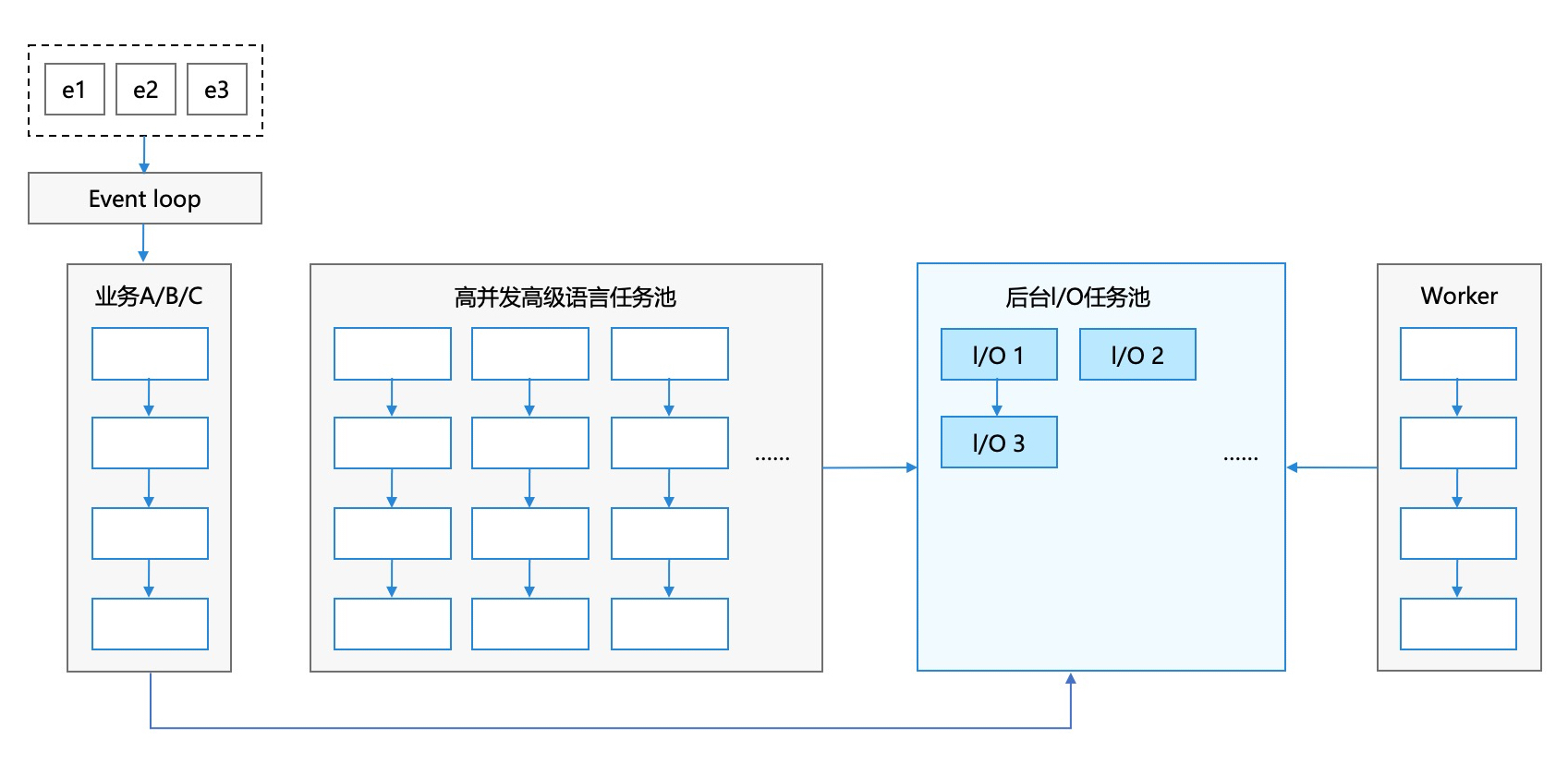
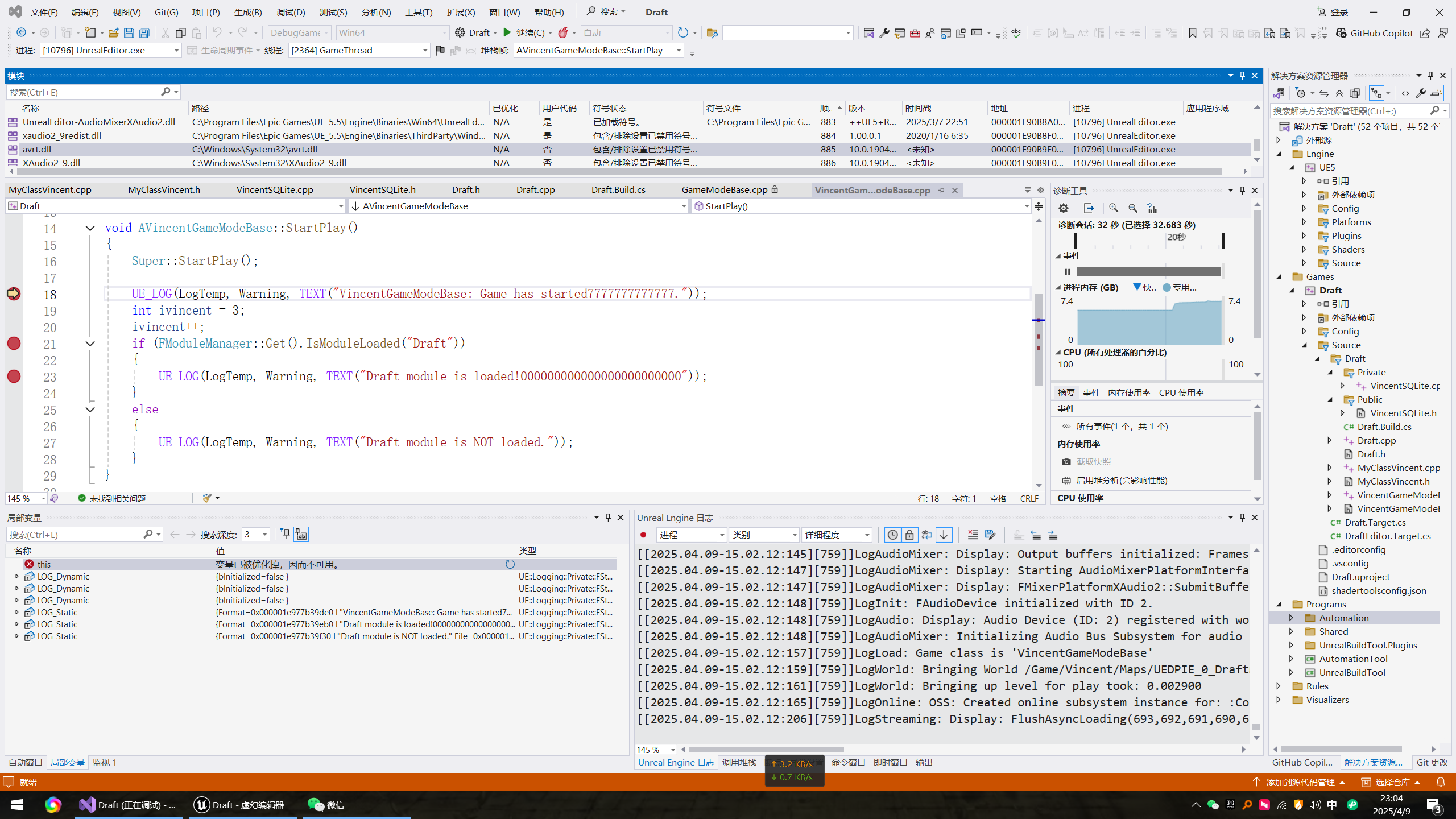
过去自己学习深度强化学习的痛点:
-
只能看到各种术语、数学公式勉强看懂,没有建立清晰且准确关联
-
多变量交互关系浮于表面,有时候连环境、代理控制的变量都混淆
-
模型种类繁多,概念繁杂难整合、对比或复用,无框架分析所有模型
-
代码实现步骤未清晰划分:环境->定义奖励->创建代理->训练->部署
最根本的原因在于,我们需要一个既能全面表达复杂环境与交互结构,又能统一处理不确定性和动态决策的数学与计算(所有强化学习)框架。
概率图模型的“图结构”天然适合分解复杂依赖:
-
可以把一系列随机变量之间的依赖关系用图的结构直观地呈现出来。
-
不管是MDP、HMM(隐马尔可夫模型)还是更复杂的POMDP和Bayesian网络,都可以视作是对一系列随机变量之间依赖关系的“图”式表达。
-
概率图模型以直观的图形方式展示变量之间的因果或条件依赖关系,利于后续的解释或扩展。
强化学习本质:一个序列决策过程,状态 (St)、动作 (At) 以及奖励 (Rt) 随时间演化且相互影响
-
图模型优势:通过节点和有向边,清晰地展现“谁依赖于谁”,帮助我们明确:
-
当前时刻状态与动作是如何影响下一个时刻状态与奖励的?
-
代理(Agent)与环境(Environment)分别控制或决定哪些随机变量?
-
哪些假设(如马尔可夫性、完全可观测或部分可观测等)在图中如何体现?
