文章目录
- 一、二叉树
- 1. DFS
- 2. BFS
- 二、回溯模板
- 三、记忆化搜索
- 四、动态规划
- 1. 01背包
- 朴素版本
- 滚动数组优化
- 2. 完全背包
- 朴素版本
- 滚动数组优化
- 3. 最长递增子序列LIS
- 朴素版本
- 贪心+二分优化
- 4. 最长公共子序列
- 5. 最长回文子串
- 五、滑动窗口
- 六、二分查找
- 七、单调栈
- 八、单调队列
- 九、图论
- 1. 建图
- 邻接矩阵
- 邻接表
- 2. 图的遍历
- DFS
- BFS
- 3. 拓朴排序
- 4. 并查集
- 5. 最小生成树
- Kruskal
- Prim
- 6. BFS层序遍历求最短路
- 7. 迪杰斯特拉
- 朴素版本
- 堆优化版本
- 8. 弗洛伊德
- 9. 强连通分量
- 十、区间相关
- 1. 前缀和
- 2. 二维前缀和
- 3. 差分
- 4. 二维差分
- 5. 树状数组
- 6. 线段树
- 十一、杂项
- 1. 求质数/素数
- 2. 求约数
- 3. 快速幂
- 4. 离散化
- 5. 优先队列
- 6. 同余取模
一、二叉树
适用场景
一般情况下,两种方式是可以互相转换的,DFS代码会更加简洁。
DFS依赖于递归实现(栈)
BFS依赖于迭代实现(队列)
1. DFS
C++:
void dfs(TreeNode* node) {
if (!node) return;
//相应的处理
dfs(node->left);
dfs(node->right);
}
Java:
void dfs(TreeNode node) {
if (node == null) return;
//相应的处理
dfs(node.left);
dfs(node.right);
}
Python:
def dfs(node):
if not node: return
//相应的处理
dfs(node.left)
dfs(node.right)
2. BFS
C++:
void bfs(TreeNode* root) {
queue <TreeNode*> q;
q.push(root);
while (!q.empty()) {
int currentLevelSize = q.size();
for (int i = 1; i <= currentLevelSize; ++i) {
auto node = q.front(); q.pop();
ret.back().push_back(node->val);
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
}
}
Java:
void bfs(TreeNode root) {
Deque<TreeNode> queue = new LinkedList();
queue.addLast(root);
while(!queue.isEmpty()) {
int n = queue.size();
for (int i = 0 ; i < n ; i++) {
TreeNode node = queue.pollFirst();
if (node.left != null) queue.addLast(node.left);
if (node.right != null) queue.addLast(node.right);
}
}
}
Python:
def bfs(root):
queue = deque()
if root: queue.append(root)
while len(queue):
n = len(queue)
for i in range(n):
node = queue.popleft()
if node.left : queue.append(node.left)
if node.right: queue.append(node.right)
二、回溯模板
tip 适用场景
用于解决暴力枚举的场景,例如枚举组合、排列等。
C++:
vector<vector<int>> res;
vector<int> path;
void dfs(参数) {
if (满足递归结束) {
res.push_back(path);
return;
}
//递归方向
for (xxx) {
path.push_back(val);
dfs();
path.pop_back();
}
}
Java:
List<List<Integer>> res;
List<Integer> path;
void dfs(参数) {
if(满足递归结束) {
res.add(new LinkedList(path));
return;
}
//递归方向
for (xxx) {
path.add(val);
dfs();
path.remove(path.size() - 1);
}
}
Python:
res = []
path = []
def dfs(参数) :
if 满足递归结束:
res.append(list(path))
return
# 递归方向
for (xxxx):
path.append(val)
dfs()
path.pop()
三、记忆化搜索
适用场景
用于解决枚举过程中存在重复计算的场景问题。
此类题型一般也可以使用动态规划进行求解。
C++:
int dp[]; //初始化为-1,dp数组的维度取决于dfs函数的参数个数。
int dfs(int i) {
if (递归终止) return 0; //具体返回什么值要看题目的含义
