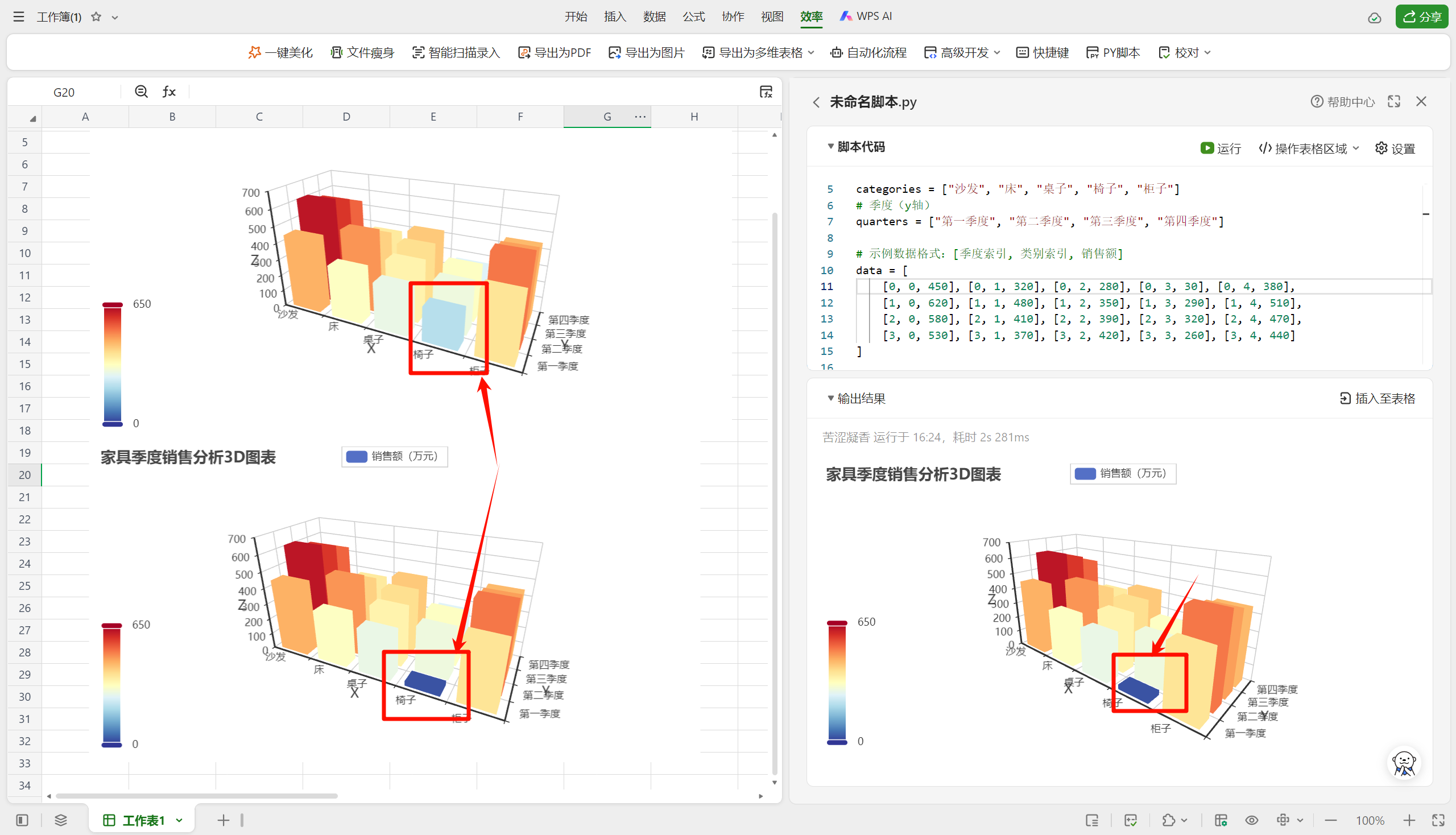
在使用selenium做网站爬取测试的时候,我们经常会遇到一些需要点击的元素,才能点击到我们想要进入的页面,
于是我们就要模拟 不断地 点点点击 鼠标的样子。
这个时候网页上就会有很多的标签页,你的浏览器网页标签栏 be like:

那么,怎么切换页面,并返回到上一页呢?
- 打包切换页面的逻辑
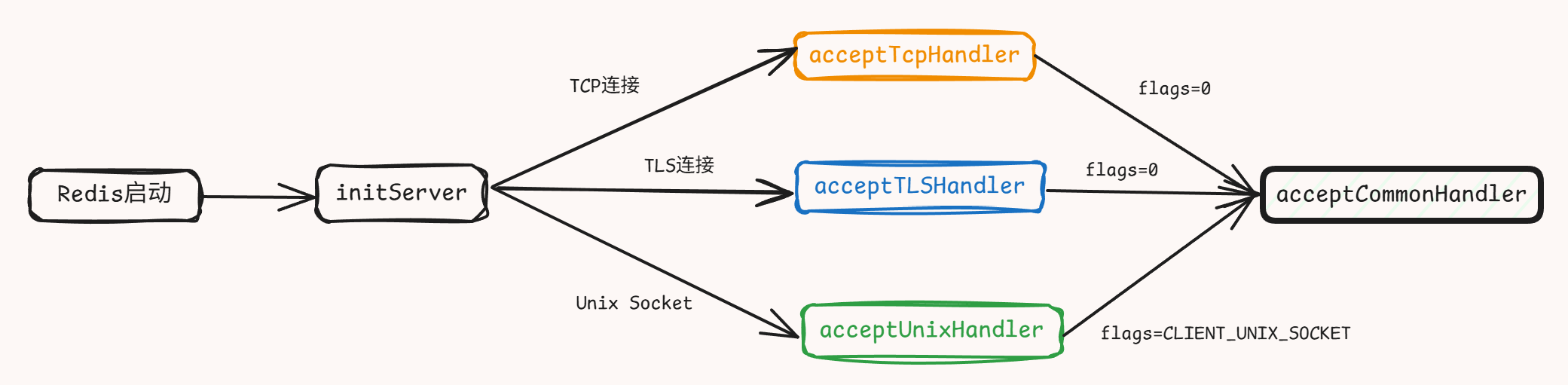
def switch_windows(index):
#获取当前句
current_window_handle = driver.current_window_handle
print(current_window_handle )
#获取所有句柄
all_handles = driver.window_handles
print(all_handles )
#切换至第二个窗口
driver.switch_to.window(all_handles [index])
print(driver.title) #获取目前内容页的信息
- 点击按钮跳到下一页 --> 切换到新页面 -->操作新页面内容 --> 返回上一页
#点击按钮,跳转到下一个页面
element=driver.find_element(By.XPATH,input_)
element.click()
#切换到最后一个页面-新页面
switch_windows(index=-1)
#读取页面的信息
sleep(1)
page_html=driver.page_source
page_soup=BeautifulSoup(page_html,'lxml')
#返回首页
switch_windows(index=0)
除了用点击到下一页的方法,也可以模拟标签点开的方法(强推!!!好用)
原理是,网页模拟点开标签,然后把网址输入进去的过程
driver.execute_script("window.open('https://www.google.com')") # 新标签页1
driver.execute_script("window.open('https://www.python.org')") # 新标签页2
- 返回首页以后,我们要把后面不用的其他标签页关闭掉:
# 获取所有标签页的句柄(handles)
all_handles = driver.window_handles # 返回所有标签页的ID列表
homepage_handle = all_handles[0] # 首页通常是第一个标签页
# 关闭其他标签页(保留首页)
for handle in all_handles:
if handle != homepage_handle: # 如果不是首页
driver.switch_to.window(handle) # 切换到该标签页
driver.close() # 关闭它
# 最后切换回首页
driver.switch_to.window(homepage_handle)
print("已关闭其他标签页,仅保留首页")
- 如果不确定在读取页面的时候,是不是读取到自己想要的那个网址,可以使用读取网址的方式判断:
print("当前页面URL:", driver.current_url)
也可以跟自己的目标网址做判断,如果不对的话,则切换到上一个界面
current_url= driver.current_url
if current_url != target_url:
switch_windows(index=-2) #比最后一个网址再上一个页面
这部分内容在【返回首页】的代码之前,效果如:

PS:
一些网站的HTML内部会设置一些【点击事件处理属性】,
当用户点击这个元素时,会触发 onclick 中定义的 JavaScript 代码,类似下面的代码。
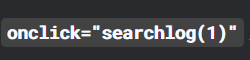

这种可能就要点击网页上的元素,才能获取网络响应,直接跳转到该网址上,是行不通的,可能会被发现爬虫,然后强制跳转到其他的网页页面上。
这个时候,只能用上面的方法了。
如果有更好的方法,可以解决如上的问题的话,希望大家可以提出来呀,感谢不尽!!