背景
在推荐系统与广告投放领域,长期行为序列建模旨在从用户数月甚至数年的历史行为中捕捉稳定兴趣模式,是解决冷启动、提升推荐精度的关键。随着工业界需求激增,SIM、ETA、SDIM、TWIN及TWIN-v2等模型相继诞生,推动技术不断革新。以下将按序深入解析这些模型的原理、创新及实践意义。
一、SIM:两阶段检索的奠基者
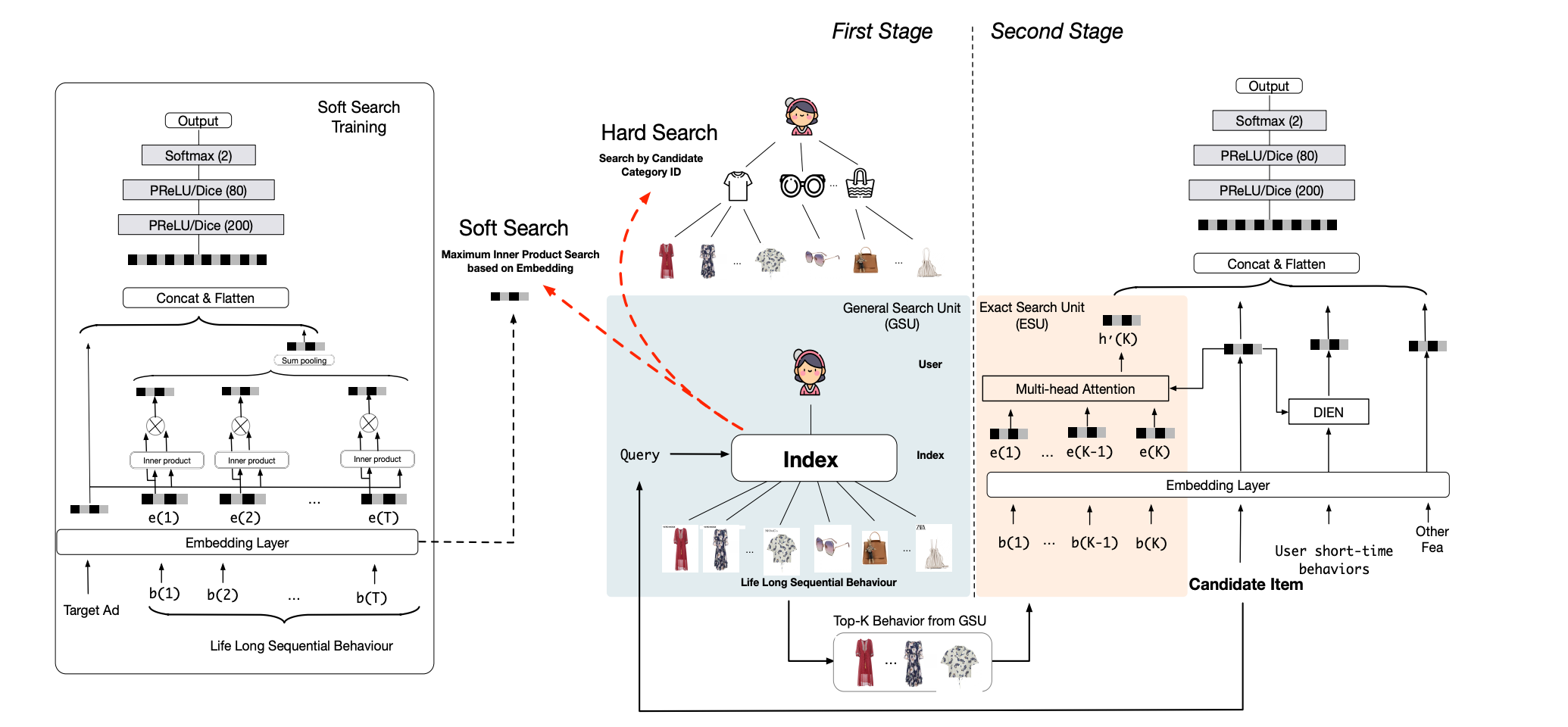
SIM 由阿里团队提出,首次将两阶段范式引入长序列建模,解决传统模型无法处理超长序列的难题,论文参考: Search-based User Interest Modeling with Lifelong Sequential
Behavior Data for Click-Through Rate Prediction
- 核心架构:
- GSU阶段(通用搜索单元):提出两种检索方案。
- Hard-Search:基于类目ID规则筛选。若目标Item类目为 C a C_a Ca,则从用户行为 B = [ b 1 , b 2 , … , b T ] B = [b_1, b_2, \dots, b_T] B=[b1,b2,…,bT] 中筛选出类目为 C a C_a Ca 的行为,相关性分数 r i = Sign ( C i = C a ) r_i = \text{Sign}(C_i = C_a) ri=Sign(Ci=Ca)( C i C_i Ci 为行为 b i b_i bi 的类目)。
- Soft-Search:通过向量内积检索。计算目标Item嵌入 e a \mathbf{e}_a ea 与行为Item嵌入 e i \mathbf{e}_i ei 的内积 r i = ( W b e i ) ⊙ ( W a e a ) T r_i = (W_b \mathbf{e}_i) \odot (W_a \mathbf{e}_a)^T ri=(Wbei)⊙(Waea)T,选取相似度高的Top-K行为( W a , W b W_a, W_b Wa,Wb 为可学习参数)。
- ESU阶段(精确搜索单元):对筛选后的短序列应用Transformer或DIEN模型。引入时间间隔分桶嵌入
e
Δ
t
=
E
⋅
one-hot
(
bin
(
Δ
t
)
)
\mathbf{e}_{\Delta t} = \mathbf{E} \cdot \text{one-hot}(\text{bin}(\Delta t))
