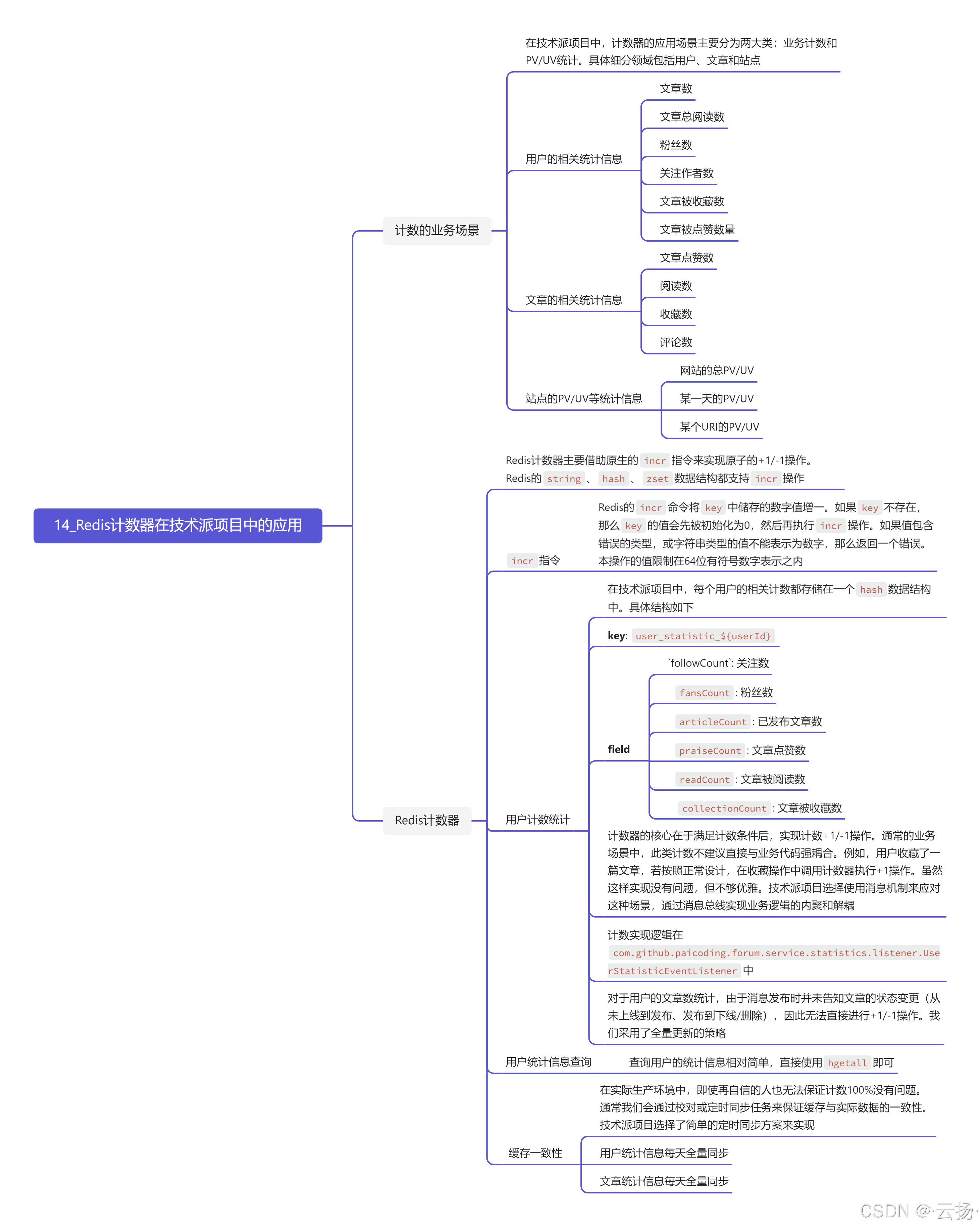
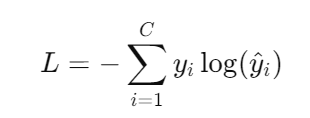主成分分析
PCA的目的是:对数据进行一个线性变换,在最大程度保留原始信息的前提下去除数据中彼此相关的信息。反映在变量上就是说,对所有的变量进行一个线性变换,使得变换后得到的变量彼此之间不相关,并且是所有可能的线性变换中方差最大的一些变量(我们认为方差体现了信息量的大小)。
总体主成分分析
设
X
\mathbf{X}
X是一个
n
n
n维随机向量,其均值向量为
μ
=
μ
1
,
…
,
μ
n
\mu=\mu_1,\dots,\mu_n
μ=μ1,…,μn、协方差矩阵为
Σ
=
(
σ
i
j
)
,
i
,
j
=
1
,
2
,
…
,
n
\Sigma=(\sigma_{ij}),\;i,j=1,2,\dots,n
Σ=(σij),i,j=1,2,…,n。对
X
\mathbf{X}
X进行一个线性变换
T
\mathcal{T}
T得到一个
n
n
n维随机向量
Y
=
(
Y
1
,
…
,
Y
n
)
\mathbf{Y}=(\mathbf{Y}_1,\dots,\mathbf{Y}_n)
Y=(Y1,…,Yn),
T
\mathcal{T}
T的矩阵为:
A
=
(
α
1
α
2
⋮
α
n
)
\begin{equation*} A= \begin{pmatrix} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{pmatrix} \end{equation*}
A=
α1α2⋮αn
若:
- Cov ( Y ) \operatorname{Cov}(\mathbf{Y}) Cov(Y)是一个对角矩阵,即 Cov ( Y i , Y j ) = 0 , i ≠ j \operatorname{Cov}(\mathbf{Y}_i,\mathbf{Y}_j)=0,\;i\ne j Cov(Yi,Yj)=0,i=j;
- Y 1 \mathbf{Y}_1 Y1是所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差最大的随机变量, Y 2 \mathbf{Y}_2 Y2是与 Y 1 \mathbf{Y}_1 Y1不相关的所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差第二大的随机变量,以此类推。
则分别称
Y
1
,
Y
2
,
…
,
Y
n
\mathbf{Y}_1,\mathbf{Y}_2,\dots,\mathbf{Y}_n
Y1,Y2,…,Yn是第一、第二、……、第
n
n
n主成分。
这一定义是否足够?
若不对
T
\mathcal{T}
T的矩阵
A
A
A作出相应的限制,对
X
\mathbf{X}
X进行线性变换后得到的
Y
i
,
i
=
1
,
2
,
…
,
n
\mathbf{Y}_i,\;i=1,2,\dots,n
