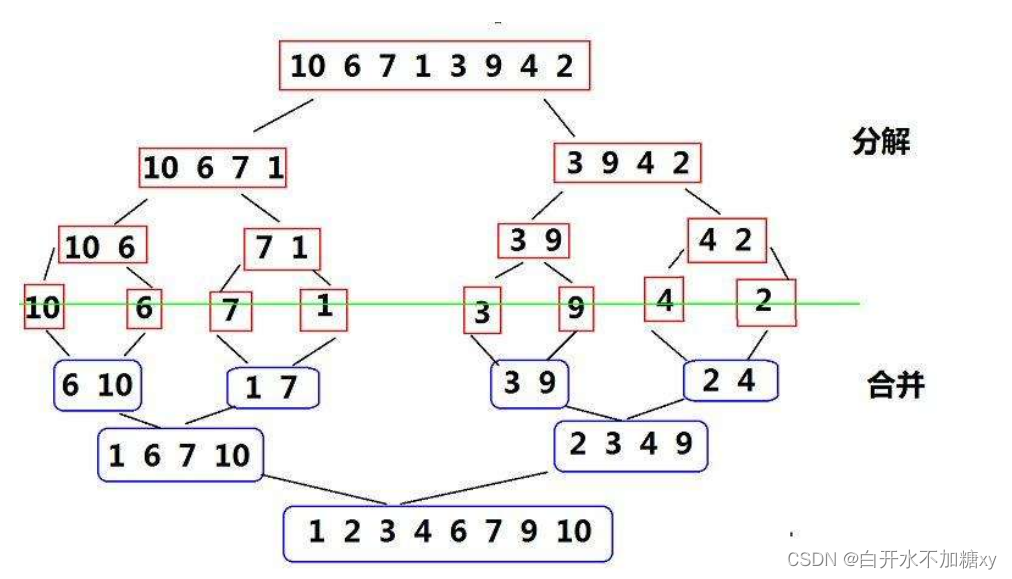
目录
一、机器视觉算法
二、yolov1 预测阶段(向前推断)
三、预测阶段的后处理
(声明:本文章是在学习他人视频的学习笔记,图片出处均来自该up主,侵权删 视频链接:为什么要学YOLOV1_哔哩哔哩_bilibili)
一、机器视觉算法
yolo是解决目标检测问题的计算机视觉算法
计算机视觉能够解决很多问题 如图像分类 目标检测 图像分割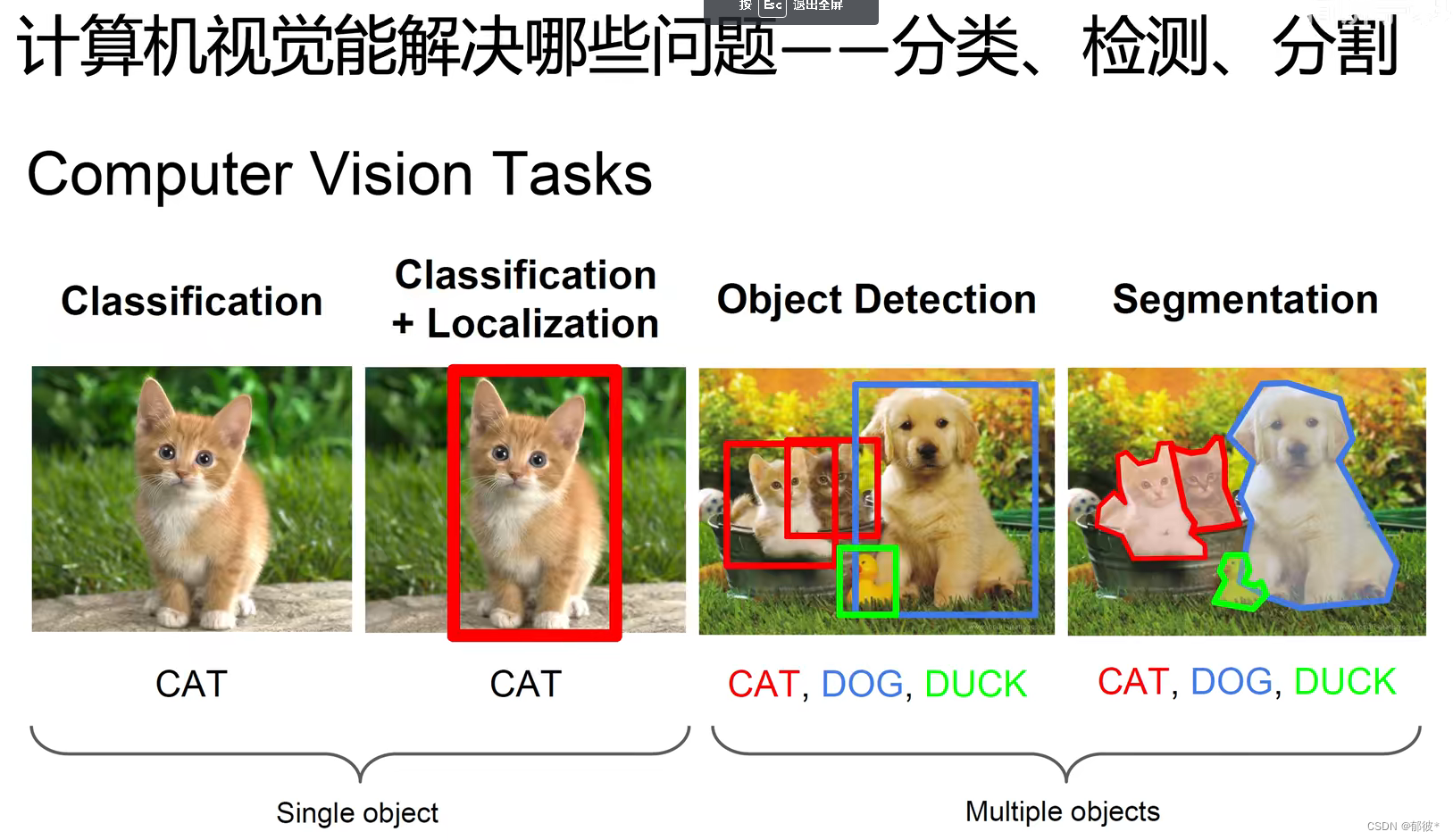
