在:从 ChatGPT 到 Stable Diffusion,背后 GPU 加速都是靠 CUDA ✊
🧩 6. 今日 CUDA:不仅仅是一个库,更是一整个宇宙
CUDA 不再只是“让 GPU 干活”,它成了一个完整的开发生态:
-
📦 各种库:cuDNN、cuBLAS、TensorRT、NCCL…
-
🧰 工具链:Nsight、Visual Profiler、CUDA Graph…
-
🌍 平台支持:从嵌入式 Jetson 到数据中心 DGX 全都能用

CUDA 的成长 = 从一把螺丝刀 🪛 ➡️ 到一整套核武库 💣
它改变了 GPU 的命运,也重新定义了“计算”的方式。
今天,如果你说你搞 AI、做科学计算、研究机器学习,却没听说过 CUDA——那就像学魔法不知道哈利波特🧙♂️。
三、CUDA架构解析
1、GPU vs CPU:架构对比
在 CUDA 的世界里,最常听到的问题之一就是:
“既然我有 CPU,为什么还要用 GPU 来计算呢?”
这个问题就像问:
“我有一辆小轿车,为什么还需要火车?”🚗 vs 🚄
它们各有专长!CPU 和 GPU 不是谁更好,而是适合干不同的活。
🏗️ 架构对比:一个是多面手,一个是并行狂魔
| 特性 | 🧑💻 CPU(中央处理器) | 🕹️ GPU(图形处理器) |
|---|---|---|
| 核心数量 | 少(4~16个高性能核心) | 多(数百到上万个) |
| 每个核心的能力 | 强,能处理复杂指令 | 弱,专注简单重复计算 |
| 控制单元 | 多,负责调度和决策 | 少,更依赖外部控制 |
| 缓存系统 | 大,层次复杂(L1/L2/L3) | 小而专注 |
| 适合的任务类型 | 串行任务、多任务处理 | 数据并行、大规模计算 |
| 延迟 vs 吞吐量 | 低延迟、决策快 | 高吞吐、批量处理猛 |
| 编程难度 | 简单,工具成熟 | 相对复杂(CUDA等) |
| 举个例子 | 跑操作系统、打开网页 | 训练 AI、视频渲染 |
🧩 用生活举个例子!
-
CPU 像一位博士👨🎓:一个人能力特别强,但只能一心一用,适合解决逻辑复杂、步骤多的问题。
-
GPU 像一群工人👷♂️👷♀️:单个能力可能不高,但可以分工协作,把重复性的任务快速干完,效率爆表!
💡 实际场景谁上场?
| 场景 | 谁更合适 |
|---|---|
| 打开浏览器、运行操作系统 | ✅ CPU |
| 视频渲染、图形处理 | ✅ GPU |
| 训练深度神经网络(AI) | ✅ GPU |
| 数据库查询、事务处理 | ✅ CPU |
| 模拟气候、科学建模、并行计算 | ✅ GPU |
| 编译代码、跑脚本 | ✅ CPU |
| 游戏里的实时光影渲染 | ✅ GPU |
🚦 并行模型上的区别
| 特性 | CPU | GPU |
|---|---|---|
| 并行粒度 | 粗粒度(每核处理独立任务) | 细粒度(线程块内高度同步) |
| 指令模型 | MIMD(多指令多数据) | SIMT(单指令多线程) |
| 控制逻辑 | 多样化、复杂 | 简化、统一控制 |
📘 名词解释:
-
MIMD:每个核心都可以执行不同的指令
-
SIMT:多个线程执行相同的指令,但处理不同的数据
🧠 小结一句话!
CPU 负责“聪明的决策”,GPU 擅长“傻快的计算”
它们不是敌人,而是互补搭档,现代计算中通常是搭配使用的!