Yi,i=1,2,…,n的方差可以任意大。
Var
(
Y
i
)
=
Cov
(
Y
)
(
i
,
i
)
=
Cov
(
A
X
)
(
i
,
i
)
=
(
A
Σ
A
T
)
i
,
i
=
α
i
Σ
α
i
T
\begin{equation*} \operatorname{Var}(\mathbf{Y}_i)=\operatorname{Cov}(\mathbf{Y})_{(i,i)}=\operatorname{Cov}(A\mathbf{X})_{(i,i)}=(A\Sigma A^T)_{i,i}=\alpha_i\Sigma\alpha_i^T \end{equation*}
Var(Yi)=Cov(Y)(i,i)=Cov(AX)(i,i)=(AΣAT)i,i=αiΣαiT
若
Var
(
Y
i
)
>
0
\operatorname{Var}(\mathbf{Y}_i)>0
Var(Yi)>0,取矩阵
B
=
k
A
B=kA
B=kA,
Z
=
k
A
X
\mathbf{Z}=kA\mathbf{X}
Z=kAX,则:
Var
(
Y
i
)
=
(
k
α
i
)
Σ
(
k
α
i
)
T
=
k
2
α
i
Σ
α
i
\begin{equation*} \operatorname{Var}(\mathbf{Y}_i)=(k\alpha_i)\Sigma(k\alpha_i)^T=k^2\alpha_i\Sigma\alpha_i \end{equation*}
Var(Yi)=(kαi)Σ(kαi)T=k2αiΣαi
改变
k
k
k的值,即可对
Y
i
,
i
=
1
,
2
,
…
,
n
\mathbf{Y}_i,\;i=1,2,\dots,n
Yi,i=1,2,…,n的方差进行任意的放缩。
因此,我们需要对
A
A
A进行相应的限制,在这里我们人为地选择要求
A
A
A是一个正交矩阵,也就是让
α
i
α
i
T
=
1
\alpha_i\alpha_i^T=1
αiαiT=1。
总体主成分完整定义
设
X
\mathbf{X}
X是一个
n
n
n维随机向量,其均值向量为
μ
=
μ
1
,
…
,
μ
n
\mu=\mu_1,\dots,\mu_n
μ=μ1,…,μn、协方差矩阵为
Σ
=
(
σ
i
j
)
,
i
,
j
=
1
,
2
,
…
,
n
\Sigma=(\sigma_{ij}),\;i,j=1,2,\dots,n
Σ=(σij),i,j=1,2,…,n。对
X
\mathbf{X}
X进行一个线性变换
T
\mathcal{T}
T得到一个
n
n
n维随机向量
Y
=
(
Y
1
,
…
,
Y
n
)
\mathbf{Y}=(\mathbf{Y}_1,\dots,\mathbf{Y}_n)
Y=(Y1,…,Yn),
T
\mathcal{T}
T的矩阵为:
A
=
(
α
1
α
2
⋮
α
n
)
\begin{equation*} A= \begin{pmatrix} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{pmatrix} \end{equation*}
