文章目录
- 前言
- 3 继续巴拉结构
- 3.1 encode 和 embedding
- 3.2 全局layernorm
- 3.3 lm_head(language modeling) 和 softmax
- 3.4 softmax 和 linear 之间的 temperature和topk
- 3.5 weight tying
前言
在 基础学习:(6)中, 在运行和训练代码基础上,向代码结构进行了挖掘.并且按照训练和运行过程, 扣了一些细节.但是和周围朋友(感谢 suntianlong)讨论中发现还有不会的地方.因此打算进一步深挖. 接上一个链接:https://blog.csdn.net/mikhailbran/article/details/147217336?spm=1001.2014.3001.5501

3 继续巴拉结构
为了能彻底理解nanogpt,这里继续对结构进行挖掘,尽量消除理解偏差.
3.1 encode 和 embedding
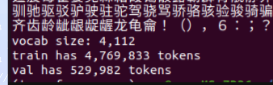
(1) encode
在我们输入提示词(prompt)后 inference 过程首先经过了编码, 由于我们已经有了 一个 meta.pkl, 所以代码走截图箭头过程.
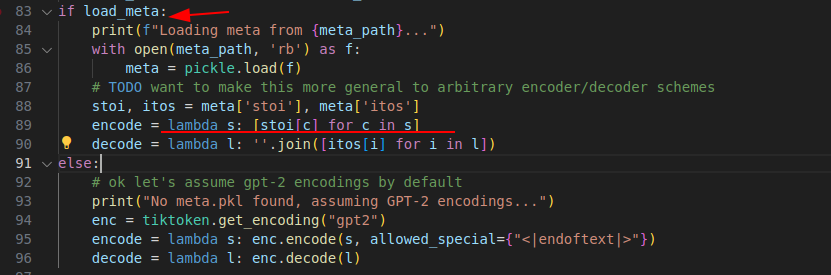
新的提示词可以进行encode, 其实encode的方法非常多,不必拘泥.
# encode the beginning of the prompt
if start.startswith('FILE:'):
with open(start[5:], 'r', encoding='utf-8') as f:
start = f.read()
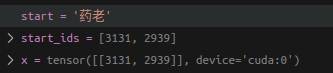
start_ids = encode(start)
x = (torch.tensor(start_ids, dtype=torch.long, device=device)[None, ...])
下图就是encode 之后的结果
(2) embedding
我们在论文里能看到embedding, 和常见的NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维, nanogpt 中用"n_embd"进行了约束,也就是768,也就是隐藏层的宽度 在BERT、T5 中,这通常叫 hidden_size.
所以我们能看到这行代码:
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
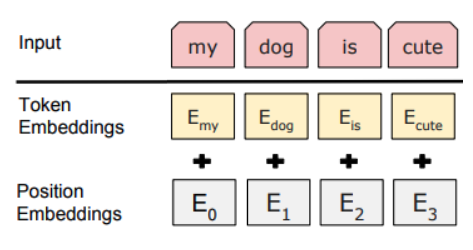
但是光有词语本身的信息是不够的, 比如语句一般是连续的,主语 谓语 宾语 都是有顺序关系,甚至 如果一个词和另外一个词距离较远,大概率就没有实际关系. 所以nanogpt 这里(其实transformer 也是这么干的) 又计算了词的位置关系
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (t, n_embd)
因此有了大家常看的一张图
这里列举一些 常见的n_embd 大小:
| 模型 | n_embd |
|---|---|
| GPT-2 small | 768 |
| GPT-2 medium | 1024 |
| GPT-2 large | 1280 |
| GPT-2 XL | 1600 |
| GPT-3 (175B) | 12288 |
注意我们这里进行prompt比较简单, 就是 “药老”

所以我们此时b = 1(batch size) t=2(token size)
也因此,形成的 x 就是 1, 2 , 768的shape

至于embedding 如何实现, 有很多,比如用sin cos ,这样可以完美的实现线性组合和加减.不赘述.
(3) dropout
此处还有个细节,dropout.在的到 x 前会过一个dropout.老生常谈了,随机丢数据,提高模型行泛化程度避免过拟合.
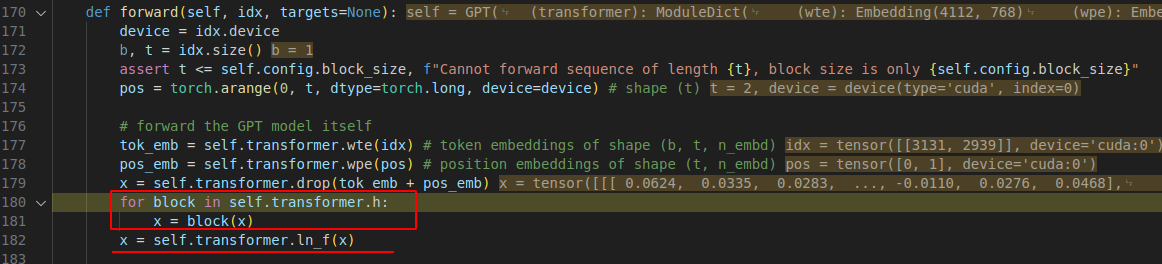
3.2 全局layernorm
这里又有个细节, 明明12个block 都计算完了,每层block 都有自己的 layernorm 最后在 182 行代码处又加了一个layernorm
我查了下GPT-2、GPT-3、GPT-4 都保留了这层 ln_f. 以及BERT:encoder 输出后也接 LayerNorm 都是为了稳定输出分布、提高泛化.
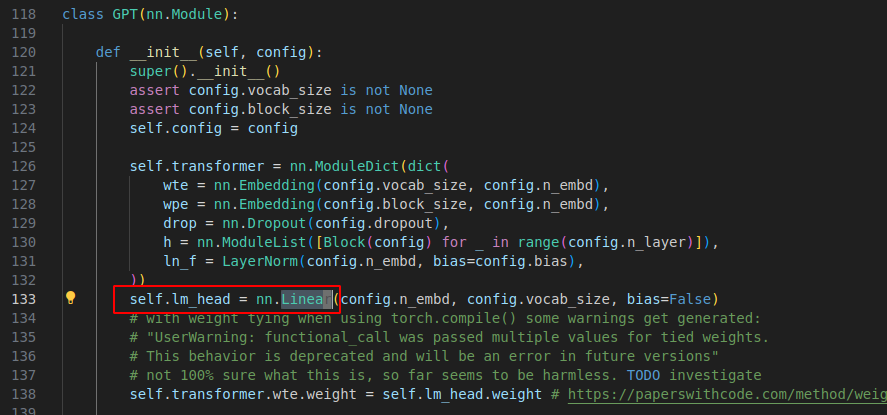
3.3 lm_head(language modeling) 和 softmax
transformer论文中有一个 linear 和 softmax
在模型init 时候以及就那个定义好

