1. 背景
技术工单(Support Case)是企业在进行云平台操作的时候通常会用到的一种技术支持类型,提供的技术支持通常包括所有的云服务的使用问题、账单问题、限制额度提升等等。对于云平台的管理者而言,对各个 BU 所提的工单进行统计管理和分类,可以更好地追踪各个 BU 的服务使用情况、大家的知识短板、责任划分等等,并且将分析结果实施呈现在 BI 报表中,方便云平台团队更好地对大家进行功能辅助。
2. 整理和分析技术支持工单的意义
-
识别常见问题:通过分析大量案例,可以发现哪些问题最常见,帮助团队针对这些问题提供更好的文档支持或改进服务。
-
知识库建设:将解决问题的方法和经验记录下来,形成企业内部知识库,以便在未来遇到类似问题时能够快速找到解决方案。
-
制定培训计划:如果分析发现某些问题频繁出现,可以为支持团队制定针对性的培训计划,提升团队的技术水平。
-
报告与决策支持:总结分析的结果可以用于内部报告,支持管理层的决策,尤其是在资源分配和服务策略调整方面。
-
预测未来需求:通过分析过去的工单,可以预测未来可能出现的需求或问题,提前准备资源和解决方案。
3. 解决方案概述
架构图:
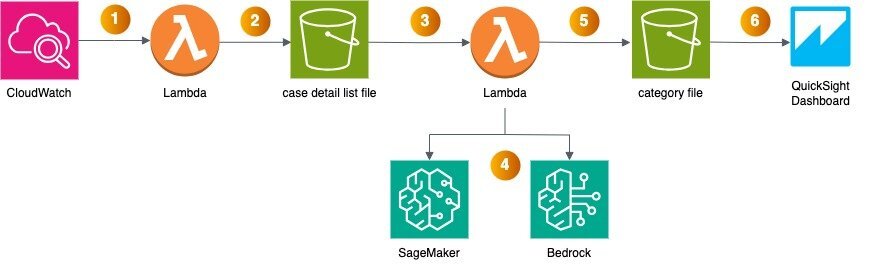
组件描述:
-
Amazon EventBridge 定时触发 Amazon Lambda,可以在一周、一个月甚至更长的时间内进行 Lambda 的定时触发,通过 Support API(至少需要订阅商业级支持)进行 Support Case 的整理工作。
-
Lambda 中的代码将提取 Support Case 的列表和具体内容,并将以 csv 格式存储到 Amazon S3 桶,形成当前周期 Support Case 的列表文件。
-
S3 上新增的 Support Case 文件将触发一个新的 Lambda,该 Lambda 将会执行大语言模型的调用工作。
-
Lambda 将调用 Amazon Sagemaker(中国区)或者 Amazon Bedrock(海外区)进行 Support Case 的根因分析。
-
分析好的根因可以发送到 Amazon QuickSight Dashboard 进行可视化展示和分析。
4. 部署说明
1、对于订阅了企业级和准企业级支持的客户,可以直接联系您的 TAM 来完成 Support Case 整理工作. 商业级支持的客户可通过 Support API 拉取最近的 Support Case,将 Case 的元数据直接生成 csv 存到 S3,每个 Case 的回复内容整理成以 Case 命名的 txt 文件存到 S3。示例代码如下:
import boto3
from datetime import datetime, timedelta
import pandas as pd
import io
bucket_name = 'support-case-blog'
date = datetime.now().strftime("%Y-%m")
# support api ak/sk
aws_access_key_id = "ak"
aws_access_key_id = "sk"
# s3 bucket ak/sk
aws_access_key_id1 = "ak1"
aws_access_key_id1 = "sk1"
session = boto3.Session(
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name='cn-north-1'
