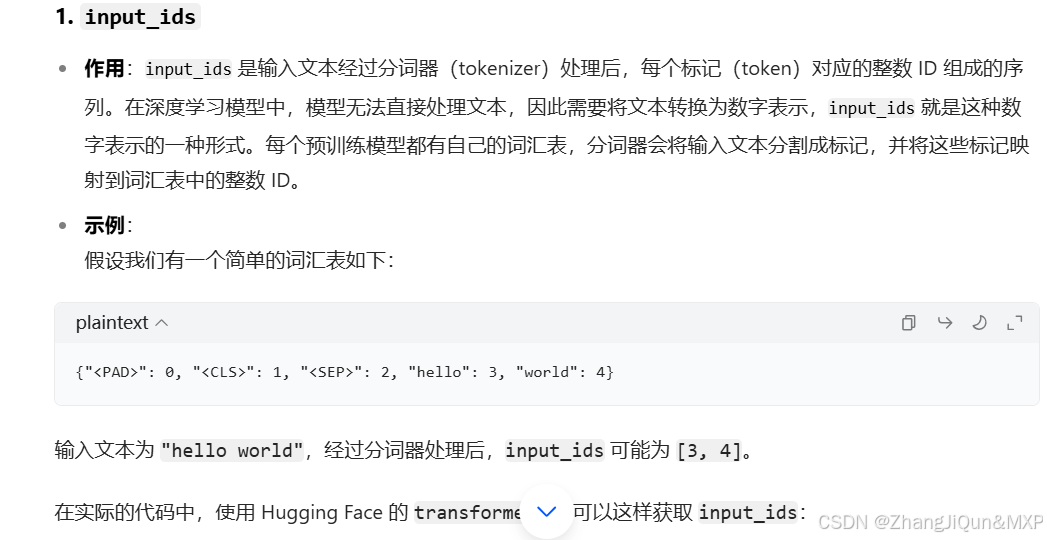
🍋🍋大数据学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
🍋一、CDH
CDH(Cloudera Distribution Including Apache Hadoop)是由Cloudera公司提供的一个集成了Apache Hadoop以及相关生态系统的发行版本。CDH是一个大数据平台,简化和加速了大数据处理分析的部署和管理。CDH提供Hadoop的核心元素-可伸缩存储和分布式计算-以及基于web的用户界面和重要的企业功能。CDH是Apache许可的开放源码,是唯一提供统一批处理、交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。
CDH是一个强大的商业版数据中心管理工具,提供了以下功能:
1.提供了各种能够快速稳定运行的数据计算框架,如Spark;
2.使用Apache Impala做为对HDFS、HBase的高性能SQL查询引擎;
3.使用Hive数据仓库工具帮助用户分析数据;
4.提供CM安装HBase分布式列式NoSQL数据库;
5.包含原生的Hadoop搜索引擎以及Cloudera Navigator Optimizer去对Hadoop上的计算任务进行一个可视化的协调优化,提高运行效率;
6.提供的各种软件能让用户在一个可视化的UI界面中方便地管理、配置和监控Hadoop以及其它所有相关组件,并有一定的容错容灾处理;
7.提供了基于角色的访问控制安全管理。
CDH和原生Hadoop区别
原生Hadoop的问题
1.版本管理过于混乱
2.部署过程较为繁琐,升级难度较大
3.兼容性差
4.安全性低
CDH优点
1. 提供基于web的用户界面,操作方便
2、集成的组件丰富,支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop
3、搭建容易,运维比原生hadoop方便。简化了大数据平台的安装和使用难度
4、版本划分清晰、更新速度快、文档清晰、支持多种安装方式、支持Kerberos安全认证等
CDH 组件
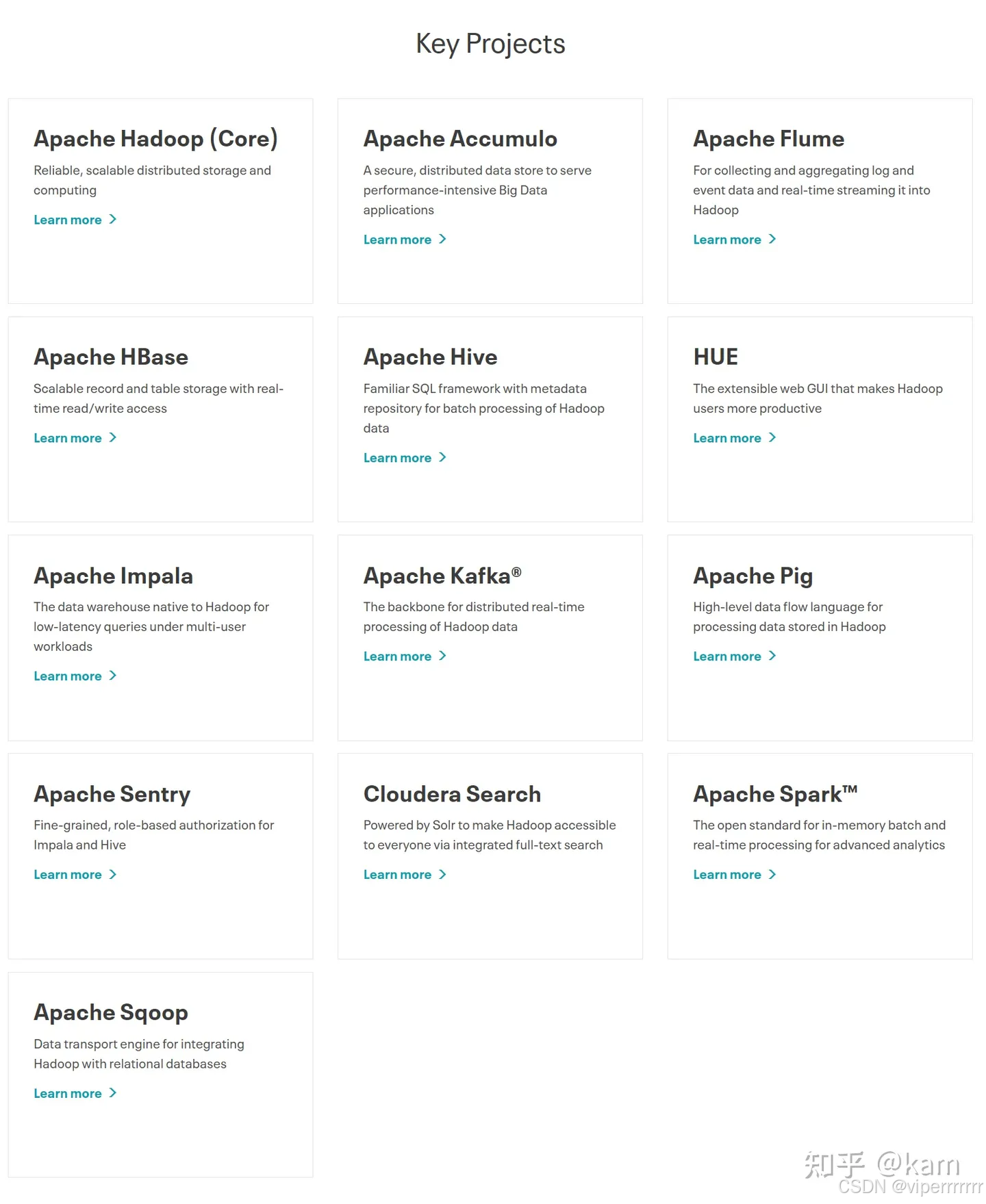
CDH作为一套开源的大数据处理平台,包含了许多不同的组件,每个组件都有各自的功能和特点。下面大概介绍下各个组件的功能和用途。
🍋二、Hadoop HDFS

Hadoop HDFS(Hadoop Distributed File System)是CDH中的一个核心组件,它是一个可扩展的分布式文件系统,用于存储大规模的数据文件。HDFS通过将文件切分为多个块,并将这些块分布在不同的计算节点上,实现了高可用性和高性能的文件存储。
