系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 背景
- 系统模型
- 威胁模型
- 技术实现
- 密码学映射
- 框架
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
隐私保护联邦学习是一种分布式机器学习,多个合作者通过受保护的梯度来训练模型。为了实现对用户退出的鲁棒性,现有的实用隐私保护联邦学习方案都是基于(t,N)-门限秘密共享的。这种方案依赖于一个强假设来保证安全性:阈值t必须大于用户数的一半。这种假设是如此严格,以至于在某些情况下,这些方案可能并不合适。基于这个问题,我们首先引入了联邦学习的成员资格证明,它利用密码累加器通过累加用户ID来生成成员资格证明。这些证据在公共区块链上发布,供用户验证。结合成员资格证明,提出了一种隐私保护的联邦学习方案PFLM.PFLM在保证安全性的同时,释放了门限的假设。此外,我们设计了一种基于ElGamal加密变体的结果验证算法,用于验证云服务器聚合结果的正确性。验证算法作为一部分集成到PFLM中。在随机预言模型中的安全性分析表明,PFLM能有效地防止主动攻击者攻击隐私。实现了PFLM,实验证明了PFLM在计算和通信方面都具有很好的性能.
提示:以下是本篇文章正文内容,下面案例可供参考
背景
联邦学习作为一种分布式机器学习技术,允许多个协作者在不共享本地数据的前提下联合训练高精度模型[10,33]。其采用"中心化模型训练-去中心化数据管理"的范式,与云计算的数据管理模式高度契合[23,44]。典型部署场景中,云服务器通过聚合用户本地计算的梯度更新全局模型,用户则基于聚合结果优化本地模型[25,26]。这种云端联邦学习已成为工业界的基础架构,受到广泛关注。
然而现有方案面临严峻的隐私威胁。研究表明[27,28,31],恶意服务器可能从梯度中推断用户隐私信息——例如判断特定样本是否参与训练[28,31],极端情况下甚至能重构原始数据[27]。因此,未经保护的梯度直接传输存在重大风险[21]。