)
session1 = boto3.Session(
aws_access_key_id=aws_access_key_id1,
aws_secret_access_key=aws_secret_access_key1,
region_name='cn-north-1'
)
s3_client = session1.client('s3')
# 创建support客户端
support_client = session.client('support')
# 计算2年前的日期
two_years_ago = datetime.now() - timedelta(days=730)
# 设置过滤器
filters = [
{
'name': 'AfterTime',
'values': [
two_years_ago.strftime('%Y-%m-%dT%H:%M:%SZ')
]
}
]
# 获取案例列表
def get_cases():
cases = []
next_token = ''
while True:
if next_token:
response = support_client.describe_cases(
includeCommunications=True,
includeResolvedCases=True,
afterTime=two_years_ago.strftime('%Y-%m-%dT%H:%M:%SZ'),
nextToken=next_token
)
else:
response = support_client.describe_cases(
includeCommunications=True,
includeResolvedCases=True,
afterTime=two_years_ago.strftime('%Y-%m-%dT%H:%M:%SZ')
)
cases.extend(response['cases'])
if 'nextToken' in response:
next_token = response['nextToken']
else:
break
return cases
def get_communications(caseId):
communications = []
next_token = ''
while True:
if next_token:
response = support_client.describe_communications(
caseId = caseId,
afterTime=two_years_ago.strftime('%Y-%m-%dT%H:%M:%SZ'),
nextToken=next_token
)
else:
response = support_client.describe_communications(
caseId = caseId,
afterTime=two_years_ago.strftime('%Y-%m-%dT%H:%M:%SZ'),
)
communications.extend(response['communications'])
if 'nextToken' in response:
next_token = response['nextToken']
else:
break
return communications
# 创建一个空的list
data = []
cases = get_cases()
# 遍历每个案例并将数据添加到列表中
for case in cases:
