gpt2 本地调用调用及其调用配置说明
环境依赖安装,模型下载
在大模型应用开发中,需要学会本地调用模型,
要在本地环境调用gpt2 模型需要将模型下载到本地,这里记录本地调用流程:
在huggingface 模型库中查找到需要使用的模型;这里以调用 uer/gpt2-chinese-cluecorpussmall 模型为例。使用transformers 对应模型进行模型下载;
下载模型:
需要先安装 PyTorch 或者 TensorFlow 同时确保能够访问到 https://huggingface.co 网站 否则下载不成功;
pip install torch torchvision torchaudio
pip install tensorflow
#将模板下载到本地
from transformers import AutoModelForCausalLM, AutoTokenizer
#将饭型利分问器卜我到小地,并指定保任路径
model_name ="uer/gpt2-chinese-cluecorpussmall"
cache_dir ="model/uer/gpt2-chinese-cluecorpussmall"
#下载模型
AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir)
#下载分词库工具
AutoTokenizer.from_pretrained(model_name,cache_dir=cache_dir)
print(f"模型分词器已下载到:{cache_dir}")
模型下载完成后目录结构:

目录文件说明:
调用模型是使用分带有config.json 的目录结对路径
config.json:
{
// 激活函数类型,这里使用 GELU 的改进版(gelu_new),常用于 GPT 模型
"activation_function": "gelu_new",
// 模型架构类型,这里是 GPT2 的带语言模型头的版本(用于文本生成)
"architectures": [
"GPT2LMHeadModel"
],
// Attention 层的 dropout 概率(防止过拟合)
"attn_pdrop": 0.1,
// Embedding 层的 dropout 概率
"embd_pdrop": 0.1,
// 是否启用梯度检查点(节省显存但降低速度),false 表示不启用
"gradient_checkpointing": false,
// 参数初始化范围(正态分布的标准差)
"initializer_range": 0.02,
// Layer Normalization 的 epsilon(防止除以零的小常数)
"layer_norm_epsilon": 1e-05,
// 模型类型标识(这里是 GPT2)
"model_type": "gpt2",
// 上下文最大长度(token 数量)
"n_ctx": 1024,
// Embedding 的维度大小
"n_embd": 768,
// Attention 头的数量
"n_head": 12,
// Feed-Forward 层中间维度(null 表示使用默认值 4*n_embd)
"n_inner": null,
// Transformer 的层数
"n_layer": 12,
// 模型支持的最大位置编码长度
"n_positions": 1024,
// 是否输出过去的隐藏状态(兼容性参数)
"output_past": true,
// 残差连接的 dropout 概率
"resid_pdrop": 0.1,
// 任务特定参数(这里是文本生成的默认配置)
"task_specific_params": {
"text-generation": {
// 是否使用采样(而非贪婪解码)
"do_sample": true,
// 生成的最大长度
"max_length": 320
}
},
// 使用的 tokenizer 类型(虽然模型是 GPT2,但这里用了 BertTokenizer)
"tokenizer_class": "BertTokenizer",
// 词表大小(中文 BERT 词表通常为 21128)
"vocab_size": 21128
}
special_tokens_map.json:
{
// 未知字符标记(遇到不在词表中的字符时使用)
"unk_token": "[UNK]",
// 分隔符标记(用于分隔两个句子的特殊标记,如句子A和句子B)
"sep_token": "[SEP]",
// 填充标记(用于将不同长度的序列补齐到相同长度)
"pad_token": "[PAD]",
// 分类标记(常用于文本分类任务,放在文本开头)
"cls_token": "[CLS]",
// 掩码标记(用于掩码语言模型MLM任务,如BERT的完形填空)
"mask_token": "[MASK]"
}
unk_token
用途:当遇到词表中不存在的字符或单词时使用
示例:“你好[UNK]世界”(中间的词未被词表收录)
注意:所有NLP模型都需要处理OOV(Out-Of-Vocabulary)问题
sep_token
典型场景:
句子对任务(如文本相似度判断)
问答系统(问题和上下文的分隔)
BERT风格格式:[CLS]句子A[SEP]句子B[SEP]
pad_token
功能:
保证batch内样本长度一致
通常配合attention_mask使用(1表示真实token,0表示padding)
训练技巧:计算loss时应忽略padding部分
cls_token
特殊用途:
分类任务中代表整个序列的语义
通常接分类器层[CLS] -> Dense -> Softmax
可视化:可通过注意力权重观察模型如何聚合信息
mask_token
预训练用途:
BERT的MLM任务:“机器[MASK]很厉害” -> “机器学习很厉害”
通常15%的token会被随机mask
微调注意:下游任务中可能不需要此tok
tokenizer_config.json:
使用transformers 进行模型调用:
# 本地离线调用gpa2 模型
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# 设置具体包含config 本地模型路径
model_name = r"D:\study\ai_lean\PythonProject\gpt2-lean\model\uer\gpt2-chinese-cluecorpussmall\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3"
# 加载模型 和分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 使用加载的模型和分词器生成文本的 pipeline
generator = pipeline(
"text-generation", # pipeline 的类型
model=model, # 模型
tokenizer=tokenizer, # 分词器
device=0, # 设备
max_length=100, # 最大长度
do_sample=True, # 是否使用采样
top_k=10, # 采样的topk
num_return_sequences=1, # 返回的文本数量
eos_token_id=tokenizer.eos_token_id, # 结束符
)
# 生成文本
output = generator("你好,我是一名程序员", num_return_sequences=1, max_length=100)
print(output)
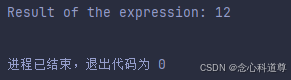
输出结果:
[{‘generated_text’: ‘你好,我是一名程序员 。 我 的 职 业 发 展 是 做 程 序 员 , 但 我 没 有 一 技 之 长 。 所 有 的 事 情 , 我 都 想 着 尽 可 能 的 做 好 。 在 这 里 我 想 说 : 一 个 人 的 一 生 是 有 规 律 的 , 每 个 人 都 是 在 不 断 完 善 , 不 断 探 索 。 我 在 这 个 问 题 上 , 有 自 我 的 判 断’}]
这是调用uer/gpt2-chinese-cluecorpussmall 模型续写的结果,