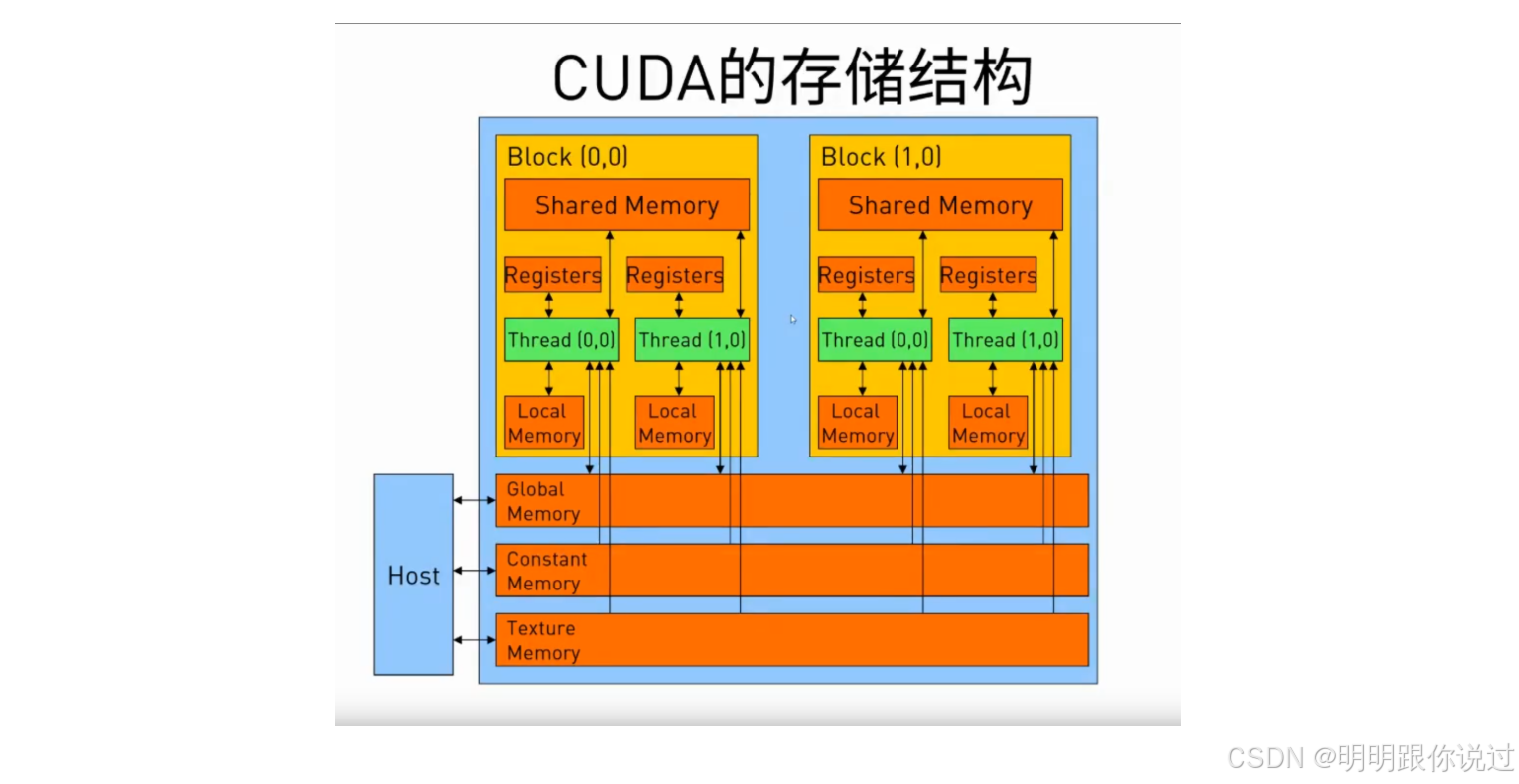
2、CUDA核心组件
🔧 CUDA 核心组件:构建 GPU 编程的四大金刚
你可以把 CUDA 想象成一个“GPU 软件开发的操作系统”,它不是一个单一的程序,而是由一整套核心组件组成的“超级工具箱”。
下面我们来看看构成 CUDA 的四大金刚 🔥
1️⃣ CUDA Runtime API(运行时 API)
💬 它是开发者最常打交道的接口,是你用 C/C++ 写 CUDA 程序的“入口”。
📌 功能包括:
-
GPU 内存分配和释放(
cudaMalloc/cudaFree) -
设备信息查询(
cudaGetDeviceProperties) -
启动 kernel(
<<< >>>语法就是它支持的)
🧠 类比一下:
就像你用 Python 写脚本,Python 帮你处理内存、线程这些底层细节,CUDA Runtime API 就是帮你“简单调用 GPU”。
2️⃣ CUDA Driver API(驱动层 API)
🛠️ 更底层、更灵活、更复杂。适用于需要细粒度控制 GPU 资源的场景。
📌 功能包括:
-
设备初始化与上下文管理(更手动)
-
加载 PTX、模块化内核编程
-
编译时更灵活地控制 GPU 行为
🎯 谁在用?
