字节推荐算法
一、实习项目:多任务模型中的每个任务都是做什么?怎么确定每个loss的权重
这个根据实际情况来吧。如果实习时候用了moe,就可能被问到。
loss权重的话,直接根据任务的重要性吧。。。
二、特征重要性怎么判断的?
2.1. 基于树模型的方法(Model-based Methods)
在使用树模型(如 XGBoost、LightGBM、CatBoost)时,通常有多种方式可以计算 feature_importance_
2.1.1. Gain(信息增益)
- 定义:每个特征在树结构中带来的信息增益(或损失函数的减少量)之和。
- 特点:反映了特征对模型性能提升的“贡献度”。
- 优点:精度较高,考虑了每次分裂的效果。
- 劣势:容易偏向使用频率较低但效果突出的特征。
2.1.2. Split(或 Weight / Frequency)
- 定义:每个特征被用作分裂点的次数。
- 特点:反映了特征在树中“被使用的频率”。
- 优点:实现简单,速度快。
- 劣势:不考虑每次使用带来的好处(信息增益大小),可能高估某些无效但频繁使用的特征。
2.1.2. Cover(覆盖度)
- 定义:使用该特征进行分裂的样本权重的总和(即覆盖的样本量)。
- 特点:用于衡量特征使用时影响的样本规模。
- 优点:结合了使用频率和样本量。
- 劣势:对结果的解释性不如 Gain 明确。
2.2. 基于模型不确定性的分析
2.2.1. SHAP (SHapley Additive exPlanations)
- 利用博弈论中 Shapley Value 分析每个特征对模型输出的贡献,支持大多数模型(树模型、神经网络、线性模型)
2.2.2. LIME (Local Interpretable Model-agnostic Explanations)
- 基于局部线性模型的解释方法,对每个预测样本提供局部特征重要性
2.3. Permutation Importance(置换重要性)
- 打乱某一特征,看模型性能下降多少(需要做很多次,求平均)
2.4. 消融实验
- 删除某一特征,观察模型性能的下降程度
2.5. 基于回归模型系数的方法
- 逻辑回归、线性回归中的系数大小表示特征重要性。简单讲就是y = wx+b的w。
三、谈谈推荐模型中的SENet(Squeeze-and-Excitation Networks)
SENet本身并不直接进行特征选择(即不删除不重要的特征),而是通过重新标定特征的重要性来间接影响模型的学习过程。但是其实我们可以将SENet的的门控参数当作特征重要度用。
SENet的通道注意力思想被引入到多特征交互建模中,动态地学习不同特征的重要性。
3.1. SENet 结构模块
3.1.1. Squeeze(压缩)
对每个通道(对应推荐系统中的每个嵌入向量)做全局平均池化,提取通道级的全局信息。
- 输入维度:
(batch_size, num_fields, embedding_dim) - 输出维度:
(batch_size, embedding_dim)
3.1.2. Excitation(激励)
通过一个两层的全连接网络(MLP)建模特征之间的关系,输出每个特征维度的权重。
- 通常包含 ReLU 激活 + Sigmoid
- 可视为一个门控机制,学习特征维度的重要性
3.1.3. Scale(缩放)
将激励模块生成的权重乘回原始特征,实现特征重标定。
3.2. 在推荐模型中的应用
SENet是一个很方便的模块,即插即用。推荐系统中的输入通常是多个类别特征的 embedding(嵌入向量),SENet 可以作用于这些向量,对不同特征分配动态的权重。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SEBlock(nn.Module):
def __init__(self, num_channels, reduction_ratio=4):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool1d(1) # 对于1D特征(如嵌入向量)
self.fc = nn.Sequential(
nn.Linear(num_channels, num_channels // reduction_ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(num_channels // reduction_ratio, num_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x_input):
b, f, size = x_input.size()
y = self.avg_pool(x_input).view(b, f)
gate = self.fc(y).view(b, f, 1)
return x_input * gate
四、特征共线性无法计算重要度怎么处理?
特征共线性 指的是多个特征之间存在高度相关性,
- 这种冗余关系会使得模型在估计每个特征贡献时,共线特征会分摊重要性,使它们看起来都不重要。
- 但特征共线性问题其实只是对 线性模型(如线性回归、逻辑回归)会产生影响。
4.1. 降低共线性
- 删除冗余特征
- 主成分分析(PCA):通过 PCA 将共线特征压缩成无关主成分,再做重要性分析
- 加入正则化
4.2. 选择对特征共线性不敏感的树模型或者其他的特征重要性检测方法
五、负样本不均衡怎么处理?负采样后怎么保证预估值正常?