eΔt=E⋅one-hot(bin(Δt))(
E
\mathbf{E}
E 为嵌入矩阵),计算注意力权重:
α i , j = softmax ( ( W q v q + e Δ t ) ⋅ ( W k v j ) d k ) \alpha_{i,j} = \text{softmax}\left( \frac{(\mathbf{W}_q \mathbf{v}_q + \mathbf{e}_{\Delta t}) \cdot (\mathbf{W}_k \mathbf{v}_j)}{\sqrt{d_k}} \right) αi,j=softmax(dk(Wqvq+eΔt)⋅(Wkvj))
( W q , W k \mathbf{W}_q, \mathbf{W}_k Wq,Wk 为线性变换矩阵, d k d_k dk 为Key向量维度)。
- GSU阶段(通用搜索单元):提出两种检索方案。
- 工程实践:通过两级索引存储(用户ID+类目ID),在线检索延迟控制在毫秒级。但两阶段目标不一致,可能过滤关键兴趣点。
二、ETA:LSH加速的端到端检索
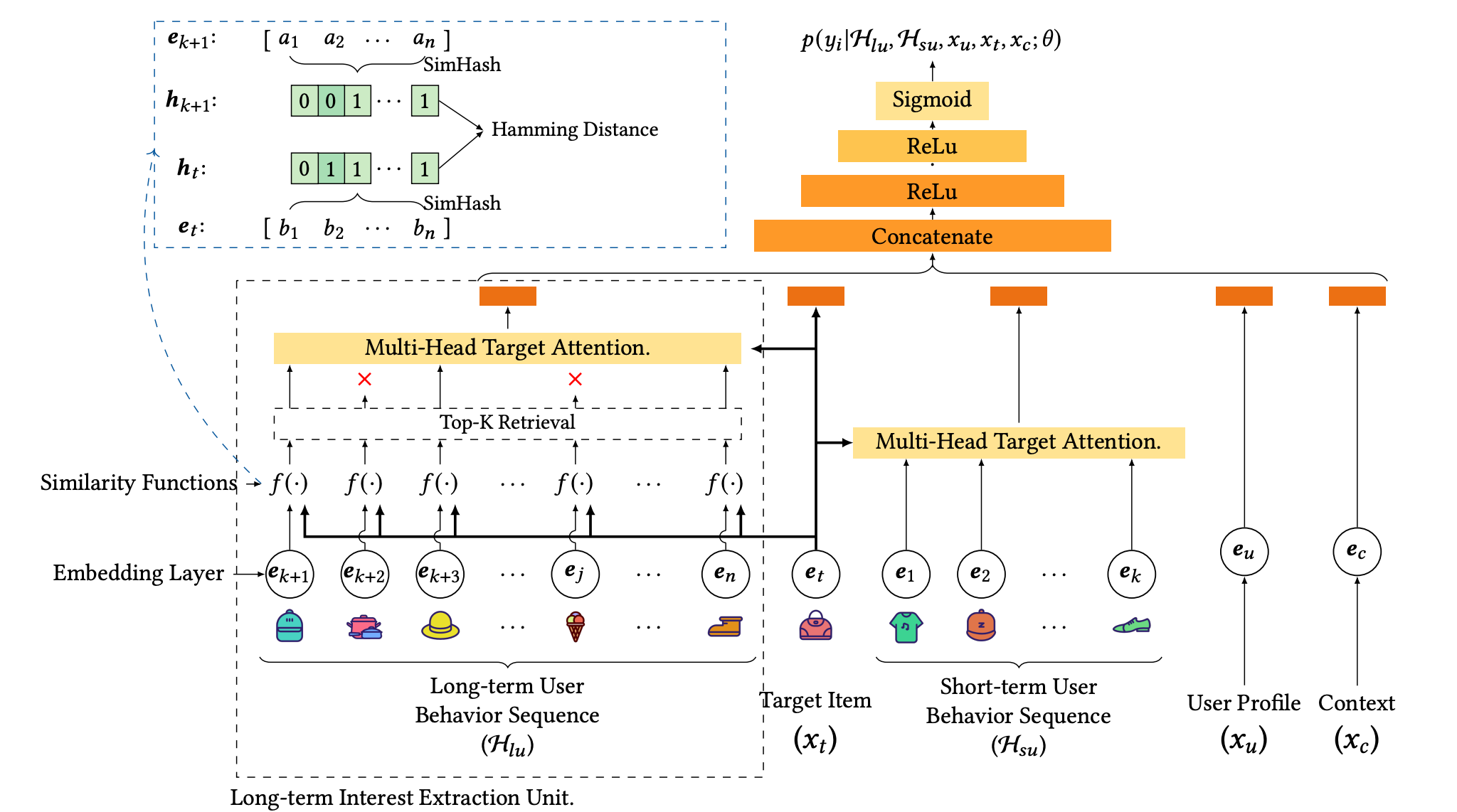
ETA由阿里提出,在减小GSU复杂度上做文章,不同的是使用SimHash来代替self-attention,论文参考: End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model
SimHash原理

SimHash是对一个embedding做hash编码的过程,假设有一个embedding
e
k
∈
R
d
e_k \in \mathbb{R}^d
ek∈Rd,给定一个随机矩阵
R
∈
R
m
×
d
R \in \mathbb{R}^{m \times d}
R∈Rm×d,矩阵
R
R
R 的每一行代表一个hash function。
SimHash
(
e
k
,
R
)
=
sign
(
e
k
⋅
R
)
\text{SimHash}(e_k, R) = \text{sign}(e_k \cdot R)
SimHash(ek,R)=sign(ek⋅R)
公式表明,将
e
k
e_k
ek 和
R
R
R 做矩阵乘法后,得到一个
m
×
1