if (dp[i] != -1) return dp[i];
int cnt = 0;
for (递归方向) {
cnt += dfs(xxx); //如果是计数,一般是叠加,也有可能是取最大或者最小
}
return dp[i] = cnt;
}
Java:
int[] dp; //初始化为-1,dp数组的维度取决于dfs函数的参数个数。
int dfs(int i) {
if (递归终止) return 0; //具体返回什么值要看题目的含义
if (dp[i] != -1) return dp[i];
int cnt = 0;
for (递归方向) {
cnt += dfs(xxx); //如果是计数,一般是叠加,也有可能是取最大或者最小
}
return dp[i] = cnt;
}
Python:
from functools import cache
@cache #缓存,避免重复运算
def dfs(i)->int:
if 终止: return 0 #具体返回什么值要看题目的含义
cnt = 0
for 递归方向:
cnt += dfs(xxx) #如果是计数,一般是叠加,也有可能是取最大或者最小
return cnt
四、动态规划
1. 01背包
适用场景
给出若干个物品,每个物品具有一定的价值和价格,求解在限定的总额下可以获取的最大价值,注意,每个物品只能选取一次。
朴素版本和滚动数组优化的区别主要在于空间复杂度上,时间复杂度差不多,所以笔试的时候基本上没差别(空间很少会被卡)。
朴素版本
C++:
int n, C; //n个物品, C表示背包容量
int v[], w[]; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int dp[n+1][C+1]; //容器规模
//初始化 dp[0][j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = 0 ; j <= C ; j++) {
if (j >= v[i - 1]) dp[i][j] = max(dp[i-1][j], dp[i-1][j-v[i-1]] + w[i - 1]);
else dp[i][j] = dp[i - 1][j];
}
}
return dp[n][C];
Java:
int n, C; //n个物品, C表示背包容量
int[] v, w; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int[][] dp = new int[n + 1][C + 1]; //容器规模
//初始化 dp[0][j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = 0 ; j <= C ; j++) {
if (j >= v[i - 1]) dp[i][j] = Math.max(dp[i-1][j], dp[i-1][j-v[i-1]] + w[i - 1]);
else dp[i][j] = dp[i - 1][j];
}
}
return dp[n][C];
Python:
n, C; #n个物品, C表示背包容量
v, w; #v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
dp = [[0 for _ in range(C+1)] for _ in range(n+1)] #容器规模
#初始化 dp[0][j] j∈[0,C]
for i in range(1, n+1):
for j in range(C+1):
if j>=v[i-1]: dp[i][j] = max(dp[i-1][j], dp[i-1][j-v[i-1]]+W[i-1])
else: dp[i][j] = dp[i-1][j]
return dp[n][C];
滚动数组优化
C++:
int n, C; //n个物品, C表示背包容量
int v[], w[]; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int dp[C+1]; //容器规模
//初始化 dp[j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = C ; j >= v[i - 1] ; j--) {
dp[j] = max(dp[j], dp[j-v[i-1]] + w[i - 1]);
}
}
return dp[C];
Java:
int n, C; //n个物品, C表示背包容量
int[] v, w; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int dp[C+1]; //容器规模
//初始化 dp[j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = C ; j >= v[i - 1] ; j--) {
dp[j] = Math.max(dp[j], dp[j-v[i-1]] + w[i - 1]);
}
}
return dp[C];
Python:
n, C; //n个物品, C表示背包容量
v, w; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
dp = [0 for _ in range(C+1)] //容器规模
//初始化 dp[j] j∈[0,C]