分类:输入图像,输出图像中不同类别图像的类别
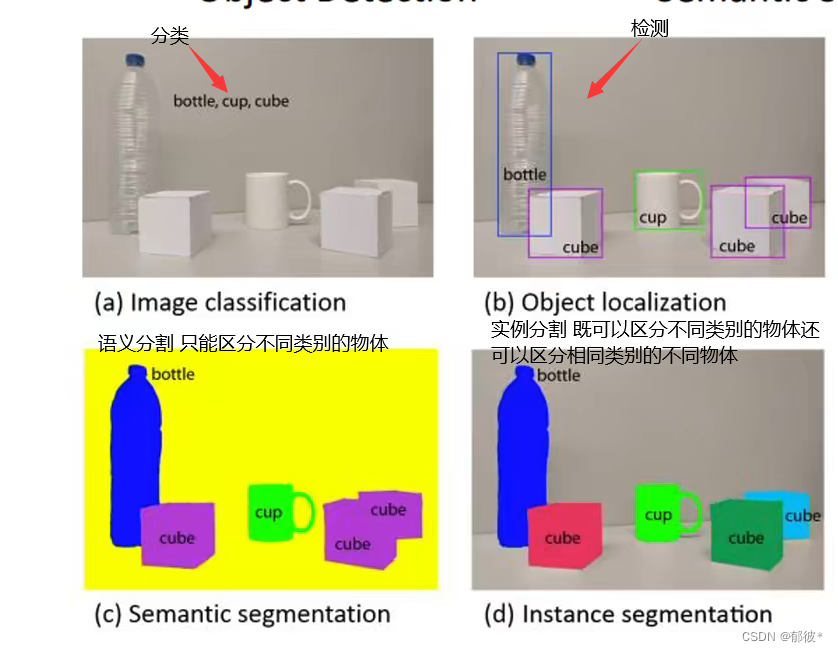
检测:将不同类别的图像框选出来 并检测其类别
分割: 将不同类别的图像通过抠图的形式 区分开来
分割也分为两种:1、语义分割(Semantic Segmentation) 2、实例分割(Instance Segmentation)

除了以上这些 计算机视觉还可以进行关键点检测 例如将人体的骨架的关键点识别出来或将人脸部的关键点识别出来(眼睛、鼻子、嘴巴...)
而目标检测是计算机视觉里一个非常重要的部分 yolo算法就是解决这个问题的