-
深度学习框架开发者(例如 PyTorch 底层封装)
-
系统级别的 GPU 控制和调优
🧠 类比一下:
Runtime API 是自动挡 🚗,Driver API 是手动挡赛车 🏎️,能玩得更极限,但也更难操作。
3️⃣ CUDA 核函数(Kernel Function)
🚀 这是你写的代码真正运行在 GPU 上的“主力部队”。
📌 特点:
-
用
__global__关键字声明 -
用
<<<grid, block>>>语法来启动(指定并行粒度) -
每个线程独立执行一份 kernel 的代码
🧠 类比一下:
Kernel 像是“工厂车间的流水线工人”👷,你一次下达指令,成百上千个“工人”在不同岗位同步干活。
__global__ void add(int *a, int *b, int *c) {
int i = threadIdx.x;
c[i] = a[i] + b[i];
}4️⃣ CUDA 内存模型(Memory Model)
💾 GPU 的内存系统是多层次的,用得好 = 性能飞起🚀
| 类型 | 特性 | 示例 |
|---|---|---|
| Global Memory | 所有线程可访问,容量大,访问慢 | cudaMalloc 分配的内存 |
| Shared Memory | 每个线程块共享,访问速度快 | 用 __shared__ 声明 |
| Local Memory | 每线程独享,实为全局空间 | 局部变量(寄存器不足时) |
| Registers | 每线程专属,最快 | 编译器自动分配 |
| Constant Memory | 只读缓存,供所有线程共享,适合常量传递 | __constant__ |
| Texture/Surface | 专用于图像处理,带缓存优化 | 适合做图像/矩阵采样等 |
🧠 类比一下:
内存就像厨房里的原料分区,寄存器是你手边的调料台,Global memory 是仓库,Shared memory 是工位中间的调料包。
四、CUDA编程模型
1、CUDA程序的基本结构
🧱 CUDA 程序的基本结构:从 CPU 到 GPU 的“打工外包流程”
要写一个 CUDA 程序,其实核心流程就一句话:
🗣️ 主程序在 CPU 上运行,但把计算“打包”交给 GPU 干
下面我们一步步拆解这个“GPU 打工队”的工作流程 👷♂️
🧭 基本结构总览(5 个步骤)
一个典型 CUDA 程序结构可分为以下 5 步:
1️⃣ 准备数据(在 CPU 上)
2️⃣ 分配 GPU 内存并复制数据(Host ➡ Device)
3️⃣ 编写并调用 CUDA 核函数(Kernel)
4️⃣ 把计算结果从 GPU 拷回 CPU(Device ➡ Host)
5️⃣ 释放内存资源,程序结束
🧪 示例:两个数组相加(Vector Add)
我们用一个经典的例子来演示 CUDA 程序的完整结构:向量加法
📌 功能:
c[i] = a[i] + b[i];🧾 完整代码框架:
#include <stdio.h>
#include <cuda_runtime.h>
// CUDA 核函数:每个线程负责加一个元素
__global__ void vectorAdd(int *a, int *b, int *c, int n) {
int i = threadIdx.x;
if (i < n)
c[i] = a[i] + b[i];
}
int main() {
const int N = 10;
int a[N], b[N], c[N]; // 在 CPU(host)上的数组
int *d_a, *d_b, *d_c; // GPU(device)上的指针
// 初始化数据
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * 2;
}
// 1. 分配 GPU 内存
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
// 2. 拷贝数据到 GPU
cudaMemcpy(d_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, N * sizeof(int), cudaMemcpyHostToDevice);
// 3. 启动 Kernel(让 GPU 干活!)