communications = get_communications(case['caseId'])
# 将当前case里面的所有案例回复整理到一个以case号命名的txt文件, 并上传到s3
replies = '\n'.join(comm['body'] for comm in communications)
s3_client.put_object(Body = replies.encode('utf-8'),
Bucket=bucket_name,
Key = date + '/repies/' + case['displayId'] + '.txt')
data.append({
'displayId': case['displayId'],
'subject': case['subject'],
'submittedBy': communications[-1]['submittedBy'],
'timeCreated': case['timeCreated'],
'severityCode': case['severityCode'],
'serviceCode': case['serviceCode'],
'categoryCode': case['categoryCode']
})
# 创建DataFrame
df = pd.DataFrame(data)
csv_bytes = df.to_csv(None).encode()
s3_client.put_object(
Bucket = bucket_name,
Key = date + '/' + date + '.csv',
Body = csv_bytes
)
2、代码运行后 S3 桶里面对应的 prefix 下面会有一个包含所有 case 元数据的 csv 文件和以 case 号命名的 txt 文件,包含所有的 case 回复信息。如下图所示:

3、收集到 Case 内容后,对于中国区的用户可以利用 SageMaker 上部署的大语言模型的能力,帮我们总结 Case 的内容,对于海外区的用户可以通过调用 Bedrock 来总结。例如 Case 里描述发生的问题,最终定位到的 Root Cause,以及对 Case 做一个分类(工程师对服务不熟悉导致的配置错误/对服务相关特性的咨询/亚马逊云科技底层故障/提限相关/服务本身限制等)。示例代码如下:
import boto3
from datetime import datetime, timedelta
import pandas as pd
from transformers import AutoTokenizer
import sagemaker
import json
import os
from sagemaker import Model, image_uris, serializers, deserializers
# 创建Sagemaker Client
sagemaker_client = boto3.client(
'sagemaker-runtime',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=aws_region
)
# 创建S3 Client
session1 = boto3.Session(
aws_access_key_id=aws_access_key_id1,
aws_secret_access_key=aws_secret_access_key1,
region_name=aws_region