A=
α1α2⋮αn
若:
- A A T = I AA^T=I AAT=I;
- Cov ( Y ) \operatorname{Cov}(\mathbf{Y}) Cov(Y)是一个对角矩阵,即 Cov ( Y i , Y j ) = 0 , i ≠ j \operatorname{Cov}(\mathbf{Y}_i,\mathbf{Y}_j)=0,\;i\ne j Cov(Yi,Yj)=0,i=j;
- Y 1 \mathbf{Y}_1 Y1是所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差最大的随机变量, Y 2 \mathbf{Y}_2 Y2是与 Y 1 \mathbf{Y}_1 Y1不相关的所有对 X \mathbf{X} X进行线性变换后得到的随机变量中方差第二大的随机变量,以此类推。
则分别称 Y 1 , Y 2 , … , Y n \mathbf{Y}_1,\mathbf{Y}_2,\dots,\mathbf{Y}_n Y1,Y2,…,Yn是第一、第二、……、第 n n n主成分。
主成分求解定理
设
X
\mathbf{X}
X是一个
n
n
n维随机向量,
Σ
\Sigma
Σ是其协方差矩阵,
Σ
\Sigma
Σ的特征值\footnote{若特征多项式有重根,则标准正交化特征向量组不唯一,主成分也不唯一。}从大到小记作
λ
1
,
…
,
λ
n
\lambda_1,\dots,\lambda_n
λ1,…,λn,
φ
1
,
…
,
φ
n
\varphi_1,\dots,\varphi_n
φ1,…,φn为对应的标准正交化特征向量,则
X
\mathbf{X}
X的第
i
i
i个主成分以及其方差为:
Y
i
=
φ
i
T
X
,
Var
(
Y
i
)
=
φ
i
T
Σ
φ
i
=
λ
i
\begin{equation*} \mathbf{Y}_i=\varphi_i^T\mathbf{X},\;\operatorname{Var}(\mathbf{Y}_i)=\varphi_i^T\Sigma\varphi_i=\lambda_i \end{equation*}
Yi=φiTX,Var(Yi)=φiTΣφi=λi
考虑到:
Var
(
Y
i
)
=
α
i
Σ
α
i
T
,
Cov
(
Y
i
,
Y
j
)
=
α
i
Σ
α
j
T
\begin{equation*} \operatorname{Var}(\mathbf{Y}_i)=\alpha_i\Sigma\alpha_i^T,\quad \operatorname{Cov}(\mathbf{Y}_i,\mathbf{Y}_j)=\alpha_i\Sigma\alpha_j^T \end{equation*}
Var(Yi)=αiΣαiT,Cov(Yi,Yj)=αiΣαjT
求解主成分的过程即为求解:
α
i
=
arg
max
α
i
Σ
α
i
T
s.t.
{
∣
∣
α
i
∣
∣
=
1
,
i
=
1
,
2
,
…
,
n
α
i
Σ
α
j
=
0
,
j
<
i
\begin{gather*} \alpha_i=\arg\max\alpha_i\Sigma\alpha_i^T \\ \operatorname{s.t.} \begin{cases} ||\alpha_i||=1,\;&i=1,2,\dots,n\\ \alpha_i\Sigma\alpha_j=0,\;&j<i \end{cases} \end{gather*}
αi=argmaxαiΣαiTs.t.{∣∣αi∣∣=1,αiΣαj=0,i=1,2,…,nj<i

于是上述结论成立。
因子载荷的定义
将第
i
i
i个主成分
Y
i
\mathbf{Y}_i
Yi与变量
X
j
\mathbf{X}_j
Xj的相关系数
ρ
(
Y
i
,
X
j
)
\rho(\mathbf{Y}_i,\mathbf{X}_j)
ρ(Yi,Xj)称为因子载荷。可推得:
ρ
(
Y
i
,
X
j
)
=
λ
i
α
i
j
σ
j
j
,
i
,
j
=
1
,
2
,
…
,
n
\begin{equation*} \rho(\mathbf{Y}_i,\mathbf{X}_j)=\frac{\sqrt{\lambda_i}\alpha_{ij}}{\sqrt{\sigma_{jj}}},\;i,j=1,2,\dots,n \end{equation*}
ρ(Yi,Xj)=σjjλiαij,i,j=1,2,…,n
由相关系数的定义:
ρ
(
Y
i
,
X
j
)
=
Cov
(
Y
i
,
X
j
)
Var
(
Y
i
)
Var
(
X
j
)
=
Cov
(
α
i
X
,
e
j
T
X
)
λ
i
σ
j
j
=
α
i
Σ
e
j
λ
i
σ
j
j
=
e
j
T
Σ
α
i
λ
i
σ
j
j
=
e
j
T
λ
i
α
i
λ
i
σ
j
j
=
λ
i
α
i
j
σ
j
j
\begin{align} \rho(\mathbf{Y}_i,\mathbf{X}_j) &=\frac{\operatorname{Cov}(\mathbf{Y}_i,\mathbf{X}_j)}{\sqrt{\operatorname{Var}(\mathbf{Y}_i)\operatorname{Var}(\mathbf{X}_j)}}=\frac{\operatorname{Cov}(\alpha_i\mathbf{X},e_j^T\mathbf{X})}{\sqrt{\lambda_i\sigma_{jj}}} \\ &=\frac{\alpha_i\Sigma e_j}{\sqrt{\lambda_i\sigma_{jj}}}=\frac{e_j^T\Sigma\alpha_i}{\sqrt{\lambda_i\sigma_{jj}}}=\frac{e_j^T\lambda_i\alpha_i}{\sqrt{\lambda_i\sigma_{jj}}}=\frac{\sqrt{\lambda_i}\alpha_{ij}}{\sqrt{\sigma_{jj}}} \end{align}
ρ(Yi,Xj)=Var(Yi)Var(Xj)Cov(Yi,Xj)=λiσjjCov(αiX,ejTX)=λiσjjαiΣej=λiσjjejTΣαi=λiσjjejTλiαi=σjjλiαij
总体主成分的性质
总体主成分具有如下性质:
- Cov ( Y ) = diag { λ 1 , … , λ n } \operatorname{Cov}(\mathbf{Y})=\operatorname{diag}\{\lambda_1,\dots,\lambda_n\} Cov(Y)=diag{λ1,…,λn};
- Y \mathbf{Y} Y的方差之和等于 X \mathbf{X} X的方差之和,即 ∑ i = 1 n λ i = ∑ i = 1 n σ i i \sum\limits_{i=1}^{n}\lambda_i=\sum\limits_{i=1}^{n}\sigma_{ii} i=1∑nλi=i=1∑nσii;
- 第
i
i
i个主成分与原变量的因子负荷量满足:
∑ j = 1 n σ j j ρ 2 ( Y i , X j ) = λ i \begin{equation*} \sum_{j=1}^{n}\sigma_{jj}\rho^2(\mathbf{Y}_i,\mathbf{X}_j)=\lambda_i \end{equation*} j=1∑nσjjρ2(Yi,Xj)=λi - 原变量的第
j
j
j个分量与所有主成分的因子负荷量满足:
∑ i = 1 n ρ 2 ( Y i , X j ) = 1 \begin{equation*} \sum_{i=1}^{n}\rho^2(\mathbf{Y}_i,\mathbf{X}_j)=1 \end{equation*} i=1∑nρ2(Yi,Xj)=1
证明:- 由PCA求解过程直接可得。
- 显然:
∑ i = 1 n Var ( Y i ) = tr [ Cov ( Y ) ] = tr [ Cov ( A X ) ] = tr ( A Σ A T ) = tr ( Σ A T A ) = tr ( Σ ) = ∑ i = 1 n Var ( X i ) \begin{align*} \sum_{i=1}^{n}\operatorname{Var}(\mathbf{Y}_i) &=\operatorname{tr}[\operatorname{Cov}(\mathbf{Y})]=\operatorname{tr}[\operatorname{Cov}(A\mathbf{X})]=\operatorname{tr}(A\Sigma A^T) \\ &=\operatorname{tr}(\Sigma A^TA)=\operatorname{tr}(\Sigma)=\sum_{i=1}^{n}\operatorname{Var}(\mathbf{X}_i) \end{align*} i=1∑nVar(Yi)=tr[Cov(Y)]=tr[Cov(AX)]=tr(AΣAT)=tr(ΣATA)=tr(Σ)=i=1∑nVar(Xi) - 显然:
∑ j = 1 n σ j j ρ 2 ( Y i , X j ) = ∑ j = 1 n λ i α i j 2 = λ i α i α i T = λ i \begin{equation*} \sum_{j=1}^{n}\sigma_{jj}\rho^2(\mathbf{Y}_i,\mathbf{X}_j)=\sum_{j=1}^{n}\lambda_i\alpha_{ij}^2=\lambda_i\alpha_i\alpha_i^T=\lambda_i \end{equation*} j=1∑nσjjρ2(Yi,Xj)=j=1∑nλiαij2=λiαiαiT=λi - 因为 A A A是正交矩阵,所以 A A A可逆,于是 X \mathbf{X} X可以表示为 Y 1 , … , n \mathbf{Y}_1,\dots,\mathbf{n} Y1,…,n的线性组合,所以二者的复相关系数为 1 1 1。由复相关系数性质可直接得出结论。
贡献率定义
称第
i
i
i个主成分
Y
i
\mathbf{Y}_i
Yi的方差与所有主成分方差之和为
Y
i
\mathbf{Y}_i
Yi的方差贡献率,记为
η
i
\eta_i
ηi,即:
η
i
=
λ
i
∑
j
=
1
n
λ
j
\begin{equation*} \eta_i=\frac{\lambda_i}{\sum\limits_{j=1}^{n}\lambda_j} \end{equation*}
ηi=j=1∑nλjλi
将:
∑
i
=
1
k
λ
i
∑
i
=
1
n
λ
i
\begin{equation*} \frac{\sum\limits_{i=1}^{k}\lambda_i}{\sum\limits_{i=1}^{n}\lambda_i} \end{equation*}
i=1∑nλii=1∑kλi
称为主成分
Y
1
,
…
.
Y
k
\mathbf{Y}_1,\dots.\mathbf{Y}_k
Y1,….Yk的累计方差贡献率。称主成分
Y
1
,
…
.
Y
k
\mathbf{Y}_1,\dots.\mathbf{Y}_k
Y1,….Yk与变量
X
j
\mathbf{X}_j
Xj之间的复相关系数的平方
R
2
R^2
R2为
Y
1
,
…
.
Y
k
\mathbf{Y}_1,\dots.\mathbf{Y}_k
Y1,….Yk对
X
j
\mathbf{X}_j
Xj的贡献率,其计算公式为:
R
2
=
∑
i
=
1
k
λ
i
α
i
j
2
σ
i
i
\begin{equation*} R^2=\sum_{i=1}^{k}\frac{\lambda_i\alpha_{ij}^2}{\sigma_{ii}} \end{equation*}
R2=i=1∑kσiiλiαij2
由前述,我们一般通过选择主成分的个数来实现对数据的降维,即选择主成分的个数使它们的累计方差贡献率达到一定比例(一般为 85 % 85\% 85%)。
样本主成分分析
假设对
n
n
n维随机变量
X
\mathbf{X}
X进行
m
m
m次独立观测,得到
m
m
m个
n
n
n维样本
x
1
,
…
,
x
m
x_1,\dots,x_m
x1,…,xm。在样本主成分分析中,我们使用样本来估计
X
\mathbf{X}
X的协方差矩阵,即:
S
=
(
s
i
j
)
,
s
i
j
=
1
m
−
1
∑
k
=
1
m
(
x
k
i
−
X
^
i
)
(
x
k
j
−
X
^
j
)
,
i
,
j
=
1
,
2
,
…
,
n
\begin{equation*} S=(s_{ij}),\;s_{ij}=\frac{1}{m-1}\sum_{k=1}^{m}(x_{ki}-\hat{\mathbf{X}}_i)(x_{kj}-\hat{\mathbf{X}}_j),\;i,j=1,2,\dots,n \end{equation*}
S=(sij),sij=m−11k=1∑m(xki−X^i)(xkj−X^j),i,j=1,2,…,n
其中:
X
^
i
=
1
m
∑
j
=
1
m
x
j
i
,
i
=
1
,
2
,
…
,
n
\begin{equation*} \hat{\mathbf{X}}_i=\frac{1}{m}\sum_{j=1}^{m}x_{ji},\;i=1,2,\dots,n \end{equation*}
X^i=m1j=1∑mxji,i=1,2,…,n
其余步骤与总体主成分分析一致。
注意事项
多重共线性问题
当原始变量出现多重共线性时,PCA的效果会受到影响,这是因为重复的信息在方差占比中重复进行了计算。我们可以通过计算协方差矩阵的最小特征值来判断是否出现多重共线性的情况。若最小特征值趋于 0 0 0,则需要对纳入研究的变量进行考察与筛选。
相关矩阵导出主成分