二、yolov1 预测阶段(向前推断)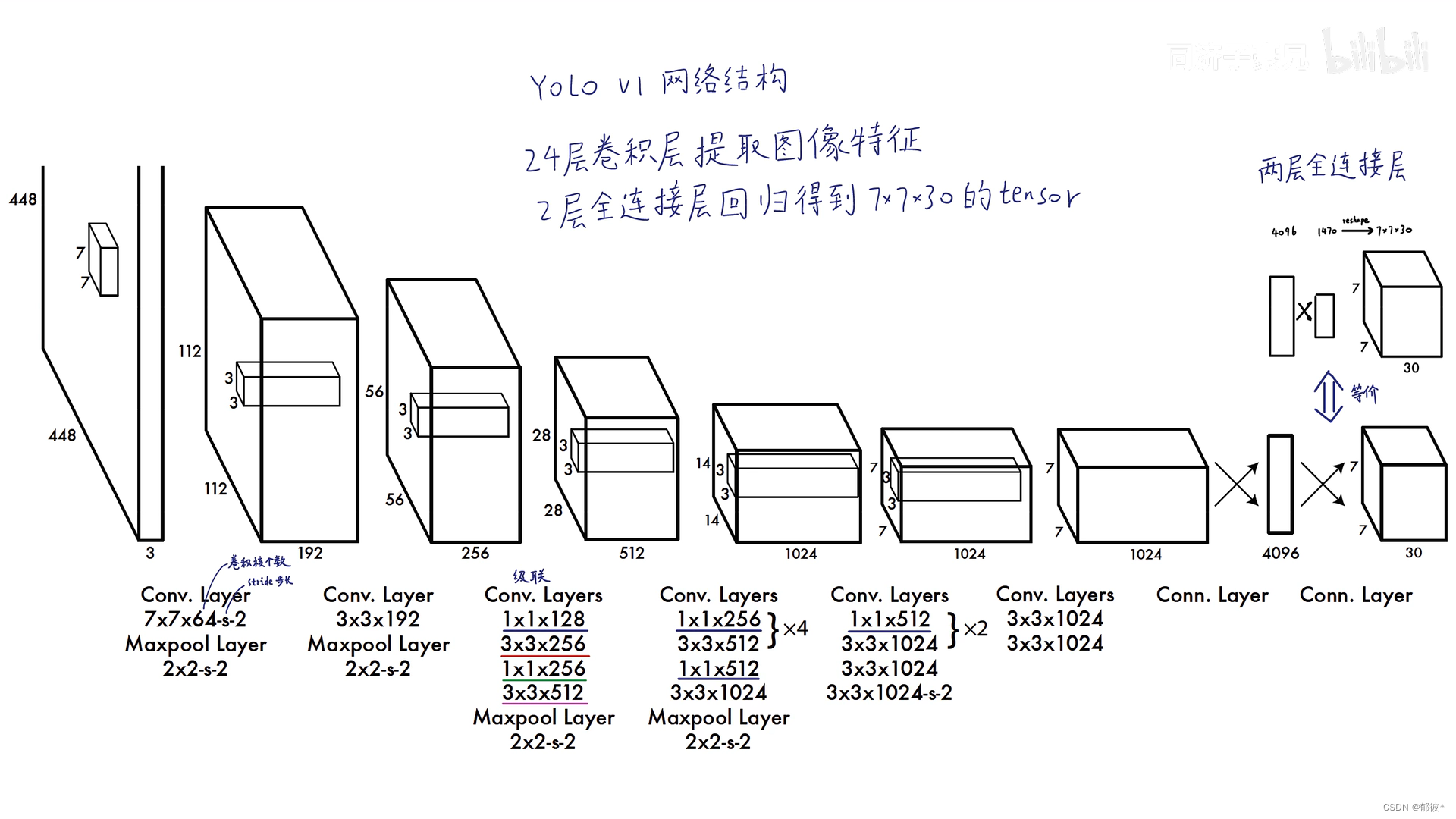
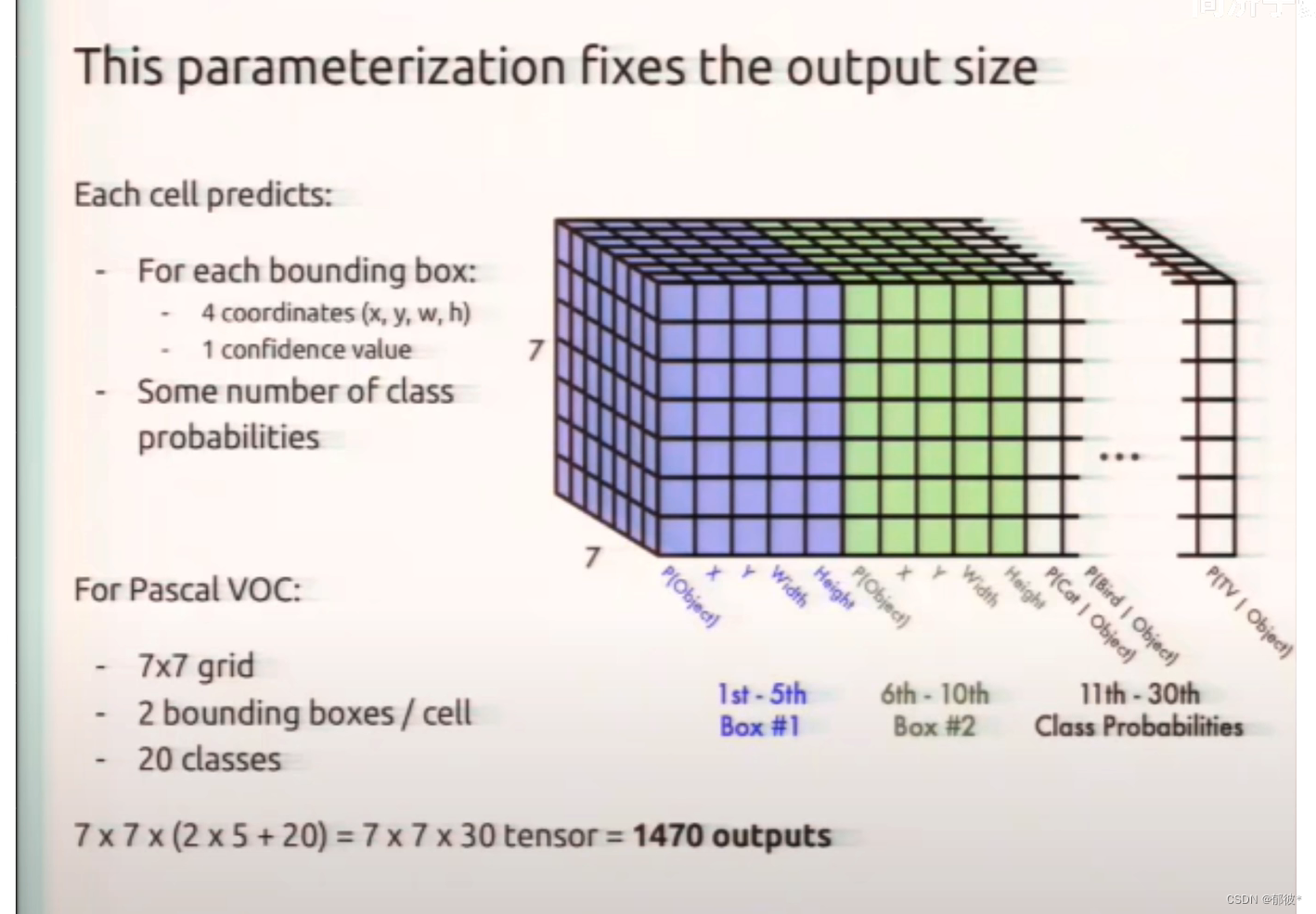
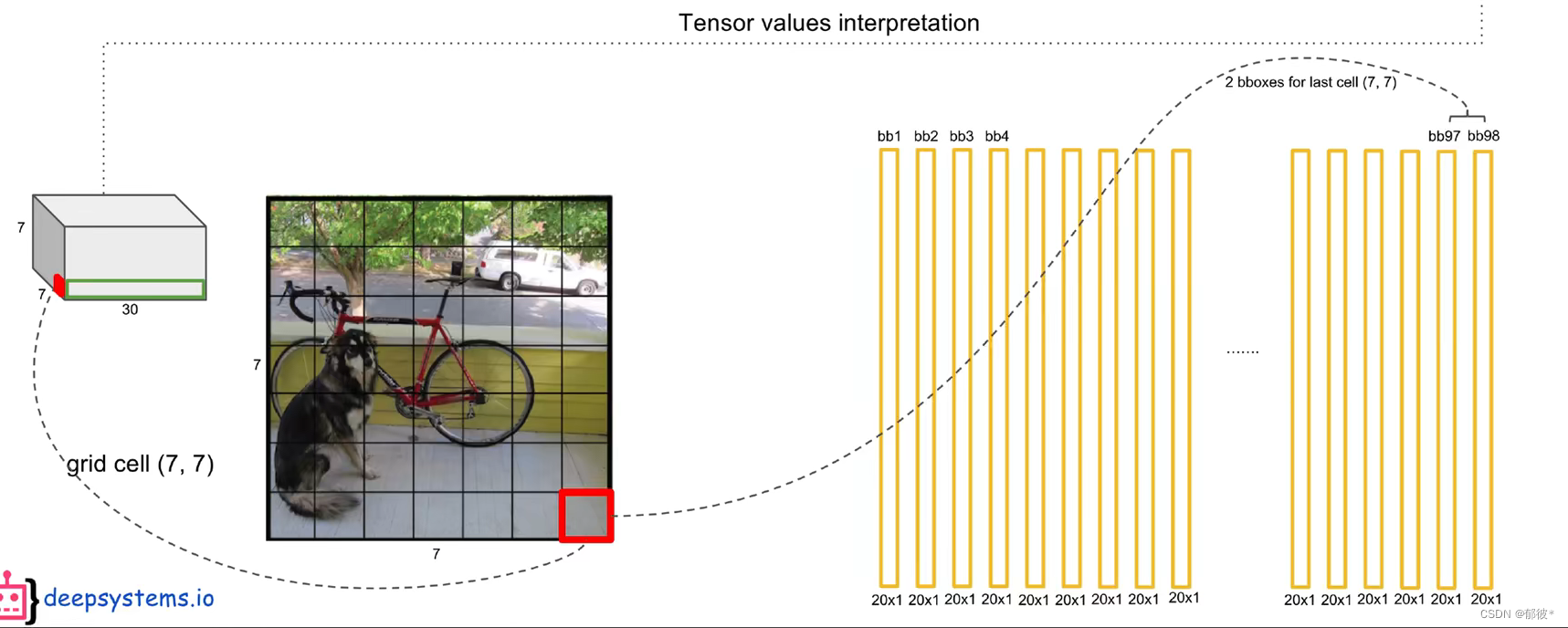
输入的是448×448分辨率的彩色图片 ,通过一系列的卷积层最后得到了一个30维的7×7的矩阵
为什么最后输出的是7x7x30呢
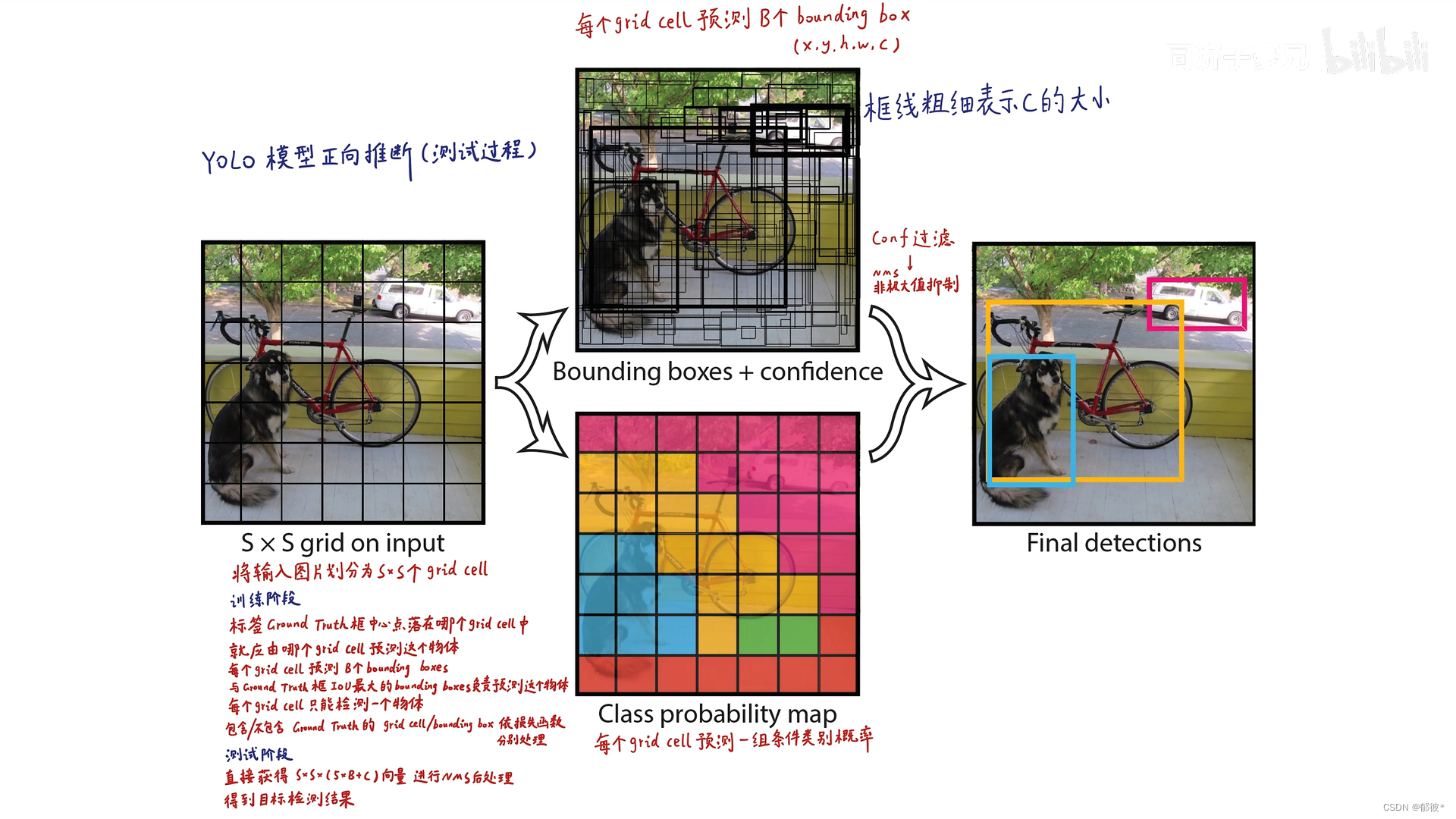