HDFS文件系统维护着一个命名空间,它是一个树状结构,包含文件和目录。这个命名空间以根目录“/”开始,用户可以创建、删除文件和目录,以及修改它们的权限。
1.NameNode
负责客户端请求的响应
元数据的管理(查询,修改)
namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
2.JournalNode
NameNode之间共享数据(主要体现在 NameNode配置 HA)
3.DataNode
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
🍋三、Hadoop YARN
YARN的核心思想是将资源管理和作业调度从特定的计算框架(如MapReduce)中分离出来使其成为单独的守护进程,使得Hadoop集群能够更通用地支持多种类型的应用程序和工作负载。
这个想法是拥有一个全局的 ResourceManager ( RM ) 和每个应用程序的 ApplicationMaster ( AM )。应用程序可以是单个作业,也可以是作业的 DAG。ResourceManager 和 NodeManager 构成了数据计算框架。 ResourceManager是系统中所有应用程序之间资源仲裁的最终权威。 NodeManager 是每台机器的框架代理,负责容器、监视其资源使用情况(CPU、内存、磁盘、网络)并将其报告给ResourceManager/Scheduler。每个应用程序的 ApplicationMaster 实际上是一个特定于框架的库,其任务是与 ResourceManager 协商资源并与 NodeManager 一起执行和监视任务。(ApplicationMaster 是由应用程序框架(如 MapReduce、Spark、Impala 等)提供的。每个框架都会根据自己的需求和特点来实现 ApplicationMaster。这也意味着,不同的应用程序框架会有不同的 ApplicationMaster 实现,它们负责处理与框架相关的特定逻辑。)

Hadoop YARN(Yet Another Resource Negotiator)是CDH中的另一个核心组件,它是一个资源管理器,负责对集群中的计算资源进行统一管理和调度。YARN可以根据应用程序的需求,动态分配计算资源,实现任务的高效执行。
🍋四、Hadoop MapReduce
Hadoop MapReduce是CDH中用于分布式计算的编程模型和框架,它将大规模的数据切分为多个小任务,并在集群中的计算节点上并行执行这些任务。MapReduce可以实现大规模数据的处理和分析,支持复杂的数据转换和计算操作。
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责 Map 阶段的整个数据处理流程。
(3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。
🍋五、HBase
HBase是CDH的一个分布式数据库,它基于Hadoop HDFS存储数据,并提高性能的随机读写能力。HBase适用于需要快速访问和查询大规模数据的场景,如日志分析、推荐系统等。
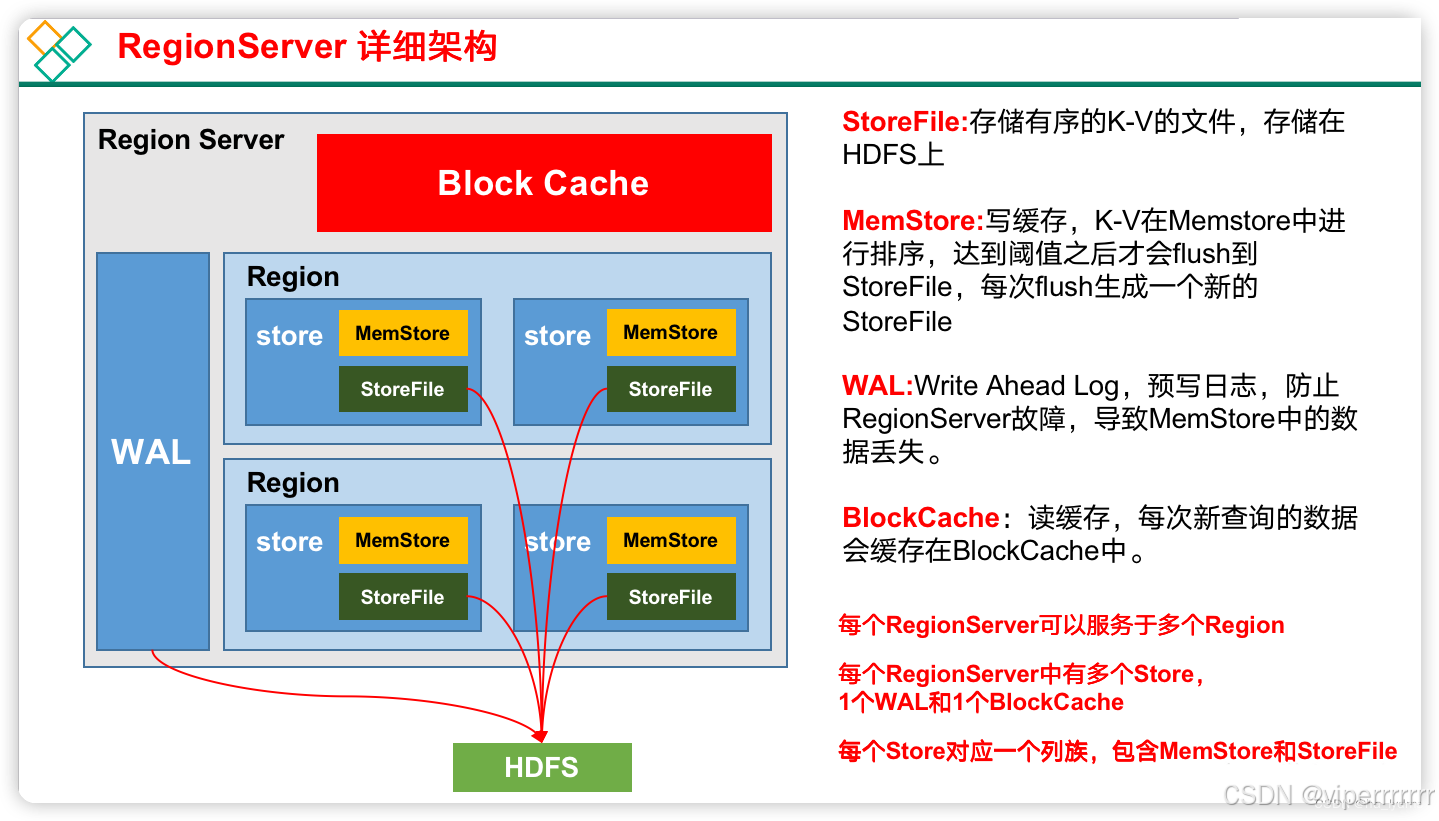
1)StoreFile
保存实际数据的物理文件,StoreFile以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
2)MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
3)HLog
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个实现了Write-Ahead logfile机制的文件HLog中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)BlockCache
读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。
🍋六、Hive
Hive是CDH中的一个数据仓库工具,它提供了类似于SQL的查询语言(HiveSQL),它可以将结构化的数据映射到Hadoop集群中的文件,并支持高性能的数据查询和分析。Hive可以方便地进行数据的ETL(Extract、Transform、Load)操作,适用于数据分析和报表生成等任务。
Hive

基于 MapReduce 或 Tez:
Hive 最初是基于 MapReduce 的,MapReduce 是一种批处理框架,适合处理大规模数据,但延迟较高。即使后来引入了 Tez 作为执行引擎,Hive 仍然是以批处理为核心,不适合低延迟查询。
中间结果写磁盘:
MapReduce 和 Tez 在执行过程中会将中间结果写入磁盘,导致额外的 I/O 开销。
🍋七、Impala
Impala是CDH中的一个交互式查询引擎,它可以直接访问存储在Hadoop HDFS和HBase中的数据,并提供类似于SQL的查询语言。Impala通过在内存中执行查询操作,实现了低延迟的数据查询和分析,适用于实时数据处理和探索性数据分析等场景。