for i in range(1, n+1):
for j in range(C,v[i-1]-1,-1):
dp[j] = max(dp[j], dp[j-v[i-1]]+w[i-1])
return dp[C];
2. 完全背包
适用场景
给出若干个物品,每个物品具有一定的价值和价格,求解在限定的总额下可以获取的最大价值,注意,每个物品不限制选取次数。
朴素版本和滚动数组优化的区别主要在于空间复杂度上,时间复杂度差不多,所以笔试的时候基本上没差别(空间很少会被卡)。
朴素版本
C++:
int n, C; //n个物品, C表示背包容量
int v[], w[]; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int dp[n + 1][C + 1]; //容器规模
//初始化 dp[0][j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = 0 ; j <= C ; j++) {
if (j >= v[i - 1]) dp[i][j] = max(dp[i-1][j], dp[i][j-v[i-1]] + w[i - 1]);
else dp[i][j] = dp[i - 1][j];
}
}
return dp[n][C];
Java:
int n, C; //n个物品, C表示背包容量
int[] v, w; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int[][] dp = new int[n + 1][C + 1]; //容器规模
//初始化 dp[0][j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = 0 ; j <= C ; j++) {
if (j >= v[i - 1]) dp[i][j] = max(dp[i-1][j], dp[i][j-v[i-1]] + w[i - 1]);
else dp[i][j] = dp[i - 1][j];
}
}
return dp[n][C];
Python:
n, C; #n个物品, C表示背包容量
v, w; #v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
dp = [[0 for _ in range(C+1)] for _ in range(n+1)] #容器规模
#初始化 dp[0][j] j∈[0,C]
for i in range(1, n+1):
for j in range(C+1):
if j>=v[i-1]: dp[i][j] = max(dp[i-1][j], dp[i][j-v[i-1]]+W[i-1])
else: dp[i][j] = dp[i-1][j]
return dp[n][C];
滚动数组优化
C++:
int n, C; //n个物品, C表示背包容量
int v[], w[]; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int dp[C+1]; //容器规模
//初始化 dp[j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = v[i-1] ; j <= C ; j++) {
dp[j] = max(dp[j], dp[j-v[i-1]] + w[i - 1]);
}
}
return dp[C];
Java:
int n, C; //n个物品, C表示背包容量
int[] v, w; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
int dp[C+1]; //容器规模
//初始化 dp[j] j∈[0,C]
for (int i = 1 ; i <= n ; i++) {
for (int j = v[i-1] ; j <= C ; j++) {
dp[j] = Math.max(dp[j], dp[j-v[i-1]] + w[i - 1]);
}
}
return dp[C];
Python:
n, C; //n个物品, C表示背包容量
v, w; //v[i]表示第i个物品的价格/体积 w[i]表示第i个物品的价值
dp = [0 for _ in range(n+1)] //容器规模
//初始化 dp[j] j∈[0,C]
for i in range(1, n+1):
for j in range(C+1):
dp[j] = max(dp[j], dp[j-v[i-1]]+w[i-1])
return dp[C];
3. 最长递增子序列LIS
适用场景
给定一个数组,求数组最长上升子序列的长度。
朴素版本可以求解的数据规模约为 1000。如果题目数据给到了10000或者更大,需要使用贪心+二分进行优化。
朴素版本
C++:
int lengthOfLIS(vector<int>& nums) {
int dp[nums.size()];
int ans = 1;
dp[0] = 1;
for (int i = 1 ; i < nums.size() ; i++) {
dp[i] = 1;
for (int j = 0 ; j < i ; j++) {
if (nums[j] < nums[i]) {
dp[i] = max(dp[j] + 1, dp[i]);
}
}
ans = max(ans, dp[i]);
}
