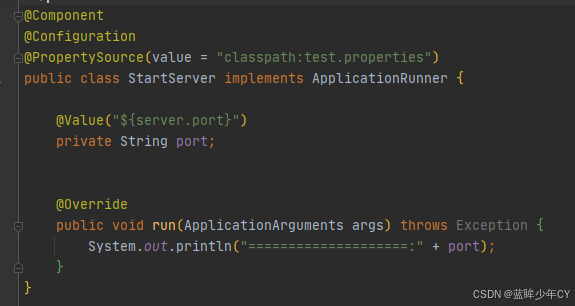
1.1 什么是网络爬虫?
1.1.1 定义与分类

网络爬虫:互联网世界的“信息捕手”
网络爬虫(Web Crawler),又称网络蜘蛛或网络机器人,是一种通过预设规则自动访问网页、提取数据的程序系统。从技术视角看,其核心任务是通过模拟浏览器行为向目标服务器发起请求,解析网页内容并存储结构化数据,最终服务于信息检索与分析。根据目标范围差异,爬虫可分为三类:通用型爬虫(如搜索引擎的全网抓取机器人)、聚焦型爬虫(针对电商、新闻等垂直领域定向采集)和增量式爬虫(仅抓取网页更新内容)。
通俗而言,网络爬虫如同一位不知疲倦的“数字图书管理员”。它按照人类设定的指令,以每秒数千次的速度穿梭于互联网,将散落在数十亿网页中的文字、图片、价格、评论等信息分门别类地“装订成册”,供后续分析与使用。例如,当你在电商平台搜索商品时,背后可能有爬虫在实时监控全网价格波动;当你阅读新闻时,可能是爬虫从数百家媒体中筛选出热点事件。
参考百度百科定义:
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫:互联网信息采集的核心技术
网络爬虫(Web Crawler),亦称网络蜘蛛或网络机器人,是一类通过预设规则自动化采集、解析互联网信息的程序系统。其技术形态主要分为三类:通用型爬虫(全网覆盖)、聚焦型爬虫(垂直领域定向抓取)以及增量式爬虫(动态更新数据)。
-
基本定义:网络爬虫(Web Crawler)是一种自动化程序,通过模拟人类浏览网页的行为,从互联网上批量抓取、解析和存储数据。
-
爬虫的核心功能:
- 遍历网页链接(如搜索引擎爬虫)。
- 提取目标数据(如价格、文本、图片等)。
-
爬虫的分类:
- 通用爬虫:覆盖全网,服务于搜索引擎(如Google Bot)。
- 聚焦爬虫:针对特定领域或网站(如电商价格监控)。
- 增量式爬虫:仅抓取更新内容(如新闻网站)。
1.1.2 典型应用场景
爬虫的现实应用场景已渗透各行各业:
-
商业决策:企业通过爬虫采集竞品价格、用户评价,优化定价策略(如亚马逊价格监控系统);
-
学术研究:抓取社交媒体数据,分析公众舆论趋势(如新冠疫情中的情绪传播研究);
-
公共服务:政府机构利用爬虫聚合多平台信息,实现灾害预警或舆情监测(如地震信息实时同步系统)。
还有一些应用场景如:
- 搜索引擎:索引全网内容(如百度、Google)。
- 数据分析:抓取公开数据用于市场趋势分析(如房价、股票)。
- 竞品监控:实时追踪电商平台价格变动(如亚马逊、京东)。
- 舆情分析:采集社交媒体数据(如微博、Twitter)进行情感分析。
- 学术研究:批量下载论文、专利或公开数据集。
作为数字时代的“数据引擎”,网络爬虫不仅是搜索引擎的基石(如Google的PageRank依赖全网爬虫),更是人工智能训练的“数据粮仓”——从ChatGPT的语言模型训练到自动驾驶的图像识别,均需爬虫提供海量原始数据。然而,其应用也需遵循法律与伦理边界,如遵守网站Robots协议、避免隐私侵犯等。
1.1.3 爬虫的工作流程——从种子到数据:一场精密的信息狩猎
- 种子URL: