一、核心模式与配置要点
1. 内嵌Hive
无需额外配置,直接使用,但生产环境中几乎不使用。
2. 外部Hive(spark-shell连接)
配置文件:将hive-site.xml(修改数据库连接为node01)、core-site.xml、hdfs-site.xml拷贝到Spark的conf/目录。
驱动:将MySQL驱动(如mysql-connector-java-5.1.49.jar)放入jars/目录。
验证:重启spark-shell,执行show tables验证连接。
3. Spark beeline(Thrift Server模式)
步骤:同外部Hive配置,启动Thrift Server后,通过beeline -u jdbc:hive2://node01:10000 -n root连接。
4. Spark-SQL CLI(命令行工具)
操作:将驱动和hive-site.xml放入对应目录,通过spark-sql.cmd启动,直接执行SQL(如show databases)。
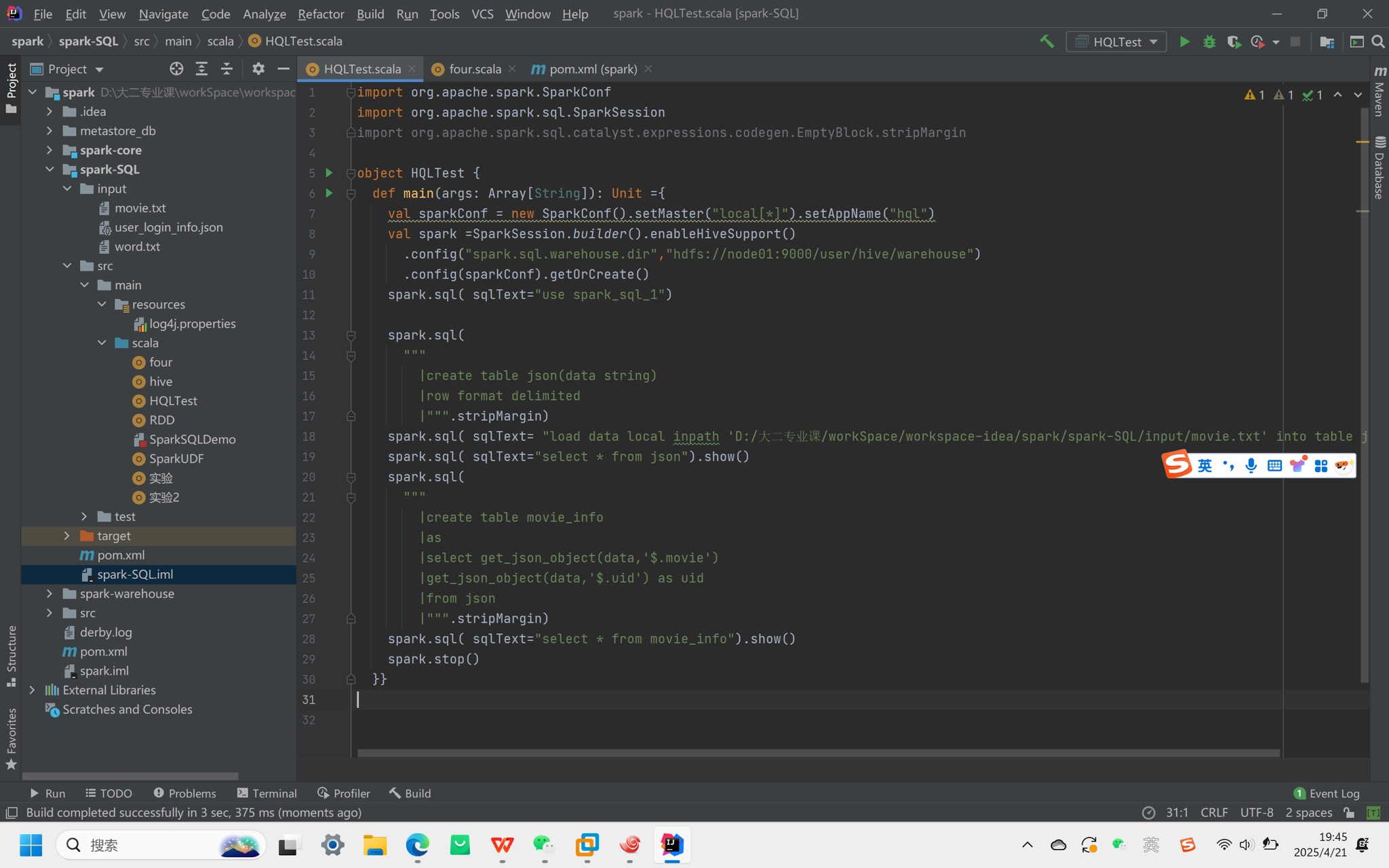
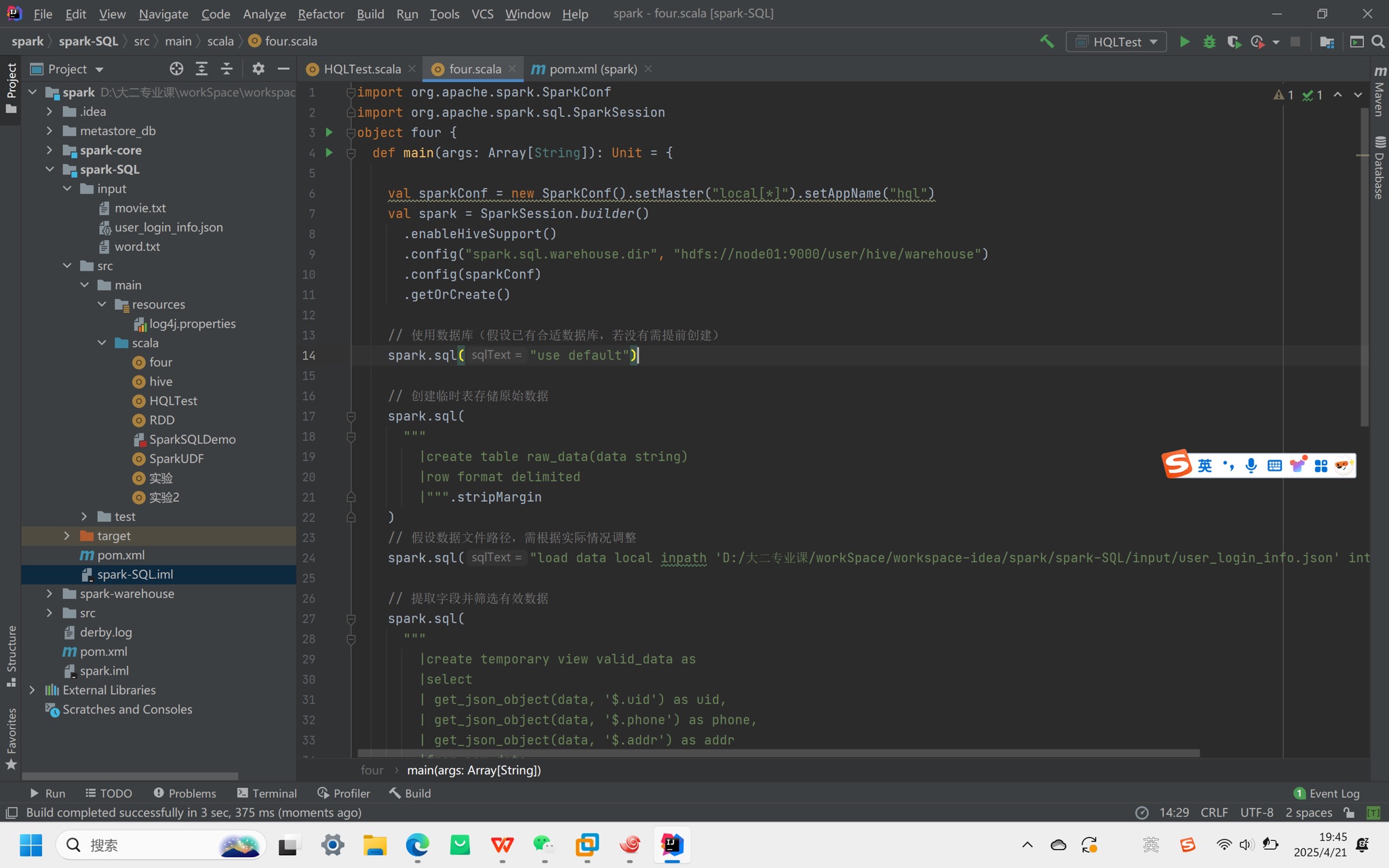
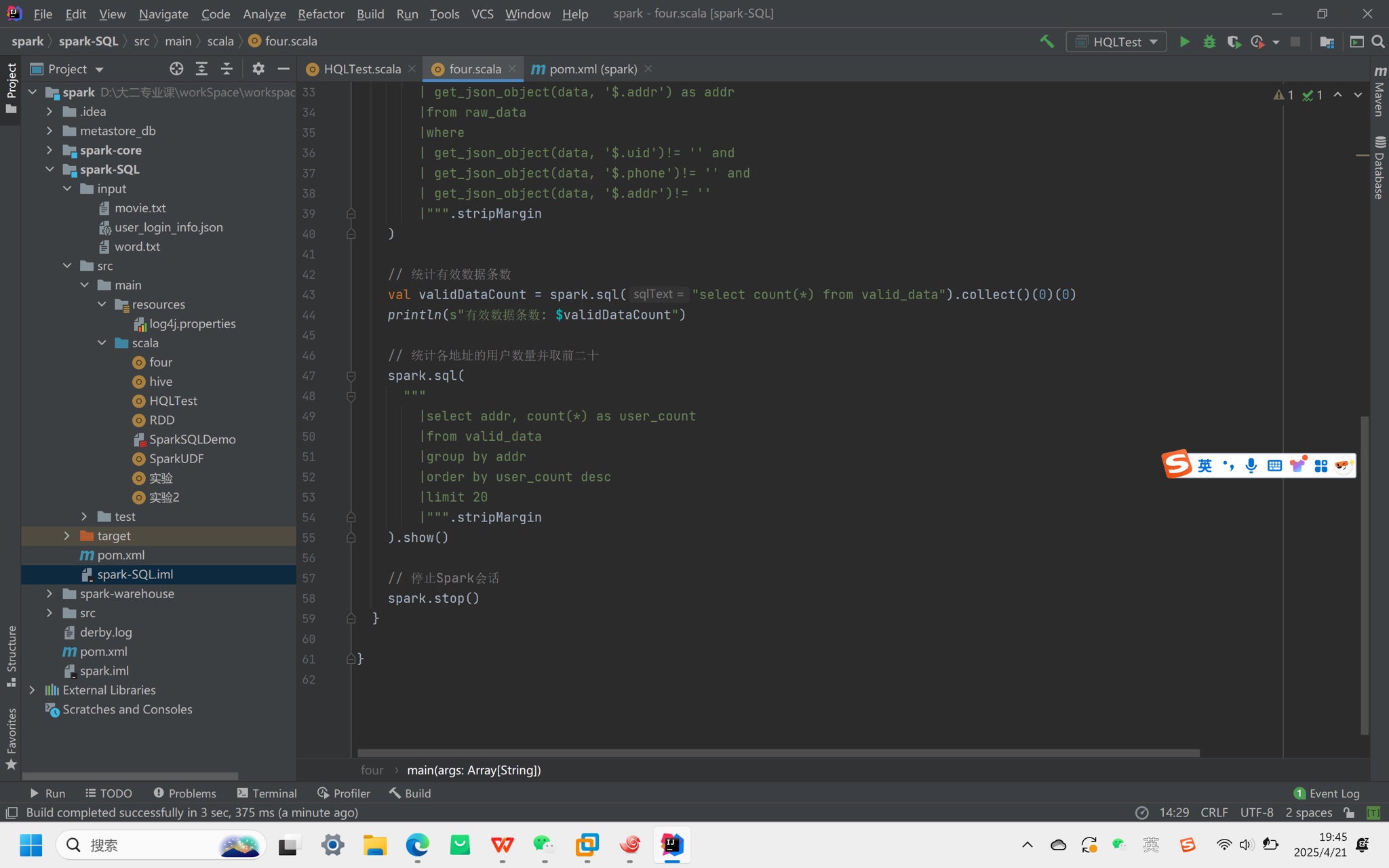
5. 代码操作(Scala示例)
依赖:添加spark-hive_2.12和hive-exec依赖。
配置:
将hive-site.xml放入项目resources目录。
通过enableHiveSupport()启用Hive支持,设置仓库路径:
.config("spark.sql.warehouse.dir", "hdfs://node01:9000/user/hive/warehouse")
常见问题:
权限错误:添加System.setProperty("HADOOP_USER_NAME", "node01")(替换为实际用户名)。
数据库位置异常:需显式配置仓库路径到HDFS,避免默认存于本地
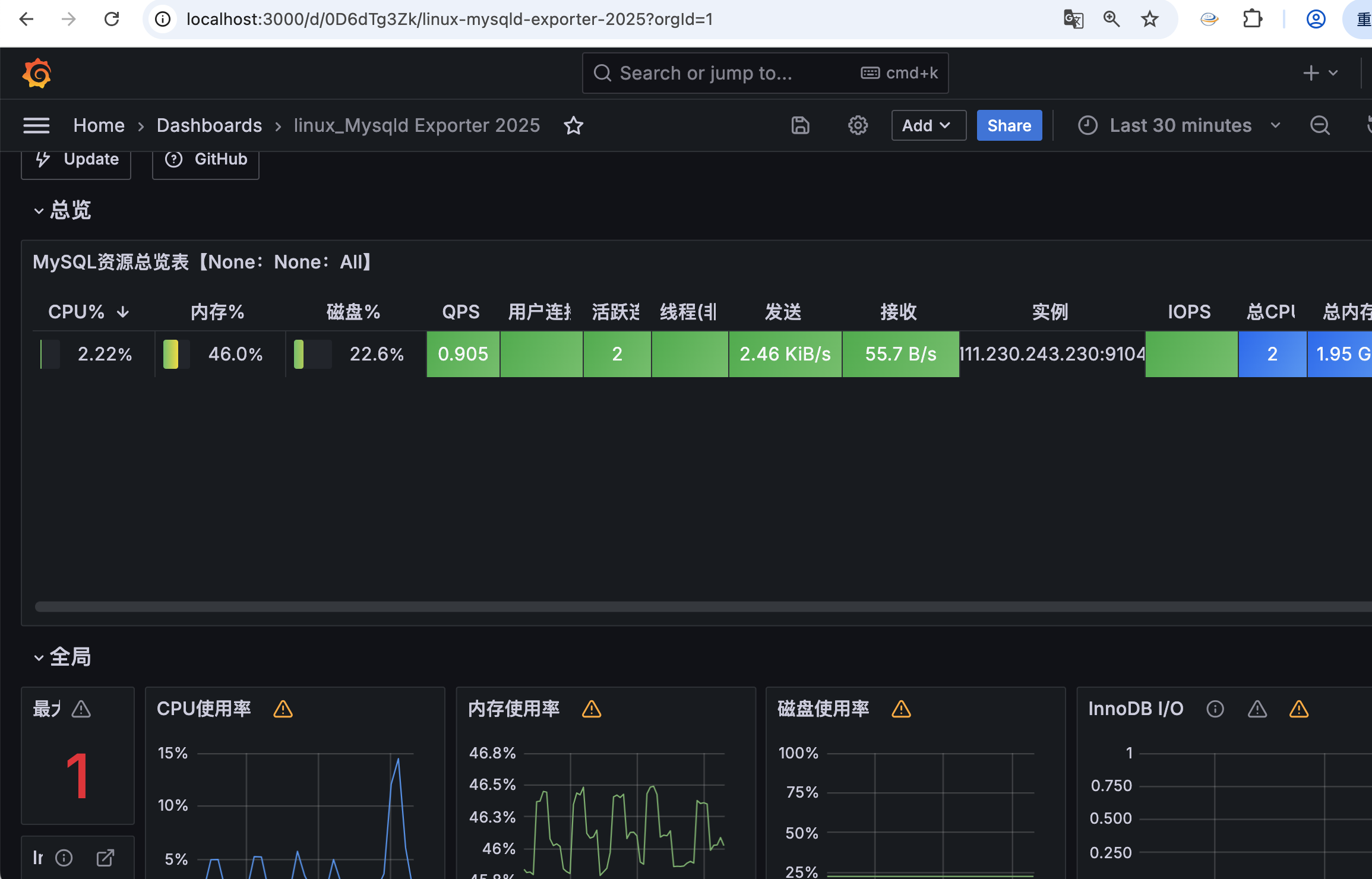
二、 实验