)
s3 = session1.client('s3')
import os
bucket_name = 'support-case-blog'
prefix = '2024-09/'
# 创建本地目录存储下载的文件
local_dir = 'cases'
os.makedirs(local_dir, exist_ok=True)
# 列出具有指定前缀的对象
response = s3.list_objects(Bucket=bucket_name, Prefix=prefix)
# 下载所有回复到本地
for obj in response.get('Contents', []):
key = obj['Key']
if key.startswith(prefix):
local_path = os.path.join(local_dir, key[len(prefix):])
print(f'Downloading {key} to {local_path}')
try:
s3.download_file(bucket_name, key, local_path)
except Exception as e:
print(f'Error downloading {key}: {e}')
print('Download complete')
# 设置超参
parameters = {
"max_new_tokens": 8192,
"do_sample": True,
"top_p": 0.9,
"temperature": 0.1,
#"max_token": 400,
#"do_sample": True,
#"top_p": 0.7,
#"temperature": 0.7,
#"top_k": 50,
}
contentType = "application/json"
endpoint_name = "endpoint_name"
# 定义prompt
prompt_start = """
任务定义:
下面给你一些"已知信息","已知信息"是一个AWS 的support case通常会包含通常会包含"case ID:", "问题描述","问题分析","问题反馈","解决方案"等。请分析输入的case,
对case输出一个100字以内的总结, 发生了什么问题,根本原因是什么,是配置错误还是aws服务故障等
已知信息:"
"""
prompt_end = """
"
输出要求:
对case输出一个简单的总结,包括 caseID, 问题总结,根本原因,问题归类:配置错误/服务故障/咨询 三类
每个字段只用一句话表达,不可以带“,”号
请将数据以用;以CSV格式返回:
样例输出
1111111111111,用户需求误解,主备概念混淆,配置错误
2222222222222,EBS卷挂载失败,数据卷故障,服务故障
33333333333333,数据库实例升级安排与沟通,咨询
"""
#创建 invoke 函数
endpoint_name = 'endpointname'
model_snapshot_path = "model_snapshot_path"
tokenizer = AutoTokenizer.from_pretrained(model_snapshot_path, use_fast=False)
sagemaker_session = sagemaker.Session()
predictor = sagemaker.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session,