双重掩码技术[6,35]通过为每个用户配置成对掩码和自掩码,可在保护梯度隐私的同时保持模型可用性。但该方案要求用户全程在线,而实际场景中用户可能因设备限制或网络问题频繁掉线。为此,现有方案采用(t,N)阈值秘密共享[6,35]:用户将掩码生成密钥分片存储,当部分用户离线时,服务器只需联系≥t个在线用户即可恢复密钥。但这引入了新的安全隐患——若阈值t < ⌊n/2⌋-1(n为用户总数),恶意服务器可将用户划分为两个超阈值子集,通过伪造其他子集用户离线的假象,最终破解所有用户的掩码并恢复原始梯度,这种攻击称为欺骗攻击。现有方案为防御此类攻击,不得不设置t > ⌊n/2⌋+1且允许掉线用户≤⌈n/2⌉-1的严格阈值,这在用户高掉线率的现实场景中将导致聚合失败。
为解决这一矛盾,本文提出基于成员资格证明的隐私保护联邦学习方案PFLM。核心创新在于:
成员资格证明机制:采用密码学累加器[3]生成用户ID的成员证明,结合区块链[34,41]公开存储在线用户证明及数量。任何用户均可验证证明真实性,使服务器无法伪造用户在线状态。
结果验证算法:设计基于ElGamal加密变体的验证协议,用户可验证服务器返回聚合结果的正确性,避免恶意服务器返回随机结果降低计算成本。相比依赖可信执行环境(TEE)[32],本方案避免了硬件成本与性能瓶颈。
安全性分析表明,PFLM在主动敌手模型下(即使服务器与多用户合谋)仍能保护用户输入隐私。实验评估证实了方案在计算开销与通信效率方面的实用性。
全文结构:第2章综述相关工作;第3章问题建模;第4章密码学基础;第5章方案概览;第6章PFLM详细设计;第7章安全性分析;第8章性能评估;第9章总结展望。
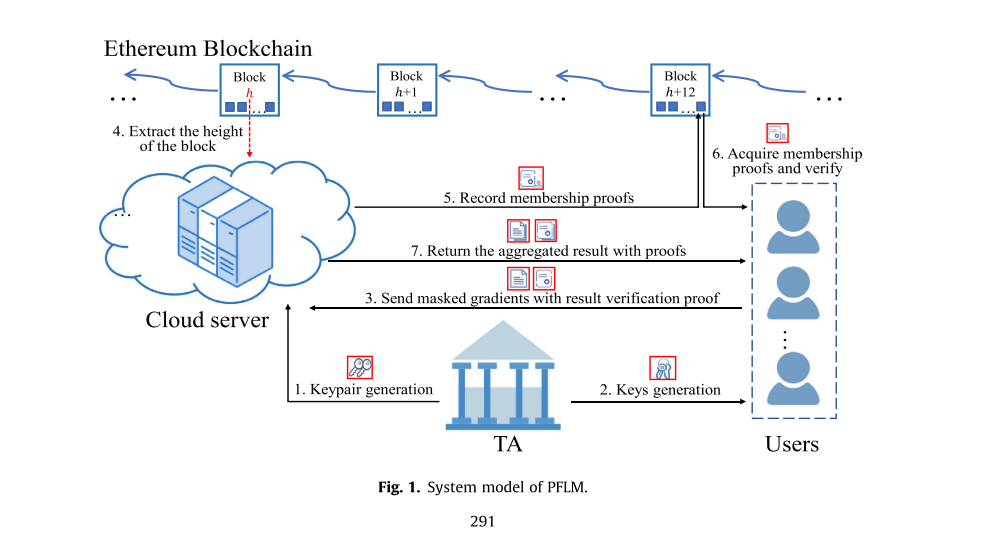
系统模型
三大核心实体:
用户节点
持有本地专属数据集
核心目标:训练高精度模型
关键操作:数据预处理→梯度生成→梯度掩码→提交验证证明
云服务平台
具备海量存储与超强算力
核心职能:
梯度聚合中枢