vectorAdd<<<1, N>>>(d_a, d_b, d_c, N);
// 4. 把结果拷回 CPU
cudaMemcpy(c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
// 5. 打印结果
printf("Result:\n");
for (int i = 0; i < N; i++)
printf("%d + %d = %d\n", a[i], b[i], c[i]);
// 6. 释放 GPU 内存
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}🧠 每步拆解说明:
| 步骤 | 内容 | 说明 📝 |
|---|---|---|
| 1 | cudaMalloc | 在 GPU 上申请内存 |
| 2 | cudaMemcpy(Host ➡ Device) | 把 CPU 数据传给 GPU |
| 3 | <<<blocks, threads>>> 启动 kernel | 设置并行维度、执行函数 |
| 4 | cudaMemcpy(Device ➡ Host) | 把结果从 GPU 拷回 CPU |
| 5 | cudaFree | 清理资源,避免内存泄露 |
🔍 补充:线程模型简要说明
-
<<<1, N>>>:意思是启动 1 个 block,每个 block 有 N 个线程 -
threadIdx.x:获取当前线程在 block 中的编号(0 ~ N-1)
🧠 可以把每个线程想成一个“工人”,threadIdx.x 就是工号,它负责数组中第几个元素的加法。
📦 小贴士:想学得更好,可以试试…
-
把
N改大点,看 GPU 性能 -
改成 2D/3D grid/block,理解多维并行
-
加个计时器看看 GPU 比 CPU 快多少(
cudaEvent)
✅ 小结一句话!
CUDA 程序结构 = 在 CPU 上安排好任务,然后启动成千上万个线程去 GPU 上“并行开工”💪

2、Kernel函数与线程层级
🧩 Kernel 函数与线程层级:并行计算的发动机 🚀
在 CUDA 编程中,我们不会一个个处理数据,而是:
把任务切片,丢给成千上万个线程同时运行!
这些线程由 GPU 上的 Kernel 函数统一调度执行。那么:
-
什么是 Kernel 函数?
-
怎么安排线程分工?
-
什么是 Block、Grid、Thread?
接下来逐一拆解!
🔧 什么是 Kernel 函数?
Kernel 是 CUDA 程序中由 GPU 执行的函数,它是并行计算的核心。
__global__ void myKernel(...) {
// 每个线程执行这段代码
}🔹 __global__ 关键字告诉编译器:
这个函数运行在 GPU 上,但可以被 CPU 调用。
🔹 启动方式:
myKernel<<<gridSize, blockSize>>>(...);这不是语法糖,而是在告诉 CUDA:
“我要启动多少线程来跑这个函数。”
🧱 线程的三层层级结构
CUDA 中线程的组织就像军队建制,非常有层级感:
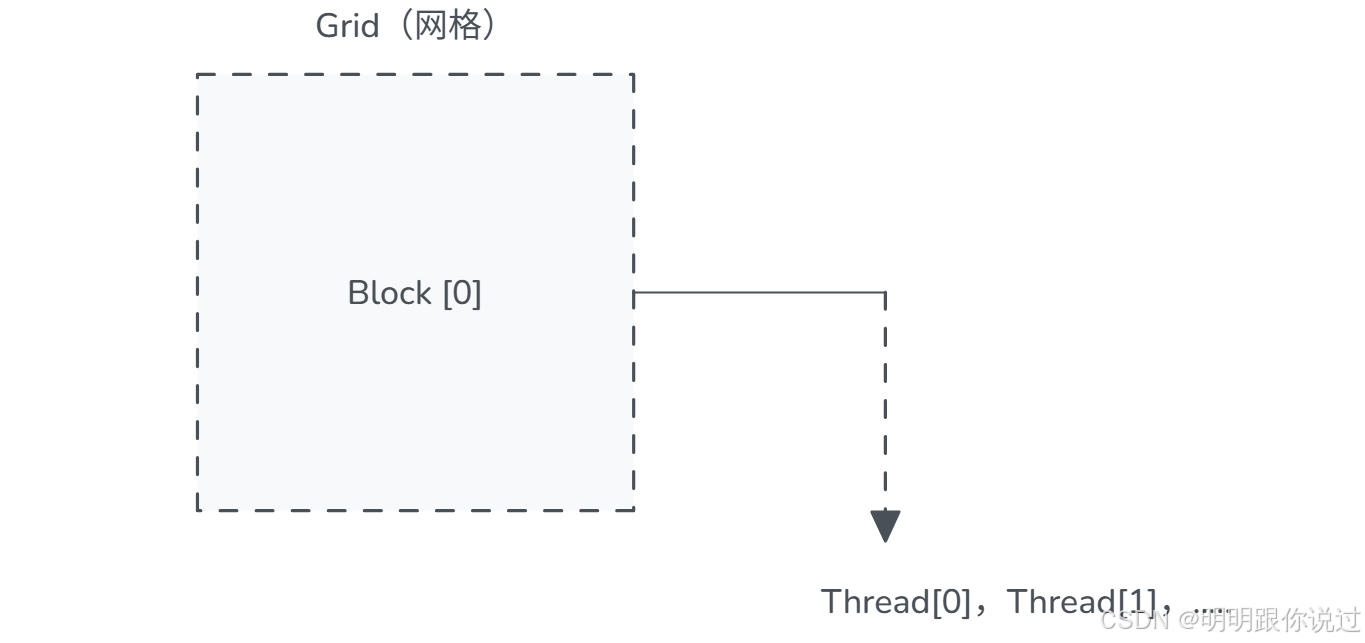
| 层级 | 作用说明 | 举例(1D) |
|---|---|---|
| Grid | 由多个 Block 组成(可以是1D/2D/3D) | 一个网格网(任务总量) |
| Block | 一个线程块,包含若干线程 | 一组线程在同一块中 |
| Thread | 最小执行单位 | 每个处理一小段任务 |
🧠 类比一下:
-
Grid:公司里的整个部门 🏢
-
Block:每个小组 👥
-
Thread:组员 👤
🧮 每个线程怎么知道“我是谁”?
CUDA 提供了 3 个内置变量,线程启动时自动可用:
| 变量 | 说明 | 类型 |
|---|---|---|
threadIdx | 当前线程在 Block 中的索引 | uint3 |
blockIdx | 当前 Block 在 Grid 中的索引 | uint3 |
blockDim | 每个 Block 有多少线程 | dim3 |
gridDim | Grid 中有多少个 Block | dim3 |
🧠 小结一句话!
