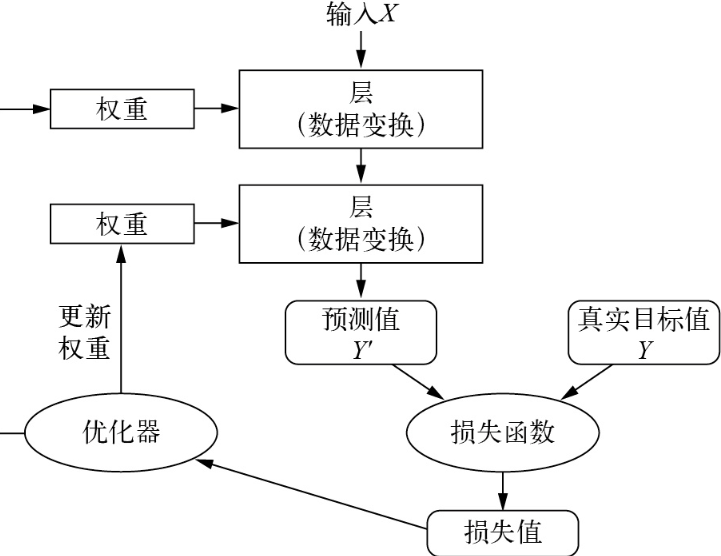
模型工作流程
模型由许多层链接在一起组成,并将输入数据映射为预测值。随后,损失函数将这些预测值与目标值进行比较,得到一个损失值,用于衡量模型预测值与预期结果之间的匹配程度。优化器将利用这个损失值来更新模型权重。
下面是输入数据。
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
输入图像保存在float32类型的NumPy张量中,其形状分别为(60000,784)(训练数据)和(10000, 784)(测试数据)。
下面是模型。
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
这个模型包含两个链接在一起的Dense层,每层都对输入数据做一些简单的张量运算,这些运算都涉及权重张量。权重张量是该层的属性,里面保存了模型所学到的知识。
下面是模型编译。
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
sparse_categorical_crossentropy是损失函数,是用于学习权重张量的反馈信号,在训练过程中应使其最小化。降低损失值是通过小批量随机梯度下降来实现的。梯度下降的具体方法由第一个参数给定,即rmsprop优化器。
下面是训练循环。
model.fit(train_images, train_labels, epochs=5, batch_size=128)
在调用fit时:模型开始在**训练数据(共60000个样本)**上进行迭代(每个小批量包含128个样本),共迭代5轮[在所有训练数据上迭代一次叫作一轮(epoch)]。对于每批数据,模型会计算损失相对于权重的梯度(利用反向传播算法,这一算法源自微积分的链式法则),并将权重沿着减小该批量对应损失值的方向移动。5轮之后,模型共执行2345次梯度更新(每轮469次),模型损失值将变得足够小,使得模型能够以很高的精度对手写数字进行分类。
用TensorFlow从头开始重新实现模型
简单的Dense类
Dense层实现了下列输入变换,其中W和b是模型参数,activation是一个逐元素的函数(通常是relu,但最后一层是softmax)。
output = activation(dot(W, input) + b)
我们实现一个简单的Python类NaiveDense,它创建了两个TensorFlow变量W和b,并定义了一个__call__()方法供外部调用,以实现上述变换。
import tensorflow as tf
class NaiveDense:
#构造函数
def __init__(self, input_size, output_size, activation):
#模拟keras的dense层可以设置激活函数
self.activation = activation
w_shape = (input_size, output_size)
#创建一个形状为(input_size, output_size)的矩阵W,并将其随机初始化
w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)
self.W = tf.Variable(w_initial_value)
b_shape = (output_size,)
#创建一个形状为(output_size,)的零向量b
b_initial_value = tf.zeros(b_shape)
self.b = tf.Variable(b_initial_value)
#前向传播
def __call__(self, inputs):
return self.activation(tf.matmul(inputs, self.W) + self.b)
#获取该层权重的便捷方法
@property
def weights(self):
#以列表的形式返回本层的权重
return [self.W, self.b]
我们总结一下NaiveDense实现了哪些步骤:
1.根据输入输出的形状初始化权重(kernel和bias)以实现仿射变换
2.初始化激活函数
3.实现前向传播函数(反向传播可以通过tensorflow的梯度带实现)
4.提供获取权重的方式
简单的Sequential类
我们创建一个NaiveSequential类来实现模型,将这些层链接起来。它封装了一个层列表(正如我们前面提到的模型由一系列层构成),并定义了一个__call__()方法供外部调用。这个方法将按顺序调用输入的层。它还有一个weights属性,用于记录所有层的权重。
class NaiveSequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, inputs):
x = inputs
for layer in self.layers:
x = layer(x)
return x
@property
def weights(self):
weights = []
for layer in self.layers:
weights += layer.weights
return weights
按照惯例,总结一下这个Sequential实现了哪些行为:
1.封装层列表
2.一次调用层列表中的层进行前向传播
实例化模型
利用NaiveSequential来实例化模型
model = NaiveSequential([
NaiveDense(input_size=28 * 28, output_size=512, activation=tf.nn.relu),
NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4
批量生成器(batch)
对MNIST数据进行小批量迭代。
import math
class BatchGenerator:
def __init__(self, images, labels, batch_size=128):
assert len(images) == len(labels)
self.index = 0
self.images = images
self.labels = labels
self.batch_size = batch_size
self.num_batches = math.ceil(len(images) / batch_size)
def next(self):
images = self.images[self.index : self.index + self.batch_size]
labels = self.labels[self.index : self.index + self.batch_size]
self.index += self.batch_size
return images, labels
批量生成器很简单,就是将训练数据保存下来,每次迭代产生批量大小的数据。
本文所有的代码汇总如下:
import tensorflow as tf
class NaiveDense:
#构造函数
def __init__(self, input_size, output_size, activation):
#模拟keras的dense层可以设置激活函数
self.activation = activation
w_shape = (input_size, output_size)
#创建一个形状为(input_size, output_size)的矩阵W,并将其随机初始化
w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)
self.W = tf.Variable(w_initial_value)
b_shape = (output_size,)
#创建一个形状为(output_size,)的零向量b
b_initial_value = tf.zeros(b_shape)
self.b = tf.Variable(b_initial_value)
#前向传播
def __call__(self, inputs):
return self.activation(tf.matmul(inputs, self.W) + self.b)
#获取该层权重的便捷方法
@property
def weights(self):
#以列表的形式返回本层的权重
return [self.W, self.b]
class NaiveSequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, inputs):
x = inputs
for layer in self.layers:
x = layer(x)
return x
@property
def weights(self):
weights = []
for layer in self.layers:
weights += layer.weights
return weights
model = NaiveSequential([
NaiveDense(input_size=28 * 28, output_size=512, activation=tf.nn.relu),
NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4
import math
class BatchGenerator:
def __init__(self, images, labels, batch_size=128):
assert len(images) == len(labels)
self.index = 0
self.images = images
self.labels = labels
self.batch_size = batch_size
self.num_batches = math.ceil(len(images) / batch_size)
def next(self):
images = self.images[self.index : self.index + self.batch_size]
labels = self.labels[self.index : self.index + self.batch_size]
self.index += self.batch_size
return images, labels





![P8627 [蓝桥杯 2015 省 A] 饮料换购](https://i-blog.csdnimg.cn/direct/fe760a4d787d4daca987288d03d2195b.png)

![[UEC++]UE5C++各类变量相关知识及其API(更新中)](https://i-blog.csdnimg.cn/direct/1fa6e22e30d84dc1858c57232c0e09a1.png)

![[Effective C++]条款30:透彻了解inlining的里里外外](https://i-blog.csdnimg.cn/direct/e4d3cbd3f39e4e719044cb86b2409cf7.png)