在模型已经训练好的情况下 输入一个图像 yolo会将图像划分成7×7的网格(grid cell)

每一个grid cell还会分成 两个bounding box

每个bounding box会生成一些信息,如中心点的x、y矩形框的h、w还有这个框的自信度,而grid cell也会生成一些信息,即假设该grid cell是不同物体的概率,是鸟的概率P(bird|Object)、是车的概率P(car|Object)等20个,自信度与不同的概率相乘,最高的那个就是yolo所推测出的物体类别。

好了,知道这些我们就可以进一步知道为什么预测阶段最后输出的是7x7x30,
7×7对应的是7×7个grid cell,而30对应的是一个grid cell中两个bounding box对应的x、y、w、h、c
各5个,加起来一共10个 grid cell的类别概率(class probability)有20个类别概率,这样就构成了7×7×30的tensor
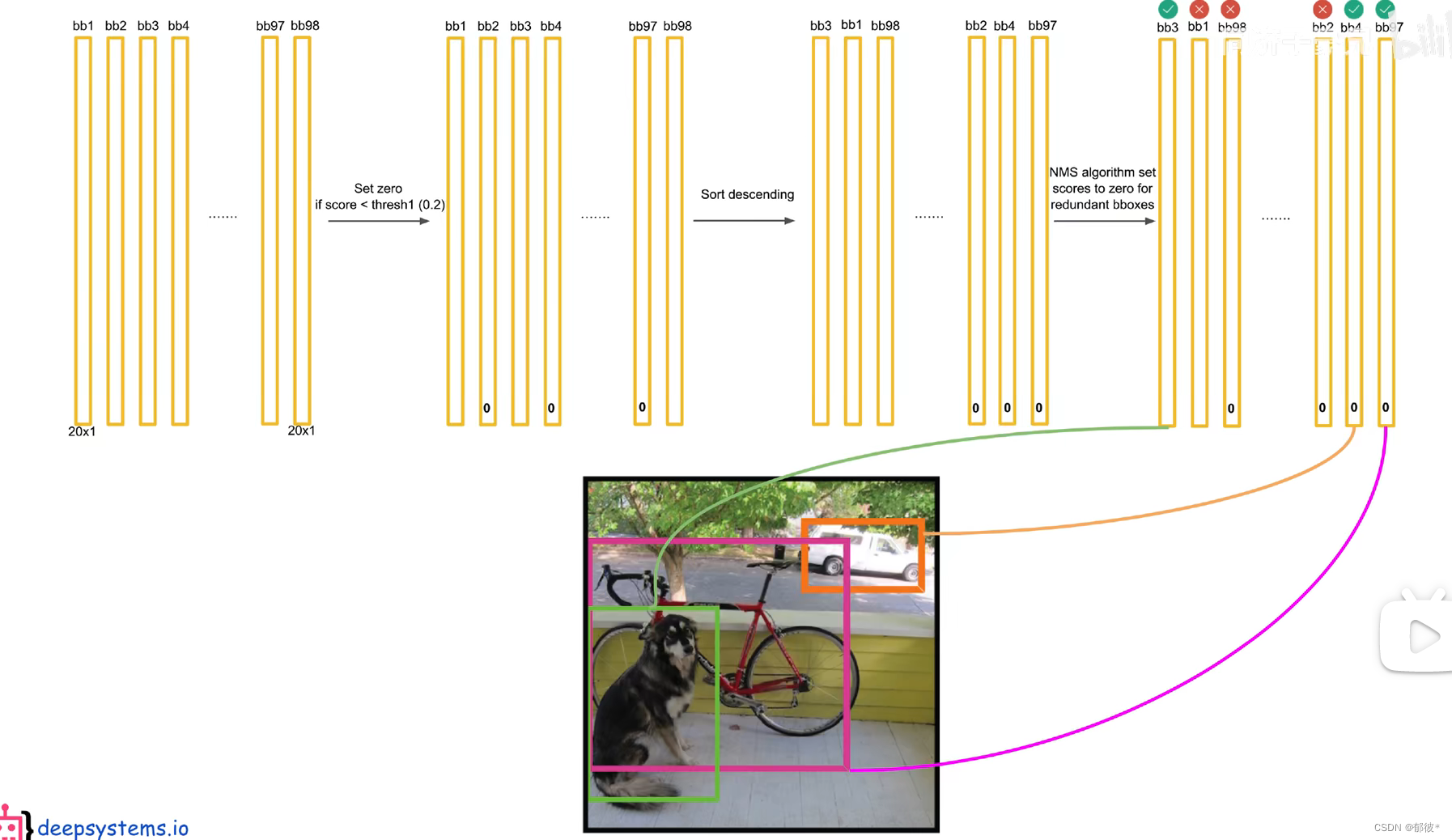
三、预测阶段的后处理
NMS非极大值抑制
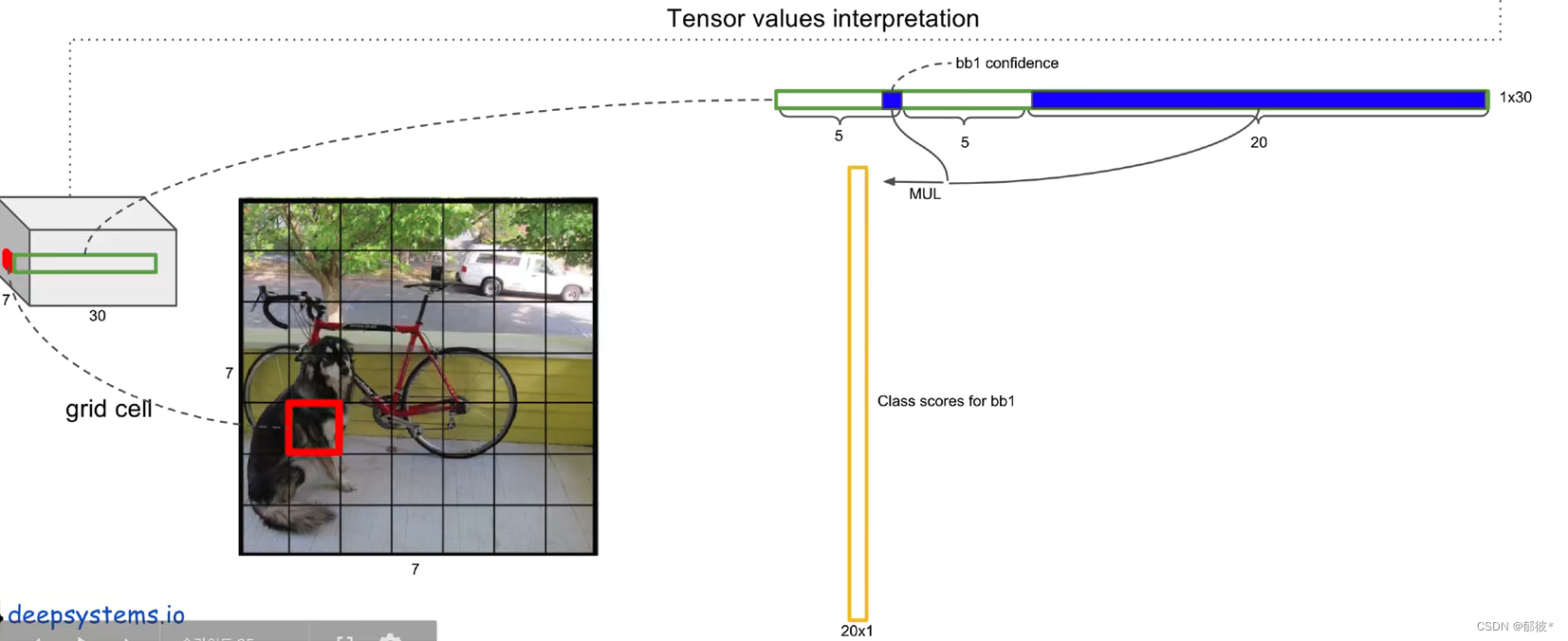