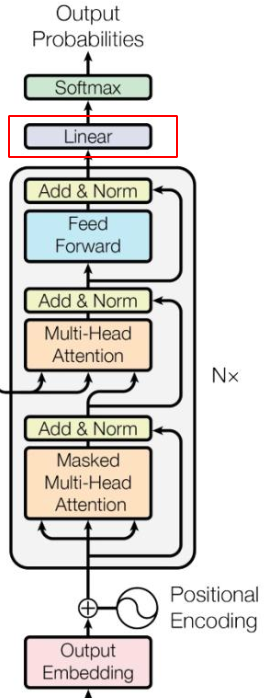
注意在经过linear之前,我们的x都是 [1,2,768] 的shape,什么意思,就是我们的 x 都是通过768个channel 来进行描述.不是我们人类认识的token.好比将蛋白质分解为了氨基酸. 所以linear 就是要根据字典
将 x 映射为 字典中的哪个字段,当程序运行到这里可以清晰看到logits 已经由用768个维度表示的向量转化为了vacab 字典中的每个 token 的原始得分或者置信度.
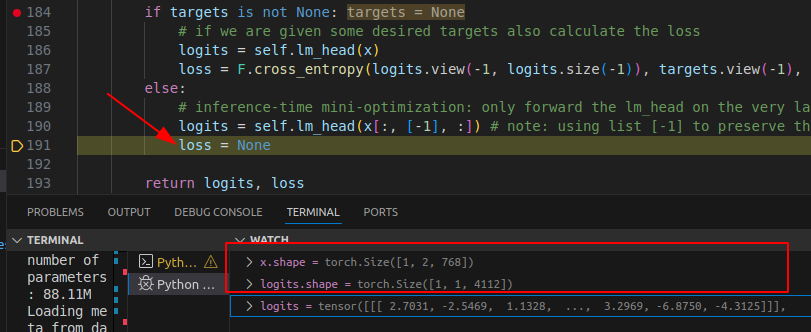
但是这个置信度不是概率,因此最后经过softmax 就是概率分布
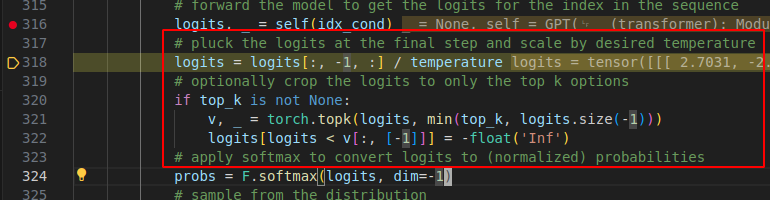
3.4 softmax 和 linear 之间的 temperature和topk
如果你仔细看代码你就会发现,还有一点tricky的内容就是 红框中的内容,先处以了temperature 再用了 top_k. top_k好理解,就是选出k个最大概率的结果.但是这个 temperature 有讲究.
这是softmax 公式
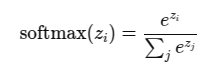
如果处以温度,就是
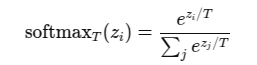
实际上其的作用就是调整形状
假设我们有logits = [5.0, 1.0, -1.0]
那么不同温度有:
| 温度 | softmax(logits / T) ≈ |
|---|---|
| 0.5 | [0.99, 0.009, 0.001] |
| 1.0 | [0.88, 0.12, 0.01] |
| 2.0 | [0.60, 0.30, 0.10] |
看图就能知道
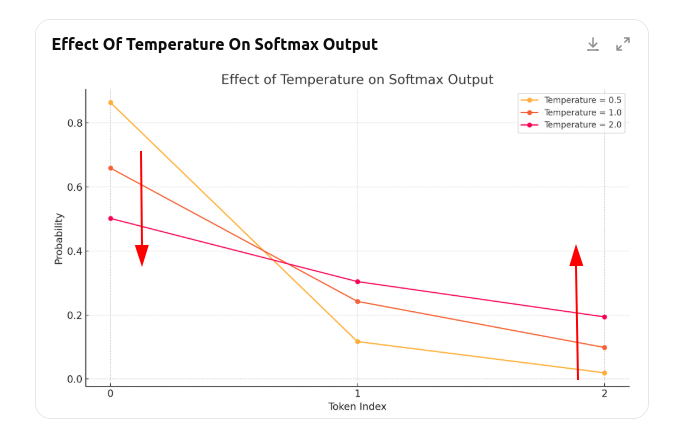
当 T < 1:大的 logit 被“放大”,小的被“压缩”,分布变陡,更倾向高置信 token , 先的预测更保守, 因为置信度高的更高,置信度度低的更低.
当 T > 1:所有 logit 被“压缩”,差距变小,softmax 更平滑,因为置信度高的压低了,置信度度低的被太高了.因此容易采样到原本低概率的 token(因为) ,因此预测结果更发散,更有创造性
3.5 weight tying
权重共享,这里是指 wte 和 m_head 权重是相同的

这里有个17年的论文: https://arxiv.org/pdf/1608.05859v3
根据这个论文的思路:
1 linear 和 m_head 两者的维度是一样的,所以从尺寸上一样
Embedding: [vocab_size , n_embd]
Output head: [n_embd , vocab_size]
2 embedding 和 output head 虽然过程不一样,但是数学过程上是可逆.
3 论文用了很多 模型尝试,发现都没有退化,且部分效果还挺好.
最后该论文证明这个效果确实可以,所以大家都这么用了