Impala
直接访问 HDFS:Impala 直接读取 HDFS 数据,避免了 MapReduce 的额外开销。
优化数据格式:Impala 对 Parquet 和 ORC 等列式存储格式进行了深度优化,能够快速读取和处理数据。
数据本地性:Impala 充分利用数据本地性(Data Locality),在数据所在的节点上执行计算,减少了数据传输的开销。
内存计算:Impala的计算引擎支持基于内存的计算,能够大大降低查询的延迟。与传统的基于磁盘的MapReduce计算模型相比,Impala的内存计算模型在处理大规模数据集时具有更高的性能。
分布式并行处理:Impala的计算引擎采用分布式并行处理架构,能够将查询任务拆分成多个子任务,并在多个节点上并行执行。这种架构能够充分利用集群的计算资源,提高查询的吞吐量。
与存储引擎分离:Impala的计算引擎与存储引擎是分离的,这意味着Impala可以支持多种不同的存储系统,如HDFS、HBase等。这种分离的设计使得Impala更加灵活和可扩展。
Impala 的功能相对精简,专注于 OLAP 场景,适合快速查询。Impala 的设计目标是低延迟查询,适合实时分析和交互式查询。
🍋八、Sqoop
Sqoop架构
(1) Sqoop Client
Sqoop的客户端组件,提供了命令行工具和API,用于与Sqoop Server进行通信,并提交数据导入和导出的任务。
(2) Sqoop Server
Sqoop的服务器组件,负责接收来自客户端的请求,并协调和管理数据导入和导出的任务。Sqoop Server可以在独立模式下运行,也可以与Hadoop集群中的其他组件(如HDFS、YARN)集成。
(3) Connector
Sqoop的连接器,用于与不同类型的关系型数据库进行交互。每个关系型数据库都需要一个相应的连接器来支持数据的导入和导出。Sqoop提供了一些内置的连接器,如MySQL、Oracle、SQL Server等,同时还支持自定义连接器。
(4) Metastore
Sqoop的元数据存储,用于保存与数据导入和导出相关的元数据信息,如表结构、字段映射、导入导出配置等。Metastore可以使用关系型数据库(如MySQL、PostgreSQL)或Hadoop的分布式文件系统(HDFS)来存储元数据。
(5) Hadoop/HDFS
Sqoop与Hadoop生态系统紧密集成,使用Hadoop的分布式文件系统(HDFS)来存储导入的数据。Sqoop可以将关系型数据库中的数据导入到HDFS中,也可以将HDFS中的数据导出到关系型数据库中。
