数据集:世界幸福指数数据集中的变量有幸福指数排名、国家/地区、幸福指数得分、人均国内生产总值、健康预期寿命、自由权、社会支持、慷慨程度、清廉指数。我们选择GDP per Capita和Freedom,来预测幸福指数得分。
文件一:linear,在上一篇博客里。
文件二:multivariate_linear_regression.py
import numpy as np
"""用于科学计算的一个库,提供了多维数组对象以及操作函数"""
import pandas as pd
"""一个用于数据导入、导出、清洗和分析的库,本文中导入csv格式数据等等"""
import matplotlib.pyplot as plt
"""pyplot提供了绘图接口"""
import matplotlib
"""一个强大的绘图库"""
import plotly
"""网页交互数据可视化工具,可以直接从https://plotly.com/python/官网copy代码进行修改"""
import plotly.graph_objs as go
plotly.offline.init_notebook_mode()
# 设置matplotlib正常显示中文和负号
matplotlib.rcParams['font.family'] = 'SimHei' # 指定默认字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号
from prepare_for_training import LinearRegression
data = pd.read_csv("D:/machine_learning/archive/2017.csv")
train_data = data.sample(frac = 0.8)
"""从数据集中随机抽取80%的数据进行训练"""
test_data = data.drop(train_data.index)
"""从数据集中移除训练集得到测试机"""
input_param_name_1 = 'Economy..GDP.per.Capita.'
input_param_name_2 = 'Freedom'
output_param_name = 'Happiness.Score'
x_train = train_data[[input_param_name_1,input_param_name_2]].values
y_train = train_data[[output_param_name]].values
x_test = test_data[[input_param_name_1,input_param_name_2]].values
y_test = test_data[[output_param_name]].values
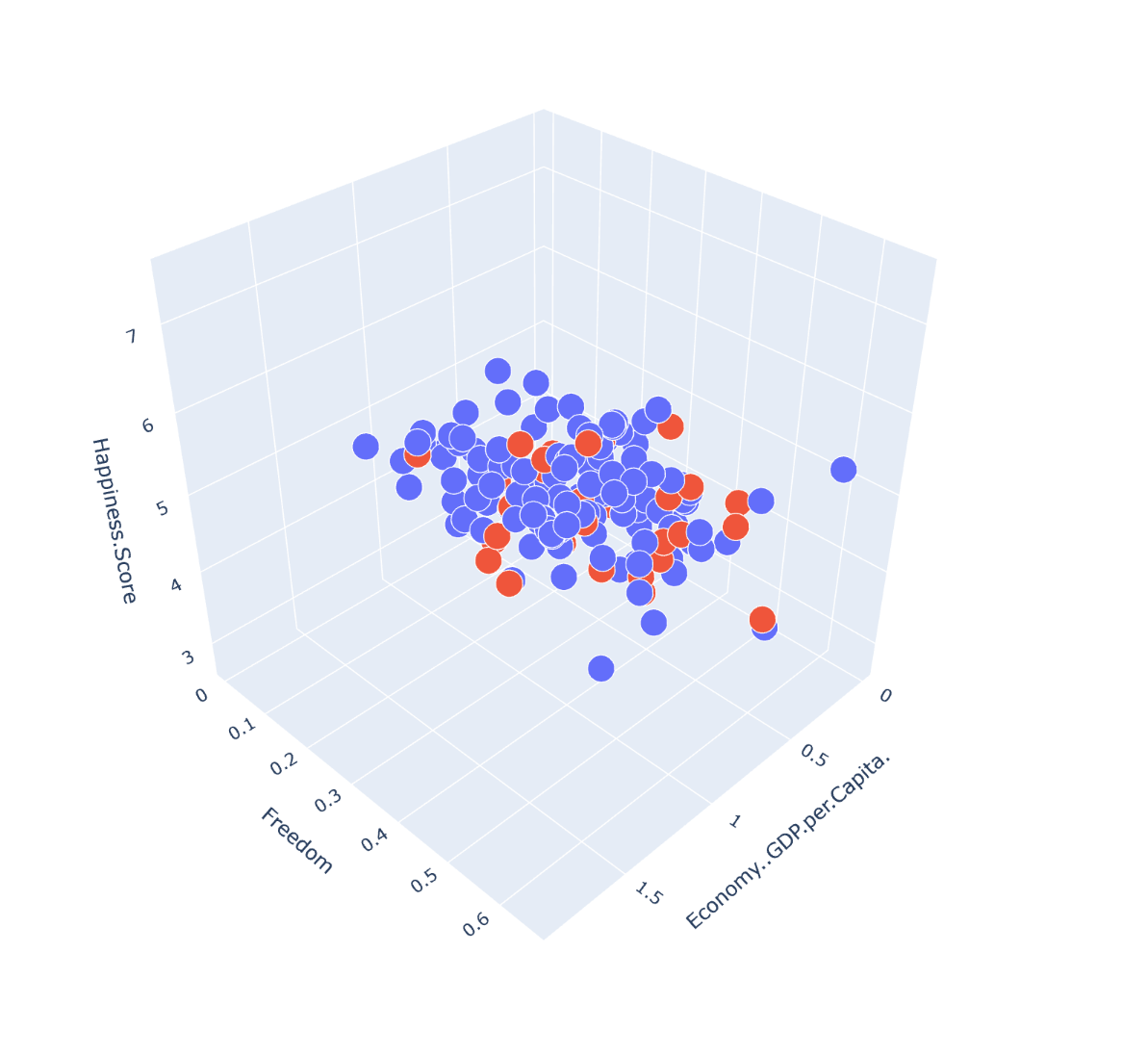
plot_training_trace = go.Scatter3d(
x = x_train[:,0].flatten(),
y = x_train[:,1].flatten(),
z = y_train.flatten(),
name = 'Training Set',
mode = 'markers',
marker = {
'size':10,
'opacity':1,
'line':{
'color':'rgb(255,255,255)',
'width':1
},
}
)
plot_test_trace = go.Scatter3d(
x = x_test[:,0].flatten(),
y = x_test[:,1].flatten(),
z = y_test.flatten(),
name = 'Test Set',
mode = 'markers',
marker = {
'size':10,
'opacity':1,
'line':{
'color':'rgb(255,255,255)',
'width':1
},
}
)
plot_layout = go.Layout(
title = 'Data Sets',
scene = {
'xaxis':{'title':input_param_name_1},
'yaxis':{'title':input_param_name_2},
'zaxis':{'title':output_param_name}
},
margin = {'l':0,'r':0,'b':0,'t':0}
)
plot_data = [plot_training_trace,plot_test_trace]
plot_figure = go.Figure(data = plot_data,layout=plot_layout)
plotly.offline.plot(plot_figure)
"""plt.scatter(x_train,y_train,label ='Train data')
plt.scatter(x_test,y_test,label ='Test data')
plt.xlabel(input_param_name_1)
plt.ylabel(output_param_name)
plt.title('Happy')
plt.legend()
plt.show()"""
"""训练次数,学习率"""
num_iterations = 500
learning_rate = 0.01
polynomial_degree = 0
sinusoid_degree = 0
linear_regression = LinearRegression(x_train,y_train,polynomial_degree,sinusoid_degree)
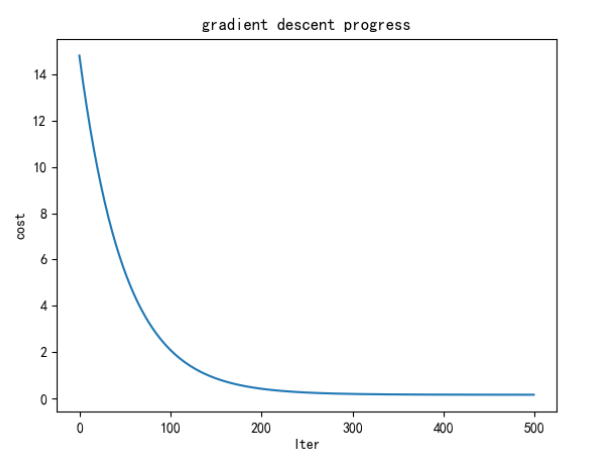
(theta,cost_history) = linear_regression.train(learning_rate,num_iterations)
print('开始时的损失',cost_history[0])
print('训练后的损失',cost_history[-1])
plt.plot(range(num_iterations),cost_history)
plt.xlabel('Iter')
plt.ylabel('cost')
plt.title('gradient descent progress')
plt.show()
predictions_num = 10
x_min = x_train[:,0].min()
x_max = x_train[:,0].max()
y_min = x_train[:,1].min()
y_max = x_train[:,1].max()
x_axis = np.linspace(x_min,x_max,predictions_num)
y_axis = np.linspace(y_min,y_max,predictions_num)
x_predictions = np.zeros((predictions_num * predictions_num,1))
y_predictions = np.zeros((predictions_num * predictions_num,1))
x_y_index = 0
for x_index,x_value in enumerate(x_axis):
for y_index,y_value in enumerate(y_axis):
x_predictions[x_y_index] = x_value
y_predictions[x_y_index] = y_value
x_y_index += 1
z_predictions = linear_regression.predict(np.hstack((x_predictions,y_predictions)))
plot_predictions_trace = go.Scatter3d(
x = x_predictions.flatten(),
y = y_predictions.flatten(),
z = z_predictions.flatten(),
name = 'Prediction Plane',
mode = 'markers',
marker = {
'size':1,
},
opacity=0.8,
surfaceaxis=2,
)
plot_data = [plot_training_trace,plot_test_trace,plot_predictions_trace]
plot_figure = go.Figure(data = plot_data,layout=plot_layout)
plotly.offline.plot(plot_figure)
效果:
损失值较单变量而言,由降低约0.1.