上面我们都是对协方差矩阵的特征值分解进行计算,但在现实中,我们可能会对数据进行标准化处理来消除量纲带来的影响,注意到标准化后数据的协方差矩阵即为相关矩阵,此时将相关矩阵作对应的特征值分解即可。但需要注意:标准化后各变量方差相等均为 1 1 1,损失了部分信息,所以会使得标准化后的各变量在对主成分构成中的作用趋于相等。因此,取值范围在同量级的数据建议使用协方差矩阵直接求解主成分,若变量之间数量级差异较大,再使用相关矩阵求解主成分。
算法流程

主成分分析的应用
主成分分类
可以实现对变量之间的分类。将变量进行主成分分析,得到第一主成分与第二主成分,然后画出各变量与两个主成分载荷的二维平面图,即将各变量画在以两个主成分为轴的平面上,变量的两个坐标是主成分在变量上的载荷。可以认为相似变量会聚在平面图中聚在一起。
主成分回归
若数据存在高度的多重共线性,对数据进行主成分筛选,然后用主成分去进行回归。
R语言代码
> # 以鸢尾花数据集作为示例
> data <- iris[1:4]
> # 变量间量纲差异不大,使用协方差矩阵进行分析
> Sigma <- cov(data)
> # 计算特征值,因为是示例就不做处理了
> eigen(Sigma)$values
[1] 4.22824171 0.24267075 0.07820950 0.02383509
> # center和scale.控制是否对原始数据进行标准化
> # 注意scale.,后面有一个点,不是scale
> x <- prcomp(data, center=FALSE, scale.=FALSE)
> # 呈现结果
> summary(x)
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 7.8613 1.45504 0.28353 0.15441
Proportion of Variance 0.9653 0.03307 0.00126 0.00037
Cumulative Proportion 0.9653 0.99837 0.99963 1.00000
> # 输出因子载荷矩阵,显示出的矩阵其实就是A^T
> # 可以自己尝试证明一下,利用协方差的性质以及Y之间的线性无关性
> x$rotation
PC1 PC2 PC3 PC4
Sepal.Length -0.7511082 0.2841749 0.50215472 0.3208143
Sepal.Width -0.3800862 0.5467445 -0.67524332 -0.3172561
Petal.Length -0.5130089 -0.7086646 -0.05916621 -0.4807451
Petal.Width -0.1679075 -0.3436708 -0.53701625 0.7518717
> # 如果输入x,则输出训练样本经过主成分分析后的结果,即Y值
> # 如果输入一组新的数据newdata,则输出newdata经过主成分分析后的结果
> # 这里因为数据太多就用head函数控制只显示前10行
> head(predict(x), 10)
PC1 PC2 PC3 PC4
[1,] -5.912747 2.302033 0.007401536 0.003087706