验证证明中继站
区块链存证管理(部署在以太坊等公链)
抗欺骗攻击防护
可信认证机构(TA)
系统初始化中枢
密钥分发中心(向用户和云服务端分发密钥)
工作流闭环
预处理阶段:
用户对本地数据加密处理,生成带掩码的梯度数据
同步生成结果验证证明(防篡改数字指纹)
安全传输阶段:
用户将加密梯度与验证证明打包上传至云端
区块链存证:
云服务生成成员资格证明,永久记录至区块链账本
聚合验证:
云端执行梯度聚合运算
同步中转验证证明至相关用户
结果核验:
用户基于接收信息校验聚合结果真实性
威胁模型
- 诚实但好奇模型(Honest-but-Curious)
参与方行为:严格遵循协议流程
攻击方式:
云服务器与用户可能私下合谋
通过合法数据推导隐私信息
类似"遵守规则但偷看账本"的会计师
2. 主动攻击者模型(Active Adversary)
增强攻击能力:
协议偏离(发送错误/随机数据)
选择性终止通信
数据投毒攻击
类似"既偷看又篡改账本"的恶意会计
模型关系:满足主动攻击安全 → 自动覆盖诚实模型安全
PFLM方案威胁设定
攻击者能力:
全员恶意假设:
云服务器和用户均可主动作恶
支持服务器伪造聚合结果
超强攻击场景:
服务器与用户合谋
秘密共享阈值突破(|U|/2)
欺骗攻击原理:
用户集分割:
将用户群U拆分为U1和U2两个子集
每个子集用户数超过秘密共享阈值
信息欺骗:
对U1谎称U2离线
对U2谎称U1已退出
隐私破解:
分别重建两组用户的掩码密钥
解密所有梯度数据
技术实现




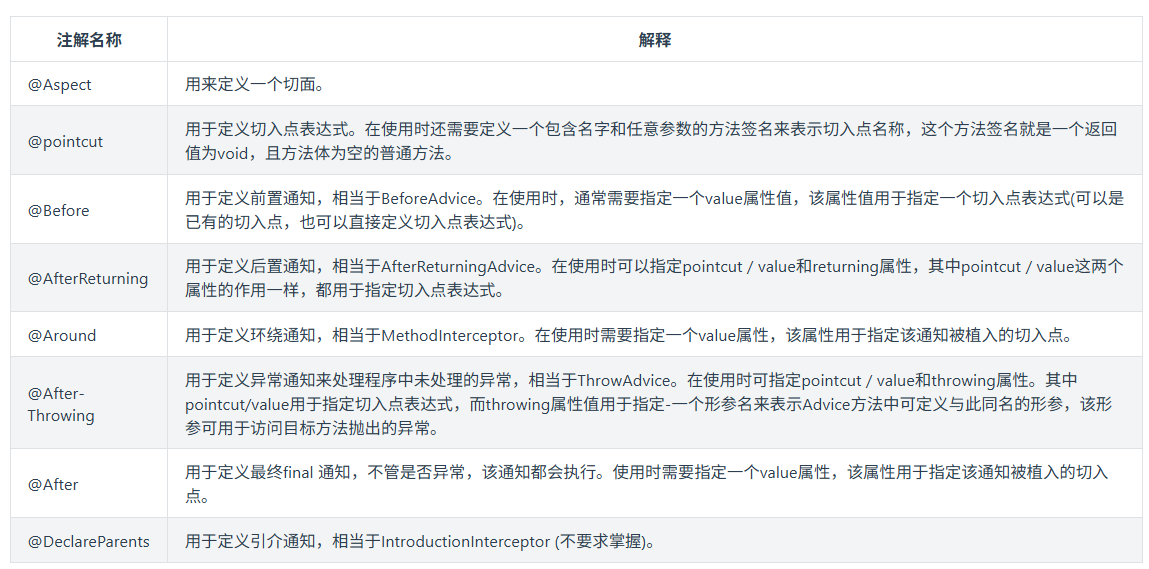
密码学映射


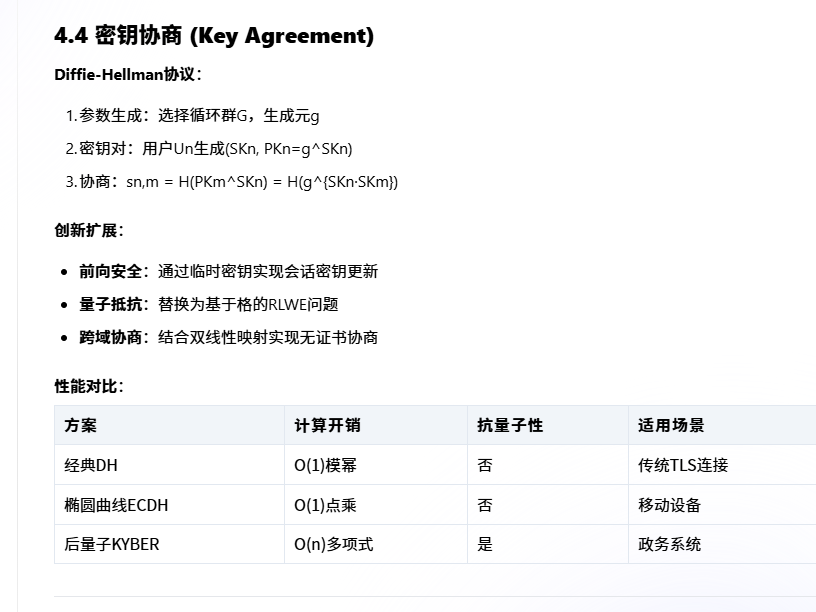

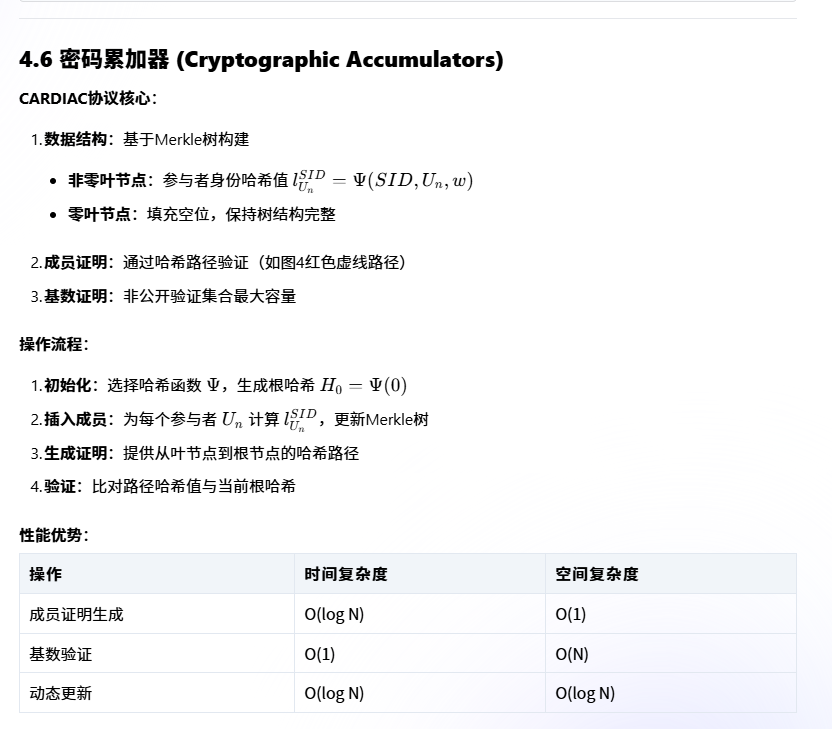
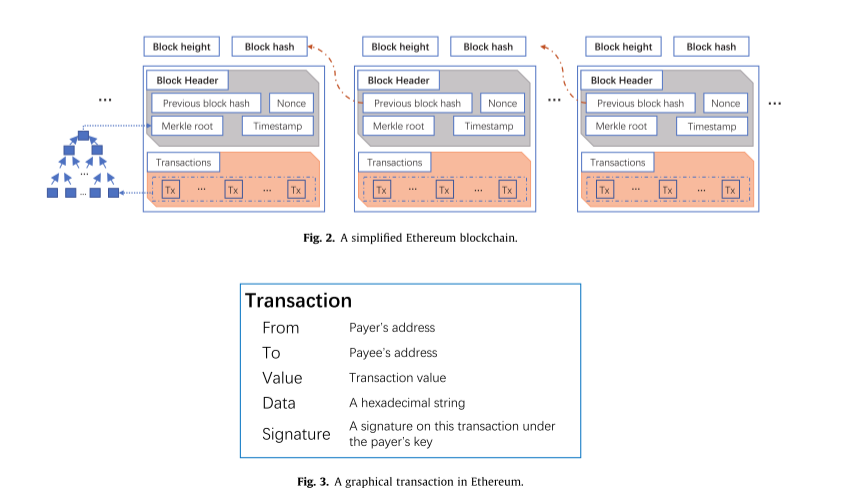
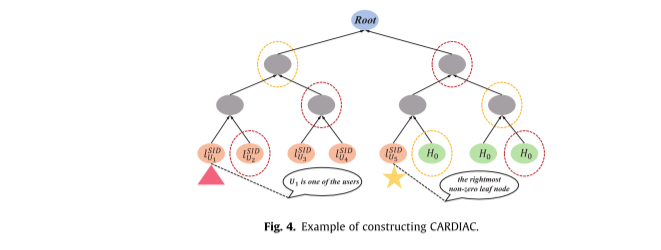