return ans;
}
Java:
public int lengthOfLIS(int[] nums) {
int[] dp = new int[nums.length];
Arrays.fill(dp, 1);
int ans = 1;
for (int i = 1 ; i < nums.length ; i++) {
for (int j = i - 1 ; j >= 0 ; j--) {
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
ans = Math.max(ans, dp[i]);
}
}
}
return ans;
}
Python:
def lengthOfLIS(self, nums: List[int]) -> int:
dp = [1 for _ in range(len(nums))]
for i in range(1, len(nums)):
for j in range(i):
if nums[i] > nums[j]:
dp[i] = max(dp[i], dp[j] + 1)
return max(dp)
贪心+二分优化
C++:
int lengthOfLIS(vector<int>& nums) {
vector<int> ls;
for (int num : nums) {
auto it = lower_bound(ls.begin(), ls.end(), num);
if (it == ls.end()) ls.push_back(num);
else *it = num;
}
return ls.size();
}
Java:
int lengthOfLIS(int[] nums) {
List<Integer> ls = new ArrayList<>();
for (int num : nums) {
int i = Collections.binarySearch(ls, num);
if (i < 0) i = -(i + 1);
if (i == ls.size()) ls.add(num);
else ls.set(i, num);
}
return ls.size();
}
Python:
def lengthOfLIS(self, nums: List[int]) -> int:
ls = []
for num in nums:
x = bisect_left(ls, num)
if x == len(ls):
ls.append(num)
else:
ls[x] = num
print(ls)
return len(ls)
4. 最长公共子序列
适用场景
求两个数组或者字符的最长公共的子序列的长度。时间复杂度为O(n^2)
C++:
int longestCommonSubsequence(string text1, string text2) {
int len1 = text1.size(), len2 = text2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1, 0));
for (int i = 1 ; i <= len1 ; i++) {
for (int j = 1 ; j <= len2 ;j++) {
if (text1[i - 1] == text2[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
return dp[len1][len2];
}
Java:
int longestCommonSubsequence(String text1, String text2) {
int len1 = text1.length();
int len2 = text2.length();
int[][] dp = new int[len1 + 1][len2 + 1];
for (int i = 1 ; i <= len1 ; i++) {
for (int j = 1 ; j <= len2 ; j++) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
return dp[len1][len2];
}
Python:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
len1, len2 = len(text1), len(text2)
dp = [[0] *(len2 + 1) for _ in range(len1 + 1)]
for i in range(1, len1 + 1):
for j in range(1, len2 + 1):
dp[i][j] = dp[i - 1][j - 1] + 1 if text1[i - 1] == text2[j - 1] else max(dp[i-1][j],dp[i][j-1])
return dp[len1][len2]
5. 最长回文子串
适用场景
求解一个数组/字符串的最长回文子串的长度,时间复杂度为O(n^2)。
C++:
int longestPalindrome(string s) {
int n = s.size();
bool dp[n][n];
int mxlen = -1;
for (int j = 0 ; j < n ; j++) {
for (int i = j ; i >= 0 ; i--) {
if (i == j) dp[i][j] = true;