[2,] -5.572482 1.971826 0.244592251 0.097552888
[3,] -5.446977 2.095206 0.015029262 0.018013331
[4,] -5.436459 1.870382 0.020504880 -0.078491501
[5,] -5.875645 2.328290 -0.110338269 -0.060719326
[6,] -6.477598 2.324650 -0.237202487 -0.021419633
[7,] -5.515975 2.070904 -0.229853120 -0.050406649
[8,] -5.850929 2.148075 0.018793774 -0.045342619
[9,] -5.158920 1.775064 0.061039220 -0.031128633
[10,] -5.645001 1.990001 0.224852923 -0.057434390
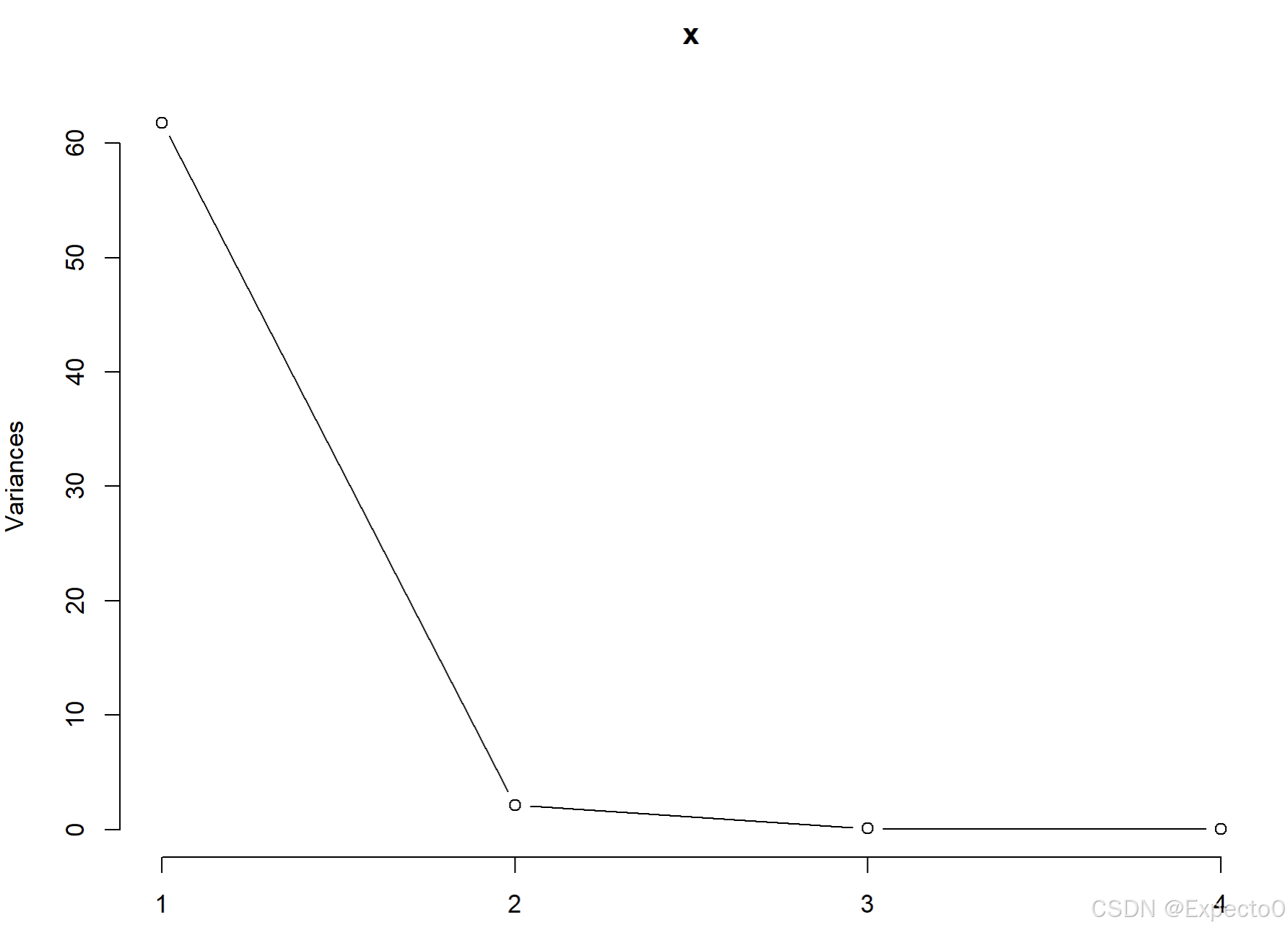
> # 画碎石图,即样本主成分与方差贡献率之间的曲线图或条形图
> screeplot(x, type = "barplot")
> screeplot(x, type = "lines")

主成分分析在R语言中还有另一个函数叫做princomp,但官方更推荐使用prcomp。主要是因为求解算法问题,prcomp使用svd分解进行求解,后面我会对这里进行一些补充。
Python代码
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
# 对数据进行标准化(可选)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 初始化 PCA,保留所有主成分
pca = PCA(n_components=4)
X_pca = pca.fit_transform(X_scaled)
print("各主成分解释的方差比例:")
print(pca.explained_variance_ratio_)
print("累计解释方差:", np.cumsum(pca.explained_variance_ratio_))
# 每个主成分上的特征权重(特征向量)
loadings = pd.DataFrame(pca.components_.T,
columns=[f'PC{i+1}' for i in range(pca.n_components_)],
index=feature_names)
print(loadings)
参考文献
- 薛毅,统计建模与R软件
- 何晓群,多元统计分析——基于R语言
- 李航,统计学方法
- Richard A.Johnson,Applied Multivariate Statistical Analysis
后续会补充的内容
- 具体数值求解算法
- R语言两个函数的具体差异
- 为什么特征值接近于0就意味着多重共线性
- R2的性质,即为什么R2等于所有自变量与因变量相关系数平方的加和