前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
1. 引言 👋
在机器学习的广阔天地中,模型评估指标是我们理解和优化模型的重要工具。其中,假阳性率(False Positive Rate,FPR)作为一个关键指标,在众多应用场景中扮演着至关重要的角色。无论是医疗诊断、欺诈检测、还是信息安全领域,对FPR的深入理解和有效控制都直接关系到模型的实际应用价值。
本文将从概念定义出发,深入剖析FPR的理论基础、计算方法、应用场景和优化策略,帮助读者全面理解这一重要指标,并能在实际工作中熟练运用。我们不仅会讨论理论知识,还将结合实际案例和代码实现,为读者提供完整的学习路径。
2. 基础概念:什么是假阳性率?🧩
2.1 混淆矩阵回顾
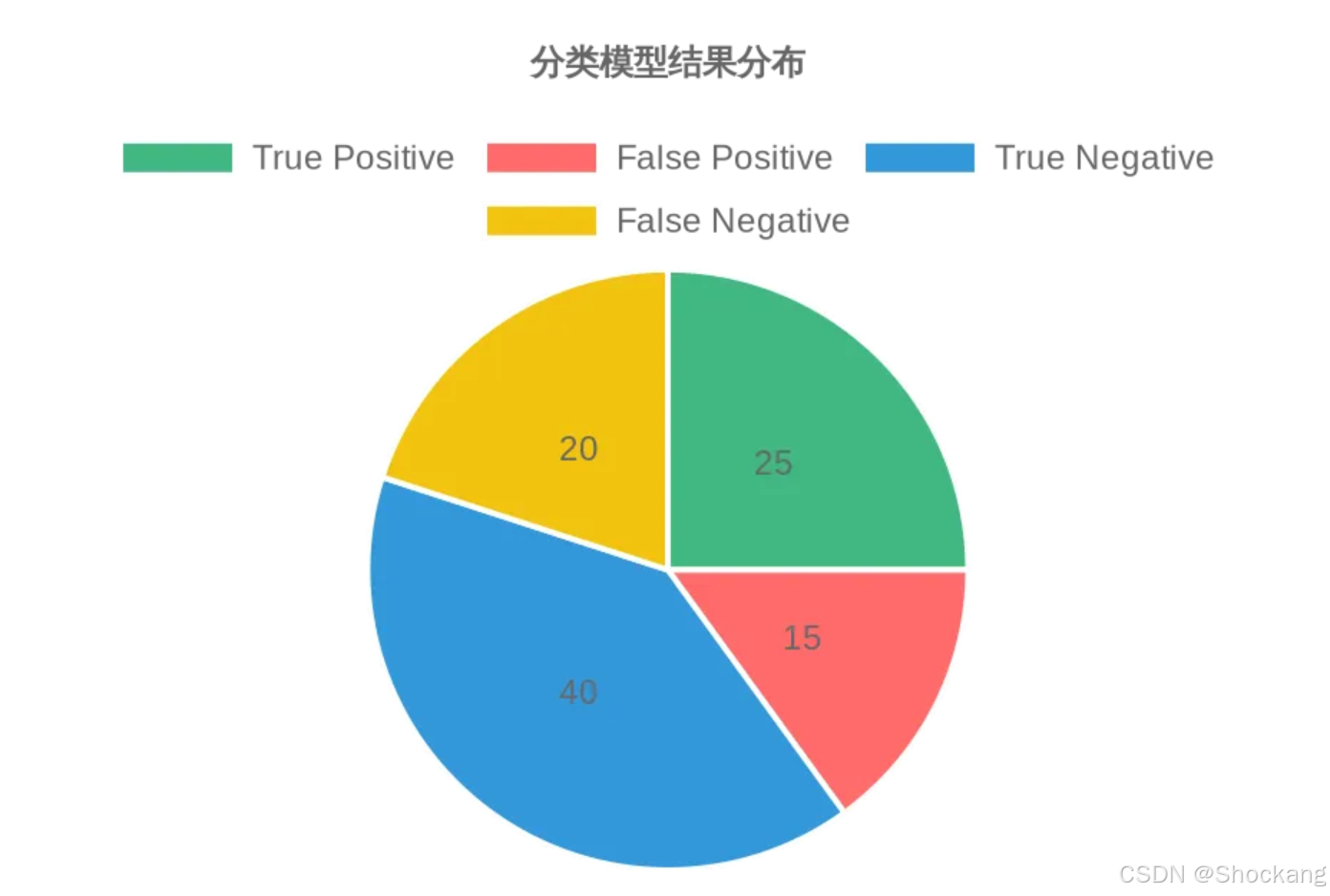
在深入理解假阳性率之前,我们需要先回顾分类问题中的基础概念——混淆矩阵(Confusion Matrix)。在二分类问题中,混淆矩阵包含四个关键元素:
- 真阳性(True Positive, TP): 模型正确地将正类样本预测为正类
- 假阳性(False Positive, FP): 模型错误地将负类样本预测为正类
- 真阴性(True Negative, TN): 模型正确地将负类样本预测为负类
- 假阴性(False Negative, FN): 模型错误地将正类样本预测为负类
这四个元素构成了评估分类模型性能的基础,如下表所示:
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 实际为正类 | TP(真阳性) | FN(假阴性) |
| 实际为负类 | FP(假阳性) | TN(真阴性) |
2.2 假阳性率的定义与计算
假阳性率(False Positive Rate, FPR)是指在所有实际为负类的样本中,被错误地预测为正类的比例。其计算公式为:
F P R = F P F P + T N FPR = \frac{FP}{FP + TN} FPR=FP+TNFP
从直观上理解,FPR表示的是模型将负类误判为正类的概率,也被称为"误报率"或"虚警率"。FPR越低,说明模型对负类的判别能力越强。
2.3 FPR的直观解释
想象一个机场安检系统,其任务是识别危险物品:
- 正类:危险物品
- 负类:安全物品
在这个场景中:
- 假阳性(FP):将安全物品错误地判定为危险物品,导致不必要的检查
- FPR:在所有安全物品中,被错误地标记为危险的比例
如果FPR=0.1,意味着10%的安全物品会被错误地标记为危险,导致不必要的安检流程和旅客延误。
3. 深入理解FPR:理论基础与重要性 🔬
3.1 FPR的统计学意义
从统计学角度看,FPR实际上是第一类错误(Type I Error)的概率,即错误地拒绝原假设的概率。在假设检验中,通常用显著性水平α来表示,它代表了我们愿意接受的假阳性率的上限。
在机器学习中,控制FPR就是在控制模型对负类样本的误判比例,这对许多应用场景至关重要,特别是那些"误报"成本高昂的情境。
3.2 FPR与决策阈值的关系
在大多数分类模型中,最终决策是基于一个阈值(threshold)来确定的。模型会为每个样本生成一个概率或分数,然后与阈值比较来决定最终分类:
- 如果分数 ≥ 阈值,预测为正类
- 如果分数 < 阈值,预测为负类
阈值的选择直接影响FPR:
- 降低阈值:更多样本会被预测为正类,FPR增加(但可能提高真阳性率)
- 提高阈值:更少样本会被预测为正类,FPR降低(但可能降低真阳性率)
这种权衡关系是ROC曲线分析的核心,我们将在后面详细讨论。
3.3 为什么FPR很重要?
FPR之所以重要,主要体现在以下几个方面:
-
成本考量:在许多场景中,假阳性会带来明显的成本或风险。例如,医疗诊断中的假阳性可能导致不必要的治疗和患者焦虑;欺诈检测中的假阳性可能阻碍正常交易。
-
资源分配:每个假阳性都可能消耗有限的资源。例如,安全系统中的假警报会分散安全人员的注意力。
-
用户体验:在产品应用中,高FPR可能严重影响用户体验。例如,垃圾邮件过滤器将正常邮件误判为垃圾邮件。
-
系统可信度:FPR过高会降低系统的整体可信度,导致"狼来了"效应,使用户忽视真正的警报。
4. FPR在不同应用场景中的重要性 🌐
4.1 医疗诊断
在医疗诊断领域,FPR代表将健康患者误诊为患病的比例。控制FPR对医疗系统至关重要,原因包括:
- 心理影响:错误的阳性诊断会给患者带来不必要的焦虑和心理负担
- 医疗资源浪费:后续不必要的检查和治疗会消耗有限的医疗资源
- 治疗风险:不必要的治疗可能带来副作用和并发症风险
例如,在癌症筛查中,高FPR会导致大量健康人接受不必要的活检,这不仅增加医疗成本,还会给患者带来身体和心理伤害。
4.2 欺诈检测
在金融欺诈检测系统中,FPR表示将正常交易误判为欺诈的比例。高FPR会带来严重后果:
- 客户体验受损:正常交易被拒绝会导致客户不满
- 业务损失:频繁的误报会降低交易量,影响收入
- 人工审核成本:每个报警通常需要人工审核,高FPR意味着高昂的人力成本
一个有效的欺诈检测系统需要在降低FPR的同时,保持对真实欺诈的高检出率,这是一个典型的平衡问题。
4.3 网络安全
在入侵检测、恶意软件识别等网络安全应用中,FPR代表将正常行为误判为威胁的比例:
- 警报疲劳:高FPR导致安全分析师面对大量误报,可能忽视真正的威胁
- 系统性能:每次报警通常会触发一系列防御措施,高FPR会降低系统性能
- 可信度降低:频繁的误报会降低安全系统的整体可信度
研究表明,在大型组织中,安全团队每天可能面对数百甚至数千个警报,其中大部分是假阳性。有效控制FPR是安全系统设计的核心挑战。
4.4 信息检索与推荐系统
在搜索引擎、内容过滤和推荐系统中,FPR表示将不相关内容错误地包含在结果中的比例:
- 用户体验:高FPR意味着用户需要筛选大量不相关内容
