强化学习算法
(一)动态规划方法——策略迭代算法(PI)和值迭代算法(VI)
(二)Model-Free类方法——蒙特卡洛算法(MC)和时序差分算法(TD)
(三)基于动作值的算法——Sarsa算法与Q-Learning算法
(四)深度强化学习时代的到来——DQN算法
(五)最主流的算法框架——Actor-Critic算法框架
(六)应用最广泛的算法——PPO算法
(七)更高级的算法——DDPG算法与TD3算法
(八)待续
前言
前面我们已经学习了强化学习中最流行的算法框架——Actor-Critic算法框架,本篇将会介绍该框架下最流行的一种算法——近端策略优化(Proximal Policy Optimization,PPO)算法,我们会结合公式推导其核心思想。我们将从策略梯度方法出发,逐步推导到PPO的关键改进。
一、PPO算法的核心思想
1. 重要性采样
重要性采样是强化学习中的一个重要思想,这种技术利用旧策略的采样数据,估计新策略的期望收益。修正采样分布差异,理论上严格等价。允许用旧策略数据更新新策略(如强化学习中的 Off-Policy 方法)。如果没有使用重要性采样,估计新策略的期望收益得到的结果其实是旧策略的采样与新策略运算得到的结果。我们实际想要的其实是,新策略的采样与新策略的做运算结果。
2. 裁剪机制
为防止
r
(
θ
)
r(θ)
r(θ) 偏离1过多(即策略更新过大),PPO引入裁剪操作:
L
C
L
I
P
(
θ
)
=
E
[
min
(
r
(
θ
)
A
(
s
,
a
)
,
c
l
i
p
(
r
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
(
s
,
a
)
)
]
L^{CLIP}(θ)=\mathbb E[\min(r(θ)A(s,a), clip(r(θ),1−ϵ,1+ϵ)A(s,a))]
LCLIP(θ)=E[min(r(θ)A(s,a),clip(r(θ),1−ϵ,1+ϵ)A(s,a))]其中
ϵ
ϵ
ϵ是超参数(如0.2),裁剪函数将
r
(
θ
)
r(θ)
r(θ)限制在
[
1
−
ϵ
,
1
+
ϵ
]
[1−ϵ,1+ϵ]
[1−ϵ,1+ϵ]之间。
裁剪的直观解释
- 若 A(s,a)>0(动作优于平均),限制 r(θ)≤1+ϵ,避免过度利用;
- 若 A(s,a)<0(动作劣于平均),限制 r(θ)≥1−ϵ,避免过度探索。
3. PPO的完整目标函数
实际中,PPO还增加了值函数误差和熵正则项:
L
T
o
t
a
l
=
L
C
L
I
P
(
θ
)
−
c
1
L
V
F
(
θ
)
+
c
2
H
(
π
θ
)
L ^{Total} =L ^{CLIP} (θ)−c_1L^{VF}(θ)+c_2H(π_θ )
LTotal=LCLIP(θ)−c1LVF(θ)+c2H(πθ)其中,
L
V
F
L^{VF}
LVF是值函数的均方误差;
H
H
H是策略的熵,鼓励探索;
c
1
,
c
2
c_1,c_2
c1,c2是权重系数。
二、代码实验
import gym
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
import torch.nn.functional as F
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 超参数设置
GAMMA = 0.99
GAE_LAMBDA = 0.95
CLIP_EPSILON = 0.2
PPO_EPOCHS = 4
BATCH_SIZE = 64
LR_ACTOR = 3e-4
LR_CRITIC = 1e-3
MAX_EPISODES = 2000
HIDDEN_SIZE = 128
EPSILON_DECAY = 0.995
reward_list = []
# 策略网络(Actor)
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, HIDDEN_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE, HIDDEN_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE, action_dim),
nn.Softmax(dim=-1)
)
self.to(device)
def forward(self, x):
return self.net(x)
# 价值网络(Critic)
class Critic(nn.Module):
def __init__(self, state_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, HIDDEN_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE, HIDDEN_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE, 1)
)
self.to(device)
def forward(self, x):
return self.net(x)
# PPO智能体
class PPOAgent:
def __init__(self, state_dim, action_dim):
self.actor = Actor(state_dim, action_dim)
self.critic = Critic(state_dim)
self.optimizer = optim.Adam([
{'params': self.actor.parameters(), 'lr': LR_ACTOR},
{'params': self.critic.parameters(), 'lr': LR_CRITIC}
])
self.data = []
def collect_data(self, state, action, reward, next_state, done, log_prob):
"""收集单步经验(保持CPU存储)"""
self.data.append((