serializer=serializers.JSONSerializer(),
)
def invoke_mixtral(user_prompt):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_prompt}
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
response = predictor.predict(
{
"inputs": inputs,
"parameters": {
"max_new_tokens":8192,
"do_sample":True,
"temperature":0.01,
}
}
)
text = json.loads(str(response, 'utf-8'))
return text["generated_text"]
print(invoke_mixtral("hello"))
#调用sagemaker,获取case总结
file_path = 'cases/repies'
summary_path = 'cases/summaries'
files = []
summary = []
with os.scandir(file_path) as entries:
# 筛选出文件,按文件大小排序(从大到小)
sorted_files = sorted(
(entry for entry in entries if entry.is_file()),
key=os.path.getsize)
# 打印排序后的文件列表及其大小
for file in sorted_files:
files.append(file.name)
for file in files:
case_id = file.split(".")[0]
with open(file_path + '/' + file, 'r') as file:
content = file.read()
prompt = prompt_start + content + prompt_end
response = ""
answer = None
try:
answer = invoke_mixtra(prompt)
output = summary_path + case_id +'.txt'
with open(output, 'w', encoding='utf-8') as file1:
file1.write(answer)
print(answer)
except Exception as e:
print(response, e)
#调用Bedrock,获取case总结
# 创建 Bedrock 客户端
client = boto3.client("bedrock-runtime", region_name="us-east-1")
# 设置模型 ID
model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
for file in files:
case_id = file.split(".")[0]
with open(file_path + '/' + file, 'r') as file:
content = file.read()
prompt = f"{prompt_start}{content}\ncase ID:{case_id}{prompt_end}"