else if (i + 1 == j) dp[i][j] = s[i] == s[j];
else {
dp[i][j] = s[i] == s[j] && dp[i + 1][j - 1];
}
if (dp[i][j] && j - i + 1 > mxlen) {
mxlen = j - i + 1;
}
}
}
return mxlen;
}
Java:
int longestPalindrome(String s) {
int n = s.length();
boolean[][] dp = new boolean[n][n];
char[] cs = s.toCharArray();
int mxlen = 0;
for (int j = 0 ; j < n ; j++) {
for (int i = j ; i >= 0 ; i--) {
if (i == j) dp[i][j] = true;
else if (i + 1 == j) dp[i][j] = cs[i] == cs[j];
else {
dp[i][j] = cs[i] == cs[j] && dp[i + 1][j - 1];
}
if (dp[i][j] && j - i + 1 > mxlen) {
mxlen = j - i + 1;
}
}
}
return mxlen;
}
Python:
def longestPalindrome(self, s: str) -> str:
n = len(s)
dp = [[False] * n for _ in range(n)]
maxlen = 0
for j in range(n):
for i in range(j + 1):
if i == j:
dp[i][j] = True
elif i + 1 == j:
dp[i][j] = s[i] == s[i + 1]
else:
dp[i][j] = s[i] == s[j] and dp[i + 1][j - 1]
if dp[i][j] and j - i + 1 >= maxlen:
maxlen = j - i + 1
return mxlen
五、滑动窗口
适用场景
求解数组/字符串 满足某个约束的最长/最短 的子数组/子串。需要满足二段性才可以使用。
C++:
for (int l = 0, r = 0 ; r < n ; r++) {
//如果右指针的元素加入到窗口内后,根据题目判断进行滑动左指针
while (l <= r && check()) l++;
}
六、二分查找
适用场景
满足二段性的数列中,求某一个值的位置、大于某个值的最小值、小于某个值的最大值。时间复杂度为O(logn)。
C++:
// 区间划分为[l,mid] 和 [mid+1,r],选择此模板
int bsec1(int l, int r)
{
while (l < r)
{
int mid = (l + r)/2;
if (check(mid)) r = mid;
else l = mid + 1;
}
return r;
}
// 区间划分为[l,mid-1] 和 [mid,r],选择此模板
int bsec2(int l, int r)
{
while (l < r)
{
int mid = ( l + r + 1 ) /2;
if (check(mid)) l = mid;
else r = mid - 1;
}
return r;
}
七、单调栈
适用场景
求序列中下一个更大、更小的元素。时间复杂度O(n)
C++:
stack<int> s;
for (int i = 0; i < n; ++i) {
while (!s.empty() && nums[i] > nums[s.top()]) {
int top = s.top();s.pop();
//此时说明 nums[top]的下一个更大的元素为nums[i]
}
s.push(i);
}
Java:
Stack<Integer> stack = new Stack();
for (int i = 0 ; i < nums.length ; i++) {
while(!stack.isEmpty() && nums[stack.peek()] < nums[i]) {
int top = stack.pop();
//此时说明 nums[top]的下一个更大的元素为nums[i]
}
stack.push(i);
}
Python:
stack = []
for i in range(len(nums)):
while stack and nums[stack[-1]] < nums[i]:
p = stack.pop()
# 此时说明 nums[top]的下一个更大的元素为nums[i]
stack.append(i)
八、单调队列
适用场景
求解移动区间的最值问题。时间复杂度O(n)
C++:
vector<int> res(nums.size() - k + 1); //存储长长度为k的每一个区间的最值
deque<int> queue;
for (int i = 0; i < nums.size(); i++) {
if (!queue.empty() && i - k + 1 > queue.front()) queue.pop_front();
while (!queue.empty() && nums[queue.back()] < nums[i]) queue.pop_back();
queue.push_back(i);