将第一个bounding box的确信值与20个类别条件概率相乘,就可以得到第一个bounding box类别全概率
将第二个bounding box的确信值与20个类别条件概率相乘,就可以得到第二个bounding box类别全概率
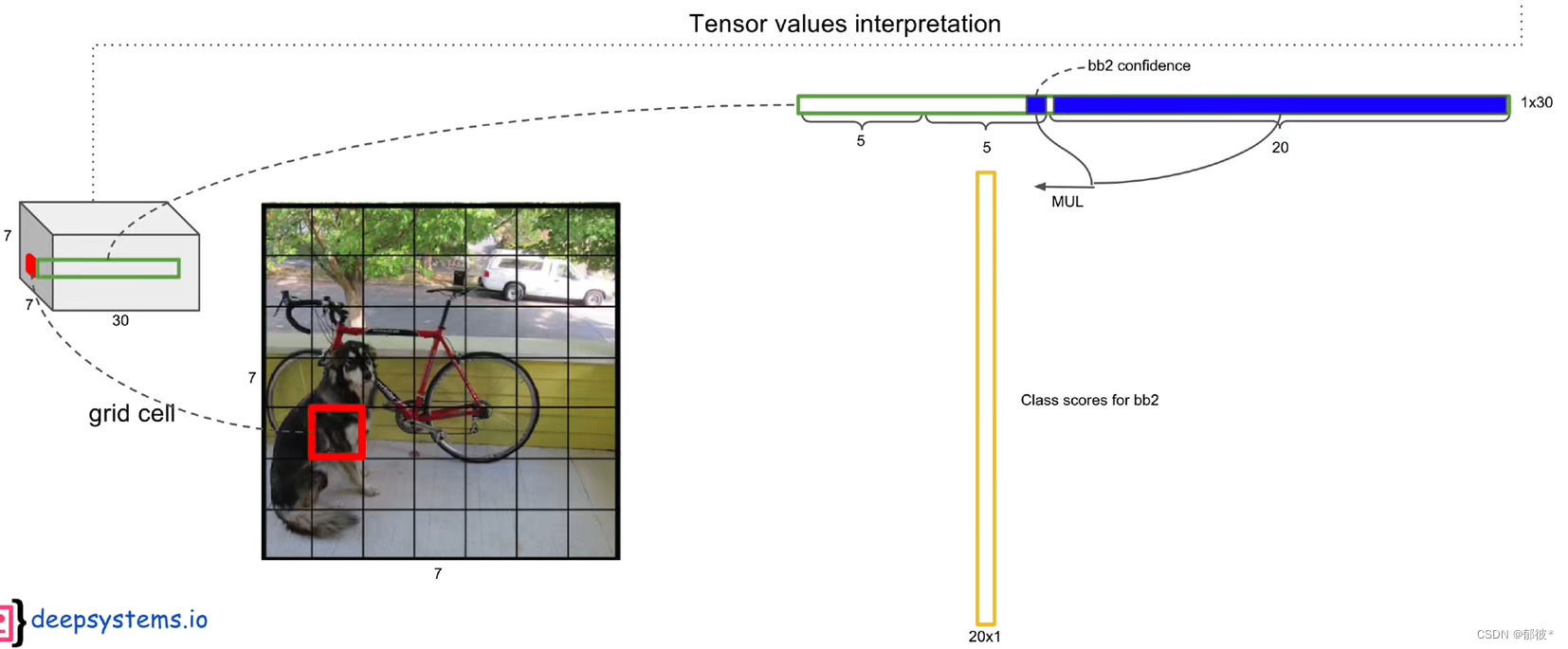
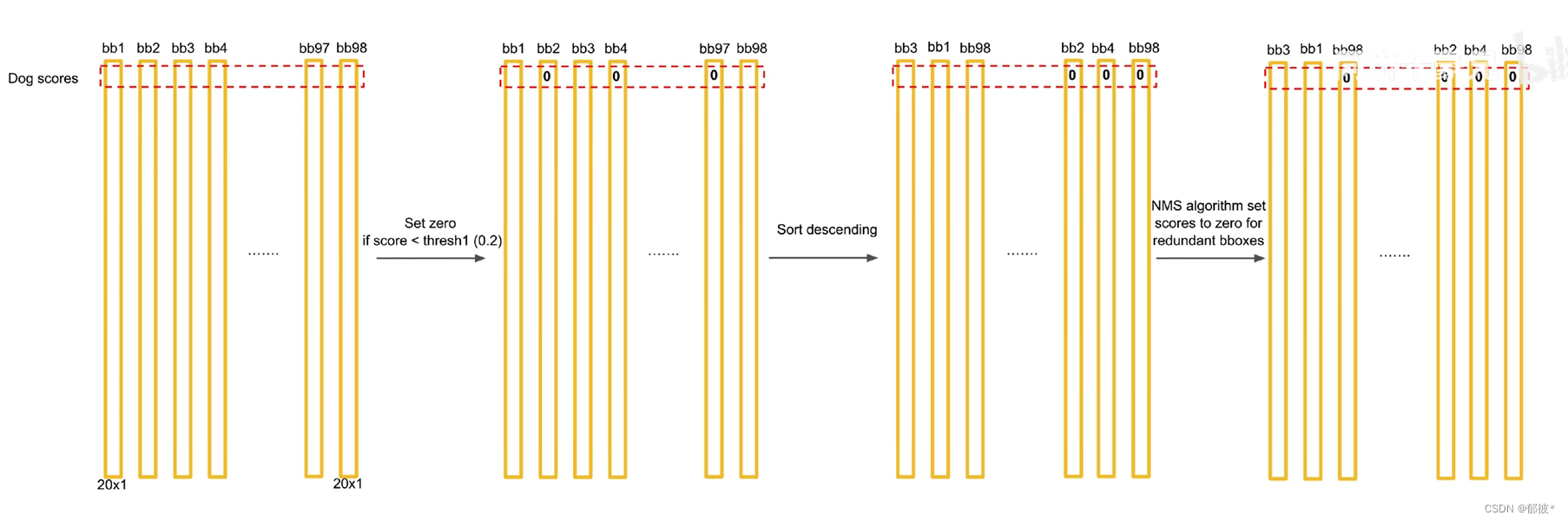
49个grid cell有98个bounding box,就有98个 bounding box类别全概率