Sqoop是CDH中的数据导入导出工具,它可以将关系型数据库(如Mysql、Oracle等)中的数据导入到Hadoop集群中的HDFS或HBase中,也可以将Hadoop集群中的数据导出到关系型数据库中。Sqoop支持自动化的数据传输和转换,方便进行数据的迁移和集成。
🍋九、Flume
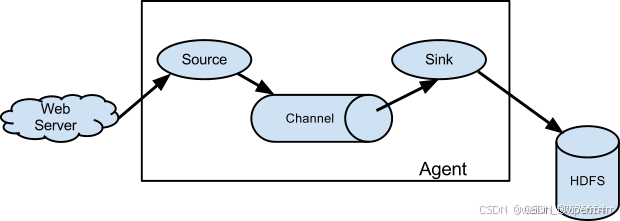
Flume 的架构设计简单但非常灵活,主要由以下几个核心组件构成:Source、Channel 和 Sink。这些组件通过配置文件进行定义和连接,形成一个数据流管道。
9.1 Source
Source 是 Flume 的数据输入组件,负责从外部数据源收集数据,并将数据转换为 Flume 的内部事件(Event)格式。常见的 Source 类型包括:
Exec Source:从命令执行的输出中读取数据,例如从 tail -F 命令读取日志文件。
Spooling Directory Source:从指定目录中读取新文件的内容。
Netcat Source:通过网络套接字接收数据。
HTTP Source:通过 HTTP POST 请求接收数据。
9.2 Channel
Channel 是 Flume 的数据缓冲组件,负责在 Source 和 Sink 之间暂存数据,确保数据传输的可靠性和高效性。常见的 Channel 类型包括:
Memory Channel:将数据存储在内存中,适用于低延迟和高吞吐量的场景。
File Channel:将数据存储在磁盘文件中,适用于需要高可靠性的场景。
Kafka Channel:使用 Apache Kafka 作为 Channel,适用于需要高可用性和持久化的场景。
9.3 Sink
Sink 是 Flume 的数据输出组件,负责将 Channel 中的数据传输到目标存储系统。常见的 Sink 类型包括:
HDFS Sink:将数据写入到 Hadoop 分布式文件系统(HDFS)。
HBase Sink:将数据写入到 HBase 数据库。
ElasticSearch Sink:将数据写入到 Elasticsearch。
Kafka Sink:将数据写入到 Apache Kafka。
Flume是CDH中的一个日志收集和传输工具,它可以实时地将分布在不同计算节点上的日志数据收集到中央存储(如HDFS)中。Flume支持灵活的数据流管道配置,可以根据需求进行数据过滤、转换和路由操作,适用于大规模分布式系统的日志管理。
🍋十、ZooKeeper
ZooKeeper是CDH中的一个分布式协调服务,它可以实现分布式系统中的数据一致性和协同操作。ZooKeeper提供了高可用性和高性能的数据存储和访问接口,可以用于分布式锁、配置管理、命名服务等场景。