m \times 1
m×1 的向量,对向量每个值做
sign
(
)
\text{sign}()
sign()(变量>0时取1,其他取0),将
d
d
d 维向量压缩到
m
m
m 维0/1向量。SimHash具有localty-preserving属性:向量
v
1
、
v
2
v1、v2
v1、v2 经SimHash运算后得到
s
1
、
s
2
s1、s2
s1、s2,
s
1
s1
s1 和
s
2
s2
s2 重合位数越多,
v
1
、
v
2
v1、v2
v1、v2 在向量空间越接近。
SimHash是一种局部敏感哈希算法,感兴趣的读者可以读一下笔者之前梳理的文章,进行扩展阅读 😃:)
- 向量相似搜索绕不开的局部敏感哈希
- Faiss PQ 乘积量化
- 一文读懂 Faiss 乘积量化(PQ)索引技术
- 一文读懂局部敏感哈希:原理、应用与实践
- 局部敏感哈希实践:以四维空间中随机投影法为例
- 工业级向量检索核心技术:IVF-PQ原理与全流程解析
ETA模型流程
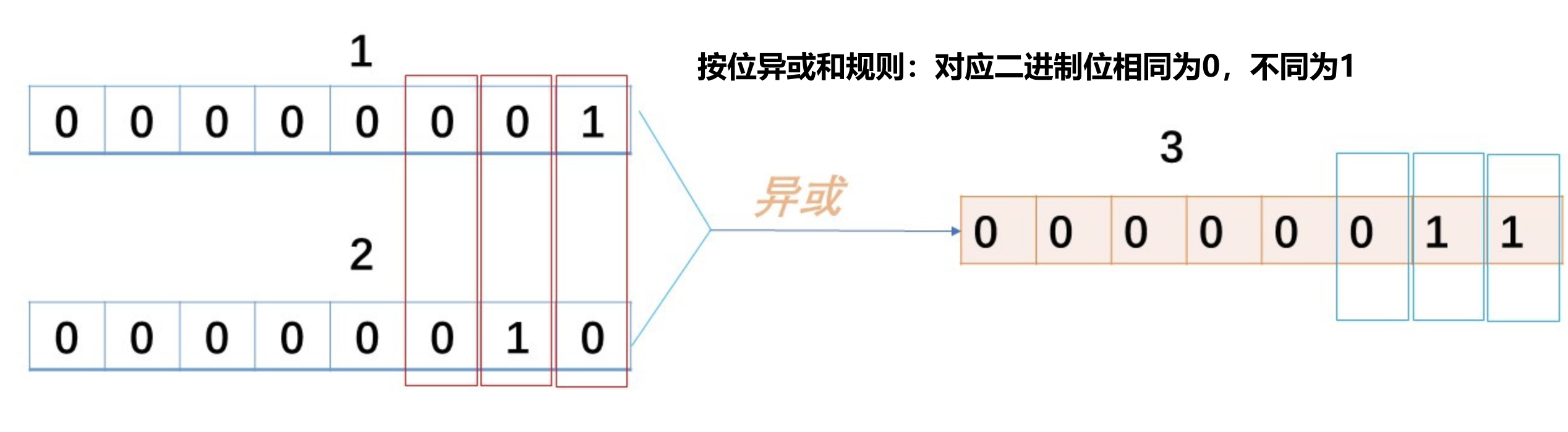
与SIM类似,区别在于对长期序列的特征提取,实现了long seq emb的端到端训练。ETA首先将target item和long seq分别经过函数 f ( ⋅ ) f(·) f(⋅) 计算相似度,先对emb进行SimHash得到二进制向量,再计算pair emb的海明距离,选topK个emb和target item做MHA,最后和其他特征concat执行ctr任务。
现有两阶段方法中,检索模型和CTR模型单独训练,信息有Gap,导致检索的TopK非CTR所需真实TopK,损害性能。而ETA-Net中ETA和BaseModel端到端训练更新,SimHash不涉及可训练参数,直接对Attention的Q和K进行Hash签名,随Attention训练更新,保障模型一致性。
预测阶段优化
预测阶段和训练阶段模型结构类似,由于SimHash函数固定,模型产出后,离线预计算Q和K的SimHash值,将HashQ和HashK的二进制向量存于embedding lookup table,预测时直接查表得item->SimHash映射,减少线上预测时间复杂度。GSU主要耗时在海明距离异或运算(时间复杂度 O ( 1 ) O(1) O(1)),GSU总时间复杂度压缩到 O ( L ) O(L) O(L)( L L L 为序列长度)。