 将98个全概率框选出来如下图,不同的颜色代表不同的种类,线条越粗代表概率越大
将98个全概率框选出来如下图,不同的颜色代表不同的种类,线条越粗代表概率越大

再经过处理后就变成了这个样子

处理的具体过程,先将低于0.2的概率全部置为零,再将概率从高到低排列,最后再进行NMS处理就得到了最后的结果
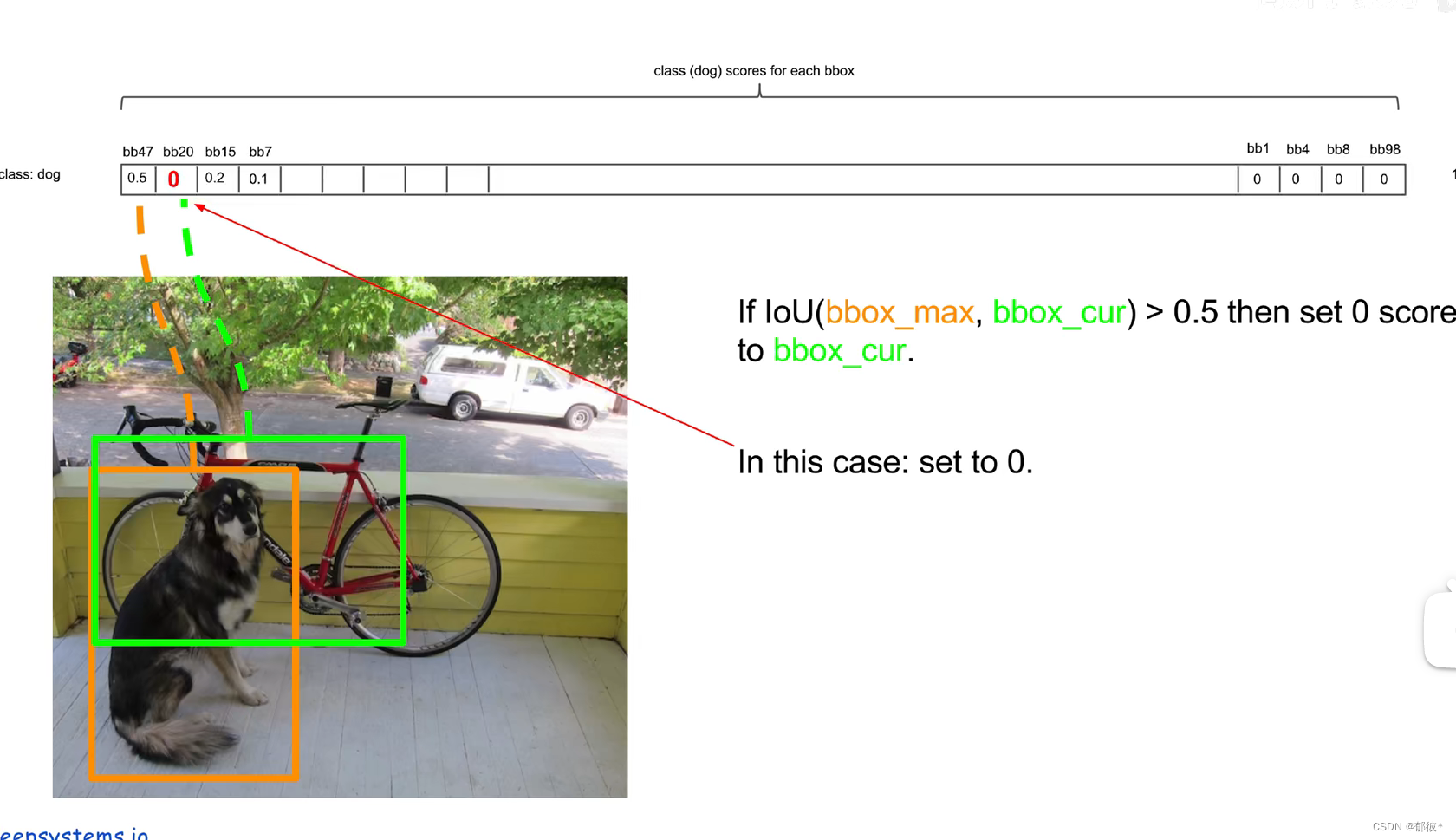
那么NMS的实际又是怎么操作的呢
如图,首先将概率最高的(橙框)与所有比它低的依次进行IOU运算,若IOU的值大于设定的阈值,则将该概率置为0

