提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 语言模型的目标
- 语言模型的数学表示
- 语言模型面临的挑战
- 解决参数量巨大的方法
- 1. 马尔可夫假设
- 2. 神经网络语言模型
- 3.自监督学习
- 4. 分布式表示
- 脑图总结
前言
在自然语言处理(NLP)领域,语言模型(Language Model,LM)是核心组件之一,其目标是建模自然语言的概率分布,从而预测词序列出现的可能性。本文将详细介绍语言模型的目标、数学表示、面临的挑战以及解决方法,并辅以实际例子。
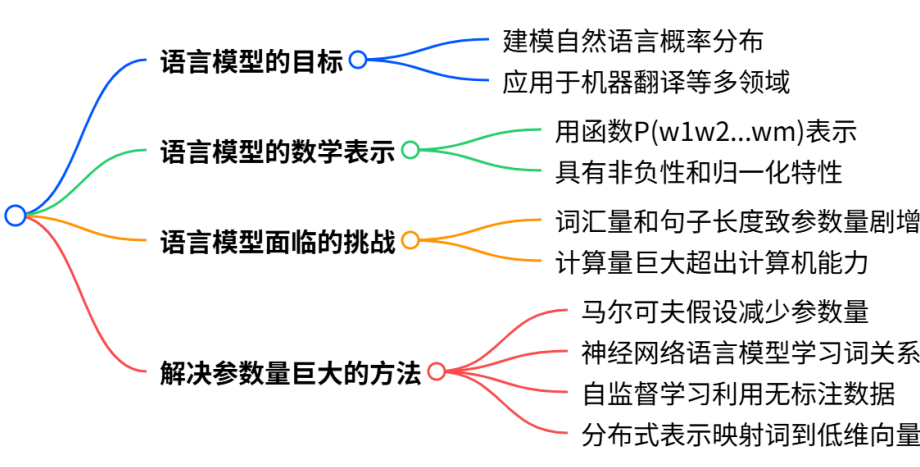
语言模型的目标
语言模型的核心目标是建模自然语言的概率分布,即预测一个词序列(句子)在语言中出现的可能性大小。
原理: 通过统计和学习语言中的规律和模式,语言模型能够估计任意词序列的概率。这种预测能力使得语言模型在机器翻译、语音识别、文本生成等任务中具有广泛应用。
例子:
- 机器翻译:语言模型可以评估翻译结果的流畅性和自然性,从而提高翻译质量。
- 语音识别:语言模型可以根据语音信号识别出的词序列,计算其作为合法句子的概率,从而选择最可能的识别结果。
- 文本生成:语言模型可以根据给定的上下文,生成符合语言规则和语义的文本。
语言模型的数学表示
表示: 在词汇表 V 上的语言模型,通常由函数 P ( w 1 w 2... w m ) P(w_1w2...w_m) P(w1w2...wm) 表示,其中 w 1 w 2 . . . w m w_1w_2...w_m w1w2...wm是一个词序列(句子), P ( w 1 w 2... w m ) P(w_1w2...w_m) P(w1w2...wm) 表示这个词序列作为一个句子出现的概率。
原理:
非负性:对于任意词串
w
1
w
2
.
.
.
w
m
∈
V
+
w_1w_2...w_m∈V^+
w1w2...wm∈V+,都有
P
(
w
1
w
2
.
.
.
w
m
)
≥
0
P(w_1w_2...w_m)≥0
P(w1w2...wm)≥0。这是因为概率值不能为负数。
归一化:对于所有可能的词串,函数
P
(
w
1
w
2
.
.
.
w
m
)
P(w_1w_2...w_m)
P(w1w2...wm)满足归一化条件,即所有可能词串的概率之和为1。
数学上,这可以表示为:
∑
w
1
w
2
.
.
.
w
m
∈
V
+
P
(
w
1
w
2
.
.
.
w
m
)
=
1
\sum\limits_{w_1w_2...w_m∈V^+} P(w_1w_2...w_m)=1
w1w2...wm∈V+∑P(w1w2...wm)=1
例子:
假设词汇表 V={a,b,c},句子长度 m=2。那么所有可能的词序列有
3
2
=
9
3^2=9
32=9
种,如
a
a
,
a
b
,
a
c
,
b
a
,
b
b
,
b
c
,
c
a
,
c
b
,
c
c
aa,ab,ac,ba,bb,bc,ca,cb,cc
aa,ab,ac,ba,bb,bc,ca,cb,cc。语言模型需要为这9种词序列分配概率,使得它们的概率之和为1。
语言模型面临的挑战
挑战:由于词汇量和句子长度的增加,语言模型的参数量会呈指数级增长,导致计算上的巨大挑战。
造成问题的原因:
考虑一个包含
∣
V
∣
| V∣
∣V∣个词的词汇表,句子长度为 m。那么,词序
w
1
w
2
.