三、SDIM:哈希采样的轻量级方案
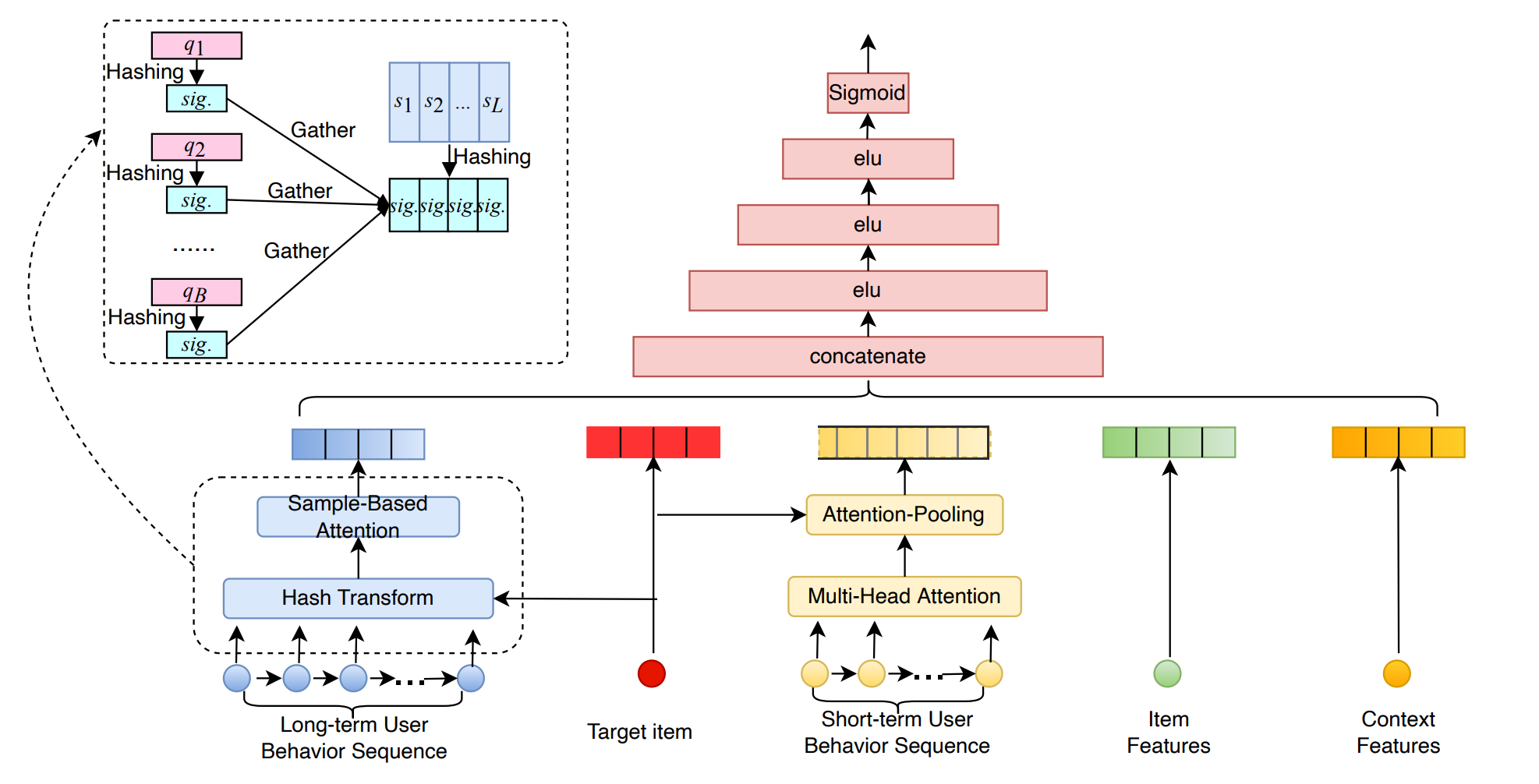
SDIM是在ETA基础上更进一步,ETA优化GSU模块,加速寻找用户长期序列中与target item相似度最高的k个item;SDIM借鉴此思想,通过计算SimHash后直接得到target item相似度最高的k个item pooling后的embedding。论文参考:Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction
模型结构
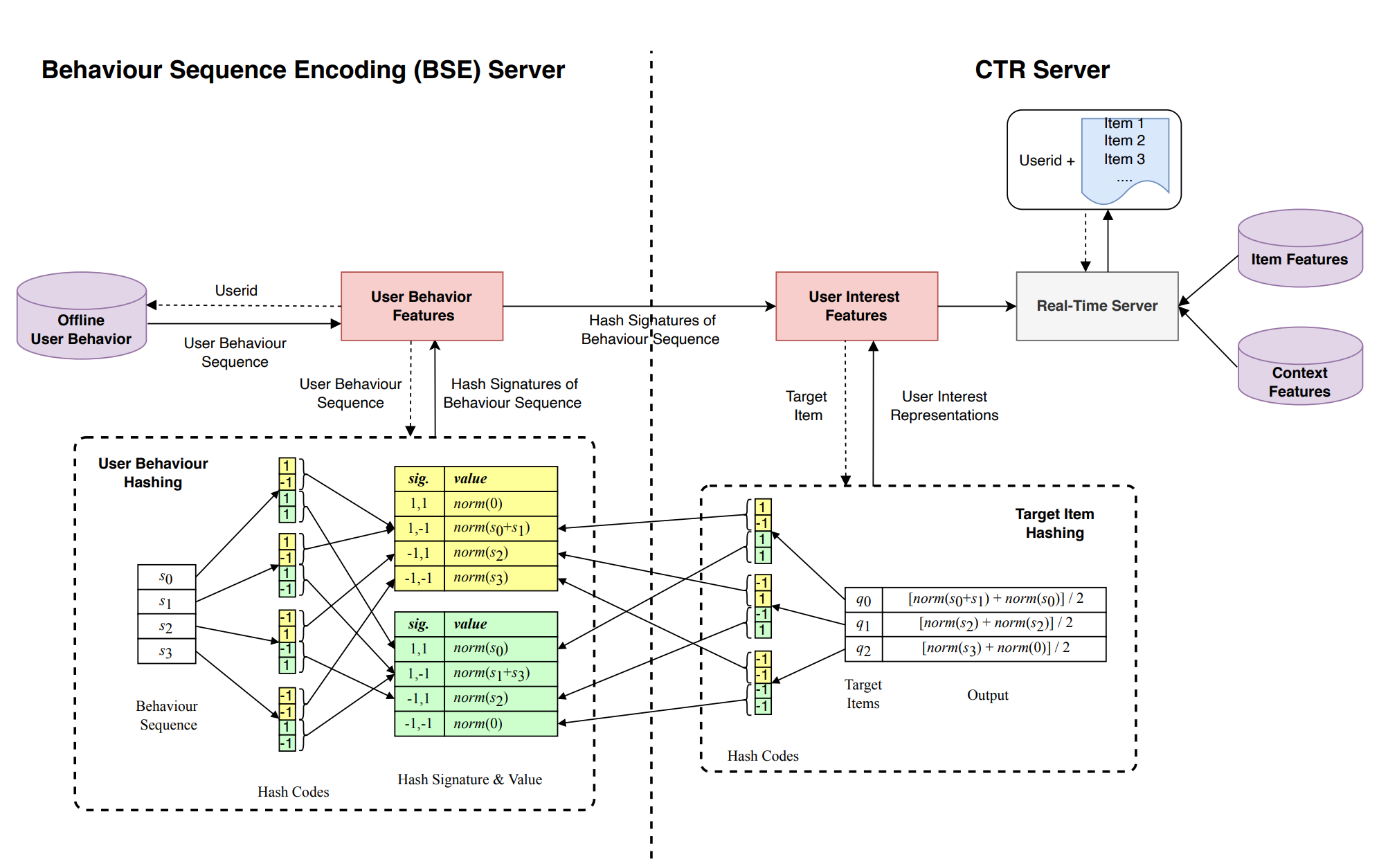
假设有 m m m 个hashcode函数(如图例中4个),为每个item计算四个hash值,每 τ \tau τ(图例中2)个hash值为一组(下图中每隔2bits组成黄色和绿色的小方块),每个item有 m / τ m/\tau m/τ(图例中2)组hash签名。
- 在user behaviour部分,以
s
1
s1
s1 为例,hash签名为
(
1
,
−
1
)
(1,-1)
(1,−1) 和
(
1
,
−
1
)
(1,-1)
(1,−1),分别映射到两个hash值域,相同hash签名聚合(如黄色值域
(
1
,
−
1
)
(1,-1)
(1,−1) 由
s
0
s0
s0 和
s
1
s1
s1 聚合,绿色值域
(
1
,
−
1
)
(1,-1)
(1,−1) 由
s
1
s1
s1 和
s
3
s3
s3 聚合)。
- 聚合方法就是先按位相加,再做L2-normalization。这样,就把user behavior sequence存储成若干buckets
- 在target item部分,将target item hash成
m
/
τ
m/\tau
m/τ 组hash签名。以
q
1
q1
q1 为例,hash签名为
(
−
1
,
1
)
(-1, 1)
(−1,1) 和
(
−
1
,
1
)
(-1, 1)
(−1,1),对应到两个hash值域分别是
norm
(
s
2
)
\text{norm}(s2)
norm(s2) 和
norm
(
s
2
)
\text{norm}(s2)
norm(s2),则
q
1
q1
q1 计算attention后的兴趣表征为
[
norm
(
s
2
)
+
norm
(
s
2
)
]
/
2
[\text{norm}(s2) + \text{norm}(s2)] / 2
[norm(s2)+norm(s2)]/2。
- 针对一个target item做target attention时,将target item也先SimHash再拆解成
个hash signature,每个hash signature去上一步得到的buckets提取聚合好的向量。把每个hash signature提取出来的向量再简单pooling一下,就得到了针对这个target item的user interest embedding
- 针对一个target item做target attention时,将target item也先SimHash再拆解成

在ETA相关处理流程中,传统方案采用的GSU先筛选出和 target-item 相似的historical items组成的Sub Behavior Sequence,后续还需将SBS传递给ESU(另一个处理单元)执行Attention机制,这一过程会额外产生
O
(
B
K
d
)
O(BKd)
O(BKd) 的时间复杂度。
与之相比,美团SDIM实现了流程的优化升级。其CTR server直接从数据存储桶(buckets)中提取的结果,近乎等同于Attention机制的最终输出,跳过了GSU筛选SBS及后续ESU处理的中间环节。这种一步到位的设计显著简化了处理流程,大幅提升了数据处理效率,有效降低了整体耗时。
SDIM的所有耗时操作可离线完成,线上只需查表+pooling,进一步降低计算复杂度。在美团数据集上AUC与Transformer相当,推理速度提升10倍,但依赖哈希函数设计。
四、TWIN:一致性两阶段框架

针对SIM的问题,快手的TWIN模型引入Consistency-Preserved GSU (CP-GSU),通过与ESU的TA相同的目标行为相关性度量,将两阶段转化为端到端训练。实际上,hard-search的召回率只有40%,CP-GSU通过计算attention寻找相似item,而非简单筛选同category item,提升召回。论文参考 TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou

Feature Split and Transform
模型将item特征分为两部分:
- item的meta Feature(固有特征),表示item的固有属性(如视频ID、作者);
- 用户与item的交互特征(如点击时间戳、播放时长),公式表示为:
K ≜ [ K h K c ] ∈ R L × ( H + C ) K \triangleq \left[ K_h \quad K_c \right] \in \mathbb{R}^{L \times (H + C)} K≜[KhKc]∈RL×(H+C)
( L L L 表示序列长度, H H H 表示固定特征个数, C C C 表示交互特征个数)。在交互特征中,将特征映射成1维:
K c W c ≜ [ K c , 1 w 1 c , … , K c , J w J c ] K_c W^c \triangleq \left[ K_{c,1} \mathbf{w}_1^c, \quad \dots \quad, K_{c,J} \mathbf{w}_J^c \right] KcWc≜[Kc,1w1c,…,Kc,JwJc]
( K c , j K_{c,j} Kc,j 表示第 j j j 个交互特征, W j c W_j^c Wjc 表示第 j j j 个交互特征的转换矩阵,转换后矩阵维度是 L × C L \times C L×C)。
原本线上attention的时间复杂度是 L ∗ ( H + C ) ∗ d L*(H+C)*d L∗(H+C)∗d,由于固定特征 H H H 与用户无关,这部分attention计算可离线提前算好存起;交互特征维度压缩到1维( d = 1 d=1 d=1),优化后时间复杂度减少到 L ∗ C L*C L∗C。
Efficient Target Attention
文章提出一种高效计算attention的方式:
α
=
(
K
h
W
h
)
(
q
⊤
W
q
)
⊤
d
k
+
(
K
c
W
c
)
β
\alpha = \frac{(K_h W^h)(\mathbf{q}^{\top} W^q)^{\top}}{\sqrt{d_k}} + (K_c W^c) \boldsymbol{\beta}
α=dk(KhWh)(q⊤Wq)⊤+(KcWc)β