if (i >= k - 1) res[i - k + 1] = nums[queue.front()];
}
return res;
Java:
int n = nums.length;
int[] res = new int[n - k + 1];
Deque<Integer> q = new LinkedList();
for (int i = 0 ; i < n ; i++) {
if (!q.isEmpty() && i - q.getFirst() > k - 1) q.pollFirst();
while (!q.isEmpty() && nums[q.getLast()] < nums[i]) q.pollLast();
q.addLast(i);
if (i >= k - 1) res[i - k + 1] = nums[q.getFirst()];
}
return res;
Python:
res = [0] * (len(nums) - k + 1)
queue = deque()
for i in range(len(nums)):
if queue and i - k + 1 > queue[0]:
queue.popleft()
while queue and nums[queue[-1]] < nums[i]:
queue.pop()
queue.append(i)
if i >= k - 1:
res[i - k + 1] = nums[queue[0]]
return res
九、图论
1. 建图
建图的方式一般有两种,邻接矩阵和邻接表;链式前向星有些许晦涩,不一定要掌握。
1.邻接矩阵,适用于稠密图【边的数量远大于点】
2.邻接表,适用于稀疏图【点的数量远大于边】
邻接矩阵
C++:
int graph[n][n];
for (int i = 0 ; i < m ; i++) {
int a,b,w; //a和b存在一条边,权重为w
cin >> a >> b >> w;
graph[a][b] = graph[b][a] = w; // 如果是有向图则不需要建立双向边
}
Java:
int[][] graph = new int[n][n];
for (int i = 0 ; i < m ; i++) {
int a,b,w; //a和b存在一条边,权重为w
a = scanner.nextInt();
b = scanner.nextInt();
w = scanner.nextInt();
graph[a][b] = graph[b][a] = w; // 如果是有向图则不需要建立双向边
}
Python:
graph = [[0 for _ in range(n)] for _ in range(n)]
for i in range(n):
a,b,w = map(int, input().split())
graph[a][b] = graph[b][a] = w # 如果是有向图则不需要建立双向边
邻接表
C++:
vector<vector<pair<int,int>>> graph(n, vector<int>(0));
for (int i = 0 ; i < m ; i++) {
int a,b,w; //a和b存在一条边,权重为w
graph[a].push_back({b,w});
graph[b].push_back({a,w}); // 如果是有向图则不需要建立双向边
}
Java:
List<List<int[]>> graph = new ArrayList();
for (int i = 0 ; i <= n ;i++) graph.add(new LinkedList());
for (int i = 0 ; i < m ; i++) {
int a,b,w; //a和b存在一条边,权重为w
a = scanner.nextInt();
b = scanner.nextInt();
w = scanner.nextInt();
graph.get(a).add(new int[]{b,w});
graph.get(b).add(new int[]{a,w});// 如果是有向图则不需要建立双向边
}
Python:
graph = defaultdict(list)
for i in range(m):
a,b,w = map(int, input().split())
graph[a].append([b,w])
graph[b].append([a,w])
2. 图的遍历
DFS
C++:
vector<vector<pair<int,int>> graph;
vector<bool> vst;
void dfs(int node) {
for (auto p: graph[node]) {
int next = p.first, weight = p.second;
if (!vst[next]) {
vst[next] = true;
dfs(next);
// 如果需要回溯的话 , vst[next] = false;
}
}
}
Java:
List<List<int[]>> graph;
boolean[] vst;
void dfs(int node) {
for (auto p: graph[node]) {
int next = p[0], weight = p[1];
if (!vst[next]) {
vst[next] = true;
dfs(next);
// 如果需要回溯的话 , vst[next] = false;