框架

想象有 10个研究员 各自掌握一部分秘密数据(比如不同地区的医疗记录),他们想合作训练一个AI模型,但必须遵守规则:
绝不泄露自己的数据;
只汇总结果,不暴露谁贡献了什么;
防止有人作弊或冒充。
于是他们设计了一套复杂的合作流程,像“特工行动”一样分步骤执行:
阶段一:成立秘密小组(Setup)
管理员(TA) 给每个研究员发了一套工具包:
加密信封(公钥):用来加密自己的数据,只有管理员能拆开。
解码手册(私钥):用来验证最终结果的真实性。
密码本(随机种子):用来生成临时密码,每次任务不同。
云服务器 像“任务中转站”,负责收集和传递信息,但自己看不到明文数据。
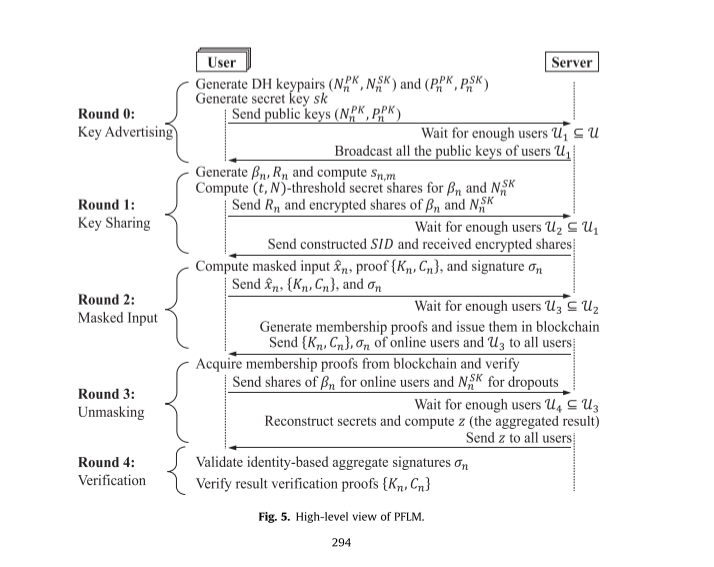
阶段二:任务启动(Round 0 - Key Advertising)
管理员说:“开始新任务!这次的任务代号是 2023-10-01(会话ID)。每个人用新信封加密数据,云服务器会把大家的信封互相传阅。”
研究员A 拿到其他人的加密信封,但不知道里面具体内容,只能用来打包自己的数据。
阶段三:分发密码碎片(Round 1 - Key Sharing)
为了防止有人偷看,研究员们互相分发了 密码碎片:
研究员A 把密码本撕成10份,把其中9份发给其他研究员(类似藏宝图碎片)。
只有凑齐至少6份碎片(假设阈值是6),才能拼出完整的密码。
云服务器 根据所有人提交的随机数,生成本次任务的唯一代号(如“2023-10-01”),确保每次任务独立。
阶段四:提交加密数据(Round 2 - Masked Input)
研究员A 要提交数据了,他做了三件事:
加密数据:用“加密信封”把数据包起来,还额外加了一层 随机包装纸(掩码值)。
例如:真实数据是数字5,包装纸是3 → 提交的是8(5+3)。
写保证书:生成一个 数学证明(比如密码学签名),证明“我提交的是合法数据,没作弊”。
打卡签到:云服务器把所有人的“保证书”记录到 公共公告板(区块链),谁参与了这次任务全网可见,不可抵赖。
阶段五:汇总数据(Round 3 - Unmasking)
云服务器 的工作:
检查公告板上的签到记录,确认哪些研究员真的参与了。
收集所有人的“加密数据包”(比如8、7、9等)。
请求密码碎片:向参与的研究员索要之前分发的密码碎片。
拆包装纸:用凑齐的密码碎片还原出总包装纸(比如总包装纸是3+2+4=9),从加密数据包中减去这个数,得到真实数据总和(比如8+7+9 -9 =15)。
阶段六:验证结果(Round 4 - Verification)
研究员A 拿到汇总结果15后,怀疑:
有人作弊吗?
云服务器造假了吗?
于是做两件事:
检查保证书:核对公告板上所有人的数学证明,确认他们都是合法参与者。
重新计算:用自己的数据(5)加上其他人的公开信息(比如人数),估算结果是否合理(比如平均3人×5=15,符合结果)。
如果没问题,进入下一轮任务;如果发现异常,启动“警报”排查内鬼。




总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。




graph TB
A[Setup: TA初始化系统] --> B[Key Advertising: 分发密钥]
B --> C[Key Sharing: 分片密钥并生成会话ID]
C --> D[Masked Input: 加密梯度并上链]
D --> E[Unmasking: 验证身份并聚合]
E --> F[Verification: 结果验证与争议处理]
F -->|通过| G[新一轮迭代]
F -->|失败| H[区块链仲裁]
隐私保护:梯度加密、秘密共享和零知识证明三重防护,确保数据不泄露。
完整性验证:区块链存证 + IBAS聚合签名,防止篡改和伪造结果。
动态扩展:CARDIAC累加器支持动态增减参与者,适应大规模联邦学习场景。
合规审计:所有操作链上可查,满足GDPR、HIPAA等数据监管要求。
该框架为医疗、金融等敏感领域的多方协作学习提供了标准化解决方案,平衡了隐私、安全与效率的需求。