torch.FloatTensor(state).to(device),
torch.LongTensor([action]).to(device),
reward,
torch.FloatTensor(next_state).to(device),
done,
torch.FloatTensor([log_prob]).to(device)
))
def compute_gae(self, next_value):
"""计算广义优势估计(GAE)"""
states = torch.stack([t[0] for t in self.data])
rewards = torch.FloatTensor([t[2] for t in self.data]).to(device)
dones = torch.FloatTensor([t[4] for t in self.data]).to(device)
with torch.no_grad():
values = self.critic(states).squeeze()
values = torch.cat([values, next_value])
advantages = []
gae = 0
for t in reversed(range(len(rewards))):
delta = rewards[t] + GAMMA * values[t + 1] * (1 - dones[t]) - values[t]
gae = delta + GAMMA * GAE_LAMBDA * (1 - dones[t]) * gae
advantages.insert(0, gae)
return torch.stack(advantages)
def update(self):
"""PPO核心更新逻辑"""
if not self.data:
return
# 解压数据并保持GPU张量
states = torch.stack([t[0] for t in self.data])
actions = torch.stack([t[1] for t in self.data]).squeeze()
old_log_probs = torch.stack([t[5] for t in self.data]).squeeze()
next_states = torch.stack([t[3] for t in self.data])
# 计算最终状态价值
with torch.no_grad():
next_value = self.critic(next_states[-1])
advantages = self.compute_gae(next_value)
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# 多轮优化
for _ in range(PPO_EPOCHS):
indices = torch.randperm(len(states)).to(device)
for i in range(0, len(states), BATCH_SIZE):
idx = indices[i:i + BATCH_SIZE]
batch_states = states[idx]
batch_actions = actions[idx]
batch_old_log_probs = old_log_probs[idx]
batch_advantages = advantages[idx]
# 计算新策略概率
probs = self.actor(batch_states)
dist = Categorical(probs)
batch_new_log_probs = dist.log_prob(batch_actions)
# 计算策略损失
ratios = (batch_new_log_probs - batch_old_log_probs).exp()
surr1 = ratios * batch_advantages
surr2 = torch.clamp(ratios, 1 - CLIP_EPSILON, 1 + CLIP_EPSILON) * batch_advantages
policy_loss = -torch.min(surr1, surr2).mean()
# 计算价值损失
values = self.critic(batch_states).squeeze()
value_loss = F.mse_loss(values, values.detach() + batch_advantages)
# 计算熵正则项
entropy_loss = -dist.entropy().mean()
# 总损失
total_loss = policy_loss + 0.5 * value_loss + 0.01 * entropy_loss
# 反向传播
self.optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5)
torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5)
self.optimizer.step()
# 清空数据
self.data = []
# 训练流程
def train_ppo(env_name, episodes):
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = PPOAgent(state_dim, action_dim)
for episode in range(episodes):
state = env.reset()[0]
episode_reward = 0
done = False
while not done:
# 选择动作
state_tensor = torch.FloatTensor(state).to(device)
with torch.no_grad():
action_probs = agent.actor(state_tensor)
dist = Categorical(action_probs)
action = dist.sample()
