论文下载地址:Generalized Category Discovery with Large Language Models in the Loop - ACL Anthology
1、研究背景
尽管现代机器学习系统在许多任务上取得了优异的性能,绝大多数都遵循封闭世界的设置,假设训练和测试数据来自同一组预定义的类别。然而,在现实世界中,许多实际问题,如意图检测和图片识别是开放世界,其中训练有素的模型可能会遇到具有未知新颖类别的数据。为了应对这一限制,广义类别发现(GCD)被提出并在自然语言处理和计算机视觉两个领域中被广泛研究。GCD要求模型根据一些仅包含已知类别的已标记数据,从一组未标记数据中识别已知和新类别,这可以使模型适应新兴类别,而无需任何人工努力。
目前的方法通常首先对标记数据进行监督预训练,对未标记数据进行自监督学习,以训练一个基本模型,如BERT,然后他们执行聚类方法,如KMeans,以发现已知和新的类别。即使这些方法可以提高已知类别的性能,但由于缺乏监督,它们通常在新类别上表现不佳。此外,由于缺乏新类别的先验知识,他们还努力揭示所发现的聚类的语义含义(例如,类别名称或描述)。最近,大型语言模型(LLM)如ChatGPT在没有任何标记样本的情况下也显示出了非凡的应用能力。然而,LLMs不能直接应用于GCD,GCD需要模型来聚类成千上万的样本。数据隐私、高推理延迟和高API成本等问题也限制了它们在现实世界中的应用。
2、拟解决的关键问题
为了解决上述限制并享受基本模型和LLM的优点,我们提出了Loop,一种将LLM引入训练过程的端到端主动学习框架。Loop通过选择几个关键样本来查询LLM,并根据反馈优化基本模型,可以弥补监督的不足,并以较小的查询代价为发现的聚类生成类别名称。因此,我们只需要在本地训练和维护一个小的基本模型,这可以降低推理成本和保护数据隐私。具体来说,如图1所示,我们首先提出局部不一致采样(LIS)来选择落入错误聚类的概率较高的最具信息量的样本。具体来说,我们选择样本具有高熵的聚类分配概率和其邻居具有最多样化的聚类分配。直观上,具有高熵和不同邻居预测的样本似乎违反了聚类假设(江等,2022)并位于决策边界附近(图2虚线圆),因此这些具有很大不确定性的邻居混沌样本将有很高的概率落入错误的聚类(王等,2023),因此纠正它们可以显著提高模型性能。
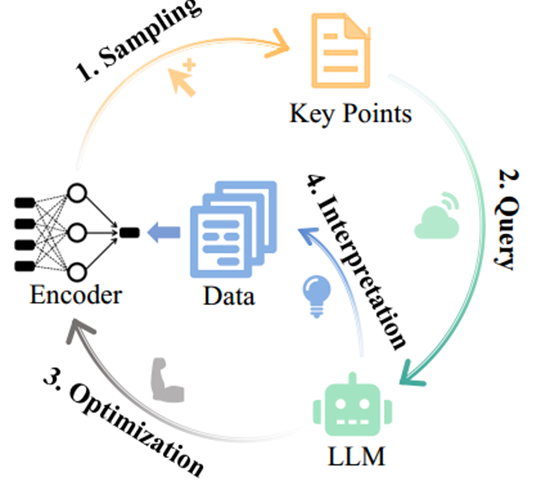
图1 模型的训练循环
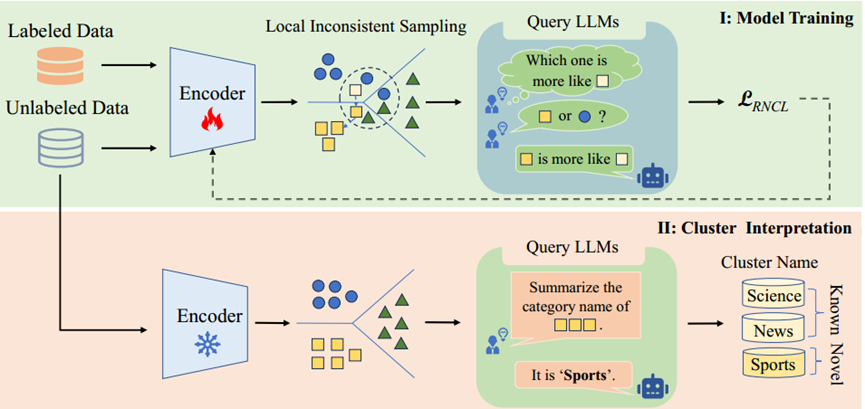
图2 模型架构
3、相关解决方案
3.1 多任务预训练

3.2 局部不一致抽样

3.3 可扩展查询策略
给定选择的样本,下一步是如何查询LLM以获得适当的监督信息。然而,我们不能直接向LLM查询类别,因为没有新类别的标签信息,并且返回的类别很难与聚类分配一致。因此,受最近工作的启发,我们提出了一种可扩展的查询策略,通过查询LLM哪些样本是所选样本的真正邻居来缓解局部不一致问题。这样,我们可以通过确定样本之间的邻域关系来找到所选样本的真实聚类分配。
这个查询策略是可伸缩的,因为我们可以设置不同数量的邻居选项供LLM选择。以带有|q| options的查询为例,提示可以设计为:“选择与查询语句更好对应的语句。查询:[S]。第一句:[S1];第二句:[S2];...;句子|q|:[S|q|]。”,其中[S]是所选的查询样本,[S1],[S2]...[S|q|]是来自具有查询样本的最多邻居的top |q|聚类的[S]的邻居句子。
所提出的查询策略可以通过从混乱的邻域中选择真正的邻居来帮助纠正局部不一致的样本。这种策略是可伸缩的,因为我们可以添加不同数量的选项来查询LLM。虽然添加更多选项将提供从与查询相同的类别中选择样本的更高概率,但它将通过添加更多查询标记(秒)来增加查询成本。即使我们没有找到真正的邻居样本,我们的模型仍然可以通过拉近相似样本来学习语义知识。
3.4 聚类解释
不同于以往只通过聚类来发现没有任何语义信息的聚类,我们提出用LLMs来解释发现的聚类。具体来说,我们首先利用“对齐和解耦”策略将对应于新类别的聚类从发现的聚类中解耦。然后,对于每个解耦的聚类,我们选择最接近聚类中心的几个样本作为代表性样本。接下来,我们制作LLM来总结这些样本,以生成这些新颖类别的标签名称。实验结果表明,该策略能够为发现的新类别选择有代表性的样本并生成准确的标签名称。
4、总结
在本文中,提出了一个主动学习框架Loop,它将LLMs引入到广义类别发现的训练循环中,可以在不需要任何人工努力的情况下提高模型性能。研究进一步提出局部不一致抽样来选择有用的样本,并利用可扩展查询在LLMs的反馈下修正这些样本。通过将样本拉得更接近其精确的邻居,模型可以学习聚类友好的表示。最后,为发现的集群生成标签名称,以便于实际应用。实验表明,Loop大大优于SOTA模型,并为发现的聚类生成准确的类别名称。