# 设置请求参数
request = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 8192,
#"top_p": 0.9,
"temperature": 0.1,
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": prompt}],
}
],
}
try:
# 调用模型并处理响应
response = client.invoke_model(modelId=model_id, body=json.dumps(request))
model_response = json.loads(response["body"].read())
response_text = model_response["content"][0]["text"]
# 格式化输出
print(f"{response_text}")
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
continue
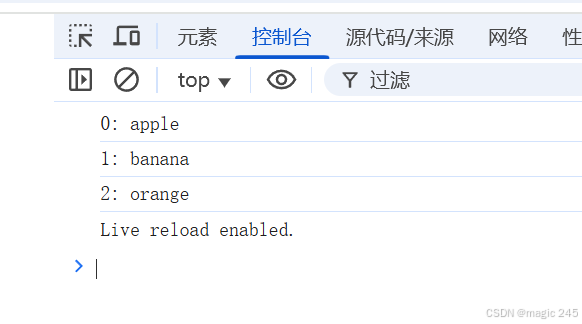
4、模型总结后的 case 如下图:

5. QuickSight 展示结果
通过上述方法,我们会得到 2 个 csv 文件,一个包含所有 Support Case 的元数据信息,一个包含所有 Support Case 的总结结果。这里,我们模拟了 200 个 case 的数据,生成了 2 个 csv。将这 2 个 csv 作为数据源导入 QuickSight 后,我们可以对这些数据进行展示和分析。
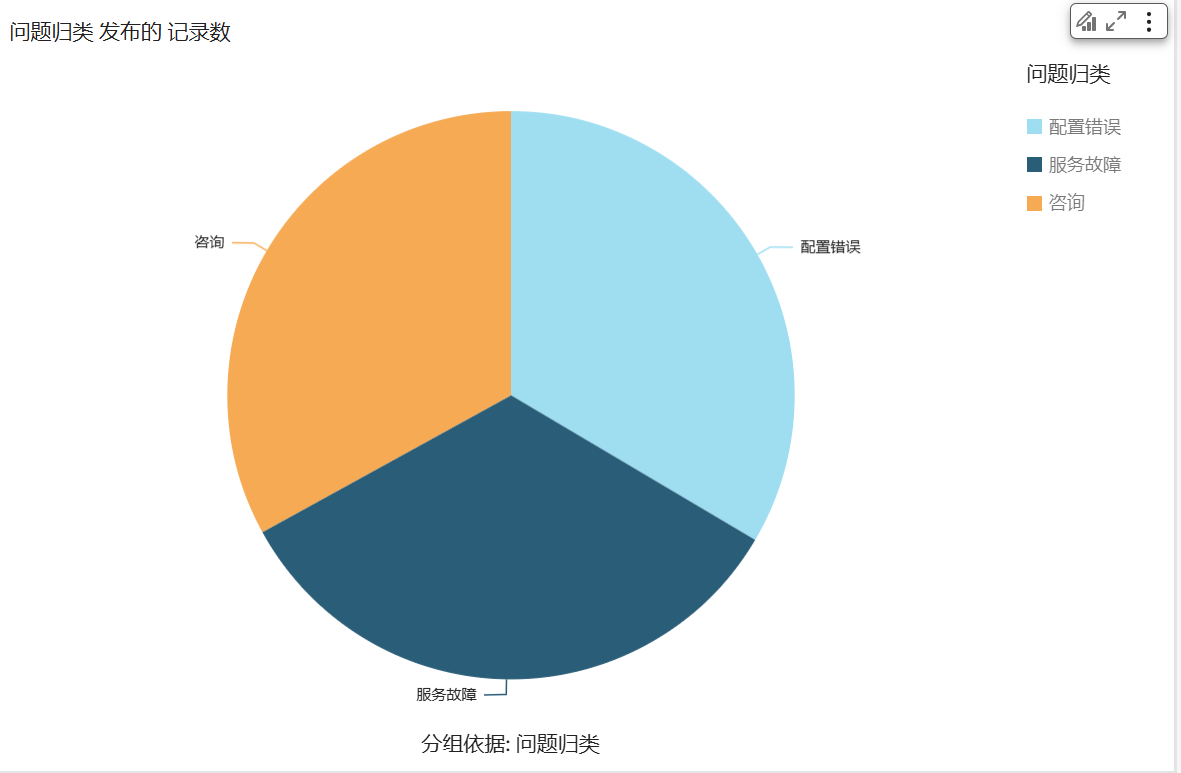
1、在 QuickSight 数据,选择刚才导入的数据集,并把问题归类作为分类字段,视觉类型选择饼图,可以对 case 按问题归类分类。例如统计数据是配置错误类 67 个,服务故障类 67 个,咨询类 66 个,可以看到如下 3 类 Case 的占比情况:
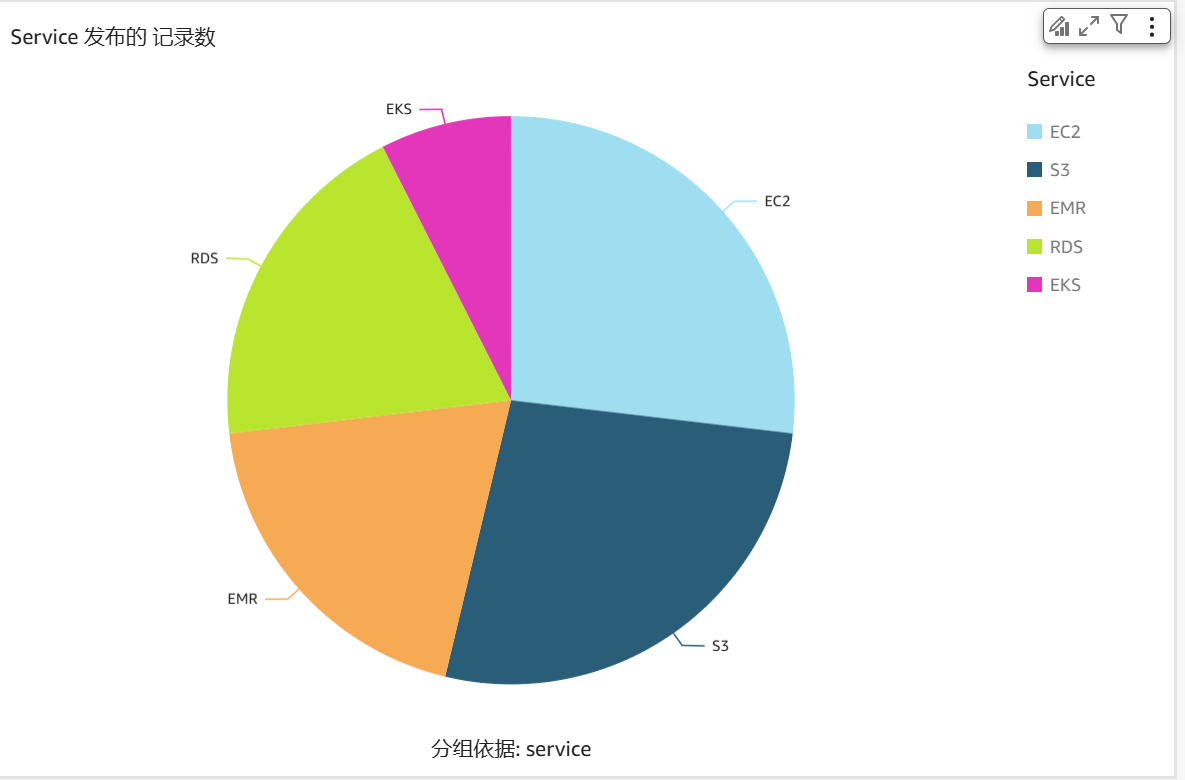
2、按 ServiceCode 进行分类,筛选中筛选出配置错误的 case 类别,可以看到工程师主要是对哪些服务不熟悉导致有配置错误。例如配置错误的 case 里面 Amazon EC2 18 个,S3 18 个,Amazon EMR 13 个,Amazon Relational Database Service(Amazon RDS) 13 个, Amazon Elastic Kubernetes Service(Amazon EKS) 5 个。可以得到下图:
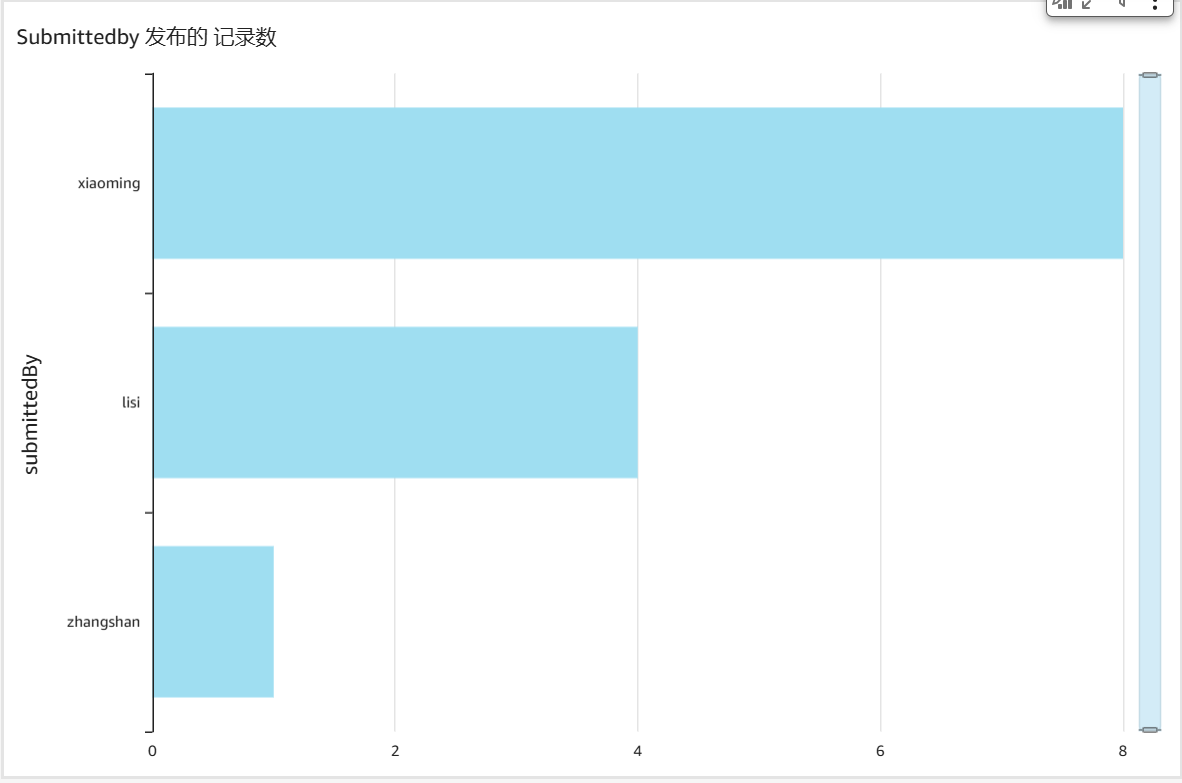
3、继续筛选出对应的服务,比如 EMR, 按照 submittedBy 字段分类,可以看到哪些部门的人对相应的服务配置错误较多,可对不同团队提供针对性的培训。例如这里筛选出对 EMR 不大熟悉的 xiaoming 和 lisi, 可以针对他们所在的部门进行 EMR 的培训。
6. 成本
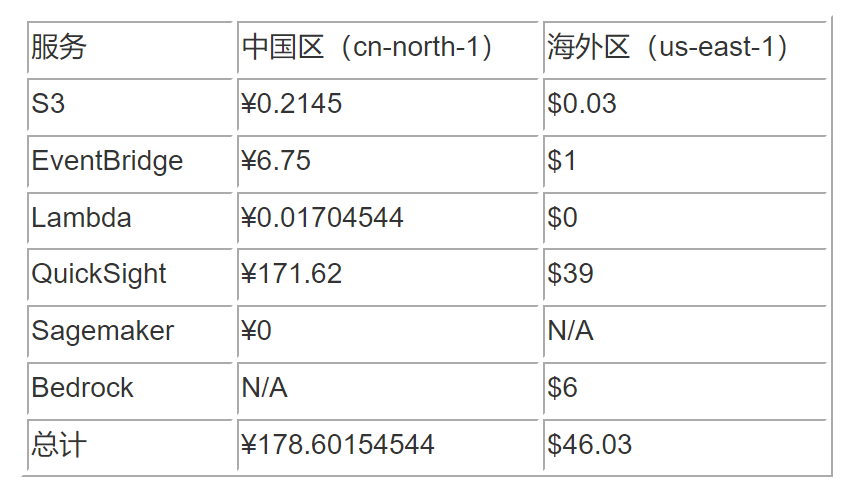
以北京区(cn-north-1)每个月分析 100 个 Case 为例:
-
S3
5MB 左右的存储空间(按 1GB S3 Standard 计算) + 100 次 PUT 请求 + 100 次 GET 请求
单价:每 GB ¥ 0.195,每 1000 个 PUT 请求 ¥ 0.0045,每 10000 个 GET 请求 ¥ 0.015
