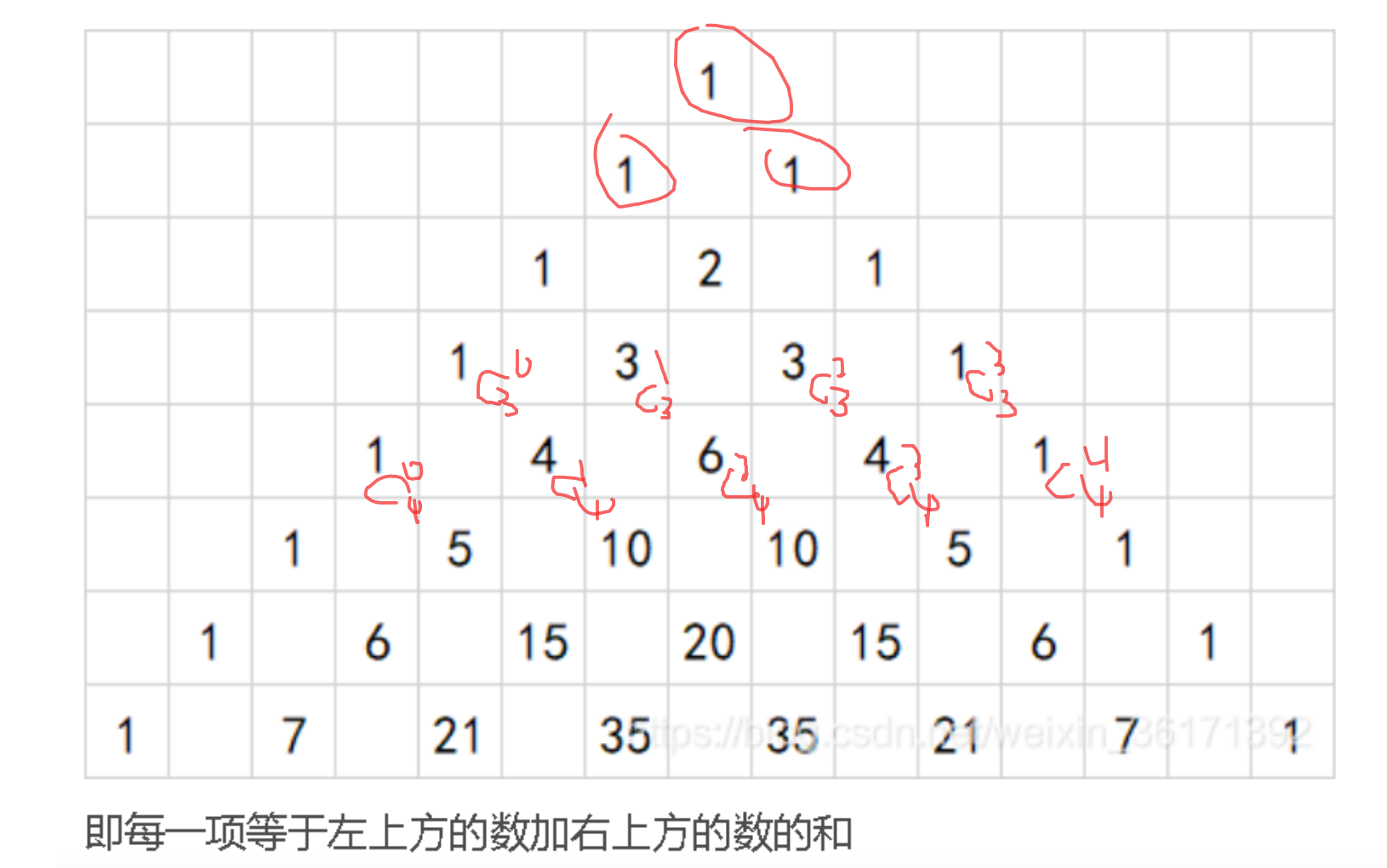
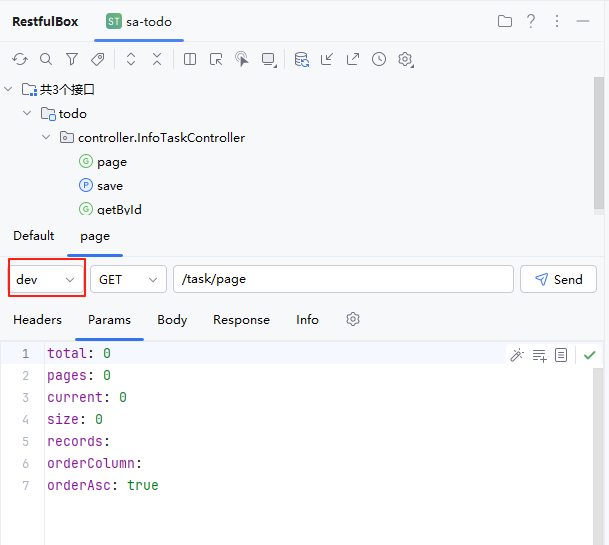
数据预处理
读取csv数据集
def read_file(file_path):
data = []
label = []
with open(file_path, "r", encoding="utf-8") as file:
reader = csv.reader(file)
next(reader) # 跳过标题行
# row每一行用英文逗号分割成列表[标签,文本] 所以标签和文本用英文逗号隔开
for row in reader:
# 数据清洗 跳过不完整行
if len(row) < 2:
print(f"跳过不完整行: {row}")
continue
# 获取每行的标签和文本
label_row, text_row = row[0], row[1]
# 数据清洗 跳过空文本的行
if not text_row:
print(f"跳过空文本的行: {row}")
continue
label.append(label_row)
# 将字符串标签转成数字标签
label = [int(i) for i in label]
print(f"读取 {len(label)} 行数据,标签分布: {Counter(label)}")
return data, label
csv.reader 默认用英文逗号(,)把一行分割成列表
数据清洗
# 数据清洗 跳过不完整行
if len(row) < 2:
print(f"跳过不完整行: {row}")
continue
# 数据清洗 跳过空文本的行
if not text_row:
print(f"跳过空文本的行: {row}")
continue