-
概率图模型在统计推断(如Bayesian推断、最大似然估计)方面有完善的理论和工具,因此能与RL中的探索—利用(exploration-exploitation)过程自然结合。
当我们能用一个动态贝叶斯网络或马尔可夫随机场来可视化时,序列之间的关系就变得更加透明。
对于多变量混杂可二分梳理,强化学习中的主体包括“环境”和“代理”。
-
环境负责提供状态和奖励
-
代理在环境中采取行动以实现累积收益最大化。
所有强化学习的“通用蓝图”:
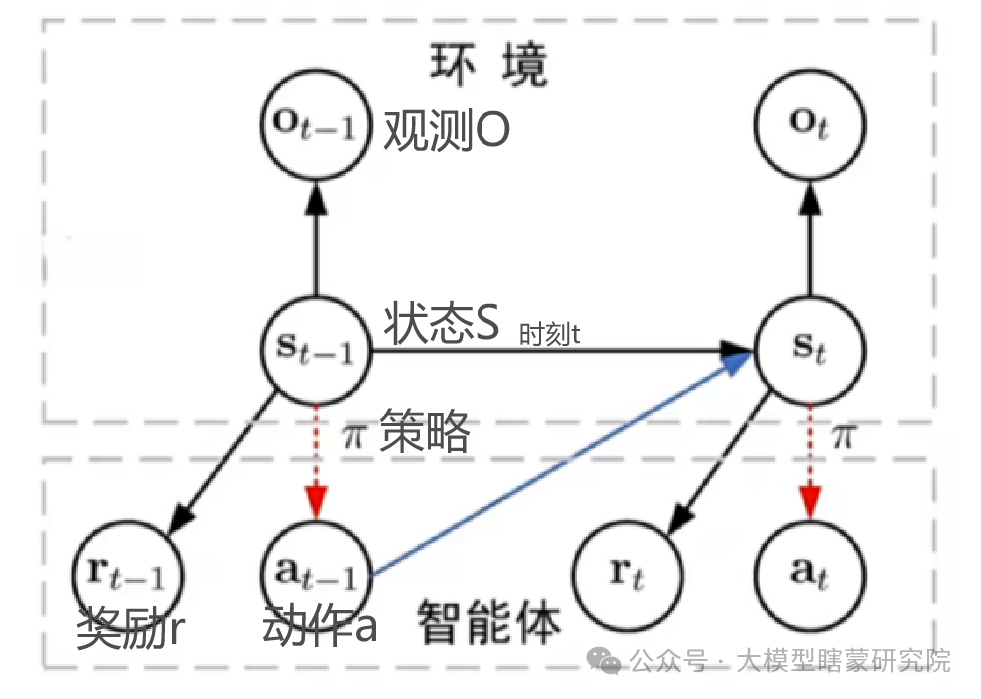
没有限定状态空间、动作空间、奖励形式、策略结构、环境类型(确定性/随机性/部分可观测...)。
只展示了宏观的交互关系,而任何“特例”都可以往里套。
环境根据动作(at)和当前状态(st)给出下一时刻状态(st+1)及相应的奖励(rt),然后智能体再继续与环境交互……
-
状态(st):
-
抽象了环境在时刻 t 的完整信息;如果不可完全观测,就用观测(ot)或者在 POMDP 框架里再对隐藏状态建模。
-
不同算法的差别,大多体现在怎样定义或估计这个状态,以及是否需要显式建模环境动力学。
-
-
动作(at):
-
智能体在时刻 t 作出的决策,这个决策可来自直接表格型策略或神经网络近似;既可以是离散的也可以是连续的。
-
但无论用什么表示方法,始终绕不开“在状态下做动作”的这个核心过程。
-
-
奖励(rt):
-
环境对当前状态、动作的一次性反馈,用来指导智能体学习;兼容各种奖励设计(稀疏奖励、密集奖励、多维奖励等)。
-
强化学习最核心的目标即是最大化“回报”,即从奖励推导的累计收益,这也体现了动态规划的思想。
-
-
策略(π(at∣st)):
-
表示智能体在状态 st 下选择动作 at 的概率分布(或确定性函数),正是因为有这个策略才构成了完整的“闭环”。
-
所有算法都需要“如何表示策略、如何更新/优化策略、如何评价策略的好坏”。
-
-
状态转移和观测模型:
-
用概率分布 P(st+1∣st, at) 来刻画环境动力学和不确定性;若有部分可观测,则还要有 P(ot∣st)。
-
任何随机性、噪声、对未来的不确定,都能融入到这条“状态演化”的概率分布里,并且与奖励、动作紧密结合。
-





![[ctfshow web入门] web32](https://i-blog.csdnimg.cn/direct/f632eb2af692428790a41c3768a612e3.png)