log_prob = dist.log_prob(action)
# 执行动作
next_state, reward, terminated, truncated, _ = env.step(action.item())
done = terminated or truncated
# 收集数据(自动记录GPU张量)
agent.collect_data(state, action.item(), reward, next_state, done, log_prob.item())
state = next_state
episode_reward += reward
if done:
agent.update()
reward_list.append(episode_reward)
# 打印训练进度
if (episode + 1) % 10 == 0:
avg_reward = np.mean(reward_list[-10:])
print(f"回合: {episode + 1}, 奖励: {episode_reward}, 最近10轮平均: {avg_reward:.1f}")
env.close()
if __name__ == "__main__":
env_name = "CartPole-v1"
episodes = MAX_EPISODES
train_ppo(env_name, episodes)
# 保存结果并绘图
plt.plot(range(episodes), reward_list)
plt.xlabel('训练回合')
plt.ylabel('回合总奖励')
plt.title('PPO在CartPole-v1中的训练表现')
plt.grid(True)
plt.show()
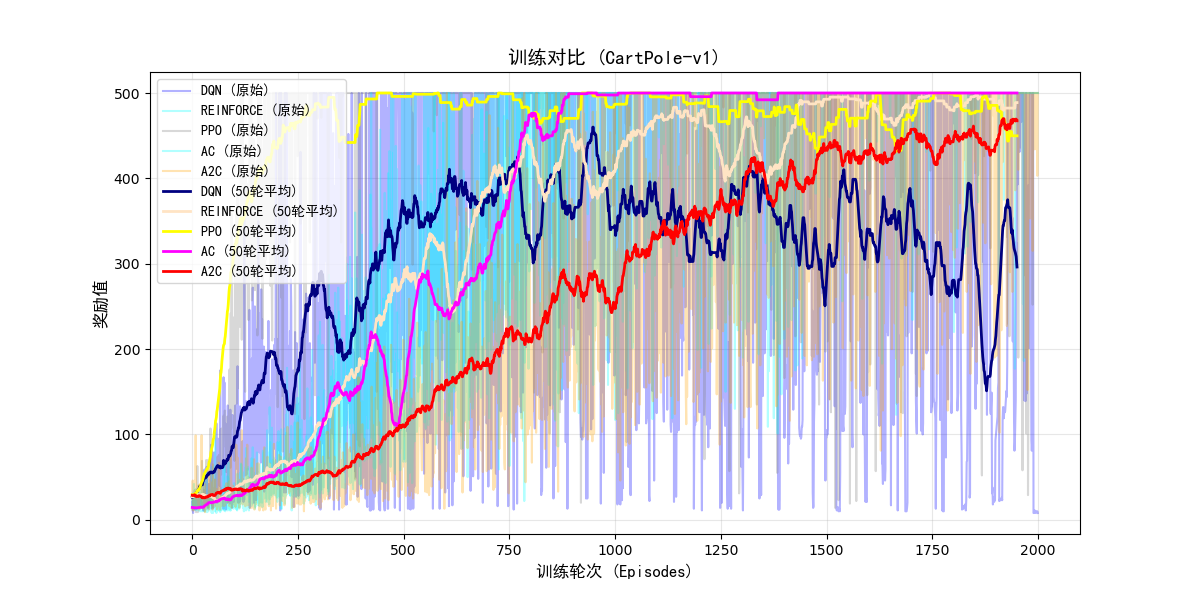
绘图代码:
import numpy as np
import matplotlib.pyplot as plt
# 加载数据(注意路径与图中一致)
dqn_rewards = np.load("dqn_rewards.npy")
REFINORCE_rewards = np.load("REINFORCE_rewards.npy")
ddqn_rewards = np.load("ddqn_rewards.npy")
ppo_rewards = np.load("ppo_rewards.npy")
AC2_rewards = np.load("AC2_rewards.npy")
A2C_rewards = np.load("AC_rewards.npy")
plt.figure(figsize=(12, 6))
# 绘制原始曲线
plt.plot(dqn_rewards, alpha=0.3, color='blue', label='DQN (原始)')
plt.plot(REFINORCE_rewards, alpha=0.3, color='cyan', label='REINFORCE (原始)')
# plt.plot(ddqn_rewards, alpha=0.3, color='orange', label='DDQN (原始)')
plt.plot(ppo_rewards, alpha=0.3, color='gray', label='PPO (原始)')
plt.plot(AC2_rewards, alpha=0.3, color='cyan', label='AC (原始)')
plt.plot(A2C_rewards, alpha=0.3, color='orange', label='A2C (原始)')
# 绘制滚动平均曲线(窗口大小=50)
window_size = 50
plt.plot(np.convolve(dqn_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='navy', label='DQN (50轮平均)')
plt.plot(np.convolve(REFINORCE_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='bisque', label='REINFORCE (50轮平均)')
# plt.plot(np.convolve(ddqn_rewards, np.ones(window_size)/window_size, mode='valid'),
# linewidth=2, color='red', label='DDQN (50轮平均)')
plt.plot(np.convolve(ppo_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='yellow', label='PPO (50轮平均)')
plt.plot(np.convolve(AC2_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='magenta', label='AC (50轮平均)')
plt.plot(np.convolve(A2C_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='red', label='A2C (50轮平均)')
# 图表标注
plt.xlabel('训练轮次 (Episodes)', fontsize=12, fontfamily='SimHei')
plt.ylabel('奖励值', fontsize=12, fontfamily='SimHei')
plt.title('训练对比 (CartPole-v1)', fontsize=14, fontfamily='SimHei')
plt.legend(loc='upper left', prop={'family': 'SimHei'})
plt.grid(True, alpha=0.3)
# 保存图片(解决原图未保存的问题)
# plt.savefig('comparison.png', dpi=300, bbox_inches='tight')
plt.show()
对比结果图: