使用Transformer进行序列到序列学习
正是序列到序列学习让Transformer真正大放异彩。与RNN相比,神经注意力使Transformer模型能够处理更长、更复杂的序列。要将英语翻译成西班牙语,你不会一个单词一个单词地阅读英语句子,将其含义保存在记忆中,然后再一个单词一个单词地生成西班牙语句子。这种方法可能适用于只有5个单词的句子,但不太可能适用于一整个段落。相反,你可能会在源句子与正在翻译的译文之间来回切换,并在写下译文时关注源句子中的单词。你可以利用神经注意力和Transformer来实现这一方法。你已经熟悉了Transformer编码器,对于输入序列中的每个词元,它使用自注意力来生成上下文感知的表示。在序列到序列Transformer中,Transformer编码器当然承担编码器的作用,读取源序列并生成编码后的表示。但与之前的RNN编码器不同,Transformer编码器会将编码后的表示保存为序列格式,即由上下文感知的嵌入向量组成的序列。
模型的后半部分是Transformer解码器。与RNN解码器一样,它读取目标序列中第0~N个词元来尝试预测第N+1个词元。重要的是,在这样做的同时,它还使用神经注意力来找出,在编码后的源句子中,哪些词元与它目前尝试预测的目标词元最密切相关——这可能与人类译员所做的没什么不同。回想一下查询−键−值模型:在Transformer解码器中,目标序列即为注意力的“查询”,指引模型密切关注源序列的不同部分(源序列同时担任键和值)。
Transformer解码器
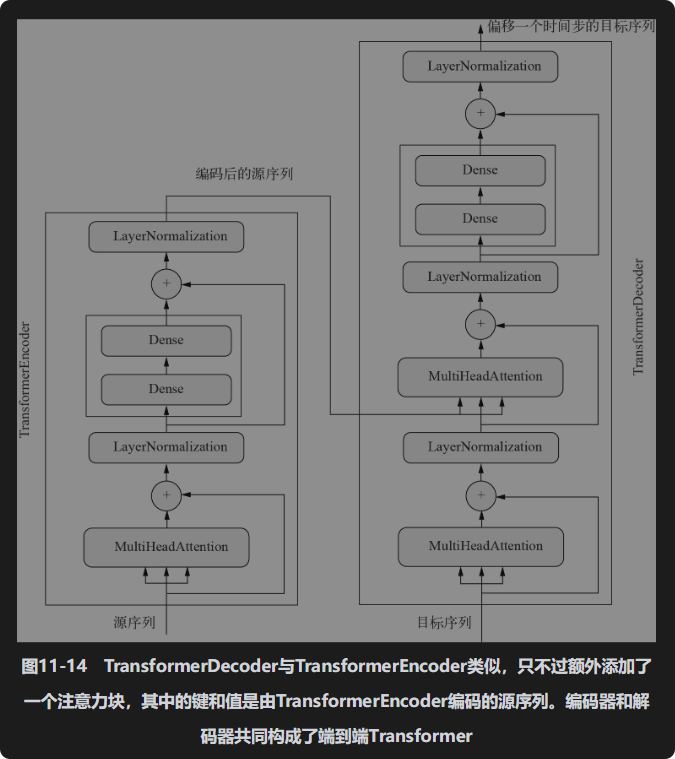
完整的序列到序列Transformer如图11-14所示。观察解码器的内部结构,你会发现它与Transformer编码器非常相似,只不过额外插入了一个注意力块,插入位置在作用于目标序列的自注意力块与最后的密集层块之间。
我们来实现Transformer解码器。与TransformerEncoder一样,我们需要将Layer子类化。所有运算都在call()方法中进行,在此之前,我们先来定义类的构造函数,其中包含我们所需要的层,如代码清单11-33所示。
代码清单11-33TransformerDecoder
class TransformerDecoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
self.supports_masking = True ←----这一属性可以确保该层将输入掩码传递给输出。Keras中的掩码是可选项。如果一个层没有实现compute_mask()并且没有暴露这个supports_masking属性,那么向该层传入掩码则会报错
def get_config(self):
config = super().get_config()
config.update({
"embed_dim"





![STM32单片机入门学习——第30节: [9-6] FlyMcu串口下载STLINK Utility](https://i-blog.csdnimg.cn/direct/97e2313311e544b9b29b6be7d62da95e.png)