ZooKeeper的选举机制是基于ZAB(Zookeeper Atomic Broadcast)协议的,这是一种基于Paxos协议的变种,专门用于ZooKeeper的分布式协调服务。该机制确保集群中只有一个领导节点(Leader),负责处理所有的写请求和大部分的读请求,其他的节点则作为跟随者(Follower)或观察者(Observer),负责处理读请求并接收来自领导者的更新。
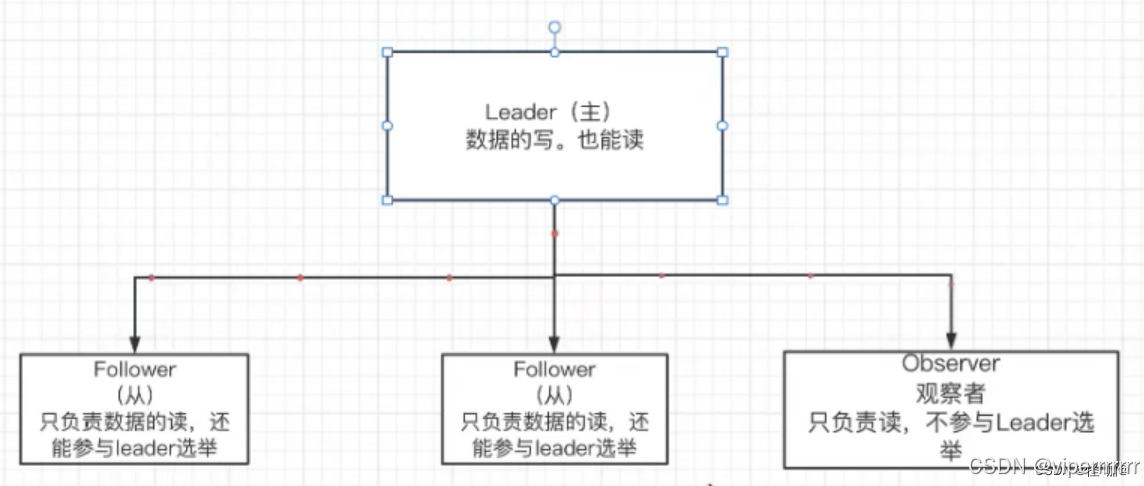
ZooKeeper 采用 主从架构,包含以下角色:
-
Leader
负责处理写请求和事务操作。通过选举机制产生。(ZooKeeper 的选举机制主要用于其集群管理,特别是在集群启动或领导者节点故障时,用于选出一个新的领导者节点。这个领导者节点将负责处理客户端的请求、维护集群状态以及与其他节点进行通信。) -
Follower
处理读请求,并将写请求转发给 Leader。参与 Leader 选举。 -
Observer(可选)
与 Follower 类似,但不参与选举,用于扩展读性能。 -
Client
与 ZooKeeper 集群交互的客户端。
🍋十一、Spark
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
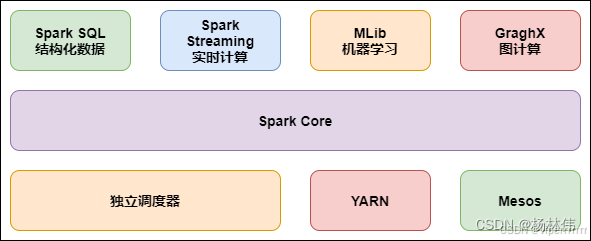
Spark有完善的生态圈,如下:
Spark Core:实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
Spark Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
🍋十二、Oozie
Oozie是一个工作流调度和协调工具,它可以将多个Hadoop任务组织成一个工作流,并按照指定的时间和依赖关系进行调度执行。Oozie支持复杂的任务依赖关系和条件触发,可以实现数据处理和分析的自动化流程控制。
🍋十三、CM(Cloudera Manager)
CDH分为Cloudera Manager管理平台(CM)和CDH parcel(parcel包含各种组件的安装包),需要先安装CM,再安装parcel
CM(Cloudera Manager)提供了一个管理和监控Hadoop等大数据服务的web界面,能让我们方便安装大数据生态圈的大部分服务。(至于具体CM运行见:https://blog.csdn.net/weixin_61006262/article/details/146241299?spm=1011.2124.3001.6209)