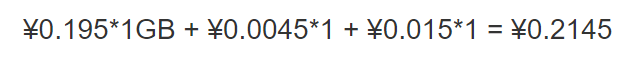
Amazon S3 价格参考
-
EventBridge
每月 1 次自定义事件
单价:每 100 万个发布的自定义事件 ¥6.75
Amazon EventBridge 价格参考
-
Lambda
每月 2 次请求 + 每次 10 分钟运行时间(X86, 128MB 内存)
单价:每个请求 ¥0.00000136,每 1 毫秒运行 ¥0.0000000142
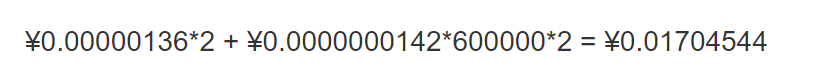
Amazon Lambda 价格参考
-
QuickSight
1 个作者 + 5 个会话
单价:作者每月 ¥161.52,读者每个会话每月 ¥2.02
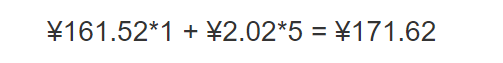
Amazon QuickSight 价格参考
-
SageMaker
建议复用现有的 Endpoint
Amazon SageMaker 价格参考
海外区同理:
-
Bedrock(us-east-1)
每月 100 万 Input Token + 20 万 Output Token
单价:Claude 3.5 Sonnet,每 1000 个 Input Token 的价格 $0.003,每 1000 个 Output Token 的价格 $0.015
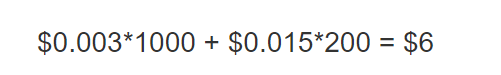
Amazon Pricing Calculator
具体费用列表如下:
7. 总结
利用大语言模型整理技术工单(Support Case)具有显著价值,可通过分析大量案例识别常见问题、建立知识库、制定培训计划、支持决策及预测需求。方案采用 EventBridge 定时触发 Lambda 函数,通过 Support API 整理工单数据,将其存储至 S3,利用 SageMaker 或 Bedrock 进行分析,分类问题类型并生成总结报告。分析结果可在 QuickSight 上展示,支持企业优化资源分配和服务策略。该解决方案架构清晰、成本低廉,为企业提供高效的技术支持工单管理与分析能力。
8. 参考链接
[1] 使用 SDK for Python (Boto3) 的 Amazon Bedrock 运行时系统示例 - AWS SDK 代码示例
[2] 如何用 API 调用 Bedrock 上的最强模型 Claude3
9. 补充信息
企业支持计划
企业支持计划可为在亚马逊云科技上运行关键业务/任务型工作负载的客户以及符合以下条件的任何客户提供资源:
-
专注于通过主动式管理提高效率和可用性;
-
按照最佳实践制定架构完善且运作良好的解决方案;
-
利用亚马逊云科技专业知识为启动和迁移提供支持。
技术客户经理(TAM)
对于企业级客户,TAM 具有亚马逊云科技全部服务的专业技术知识,并且详细了解您的使用案例和技术架构。TAM 与亚马逊云科技解决方案架构师共同协作,帮您启动新项目,并在整个实施生命周期中提供最佳实践建议。TAM 将担任您的主要联系人,满足您的持续支持需求,您可以与 TAM 直接电话联系。
本篇作者
本期最新实验为《大模型选型实战 —— 基于Amazon Bedrock测评对比和挑选最合适业务的大模型》
✨ 立即解锁当下最火爆的AI大模型,带你零基础玩转 DeepSeek、Nova 等顶尖大预言模型。
📱 即刻在云上探索实验室,开启构建开发者探索之旅吧!
⏩[点击进入实验] 构建无限, 探索启程!🚀