在推荐系统中正负样本极度不均衡 是常见问题:
- 正样本(如点击、购买)远少于负样本(未点击、未购买)不处理会导致模型偏向负类,召回率低;但直接负采样可能影响模型输出概率的解释性
5.1. 如何保证负采样后的预估值正常?
方法一:调整 loss 中的 sample weight
- 给每个样本赋予一个权重,权重反映它在真实分布中的代表性
# 例如真实负样本比例为 99%,采样比例为 10%
# 则负样本需要乘以一个调整系数 alpha ≈ 99 / 10
sample_weight = np.where(y == 1, 1.0, alpha)
model.fit(X, y, sample_weight=sample_weight)
方法二:手动调整输出概率
p = p̂ * r / [ p̂ * r + (1 - p̂) * (1 - r') / (1 - r) ]
- p̂:采样后训练输出的概率
- r:采样前的正负样本比
- r’:正负样本比
- P⁺:真实正样本概率
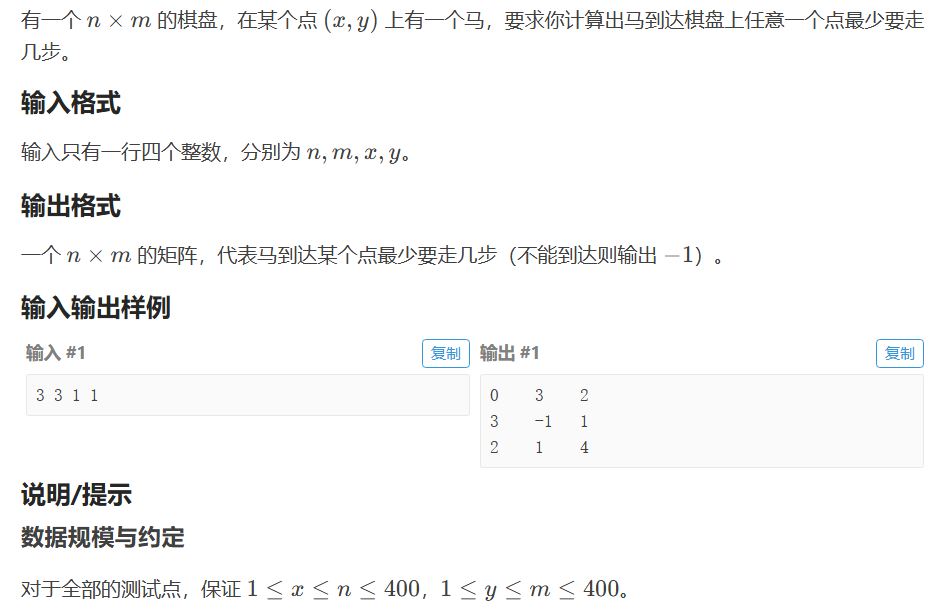
六、199. 二叉树的右视图
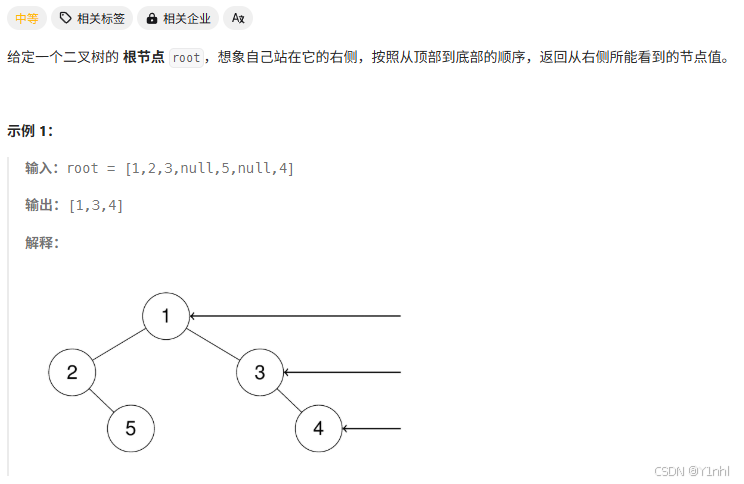
- 代码:这道题,会写层序遍历,那么就很简单了
class Solution:
def rightSideView(self, root: Optional[TreeNode]) -> List[int]:
'''
层序遍历取每层的第一个
'''
if not root: return []
res = []
queue = collections.deque()
queue.append(root)
while queue:
tmp_res = []
for _ in range(len(queue)):
node = queue.popleft()
tmp_res.append(node.val)
if node.left:queue.append(node.left)
if node.right:queue.append(node.right)
res.append(tmp_res[-1])
return res