本文根据 数据结构和算法入门 视频记录
文章目录
- 1. 排序算法
- 2. 插入排序 Insertion Sort
- 2.1 概念
- 2.2 具体步骤
- 2.3 Java 实现
- 2.4 复杂度分析
- 3. 快排 QuickSort
- 3.1 概念
- 3.2 具体步骤
- 3.3 Java实现
- 3.4 复杂度分析
- 4. 归并排序 MergeSort
- 4.1 概念
- 4.2 递归具体步骤
- 4.3 Java实现
- 4.4 复杂度分析
1. 排序算法
搜索是计算机中非常重要的步骤,但是从无序的数据中寻找特定的数字往往很难,我们之前提到的二分查找只能运用在排好序的数组中。所以排序算法是一个很重要的工作,如果我们能够将数值排好序,那么当我们寻找特定数值的时候,能省下不少功夫。
排序算法有很多,每种排序算法各有优缺点:
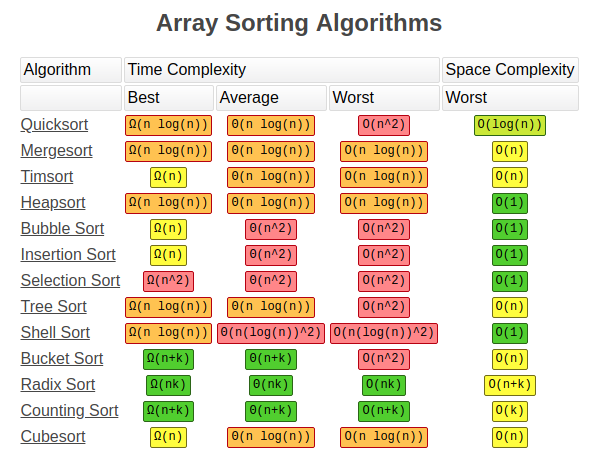
在这章节中,我们就来学习其中最经典的三种排序方法:插入排序Insertion Sort,快排Quick Sort,归并排序Merge Sort。
2. 插入排序 Insertion Sort
2.1 概念
插入排序是一种简单直观的排序算法。在插入排序中,我们从前到后依次处理未排好序的元素,对于每个元素,我们将它与之前排好序的元素进行比较,找到对应的位置后并插入。本质上,对于每一个要被处理的元素,我们只关心它与之前元素的关系,当前元素之后的元素我们下一轮才去处理。

在实现上,每个元素和之前元素比较的过程,是一个从后到前扫描的过程。在扫描时,我们将已排好序的元素先后挪位,为新的元素提供插入位置。这也叫做 in-place 排序,这样我们就不需要额外的内存空间了。
2.2 具体步骤
- 从第二个元素(第一个要被排序的新元素)开始,从后向前扫描之前的元素序列
- 如果当前扫描的元素大于新元素,将扫描元素移动到下一位
- 重复步骤2,直到找到一个小于或者等于新元素的位置
- 将新元素插入到该位置
- 对于之后的元素重复步骤1~4
伪代码 pseudo code
function insertion_sort(array[]):
for (i = 1; i < array.length; i++):
cur = array[i]
j = i - 1
while (j >= 0 && array[j] > cur):
array[j + 1] = array[j]
j--
array[j + 1] = cur
2.3 Java 实现
public void insertionSort(int[] array) {
for(int i = 1; i < array.length; i++) {
int cur = array[i];
int insertionIndex = i - 1;
while(insertionIndex >= 0 && array[insertionIndex] > cur) {
array[insertionIndex + 1] = array[insertionIndex];
insertionIndex--;
}
array[insertionIndex + 1] = cur;
}
}
2.4 复杂度分析
时间复杂度:O(n²)
空间复杂度:O(1)
「时间复杂度」在此算法中就是计算比较的次数,第一个元素我们需要比较1次,第二个元素2次,对于第n个元素,我们需要和之前的元素比较n次,比较总数量也就是 1 + 2 + … + n = n(n + 1) / 2
≈ n^2。因为我们调换位置时采用「原地操作」(in place),所以不需要额外空间,既空间复杂度为O(1)。
3. 快排 QuickSort
3.1 概念
快排是一种分治(Divide and Conquer)算法,在这种算法中,我们把大问题变成小问题,然后将小问题逐个解决,当小问题解决完时,大问题也迎刃而解。
快排的基本概念就是选取一个目标元素,然后将目标元素放到数组中正确的位置。然后根据排好序后的元素,将数组切分为两个子数组,用相同的方法,在没有排好序的范围使用相同的操作。
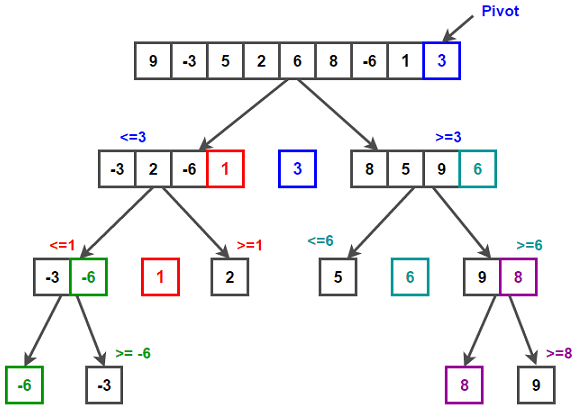
3.2 具体步骤
- 对于当前的数组,取最后一个元素当做基准数(pivot)
- 将所有比基准数小的元素排到基准数之前,比基准数大的排在基准数之后
- 当基准数被放到准确的位置之后,根据基数数的位置将元素切分为前后两个子数组
- 对子数组采用步骤1~4的递归操作,直到子数组的长度小于等于1为止
伪代码(Pseudo code)
function quickSort(array[], left, right):
partitionIndex = partition(array, left, right)
quickSort(array, left, partitionIndex - 1)
quickSort(array, partitionIndex + 1, right)
