paper地址:SmolDocling: An ultra-compact vision-language model for
end-to-end multi-modal document conversion
Huggingface地址:SmolDocling-256M-preview
代码对应的权重文件:SmolDocling-256M-preview权重文件
一、摘要
以下是文章摘要的总结:
SmolDocling 是一个超紧凑型的视觉-语言模型,用于端到端的文档转换。它通过生成一种名为 DocTags 的新标记格式,捕捉文档中所有元素的内容、结构和位置。SmolDocling 在多种文档类型(如商务文档、学术论文、技术报告等)上表现出稳健的性能,能够准确重现代码、表格、公式、图表等复杂元素。与更大规模的模型相比,它在性能上具有竞争力,同时显著降低了计算需求。此外,该研究还贡献了多个公开数据集,用于支持图表、表格、公式和代码识别等任务。
(1)以下是 SmolDocling 模型支持的所有要素:
- 代码列表:识别和解析代码片段,包括缩进和行号等细节。
- 表格:识别表格结构,包括单元格合并、表头信息等。
- 公式:识别和解析数学公式,支持 LaTeX 格式。
- 图表:识别图表并将其转换为表格形式。
- 列表:识别有序列表和无序列表,支持嵌套列表。
- 页眉和页脚:识别页面的页眉和页脚内容。
- 图片:识别图片并提供分类信息。
- 段落文本:识别普通文本内容,包括换行和格式。
- 标题:识别文档中的标题和章节标题。
- 脚注:识别脚注内容。
- 文档索引:识别文档索引部分。
- 化学分子结构:识别化学分子图像并转换为 SMILES 格式(扩展功能)。
这些要素涵盖了文档中常见的各种内容类型,使得 SmolDocling 能够全面、准确地处理和转换复杂的文档。
(2) DocTags 输出格式
DocTags 是 SmolDocling 的核心输出格式,用于统一表示文档的内容、结构和布局。以下是 DocTags 支持的主要标签和格式:
文档块类型
<text>:普通文本内容。<title>:标题或章节标题。<section_header>:章节标题。<list_item>:列表项。<ordered_list>:有序列表。<unordered_list>:无序列表。<code>:代码片段,支持缩进和行号。<formula>:数学公式,支持 LaTeX 格式。<picture>:图片,支持分类信息。<caption>:标题或说明文字(通常嵌套在图片或表格中)。<footnote>:脚注。<page_header>:页眉。<page_footer>:页脚。<document_index>:文档索引。<otsl>:表格结构,使用 OTSL 标签表示。
位置标签
<loc_x1><loc_y1><loc_x2><loc_y2>:表示元素在页面中的位置(边界框),左上角坐标和右下角坐标。
表格结构(OTSL 标签)
<fcel>:包含内容的单元格。<ecel>:空单元格。<ched>:列标题单元格。<rhed>:行标题单元格。<srow>:表格部分的行。
代码分类
<_programming-language_>:编程语言分类标签(如 Python、Java 等)。
图片分类
<image_class>:图片分类标签(如 pie_chart、bar_chart、natural_image 等)。
2. 其他格式
SmolDocling 的输出可以通过 DocTags 转换为其他常见格式,具体取决于下游任务的需求:
LaTeX
- 用于数学公式(
<formula>标签)的输出。 - 示例:
<formula>E = mc^2</formula>可以转换为 LaTeX 格式。
HTML
- 用于表格(
<otsl>标签)和其他结构化内容的输出。 - 示例:
<otsl>标签可以转换为 HTML 表格。
Markdown
- 用于文本、列表、标题等的输出。
- 示例:
<text>,<list_item>,<title>等标签可以转换为 Markdown 格式。
SMILES
- 用于化学分子结构的输出(扩展功能)。
- 示例:分子图像可以转换为 SMILES 格式。
SmolDocling 的主要输出格式是 DocTags,它是一种高效的标记语言,能够统一表示文档的内容、结构和布局。此外,DocTags 可以轻松转换为其他常见格式(如 LaTeX、HTML、Markdown 等),以满足不同的应用需求。这种灵活性使得 SmolDocling 能够适应多种文档处理任务。
二、背景介绍
1、文档转换的背景与挑战
- 技术挑战:将复杂的数字文档(如 PDF)转换为结构化的、可机器处理的格式是一项长期的技术难题。
- 主要问题:
- 文档布局和样式的多样性。
- PDF 格式本身不透明,优化用于打印而非语义解析。
- 复杂的布局样式和视觉挑战元素(如表格、图表、表单)会影响文档的阅读顺序和理解。
2、现有方法的局限性
- 传统流水线方法:
- 依赖多个专门模型(如 OCR、布局分析、表格结构识别等)。
- 虽然结果质量高,但难以调优和泛化。
- 大型多模态模型(LVLMs):
- 能够端到端解决文档转换问题。
- 存在幻觉(hallucinations)、计算资源消耗大等问题。
- 缺乏高质量的公开数据集。
3、SmolDocling 的提出
- 目标:通过一个紧凑的模型实现端到端的文档转换,同时保持高效性和高质量输出。
- 核心创新:
- DocTags 格式:一种新的标记语言,用于统一表示文档的内容、结构和布局。
- 超紧凑模型:基于 Hugging Face 的 SmolVLM-256M,参数量仅为 256M。
- 数据集贡献:公开了多个高质量数据集,用于支持图表、表格、公式和代码识别等任务。
4、SmolDocling 的优势
- 性能:在多种文档类型(如商务文档、学术论文、技术报告等)上表现出稳健的性能。
- 效率:显著减少了计算需求,与更大规模的模型相比具有竞争力。
- 灵活性:支持多种文档元素(如代码、表格、公式、图表等)的识别和转换。
5、数据集的贡献
- DocLayNet-PT:140 万页的多模态文档预训练数据集,包含丰富的标注(如布局、表格、代码、图表等)。
- 任务特定数据集:针对表格、代码、公式、图表等任务生成了多个高质量数据集(如 PubTables-1M、SynthChartNet、SynthCodeNet 等)。
三、相关工作
主要分为两个方面:大型视觉-语言模型(LVLMs) 和 文档理解领域的研究现状。以下是详细总结:
1. 大型视觉-语言模型(LVLMs)
- 专有模型:
- GPT-4o、Gemini 和 Claude 3.5 等专有模型展示了在多种模态(包括视觉)上的卓越能力。
- 开源方法:
- BLIP-2:最早将视觉编码器与冻结的大型语言模型(如 OPT 或 FlanT5)结合,使用轻量级的 Q-former。
- MiniGPT-4:在 BLIP-2 的基础上,将冻结的视觉编码器与冻结的 LLM(如 Vicuna)结合,使用 Q-Former 网络和单个投影层。
- LLaVA:使用最小的适配层,结合视觉编码器和 LLM。
- LLaVA-OneVision 和 LLaVA-NeXTInterleave:支持多图像、更高分辨率和视频理解。
- InternLM-XComposer:专门设计用于处理高分辨率和文本-图像组合与理解。
- Qwen-VL:引入位置感知适配器,解决视觉编码器生成的长图像特征序列带来的效率问题。
- Qwen2.5-VL:使用窗口注意力和 2D 旋转位置嵌入,高效处理原生分辨率输入,并引入视觉-语言合并器进行动态特征压缩。
2. 文档理解领域的研究现状
- 文档理解任务:
- 包括文档分类、OCR、布局分析、表格识别、键值对提取、图表理解、公式识别等。
- 现有解决方案:
- 商业云服务:如 Amazon Textract、Google Cloud Document AI、Microsoft Azure AI Document Intelligence。
- 前沿模型:如 GPT-4o、Claude。
- 开源库:如 Docling、GROBID、Marker、MinerU 或 Unstructured。
- 流水线系统:
- 实现了源代码中的流水线,根据输入文档有条件地应用专门的单任务模型,并将预测结果组合成有意义的文档表示。
- 每个任务通常涉及人工设计的预处理和后处理逻辑(如设置布局检测的置信度阈值、匹配布局元素与文本单元格等)。
- 多任务模型:
- 旨在提供一个能够同时处理多种文档理解相关任务的单一模型,利用跨任务共享的上下文和表示。
- OCR 依赖方法:如 LayoutLM 和 UDOP,使用从外部 OCR 引擎提取的文本,以及图像和文本边界框位置作为输入。
- 无 OCR 方法:如 Donut、Dessurt、DocParser、Pix2Struct,基于变换器的模型,端到端训练以直接从图像输出文本。
- 大型视觉语言模型(LVLMs):如 LLaVA、LLaVA-OneVision、UReader、Kosmos-2 和 Qwen-VL,利用各种视觉编码器、投影适配器和 LLM。
- 评估数据集:如 DocVQA 和 mPLUG-DocOwl 1.5 数据集,主要关注问答和推理。
3. 与 SmolDocling 相关的最接近的工作
- Nougat:专注于学术文档的精确转换和结构识别。
- DocOwl 2:使用动态形状自适应裁剪模块处理高分辨率图像,并通过 ViT 视觉编码器和 LLaMa 基础的 LLM 进行处理。
- GOT:专注于将多种元素(如文本、公式、分子图、表格、图表、乐谱和几何形状)转换为结构化格式。
- Qwen2.5-VL:引入 Omni-Parsing 策略,将多种文档元素整合到一个统一的基于 HTML 的表示中。
四、SmolDocling 模型
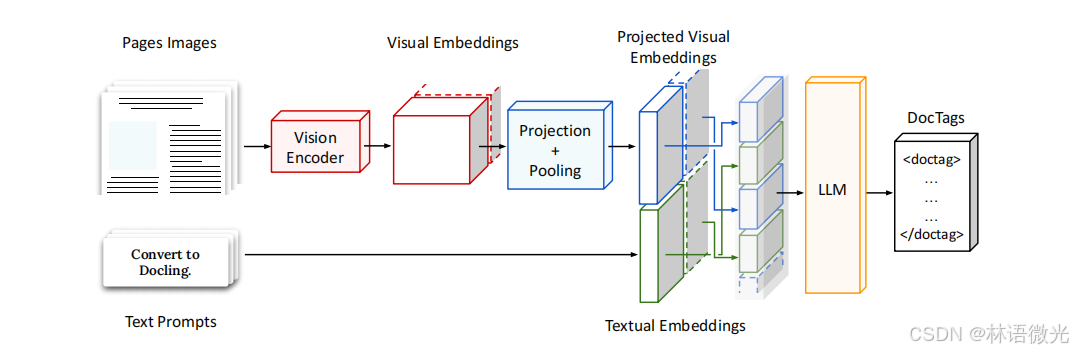
图1展示了SmolDocling的端到端流程:输入文档图像,经视觉编码器提取特征,与文本提示嵌入结合,通过LLM自回归生成DocTags序列输出。
1、SmolDocling 的模型架构
SmolDocling 的模型架构通过紧凑的视觉编码器和轻量级语言模型设计,结合激进的像素洗牌策略和视觉嵌入投影与池化技术,实现了高效的多模态融合,能够快速、准确地将文档图像转换为结构化的 DocTags 格式,显著减少了计算需求,同时在多种文档任务上表现出色。
2、DocTags格式
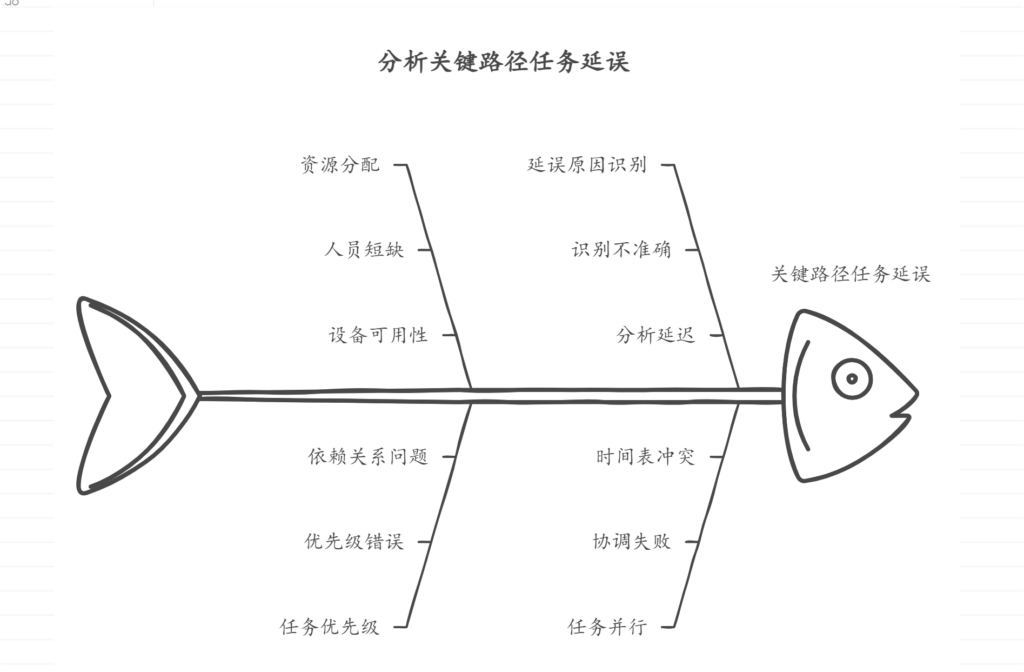
DocTags格式是一种结构化的标记语言,用于高效表示文档内容、结构和布局,通过明确标签(如文本、标题、列表项、代码、公式、图片等)和位置信息标签,支持表格结构和代码、图片分类,结合图2展示其如何描述文档元素的关键特征,包括元素类型、位置和内容,从而实现文档的高效转换和解析。
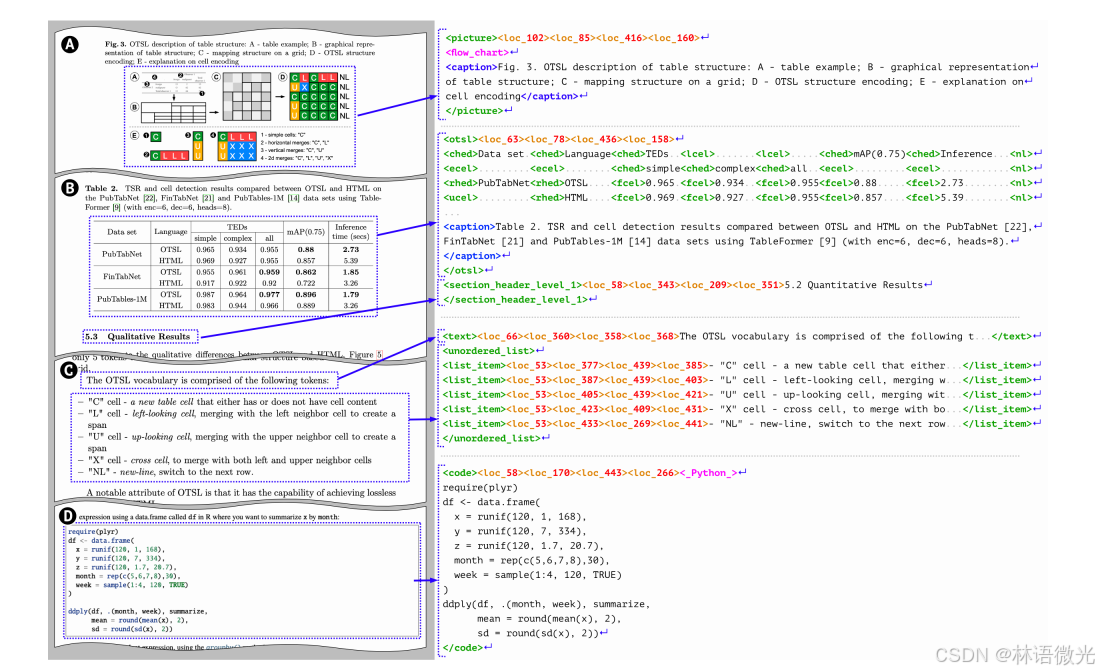
图2:DocTags格式描述了文档元素的关键特征:元素类型(文本、图片、表格、代码等)、页面位置和内容。嵌套标签传达额外信息:图片和表格可以嵌套标题,表格结构用OTSL标签表示,列表嵌套列表项,代码和图片带有分类。所有DocTags输出均来自SmolDocling预测,人为插入了换行符和点(…)以提高可读性。
3、模型训练
SmolDocling的模型训练采用课程学习方法,通过三个阶段逐步提升模型性能。
初始阶段将DocTags标记引入tokenizer,冻结视觉编码器,单独训练语言模型以适应新输出格式。
联合训练阶段解冻视觉编码器,同时训练视觉和语言部分,实现多模态融合。
最后使用所有数据集进行微调,确保模型在多种任务上的泛化能力。训练数据涵盖DocLayNet-PT预训练数据集和多个任务特定数据集,全面覆盖多种文档类型和任务。最终,SmolDocling在A100 GPU上实现单页转换时间0.35秒,内存占用仅0.489 GB,展现出高效、准确的文档转换能力。
五、数据
1、预训练数据集
- DocLayNet-PT:包含140万页的文档图像,从CommonCrawl、Wikipedia和商业文档中提取,涵盖方程式、表格、代码和彩色布局等内容。通过PDF解析和增强处理,提供布局元素、表格结构、语言、主题和图形分类的弱标注。
- Docmatix:包含130万文档,采用与DocLayNet-PT相同的弱标注策略,并增加了将多页文档转换为DocTags的指令。
2、任务特定数据集
- 布局数据集:
- DocLayNet v2:从DocLayNet-PT中采样76K页,经人工标注和质量审查,用于微调。
- WordScape:提取63K包含文本和表格的页面,作为可靠的真实标注源。
- SynthDocNet:合成250K页,使用Wikipedia内容生成,增强模型对不同布局、颜色和字体的适应性。
- 表格数据集:包括PubTables-1M、FinTabNet、WikiTableSet和从WordScape文档中提取的表格信息,转换为OTSL格式并与文本内容交织,形成紧凑序列。
- 图表数据集:包含250万张不同类型的图表(线图、饼图、柱状图等),使用三个可视化库生成,确保视觉多样性。
- 代码数据集:包含930万段渲染代码片段,涵盖56种编程语言,使用LaTeX和Pygments生成视觉多样化的代码渲染。
- 公式数据集:包含550万条独特公式,从arXiv源LaTeX代码中提取并规范化,使用LaTeX渲染,确保模型训练基于正确和标准化的代码。
3、文档指令调优数据集
- 使用DocLayNet-PT页面样本,通过随机采样布局元素生成指令,如“在特定边界框内执行OCR”、“识别页面元素类型”等,并结合Granite-3.1-2b-instruct LLM避免灾难性遗忘。
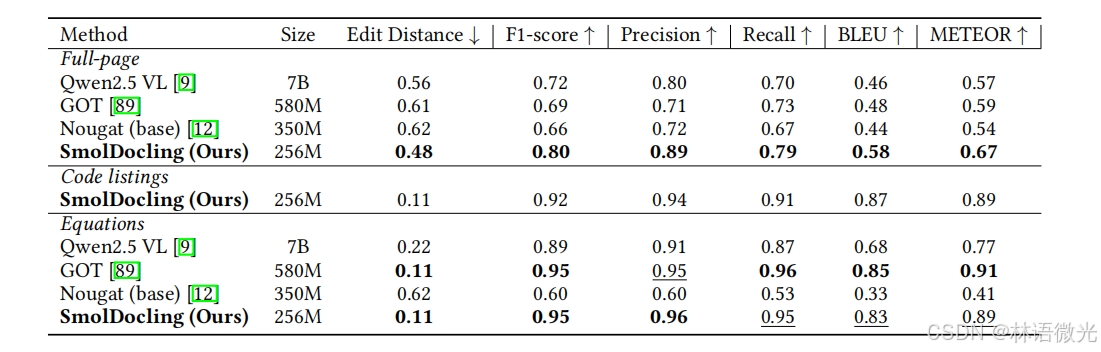
表2:结构化文档文本识别。我们在DocLayNet上评估OCR性能和文档格式,重点关注文本元素,排除表格。文本准确性通过多个指标(编辑距离、F1分数、精确度、召回率、BLEU和METEOR)进行衡量。
4、数据集贡献
- SmolDocling团队贡献了多个高质量数据集,包括DocLayNet-PT、Docmatix、SynthChartNet、SynthC