Kernel 是执行体,Grid 是组织方式,Thread 是计算单位
你写一次 Kernel,CUDA 帮你复制成千上万份“工人”去同时执行💥

3、内存管理与数据传输(Host ↔ Device)
💾 内存管理与数据传输(Host ↔ Device)
在 CUDA 编程中,CPU(Host) 和 GPU(Device) 是两套完全独立的世界,它们各自有自己的内存空间:
🧠 CPU 内存 = 主内存(RAM)
🎮 GPU 内存 = 显存(VRAM)
CUDA 编程最重要的一步就是:
想办法把数据在 Host 和 Device 之间“搬来搬去” 🚚
🧭 你必须搞懂的三件事:
| 内容 | 作用 | 类比(搬砖打工) |
|---|---|---|
cudaMalloc() | 在 GPU 上分配显存 | 给 GPU 准备砖堆 🧱 |
cudaMemcpy() | Host ↔ Device 数据传输 | 搬砖车来回运材料 🚛 |
cudaFree() | 释放 GPU 分配的内存资源 | 工地收工,清理现场 🧹 |
🧪 示例代码:准备一批数据送去 GPU 加工
const int N = 100;
int a[N], b[N], c[N];
int *d_a, *d_b, *d_c;
// 1. 在 GPU 上分配内存
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
// 2. 把 CPU 上的原材料送到 GPU
cudaMemcpy(d_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, N * sizeof(int), cudaMemcpyHostToDevice);
// 3. 执行 Kernel 计算(略)
// 4. 把结果从 GPU 拷回 CPU
cudaMemcpy(c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
// 5. 清理资源
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);🚥 cudaMemcpy 的四种传输方向
| 常量名 | 从哪传 → 传到哪 | 场景 |
|---|---|---|
cudaMemcpyHostToDevice | 🧠 CPU → 🎮 GPU | 把数据送去计算 |
cudaMemcpyDeviceToHost | 🎮 GPU → 🧠 CPU | 拿结果回来用 |
cudaMemcpyDeviceToDevice | 🎮 GPU → 🎮 GPU | GPU 内部数据拷贝 |
cudaMemcpyHostToHost | 🧠 CPU → 🧠 CPU | 和普通 memcpy 类似 |
📦 内存管理流程图(逻辑图)
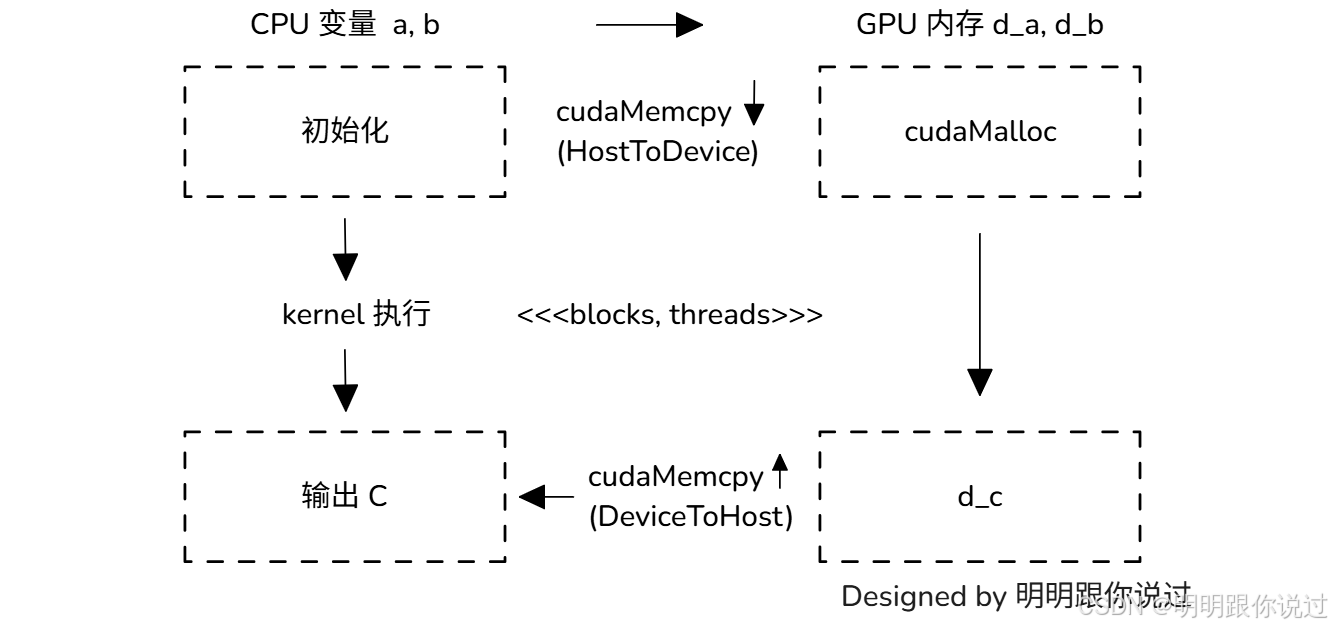
✅ 小结一句话
CUDA 内存管理 = 分配 + 拷贝 + 回收,像操作 GPU 的物流仓库一样💼
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!