这个地方个人理解,其实是一种类似 EdgeRec 中 Reliable attention 的操作,其实本质上还是如何把信息融入到 QK中,既然可以乘(类Reliable attention操作),那也可以加!!!
其中 K h W h K_h W^h KhWh 直接从离线取结果,与query计算相似度; K c W c K_c W^c KcWc 作为bias,不与query计算。结合Feature Split and Transform思想,实现attention的低复杂度计算。在CP-GSU中,取出top100的 α \alpha α 对应的item,送给ESU进行多头self-attention的计算。在ESU中,与CP-GSU计算attention的方法相同。
TWIN通过降低attention的复杂度,实现了GSU到ESU的两阶段到端到端的转换,在快手460亿规模数据集上CTR提升了4.1%,且通过优化在线基础设施,计算瓶颈降低了99.3%,但冷启动适应性差。
五、TWIN-v2:层次聚类的超长效扩展
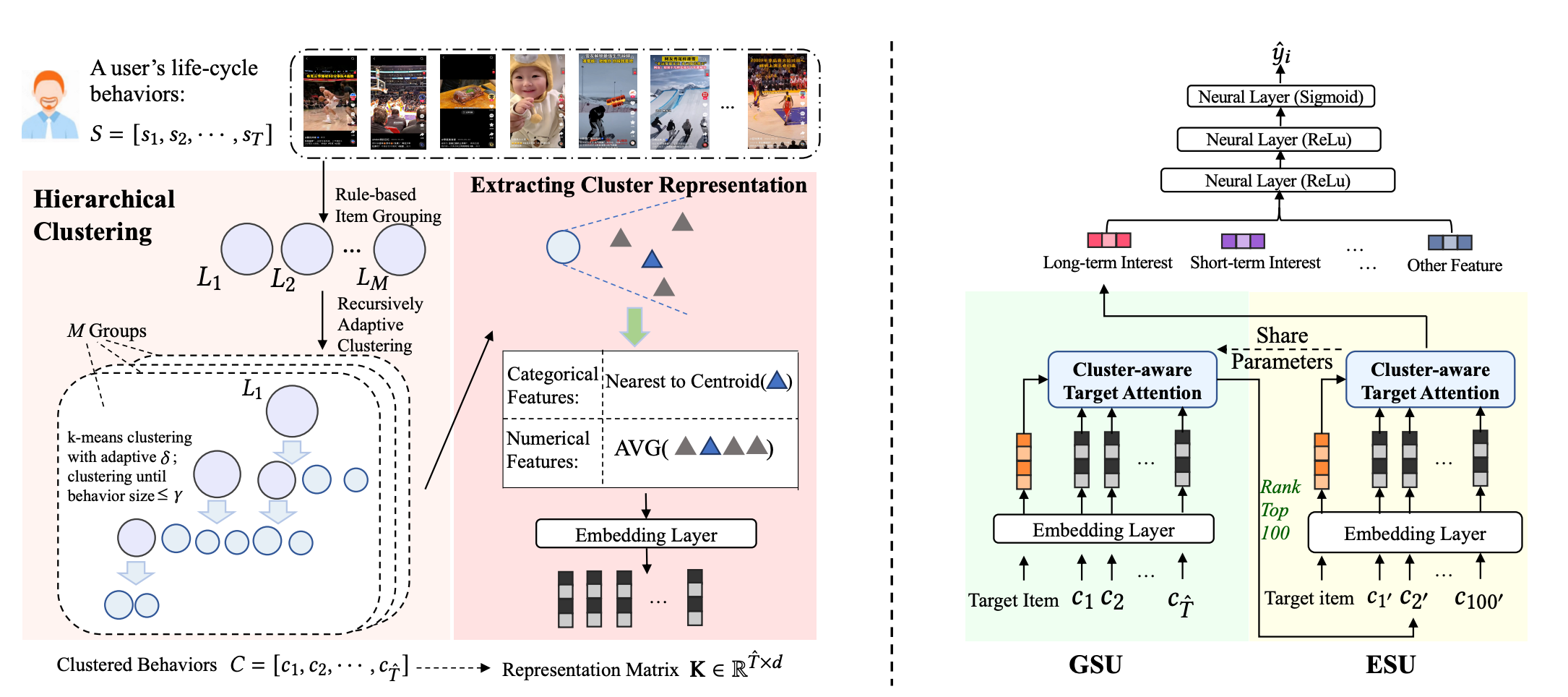
TWIN-v2针对用户终身行为序列(如 1 0 6 10^6 106 级长度)提出层次聚类压缩方案。论文参考:TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou
个人理解:非常类似于 ANN 检索中,倒排+PQ检索的办法,第一步先通过倒排缩小范围,第二步再进行 TWIN-v1 的操作,可以看看 工业级向量检索核心技术:IVF-PQ原理与全流程解析
的做法。
- 离线聚类:将用户行为按完播率分组,递归对每组进行K-means聚类,生成虚拟Item代表聚类中心。数值特征取均值 v cluster num = 1 N ∑ i = 1 N v i num \mathbf{v}_{\text{cluster}}^{\text{num}} = \frac{1}{N} \sum_{i=1}^N \mathbf{v}_i^{\text{num}} vclusternum=N1∑i=1Nvinum,类别特征取最近邻Item的特征 v cluster cat = v nearest cat \mathbf{v}_{\text{cluster}}^{\text{cat}} = \mathbf{v}_{\text{nearest}}^{\text{cat}} vclustercat=vnearestcat,大幅压缩序列长度(如 1 0 5 → 1 0 3 10^5 \to 10^3 105→103)。