- 系统效率:推送不相关内容会浪费带宽和计算资源
- 用户信任:频繁推送不相关内容会降低用户对系统的信任
例如,在内容推荐系统中,将用户不感兴趣的内容频繁推送给用户,会导致用户参与度下降和流失。
5. FPR与其他评估指标的关系 📊
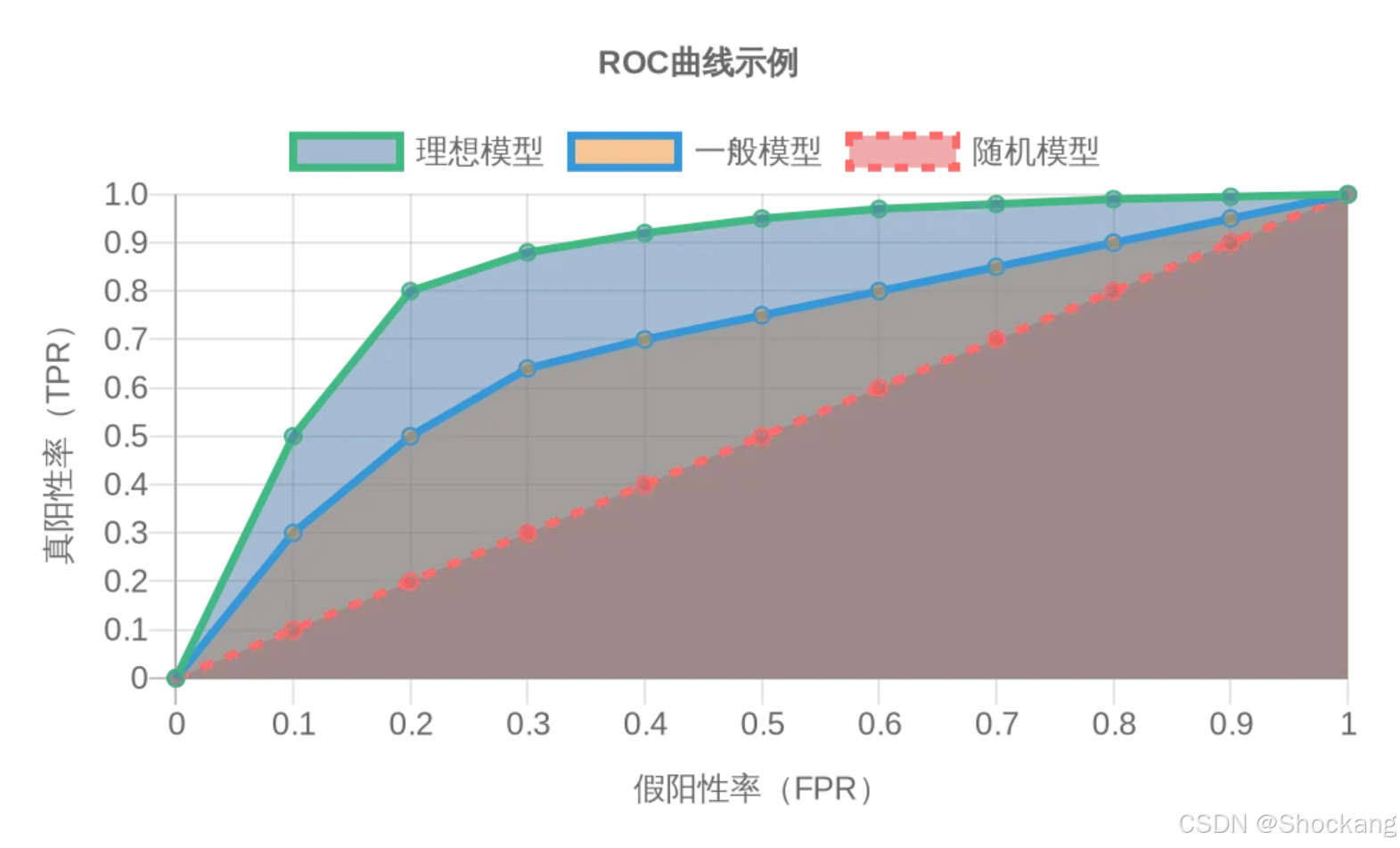
5.1 FPR与TPR:ROC曲线
真阳性率(True Positive Rate, TPR),也称为灵敏度(Sensitivity)或召回率(Recall),计算公式为:
T P R = T P T P + F N TPR = \frac{TP}{TP + FN} TPR=TP+FNTP
TPR与FPR共同构成了接收者操作特征曲线(Receiver Operating Characteristic Curve, ROC曲线)的两个坐标轴。ROC曲线是通过改变决策阈值,绘制不同阈值下TPR对FPR的曲线。
ROC曲线的特点:
- 曲线越靠近左上角,模型性能越好
- 对角线代表随机猜测的性能
- 曲线下面积(AUC)是模型性能的综合度量
5.2 FPR与精确率
精确率(Precision)表示在所有被预测为正类的样本中,真正属于正类的比例:
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
精确率与FPR的区别:
- FPR关注的是负类样本中被误判的比例
- 精确率关注的是预测为正类的样本中正确的比例
两者之间存在间接关系:在固定的TP数量下,FP增加会导致FPR增加,同时精确率降低。
5.3 特异性与FPR
特异性(Specificity)是FPR的补集,表示负类样本被正确分类的比例:
S p e c i f i c i t y = T N T N + F P = 1 − F P R Specificity = \frac{TN}{TN + FP} = 1 - FPR Specificity=

![STM32单片机入门学习——第30节: [9-6] FlyMcu串口下载STLINK Utility](https://i-blog.csdnimg.cn/direct/97e2313311e544b9b29b6be7d62da95e.png)