function partition(array[], left, right):
pivot = array[right]
smallerElementIndex = left
biggerElementIndex = right - 1
while(true):
while(smallerElementIndex < right && array[smallerElementIndex] <= pivot):
smallerElementIndex++
while(biggerElementIndex >= left && array[biggerElementIndex] > pivot):
rightIndex--
if(smallerElementIndex > biggerElementIndex) break
swap(array, smallerElementIndex, biggerElementIndex)
# Now array[smallerElementIndex] is the first element bigger than pivot
swap(array, smallerElementIndex, right)
return smallerElementIndex
3.3 Java实现
public void quickSort(int[] array, int left, int right) {
if(left >= right) return;
int partitionIndex = partition(array, left, right);
quickSort(array, left, partitionIndex - 1);
quickSort(array, partitionIndex + 1, right);
}
public int partition(int[] array, int left, int right) {
int pivot = array[right];
int leftIndex = left;
int rightIndex = right - 1;
while(true) {
while(leftIndex < right & array[leftIndex] <= pivot) {
leftIndex++;
}
while(rightIndex >= left && array[rightIndex] > pivot) {
rightIndex--;
}
if (leftIndex > rightIndex) break;
swap(array, leftIndex, rightIndex);
}
swap(array, leftIndex, right); // swap pivot to the right position
return leftIndex;
}
public void swap(int[] array, int left, int right) {
int temp = array[left];
array[left] = array[right];
array[right] = temp;
}
3.4 复杂度分析
时间复杂度:O(n^2),平均时间复杂度:O(nlogN)
空间复杂度:O(n),平均空间复杂度:O(logN)
在最坏的情况下,如果元素一开始就是从大到小倒序排列的,那么我们每个元素都需要调换,时间复杂度就是O(n^2)。当正常情况下,我们不会总碰到这样的情况,假设我们每次都找到一个中间的基准数,那么我们需要切分logN次,每层的划分(Partition)是O(N),平均时间复杂度就是O(nlogN)。空间的复杂度取决于递归的层数,最糟糕的情况我们需要O(N)层,一般情况下,我们认为平均时间复杂度是O(logN)。
4. 归并排序 MergeSort
4.1 概念
归并排序也是一种基于归并操作的有效排序算法。在此算法中,我们将一个数组分为两个子数组,通过递归重复将数组切分到只剩下一个元素为止。然后将每个子数组中的元素排序后合并,通过不断合并子数组,最后就会拿到一个排好序的大数组。
归并排序和快排一样,也是一种分而治之算法,简单理解就是将大问题变为小问题,然后把所有小问题都解决掉,大问题就迎刃而解了。其中主要包括两个步骤:
- 切分步骤:将大问题变为小问题,通过递归解决更小的子问题。
- 解决步骤:将小问题的结果合并,以此找到大问题的答案。
以数组 [38, 27, 43, 3, 9, 82, 10] 为例,我们通过递归分组,之后原数组被分成长度小于等于2的子数组:
[38, 27], [43, 3], [9, 82], [10]
并将子数组中的元素排序好:
[27, 28], [3, 43], [9, 82], [10]
然后两两合并,归并成排好序的子数组:
[3, 27, 38, 43], [9, 10, 82]
最后将子数组合并为一个排好序的大数组:
[3, 9, 10, 27, 38, 43, 82]
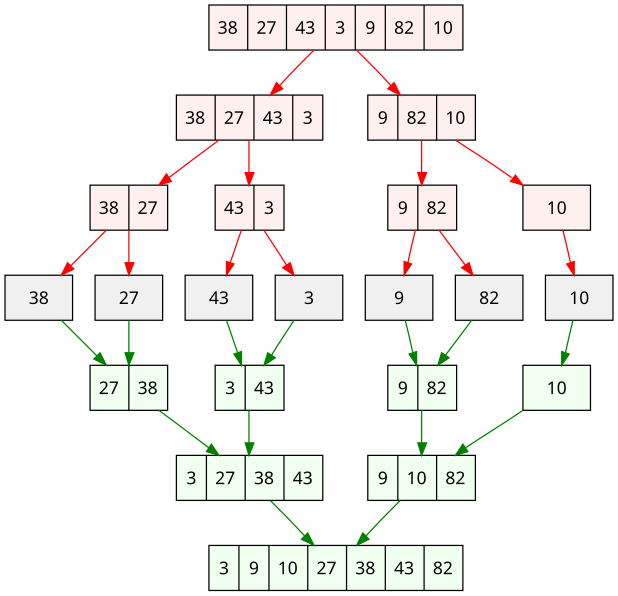