 比较完概率最高的后,再从概率第二高(蓝框)的与所有比它小的比较,若IOU大于阈值则小概率的(紫框)置为0,依次类推
比较完概率最高的后,再从概率第二高(蓝框)的与所有比它小的比较,若IOU大于阈值则小概率的(紫框)置为0,依次类推
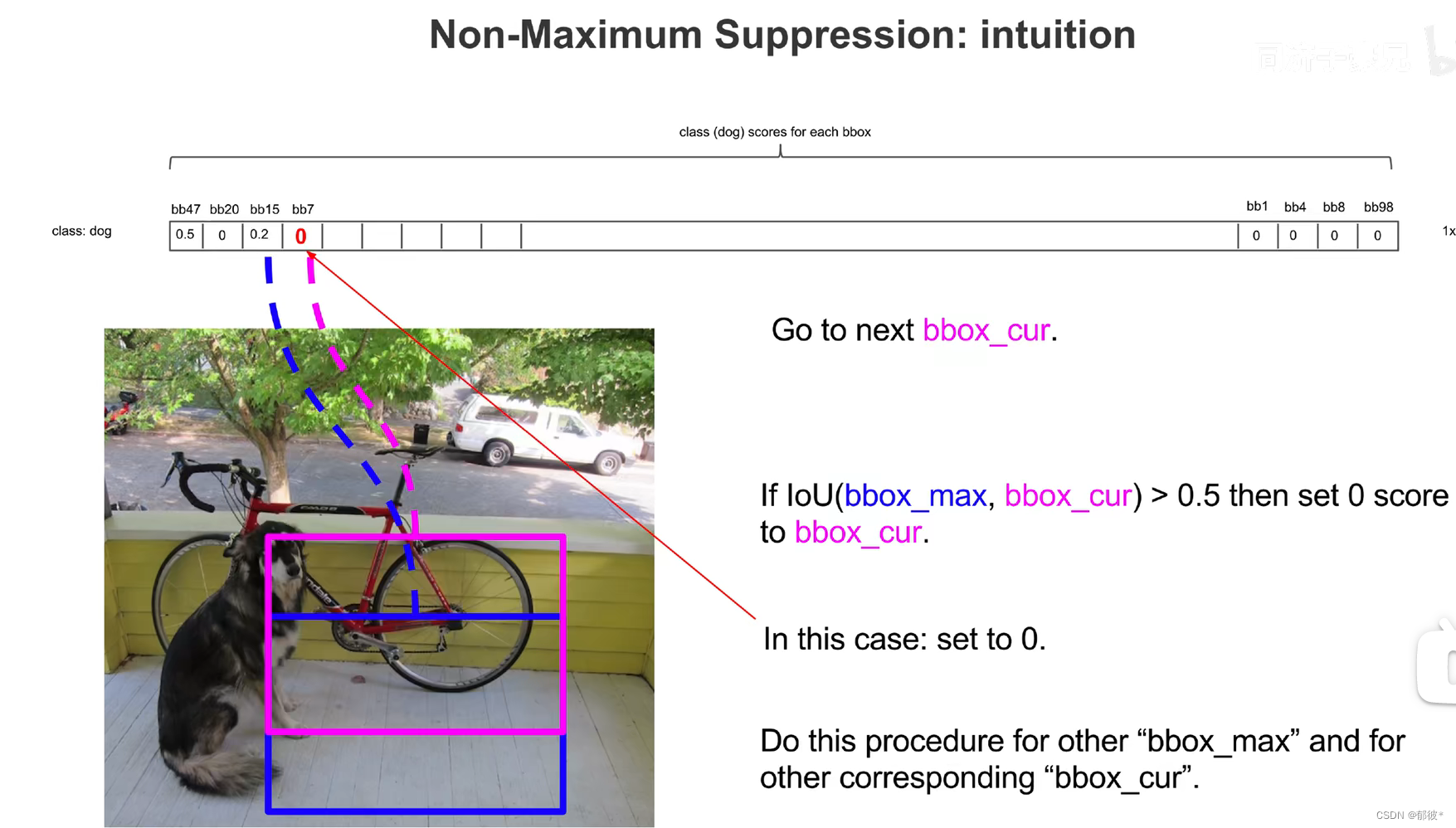
最后将概率不为0的类别和它的概率读出,并框在图像上





![[附源码]java毕业设计校园共享单车系统](https://img-blog.csdnimg.cn/619f8aedbe5a404fa73cf6f37bb50e6b.png)