.
.
w
m
w_1w_2...w_m
w1w2...wm有
∣
V
∣
m
∣V∣^m
∣V∣m种可能。对于每一种可能,语言模型都需要计算其概率
P
(
w
1
w
2
.
.
.
w
m
)
P(w_1w_2...w_m)
P(w1w2...wm)。
以《现代汉语词典(第七版)》为例,它包含了7万词条,即
∣
V
∣
=
70000
∣V∣=70000
∣V∣=70000。假设句子长度为20个词,那么词序列的可能数量达到:
∣
V
∣
m
=
7000
0
20
≈
7.9792
×
1
0
96
∣V∣^m=70000^{20} ≈7.9792×10^{96}
∣V∣m=7000020≈7.9792×1096
这是一个天文数字,远远超出了当前计算机的计算能力。直接计算如此巨大的参数量是不现实的。
解决参数量巨大的方法
为了克服参数量巨大的挑战,研究人员提出了多种方法:
1. 马尔可夫假设
原理:
引入马尔可夫假设,即假设当前词的概率只依赖于前
n
−
1
n−1
n−1个词,从而将参数量从
∣
V
∣
m
∣V∣^m
∣V∣m减少到
∣
V
∣
n
∣V∣^n
∣V∣n,其中
n
<
<
m
n<<m
n<<m。
例子:
二元语法(Bigram):假设当前词的概率只依赖于前一个词。例如,计算词序列
w
1
w
2
w
3
w_1w_2w_3
w1w2w3的概率可以分解为:
P
(
w
1
w
2
w
3
)
=
P
(
w
1
)
P
(
w
2
∣
w
1
)
P
(
w
3
∣
w
2
)
P(w_1w_2w_3)=P(w_1)P(w_2∣w_1)P(w_3∣w_2)
P(w1w2w3)=P(w1)P(w2∣w1)P(w3∣w2)
三元语法(Trigram):假设当前词的概率依赖于前两个词。例如,计算词序列
w
1
w
2
w
3
w
4
w_1w_2w_3w_4
w1w2w3w4的概率可以分解为:
P
(
w
1
w
2
w
3
w
4
)
=
P
(
w
1
)
P
(
w
2
∣
w
1
)
P
(
w
3
∣
w
1
w
2
)
P
(
w
4
∣
w
2
w
3
)
P(w_1w_2w_3w_4)=P(w_1)P(w_2∣w_1)P(w_3∣w_1w_2)P(w_4∣w_2w_3)
P(w1w2w3w4)=P(w1)P(w2∣w1)P(w3∣w1w2)P(w4∣w2w3)
2. 神经网络语言模型
原理:使用深度神经网络(如循环神经网络RNN、长短期记忆网络LSTM、Transformer等)来建模语言模型。这些模型通过训练来学习词之间的复杂关系,从而能够在保证一定性能的同时,减少参数量。
例子:
- RNN语言模型:利用循环神经网络处理序列数据,通过隐藏状态传递上下文信息。 Transformer语言模型:如GPT(Generative Pre-trained Transformer)系列模型,利用自注意力机制捕捉长距离依赖关系,实现高效的语言建模。
3.自监督学习
利用大规模无标注文本数据进行自监督学习,使模型能够自动学习语言的规律和模式。这种方法不需要人工标注数据,大大降低了数据获取的成本,同时也有助于提高模型的泛化能力。
例子:
- BERT(Bidirectional Encoder Representations from Transformers):通过掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)任务进行自监督学习,获得强大的语言表示能力。
- GPT-3(Generative Pre-trained Transformer 3):在海量互联网文本数据上进行自监督学习,展现出强大的语言理解和生成能力。
4. 分布式表示
原理:
使用词嵌入(Word Embedding)技术,将每个词映射到一个低维向量空间中的向量。这种分布式表示方法能够捕捉词之间的语义和语法关系,有助于减少参数量并提高模型的性能。
例子:
- Word2Vec:通过神经网络训练词向量,使得语义相近的词在向量空间中距离较近。 GloVe(Global Vectors for
- Word Representation):利用全局矩阵分解和局部上下文窗口的优点,训练高质量的词向量。
脑图总结