4.2 递归具体步骤
- 递归切分当前数组
- 如果当前数组数量小于等于1,无需排序,直接返回结果
- 否则将当前数组分为两个子数组,递归排序这两个子数组
- 在子数组排序结束后,将子数组的结果归并成排好序的数组
伪代码 Pseudocode
function mergeSort(array[], start, end):
if (end - start < 1) return
mid = (start + end) / 2
mergeSort(array, start, mid)
mergeSort(array, mid + 1, end);
merge(array, start, mid, end)
function merge(array[], start, mid, end):
helper[] = array.copy()
leftStart = start, rightStart = mid + 1
while(leftStart <= mid || rightStart <= end):
if(helper[leftStart] <= helper[rightStart]):
array[start++] = helper[leftStart++]
else:
array[start++] = helper[rightStart++]
if(leftStart <= mid):
while(leftStart <= mid):
array[start++] = helper[leftStart++]
else:
while(rightStart <= end):
array[start++] = helper[rightStart++]
4.3 Java实现
public void mergeSort(int[] array) {
int[] helper = copy(array);
mergeSort(array, helper, 0, array.length - 1);
return array;
}
public void mergeSort(int[] array, int[] helper, int left, int right) {
if(right - left < 1) return;
int mid = left + (right - left) / 2;
mergeSort(array, helper, left, mid);
mergeSort(array, helper, mid + 1, right);
merge(array, helper, left, mid, right);
}
public void merge(int[] array, int[] helper, int left, int mid, int right) {
for(int i = left; i <= right; i++) {
helper[i] = array[i];
}
int leftStart = left;
int rightStart = mid + 1;
for (int i = left; i <= right; i++) {
if (leftStart > mid) {
array[i] = helper[rightStart++];
} else if (rightStart > right) {
array[i] = helper[leftStart++];
} else if (helper[leftStart] < helper[rightStart]) {
array[i] = helper[leftStart++];
} else {
array[i] = helper[rightStart++];
}
}
}
public int[] copy(int[] array) {
int[] newArray = new int[array.length];
for(int i = 0; i < array.length; i++) {
newArray[i] = array[i];
}
return newArray;
}
4.4 复杂度分析
时间:O(nlogN)
空间:O(N)
在将大问题切分为小问题的过程中,我们每次都将数组切一半,所以需要logN次才能将数组切到一个元素,所以递归的层级就是logN。在每一层中,我们要对子数组进行归并,我们要扫描所有的元素,所以每一层需要N次扫描。那么,时间复杂度就是层级乘以每层的操作 = logN * N = O(NLogN)。在每一层中,我们需要一个临时的数组来存放原先的数据,然后在这个数组中扫描子数组的元素,并将其排好序放回原来的数组,所以空间复杂度就是O(N)。



![[架构之美]一键服务管理大师:Ubuntu智能服务停止与清理脚本深度解析](https://i-blog.csdnimg.cn/direct/4245e1ad9bd34684b1f3cc68e180c0e3.png#pic_center)