目录
MySQL表的增删改查(CRUD)
1. 新增(Create)/插入数据
1.1 单行数据 + 全列插入 insert into 表名 values(值, 值......);
1.2 单行数据 + 指定列插入
1.3 多行数据 + 指定列插入
1.4 关于时间日期(datetime) 类型的 数据插入
2. 查询(Retrieve)
2.1 全列查询(select * from 表名;)
2.2 指定列查询
2.3 查询字段(列)为表达式
2.4 指定别名查询(as 别名)
2.5 去重查询(distinct)
2.6 查询结果排序(order by)
2.7 条件查询(where 条件)
基本条件查询
and与or
范围查询(between and),(in)
模糊查询 (like)
null 的查询 (<=>,is noll)
2.8 分页查询 (limit)
3. 修改(Update)
4. 删除(Delete)
总结语句
MySQL表的增删改查(CRUD)
这个章节是mysql最核心的部分。这里涉及到的SQL都是工作中最常用到的,这些东西掌握了,覆盖日常工作80%+以上的内容了。
CRUD:
- 注释:在SQL中可以使用“ --空格+描述 ”来表示注释说明
- CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
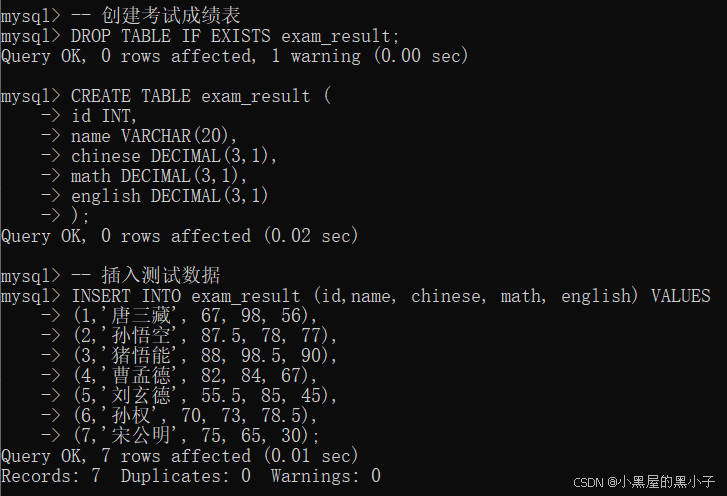
1. 新增(Create)/插入数据
1.1 单行数据 + 全列插入 insert into 表名 values(值, 值......);
into可以省略
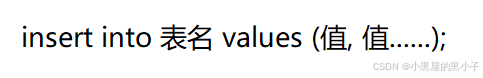
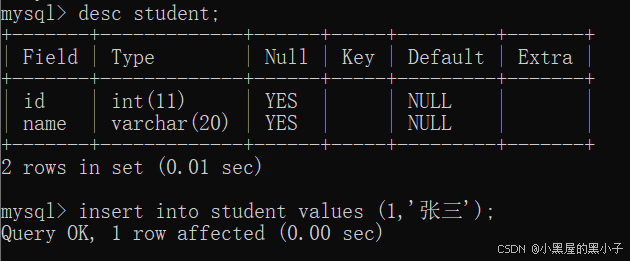
- 其中括号里值的个数,类型,顺序要和表头结构匹配,
- SQL没有字符型, ' ' 和 " " 都可以表示字符串
错误的插入方式:
个数不匹配
类型不匹配
此处还有一种错误,数据库字符集没有正确配置引起的,数据库不做任何修改,默认情况下创建的数据库字符集是“拉丁文"字符集,不能表示中文。MySQL 5.7 及更早版本。
- 此时要做的事情,让数据库的字符集和你输入的文字的字符集匹配。如果你输入的文字是utf8,就得在创建数据库的时候设置成utf8。
- 删除该数据库重新创建数据库,在创建数据库的时候指定对应字符集。一般来说,咱们的终端是utf8的,但是也可能有同学是gbk
创建了数据库之后也能更改字符集,但是比较麻烦。


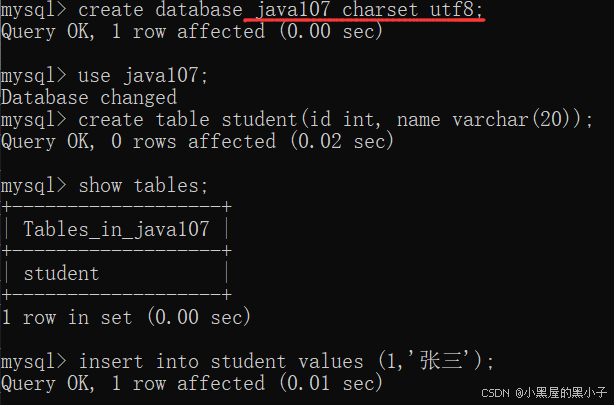
1.2 单行数据 + 指定列插入
- 只给某些指定的列进行插入数据,其他的列将按照默认值的方式填充。
- 例如:插入一行,指定插后两列


1.3 多行数据 + 指定列插入
- 一次插入多行数据,values后面写多个() 通过 , 隔开。
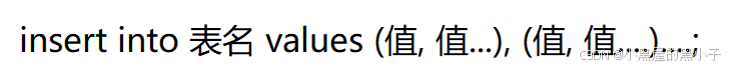
例如:插入两行,指定插后两列。
- 这里的提示,就是反馈效果。客户端给服务器发起插入请求,服务器要返回这次插入是否成功了。
- 一行受到影响就是成功插入了一行,两行受到影响就是成功插入了两行。可能插入10行,但是显示5行成功插入。


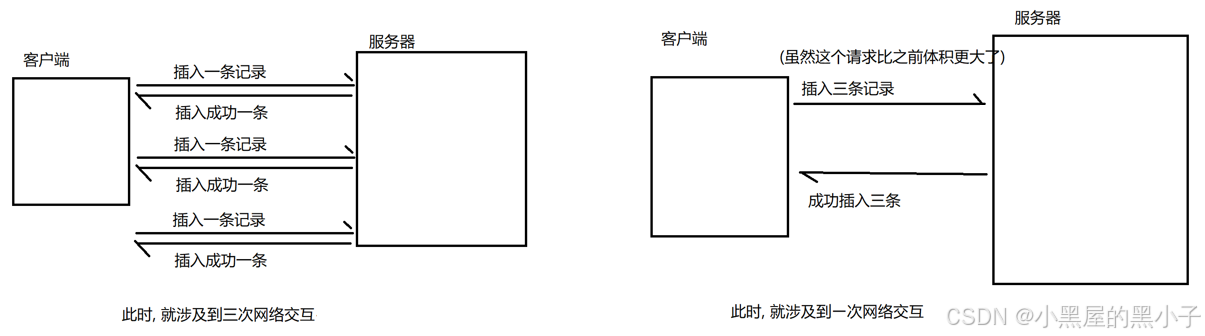
一次插入多行记录,相比于一次插入一行,分多次插入,要快不少。
mysql是一个客户端服务器结构的程序
- 分多次插入,客户端与服务器交互多次,此处的成本不仅仅是网络交互,服务器处理数据插入自身也有一系列成本(加锁等操作);一次性插入,只需客户端与服务器交互一次,所以效率会更高一些。
- 虽然一次插入多行记录体积比较大,但对效率上影响比较小;而三次网络交互,影响效率比较大。所以比较推荐使用一次插入多行记录。
1.4 关于时间日期(datetime) 类型的 数据插入
插入时间的时候,是通过固定格式的字符串来表示时间日期的。例如: '2000-06-26 8:15:26'
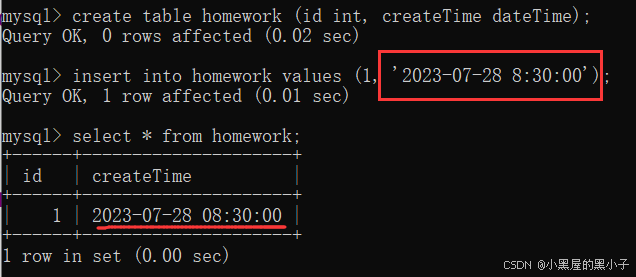
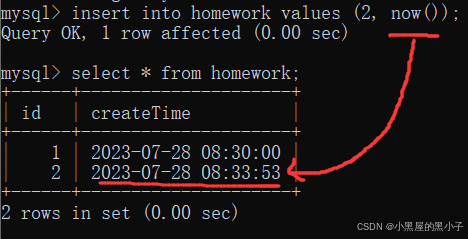
假设我现在想把这个时间日期设置成当前时刻,sql提供了一个特殊的函数now()
2. 查询(Retrieve)
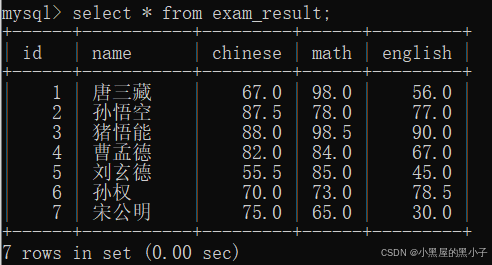
2.1 全列查询(select * from 表名;)
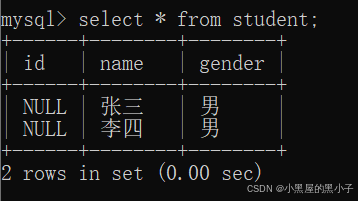
把表中的所有行和所有列都查询出来。 * 表示所有的列,这种特殊含义的符号,计算机中叫做“通配符”。
这里的表是查询出来之后,服务器通过网络把这些数据返回给客户端的,并且在客户端以表格的形式,打印出来。
select * 操作,其实也是一个危险操作。当前阶段,怎么写都没事,为了方便观察。在公司中,针对数据量比较大的生产环境不能随便select *
- mysql是一个"客户端–服务器"结构的程序。通过网络进行通信。
- 客户端这里进行的操作,就都会通过请求发送给服务器。服务器查询的结果也就会通过响应返回给客户端。
如果数据库当前这个表中的数据特别多,就可能会产生问题:
- 读取硬盘。把硬盘的IO给跑满了,此时程序的其他部分想访问硬盘,就会非常慢。
- 操作网络。可能把网卡的带宽也跑满,此时其他客户端想通过网络访问服务器,也会非常慢。
- 这样的拥堵,就可能导致客户端无法顺利访问到数据库。进一步的也就对整个系统造成影响(相当于数据库服务器挂了)。
- 得出结论,执行select * 操作,可能很危险,如果数据量有几亿,几十亿操作就麻烦了,瞬间吃满硬盘带宽和网络带宽,就可能导致其他程序无法使用硬盘或者使用网络。
- 当前阶段,怎么写都没事,为了方便观察。在公司中,针对数据量比较大的生产环境(也叫线上环境)不能随便select *

2.2 指定列查询
按需进行查询
- 指定列的顺序不需要按定义表的顺序来。
- 注意这里类型没括号


2.3 查询字段(列)为表达式
- 查询过程中,可以做一些简单的 加减乘除 之类的运算。
- 会把当前表的每一行对应列进行计算,是进行列和列之间的运算
- null参与各种运算,结果还是null


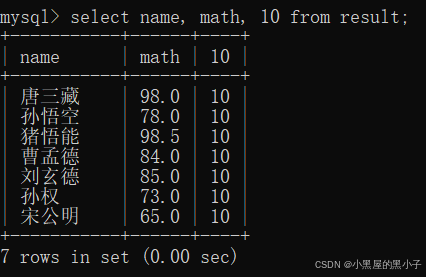
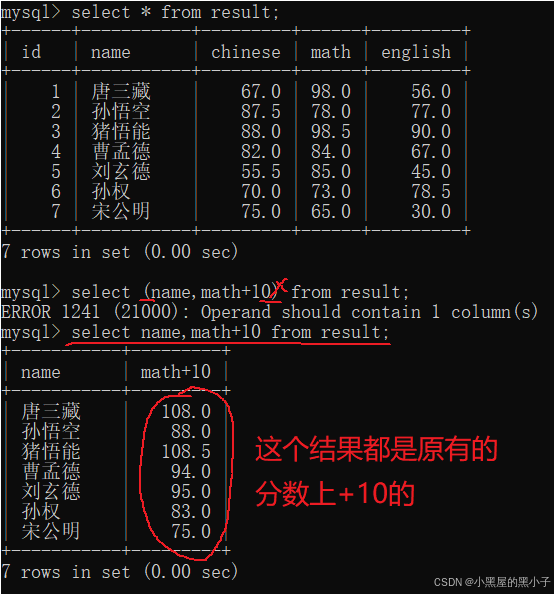
可以在查询的时候,针对分数进行变换。比如让查询的 math 成绩都在原来基础上+10分
上述这样的查询,数据库服务器硬盘的数据,是否发生了改变?并没有改变。再次查询math,此时的结果是+10之前的数据。
- msyql是一个“客户端-服务器”结构的程序!!!
- 用户在客户端输入的sql,通过请求发送给服务器,服务器解析并执行sql把查询的结果,从硬盘读取出来通过网络响应返回给客户端,客户端把这些数据以临时表的形式展示出来。只是在客户端这里显示一下的临时表。(显示一下就销毁了)和服务器那边的硬盘上的表没啥关系。
- 上上图中为什么会出现108.0这样的数字,出现在临时表里和原始的表没啥关系。decimal(3,1)这个类型是原始的表的类型不能约束临时表。
- 那临时表的类型是什么:就是一个单纯的 double / decimal不是一个带有有效数字的版本了。
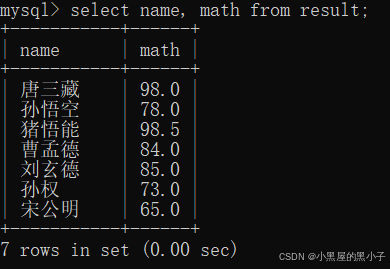
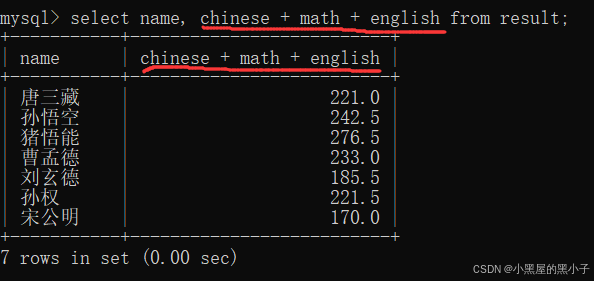
查询计算每个同学的总成绩
- 表达式查询,是让列和列之间进行运算,而不是行和行之间,(后面还会学习一个聚合查询,是行和行之间运算)
- 按照表达式查询,临时表的列名和表达式一样的,很多时候表达式的含义是不直观的。如求平方差等,很复杂的计算。所以就引出了:查询的时候给列/表达式指定别名(给表也能指定别名)
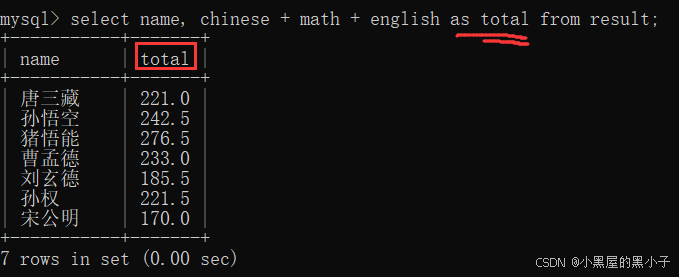
2.4 指定别名查询(as 别名)
- 查询的时候指定别名,指定别名相当于是起了个"小名"/外号,更方便的来理解含义。
- as 别名,可以是针对表达式,列,表名
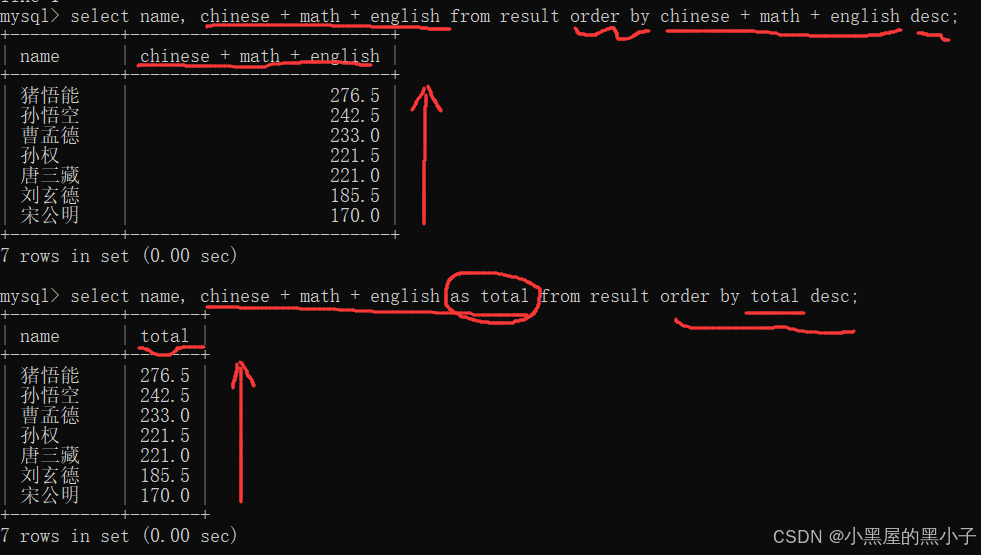
- as 关键字,as可以省略,但是不建议。math + chinese + english total
- 一个不留神,total当成了要+的一个列 或者 当成前面有个,total是一个单独的列。
- 查询结果的临时表中,列名就是刚才的别名。

2.5 去重查询(distinct)
- 使用 distinct 关键字对 某列/多个列/表达式 数据进行去重,把重复的行只保留一个。
- distinct 指定多个列的时候,要求这些列的值都相同,才视为重复。
2.6 查询结果排序(order by)
- order by 子句,按照 某些列/表达式/别名 进行排序。以行为单位。
- asc升序,desc降序,descend的缩写 不是describe。如果省略默认升序排序。
- mysql是一个客户端服务器结构的程序,
- 把请求发给服务器之后,服务器进行查询数据,并且把查询到的结果进行排序之后,再组织成响应数据返回给客户端。
- 排序仍然是针对临时数据来展开的,此处的排序,不影响原有数据在mysql服务器上存储的顺序。

- 如果一个sql 不加 order by 此时查询的结果数据的顺序是 不确定的/无序的/未定义的/不可预期的,永远不要依赖这个顺序 —— 乱纪元。在代码中不能依赖上述的顺序来展开一些代码逻辑。
- order by 指定的列,如果 select 的时候没有把这一列显示出来,也不影响排序。
- order by 还可以针对表达式以及别名进行排序。
- null数据排序,视为比任何值都小。升序出现在最上面,降序出现在最下面。null参与各种运算,结果还是null
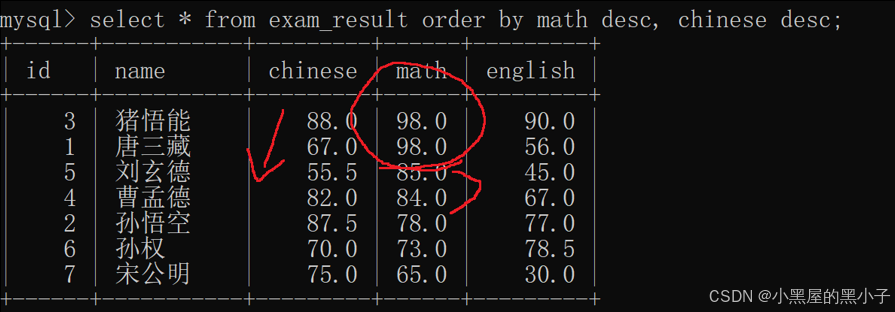
- 可以对多个字段进行排序,order by后面写多个列,使用 , 来分割开。排序优先级(主次关系)随书写顺序。
例如,查询同学各门成绩,先按照数学成绩降序,如果数学成绩相同,再按照语文降序的方式显示。
2.7 条件查询(where 条件)
- 指定具体的条件,按照条件针对数据进行筛选。
- 遍历这个表的每一行记录,把每一行的数据分别带入到条件中,如果条件成立,这个记录就会被放入结果集合中。如果条件不成立,这个记录就pass
- sql通过一系列的运算符来表示条件。

比较运算符:
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| != , <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1)。左右都是闭区间。 |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字 符 |
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
- = 在 sql 表数据条件查询中 是比较相等,在sql 表数据修改中 又表示赋值。sql 中没有 ==。
- and 相当于 &&, or相当于||, not相当于 !
- 通过where子句,搭配上条件表达式,就可以完成条件查询。
- where条件可以使用表达式,但不能使用别名。
- and的优先级高于or,在同时使用时,需要使用小括号()包裹优先执行的部分。
基本条件查询
查询英语不及格的同学及英语成绩 ( < 60 )
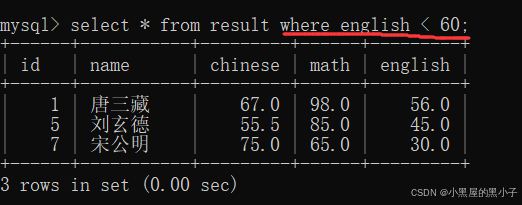
- where子句搭配上条件查询,其实相当于,针对数据库的表进行遍历,取出每一行数据,把数据代入到条件中看条件是否符合,如果是真,这个记录就保留作为结果集的一部分,如果是假,这个记录就pass,继续下一条。
- 这里如果数据量过大,服务器是不是要崩了。
- 数据量大了,硬盘读写开销,,是避免不了的。但是由于有条件限制,还有很多数据都没有作为结果集。最终给客户端返回的数据量是更可控的。(具体是否可控,也取决于条件是咋写的,至少比select * 好不少)
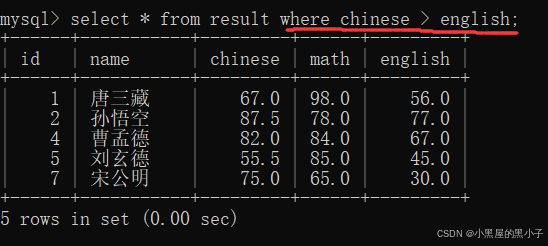
查询语文成绩好于英语成绩的同学,拿两个列进行比较
查询总分在 200 分以下的同学,使用表达式来作为条件
这里null要注意了,null参与各种运算,结果都是null。 null < 200 结果是null,所以条件不成立 false。
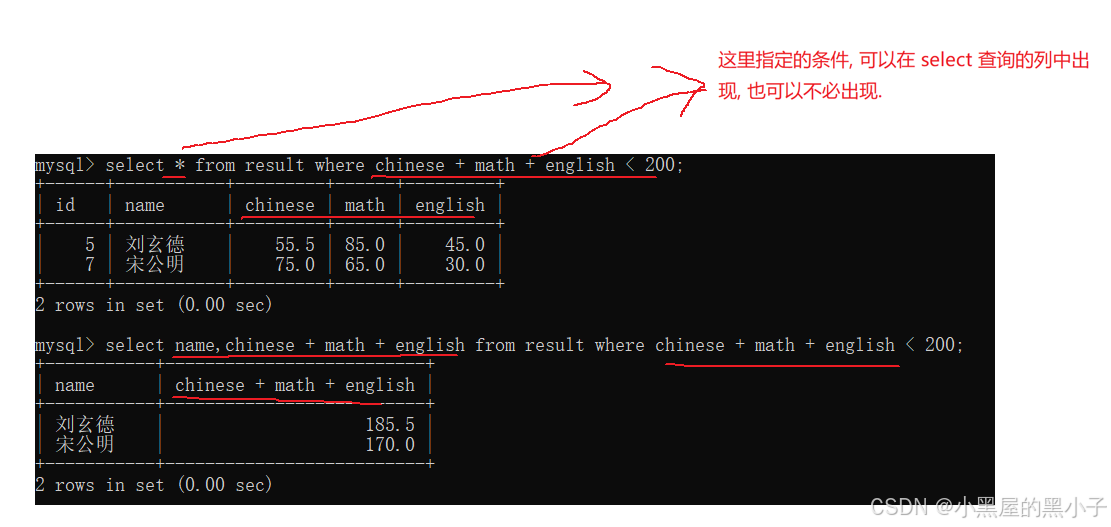
条件为表达式以及别名,会出现问题:
此处total别名不能作为where条件,和当前sql的执行顺序有关,这也是mysql对于语法规定的一部分。执行where的时候,total还处于"未定义"的状态。

写下一个sql不是从前往后的执行,执行顺序是有特定的规则的。
在上述代码中,select条件查询执行的顺序:
- 遍历表中的每个记录。
- 把这一行当前记录的值,带入到 where 的条件中,根据条件进行筛选。
- 如果这个记录条件成立,就要保留,进行列上的表达式计算。
- 如果有 order by 会在所有的行都被获取到之后(表达式也算完了),再针对所有的结果进行排序。
实现sql解析引擎的时候,其实是完全可以做到把这里的别名预先的定义好,然后再执行123,保证执行到where 的时候也能访问到别名。但是mysql 当前没有这样实现,可能是历史遗留问题吧。
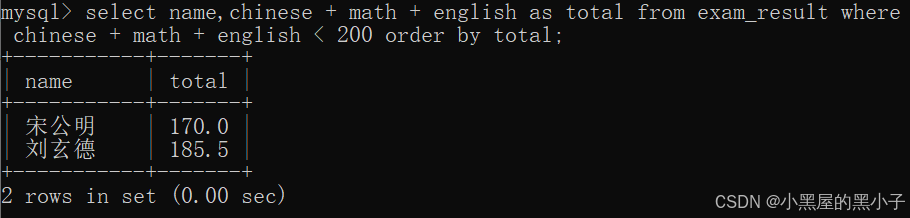
and与or
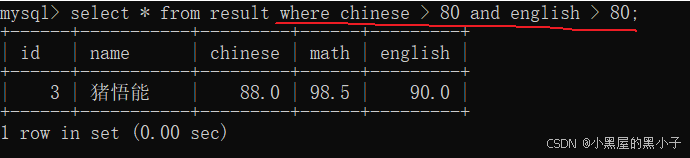
查询语文成绩大于80分,且英语成绩大于80分的同学
查询语文成绩大于80分,或英语成绩大于80分的同学
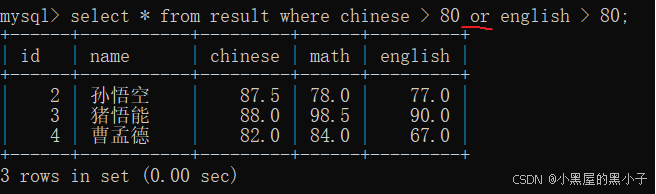
观察 AND 和 OR 的优先级:sql中 and 的运算符优先级更高。
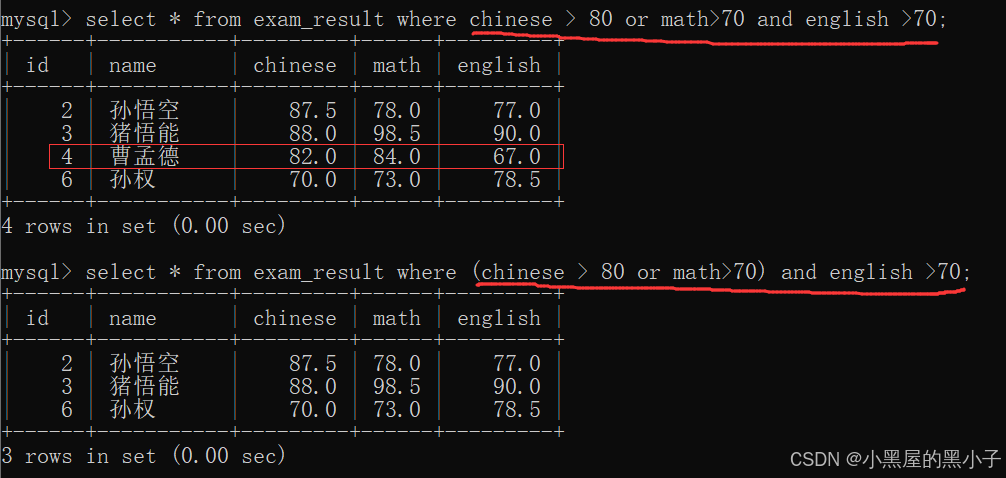
范围查询(between and),(in)
- between...and... 约定的是一个 左闭右闭 区间 (包含两侧边界)
- 大部分区间是采用左闭右开的。例如:String类的有些方法,就是按照区间来指定的 substring 等方法。List类的有些方法也是按照区间subList 等方法
查询语文成绩在 [80, 90] 分的同学及语文成绩:
使用and也能实现,这两种写法本质一样,没啥区别。
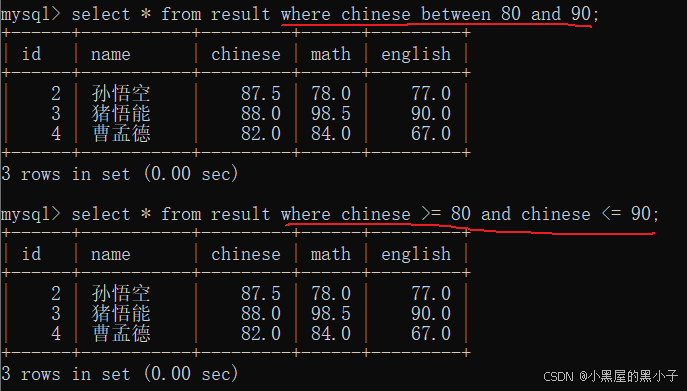
in 使用in来表示一个"离散"的集合
查询数学成绩是 78 或者 98 或者 84 或者 85 分的同学及数学成绩
使用or也能实现,这两种写法本质一样,没啥区别。
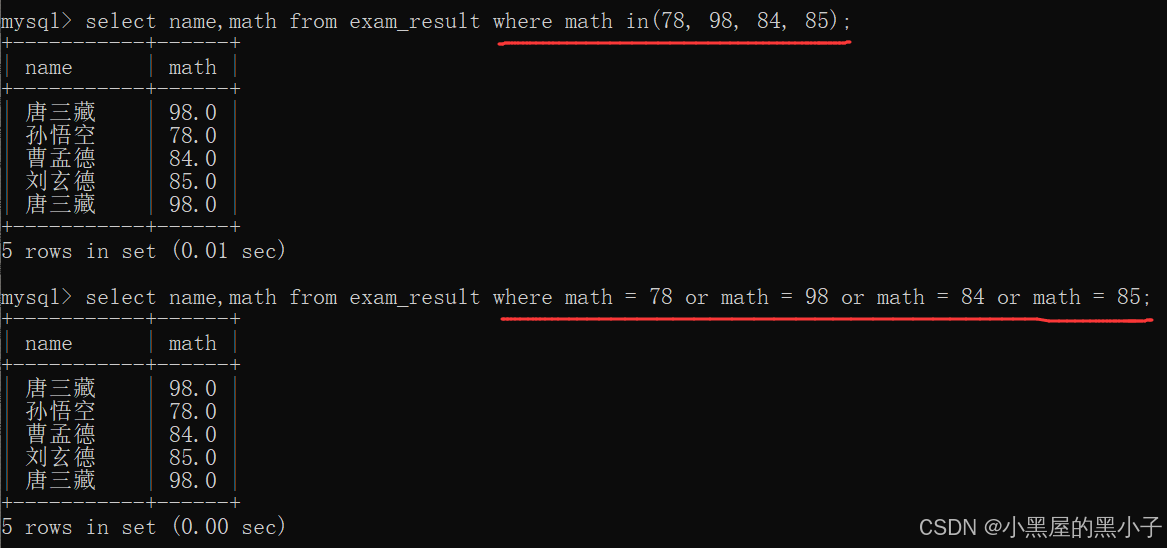
模糊查询 (like)
- like 模糊匹配(模糊匹配字符串),不要求字符串完全相同,只要满足一定的规则就可以了。搭配通配符使用,通配符就是一些特殊的字符,能够表示特定的含义。
- 通配符,类似于扑克中"会儿”或者叫做"赖子"的特殊牌,可以用来代替任意的点数和花色。
- 正则表达式(也是模糊匹配),通过特殊符号来描述一个字符串的特征用这个来匹配字符串。
like功能比 正则表达式简单很多,只支持两个用法:
- 使用 % 代表任意N个字符(包含0个字符)
- 使用 _ 代表任意1个字符
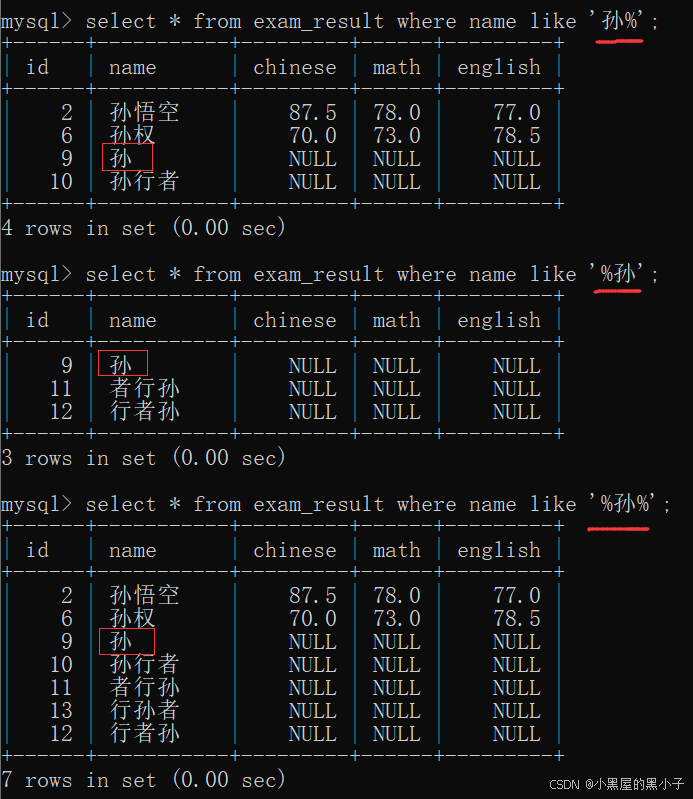
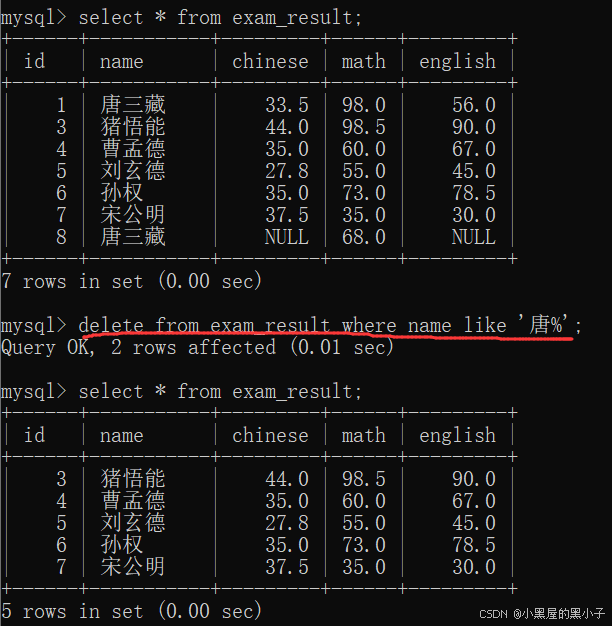
- like '孙%’ 查询孙开头的
- like '%孙’ 查询孙结尾的
- like '%孙%' 查询包含孙的
- 此处模糊查询的功能是有限的,在计算机中,进行模糊匹配字符串还有“正则表达式" 这样的方式来进行实现。
- 这里mysql中不用正则表达式模糊匹配,而是用like模糊匹配,是因为正则表达式,匹配的效率是很慢的,mysql本身也不快,慢上加慢。
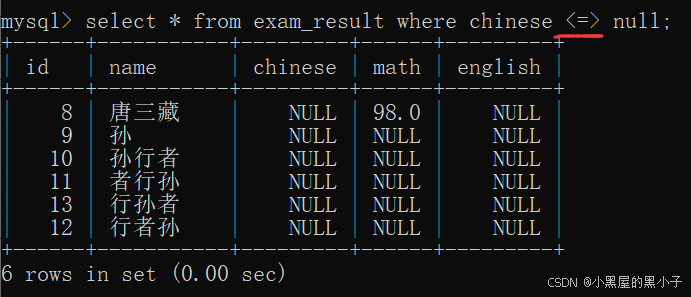
null 的查询 (<=>,is noll)
- null和其他数值进行运算,结果还是null,null结果在条件中,相当于false
- null = null => 结果还是 null => false 所以没有查询结果。
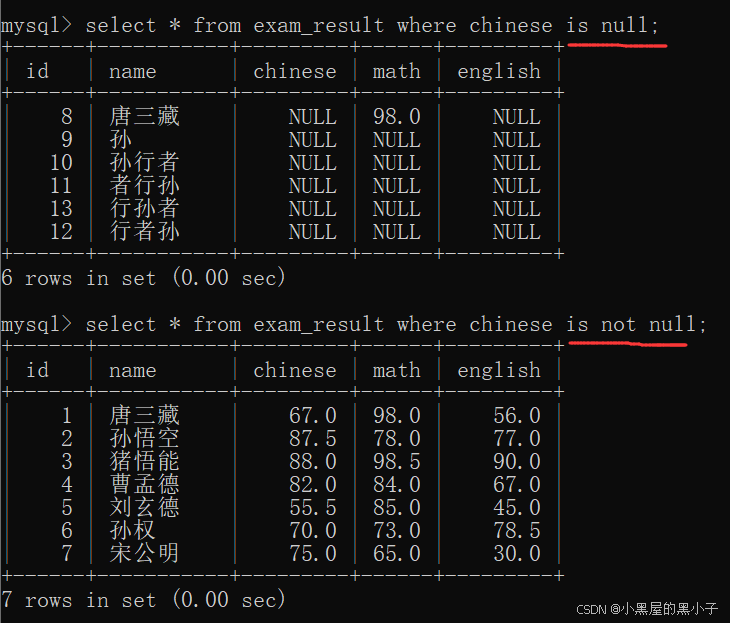
- sql不区分大小写的,NULL/null表示表格里的这一项是空着的。
- <=> 使用这个比较相等运算,就可以处理null的比较。可以针对两个列比较的。
- 还有一种方法 is null ,意思为:是null。只能看到一个列


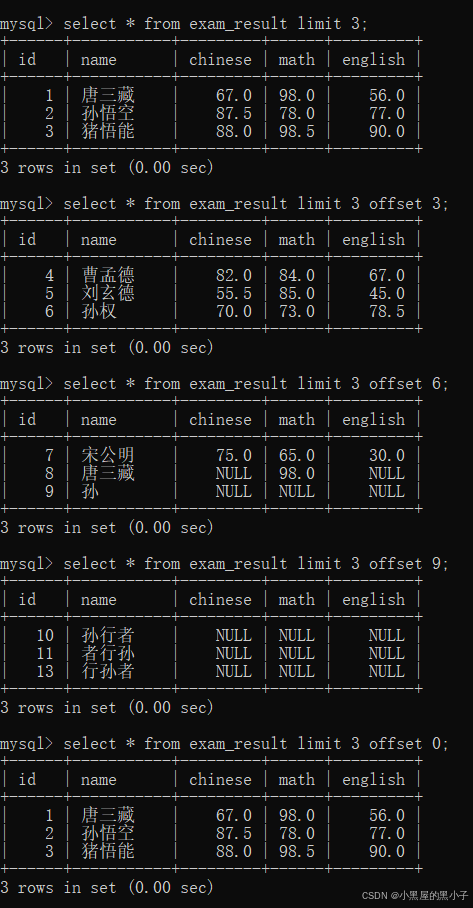
2.8 分页查询 (limit)
使用select *这种方式查询,是比较危险的,需要保证一次查询,不要查出来的东西太多。
有的时候数据非常多,一次全都显示出来,会影响到效率,也会不方便用户去看。
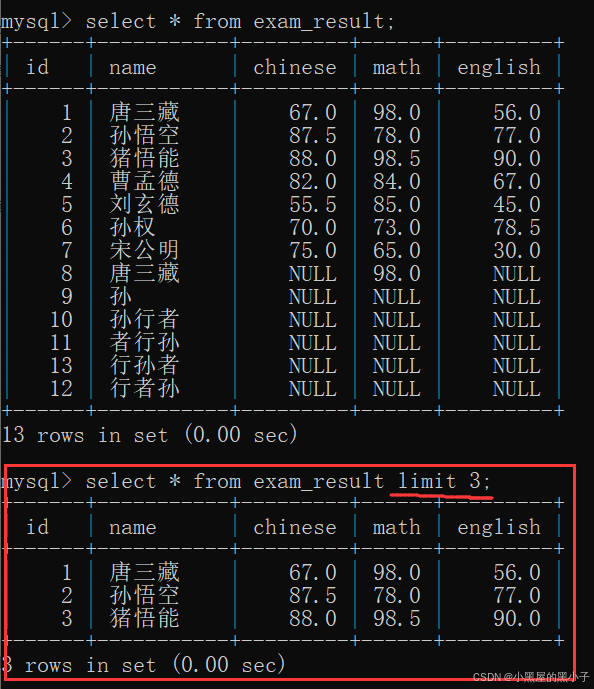
limit 可以限制查询最多能查出来多少个结果。
- limit 可以分别搭配 where 和 order by 使用,
- where 或者 order by 是在 limit子句 前面书写的,一般limit子句是在整个sql语句最后书写的。
- limit还可以搭配 offset,声明从哪一条开始查询(从0开始计数)
- 解读,limit 3 offset 6; 从第6条记录开始,查询3条记录。
- limit 和 offset 是用下标计算的。offset意为偏移量,从0开始
- limit 限制的是最多是多少数据,小于或等于limit不受影响。
limit 3 offset 6; 等价于 limit 6,3;(不太推荐这么写),容易混淆。
- 只查询操作,查询到的结果都是临时表/临时数据,对这些临时表/临时数据进行修改,并不会影响在mysql服务器硬盘上存储的原始数据。例如:列的表达式计算,去重查询,查询结果排序。
- 只要是查询,都不会影响原始数据。
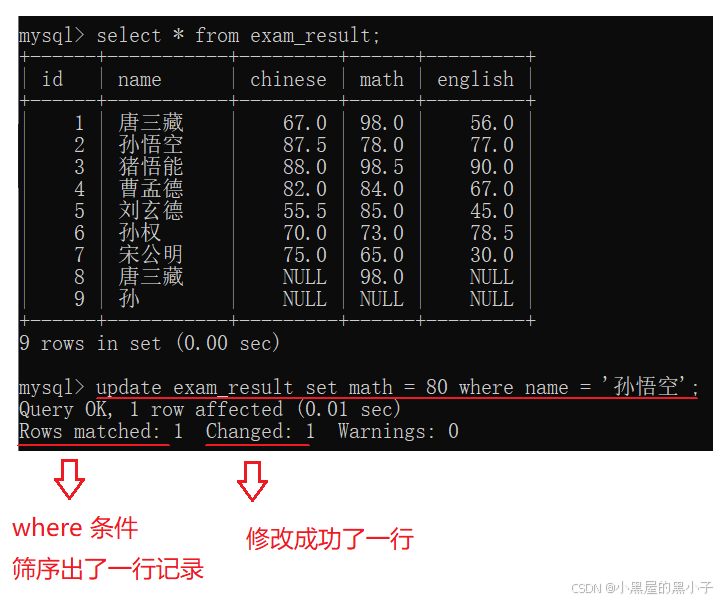
3. 修改(Update)
- where 条件,是限制这次操作具体要修改哪些行的数据。不写任何条件,就是针对所有行进行修改。
- 这里的 = 又相当于赋值了,注意跟 where 条件 中的 = (表示比较相等) 区别。

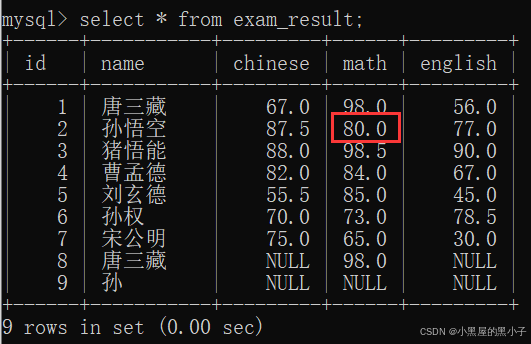
将孙悟空同学的数学成绩变更为 80 分
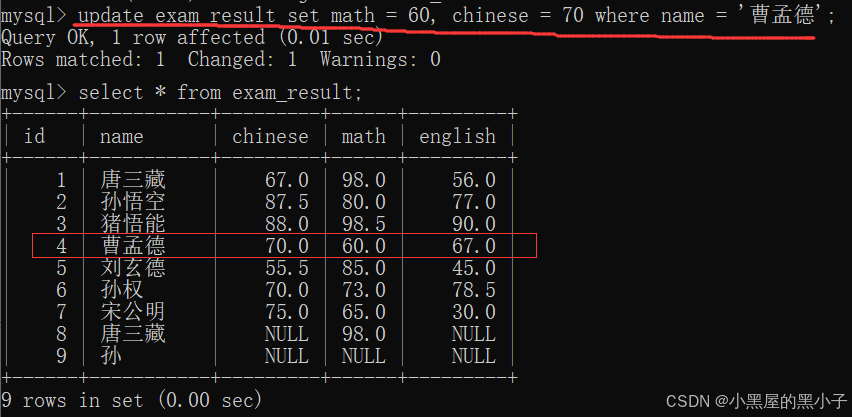
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
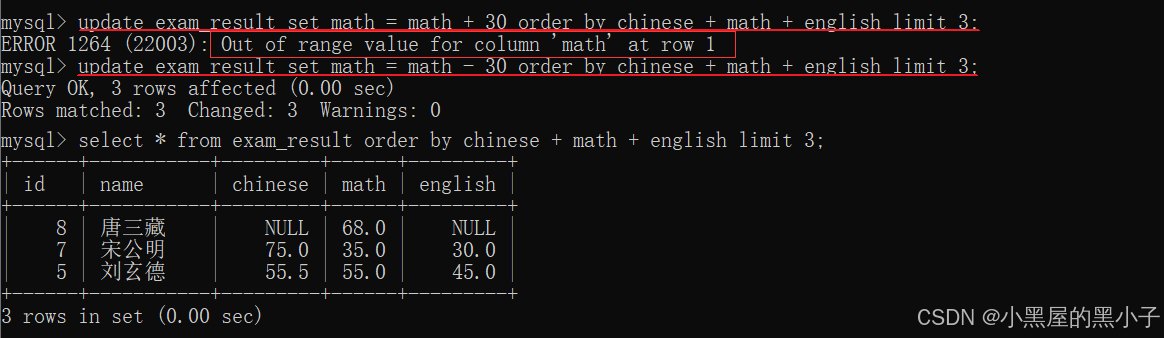
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
总成绩:表达式。 倒数:排序 order by。 前三:limit
- 这里必须写作math = math + 30 不能写作 math += 30 sql中没有 这个种语句。
- 这里‘唐三藏’的数学成绩加30变成128.0,超出了表中该字段类型设置的范围decimal(3,1),失败报错,此时修改不会生效。
将所有同学的语文成绩更新为原来的 2 倍。
同样也是超出了表中该字段类型设置的范围。

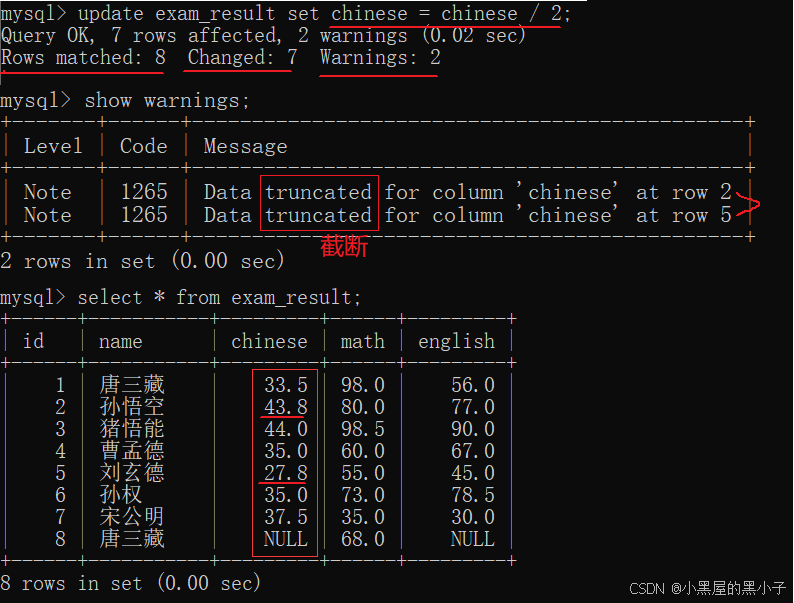
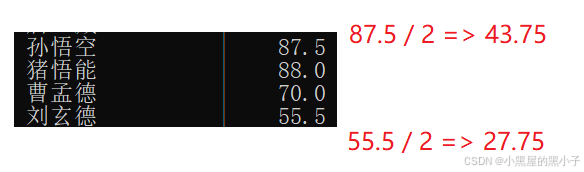
改为将所有同学的语文成绩更新为原来的 0.5 倍。
- 如上如所示:matched:8 所有行数就是8,找到了 8行数据匹配;Changed显示只改变了7行;Warnings警告 2行,意为代码有问题,但是问题不大,还能接受。
- show warnings 查看警告原因:发现发生截断了,小数点后位数不够了,只能发生截断。是发生在第二行和第五行 的 chinese 列,查看修改前的情况,
- 这一列字段的类型的范围是decimal(3,1), 3位有效数字,小数点后保留1位。超出了这个范围,按照四舍五入的方式把数据截断了。
- 只修改了7行原因是:第8行的‘唐三藏’的语文成绩是null,null参与各种运算,结果还是null。相当于没有修改。
修改如果修改后超出范围,会失败报错;如果修改后小数点位过长了,它会截断,会有警告信息。
update操作非常危险
- 撤回不了。
- 测试只能测试个大概,有可能你的bug是一个小概率触发的情况。
4. 删除(Delete)
delete 删除记录,把符合条件的行从表中删除掉。不写任何条件,就是针对所有行进行删除,删除整个表。

删除孙悟空同学考试成绩
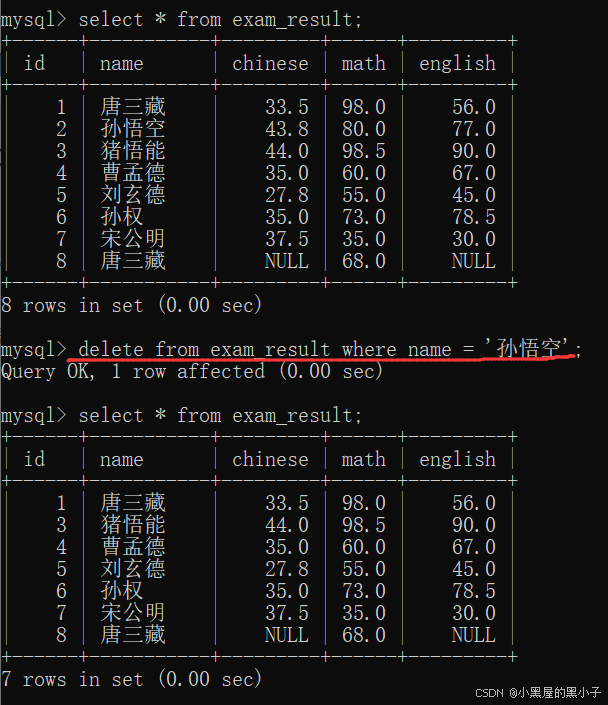
这里就是把条件匹配出来的结果,都删掉了
删除整张表数据。不指定任何条件,就是删除整个表。
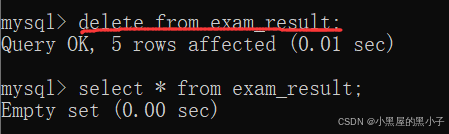
- drop table是删除了表,也删除了表里的记录。
- delete from 只删除了表中的记录,表还在(空表)
truncate也能清空表的内容,和delete from差不多。
delete from 是一条一条删,删的慢。truncate 直接一下就删没了。
删除的时候可以取消,但没有撤销操作。如果执行的sql时间很长,随时可以按ctrl +c取消。
delete和update都是很危险的操作。delete 一旦删除的条件没设置好,就可能把不该删除的给删掉了。
这里的 修改/删除 是持久生效的,都会影响到数据库服务器硬盘中的数据。
总结语句
对表中数据进行操作
新增
- insert into 表名 values (值, 值....); 插入
查询:
- select * from 表名; 查询
- distinct 去重查询
- order by 子句; 查询结果排序
- where 条件查询
- and与or 和与或
- between and 范围条件 in ‘离散’ 集合
- like 模糊匹配
- limit 分页查询
修改
- update 表名 set 列名 = 值, 列名 = 值..... where 条件;
删除
- delete from 表名 where 条件; 删除
好啦Y(^o^)Y,本节内容到此就结束了。下一篇内容一定会火速更新!!!
后续还会持续更新MySQL方面的内容,还请大家多多关注本博主,第一时间获取新鲜的知识。
如果觉得文章不错,别忘了一键三连哟! 





![Warcraft Logs [Classic] [WCL] Usage Wizard <HTOC>](https://i-blog.csdnimg.cn/direct/cc90f124f0d647e3b464e87d68fd7679.png)