- 在线检索:使用聚类中心的特征进行GSU检索,ESU阶段通过聚类感知目标注意力聚合兴趣,计算目标Item与聚类的相关性得分时考虑聚类中的行为数量
n
n
n 作为权重:
α cluster = n ⋅ cosine ( q , v cluster ) ∑ c n c ⋅ cosine ( q , v c ) \alpha_{\text{cluster}} = \frac{n \cdot \text{cosine}(\mathbf{q}, \mathbf{v}_{\text{cluster}})}{\sum_{c} n_c \cdot \text{cosine}(\mathbf{q}, \mathbf{v}_c)} αcluster=∑cnc⋅cosine(q,vc)n⋅cosine(q,vcluster)
实验表明,TWIN-v2在快手超长效序列上的CTR提升了7.6%,且通过分层聚类有效平衡了精度与效率,不过聚类参数调优较为复杂。
总结与展望
| 模型 | 核心技术 | 优势 | 局限性 |
|---|---|---|---|
| SIM | 两阶段检索(GSU+ESU) | 工程友好,低延迟 | 两阶段目标不一致 |
| ETA | SimHash+海明距离检索 | 端到端高效,适合大规模数据 | 依赖预训练Embedding质量 |
| SDIM | 哈希采样+分桶聚合 | 轻量级,线上计算极简单 | 哈希函数设计影响性能 |
| TWIN | 一致性GSU+特征解耦 | 端到端一致性,精度显著提升 | 冷启动适应性差 |
| TWIN-v2 | 层次聚类+虚拟Item | 超长效序列处理,精度效率平衡 | 聚类参数调优复杂 |
这些模型的演进展现了长序列建模从两阶段割裂到端到端统一、从高耗时到高效计算的发展路径。未来,多模态融合、动态兴趣建模、更高效的检索算法(如HNSW)及冷启动优化将是重要方向,有望进一步推动推荐系统在复杂场景下的性能突破。




![STM32单片机入门学习——第46节: [14-1] WDG看门狗](https://i-blog.csdnimg.cn/direct/26edd52d9c6d44abbed01355e6a26031.png)