}
}
}
Python:
graph
vst = [False for _ in range(n)]
def dfs(node):
for next,weight in graph[node]:
if not vst[next]:
vst[next] = True
dfs(next)
# 如果需要回溯的话 , vst[next] = false;
BFS
C++:
vector<vector<pair<int,int>> graph;
vector<bool> vst;
void bfs() {
queue<int> q;
q.push(start);
vst[start] = true;
while (!q.size()) {
int node = q.front();q.pop();
for (int p : graph[node]) {
int next = p.first, weight = p.second;
if (!vst[next]) {
vst[next] = true;
q.push_back(next);
}
}
}
}
Java:
List<List<int[]>> graph;
boolean[] vst;
void bfs() {
Deque<Integer> q;
q.addLast(start);
vst[start] = true;
while (!q.isEmpty()) {
int node = q.pollFirst();
for (int[] arr : graph.get(node)) {
int next = arr[0], weight = arr[1];
if (!vst[next]) {
vst[next] = true;
q.addLast(next);
}
}
}
}
Python:
graph
vst = [False for _ in range(n)]
def bfs():
q = deque()
q.append(start)
vst[start] = True
while q:
node = q.popleft()
for next,weight in graph[node]:
if not vst[next]:
vst[next] = True
q.append(next)
3. 拓朴排序
适用场景
求解有向图的拓扑序、有向图判断是否成环
C++:
vector<vector<int> graph;
vector<int> indegre; //存储每个节点的入度
queue<int> q;
for (int i = 0 ; i < n ; i++) {
if (indegre[i] == 0)q.push(i);
}
while(q.size()) {
int node = q.front(); q.pop();
for (int next : graph[node]) {
indegre[next]--;
if (indegre[next] == 0) q.push(next);
}
}
Java:
List<List<Integer>> graph;
int[] indegre; //存储每个节点的入度
Deque<Integer> q = new LinkedList();
for (int i = 0 ; i < n ; i++) {
if (indegre[i] == 0) q.addLast(i);
}
while (!q.isEmpty()) {
int node = q.pollFirst();
for (int next : graph.get(node)) {
indegre[next]--;
if (indegre[next] == 0) q.addLast(next);
}
}
Python:
graph = [[] for _ in range(n)]
indegre = [0] * n#存储每个节点的入度
q = deque()
for i in range(n):
if indegre[i]==0: q.append(i)
while q:
node = q.popleft()
for next in graph[node]:
indegre[next]-=1
if indegre[next] == 0: q.append(next)
4. 并查集
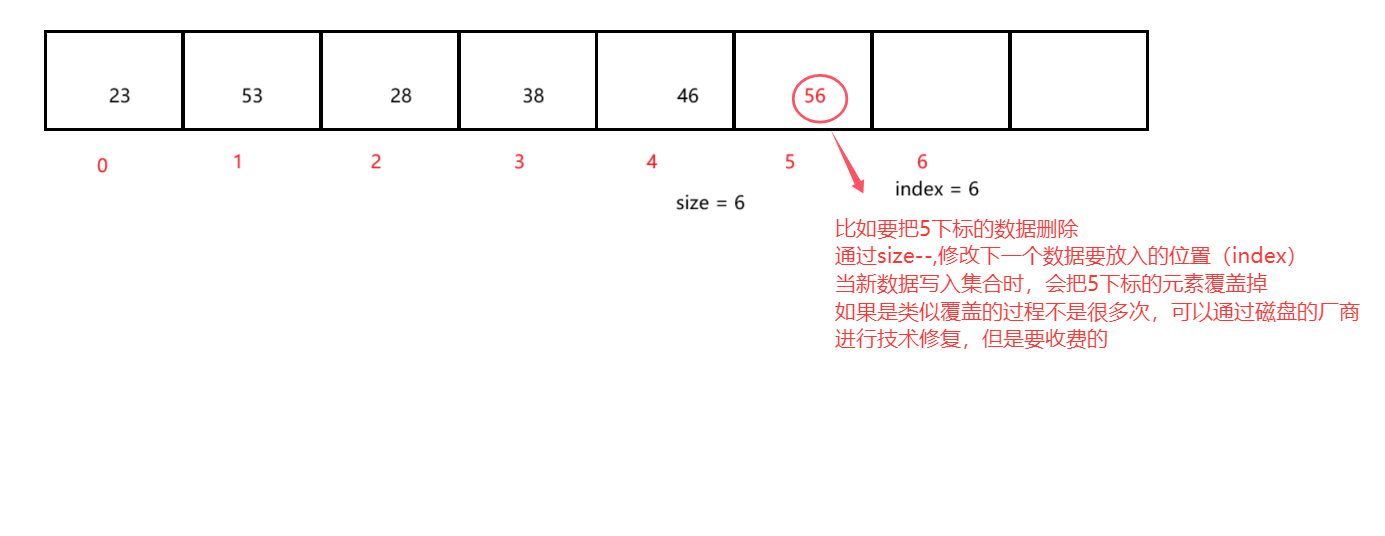
适用场景
用于解决 连通性问题。比如a和b相邻,b和c相邻,可以判断出a和c相邻。
C++:
int N = 1e5; //点的数量
int fa[N];
void init(int n) {
for (int i = 0;i < n ; i++) fa[i] = i;
}
//找到x的根节点
int find(int x) {
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
//合并两个节点
void union(int x, int y) {
fa[find(x)] = find(y);
}
Java:
int[] fa;
void init(int n) {
fa = new int[n];
for (int i = 0; i < n; i++) fa[i] = i;
}
//找到x的根节点
int find(int x) {
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
//合并两个节点
void union(int x, int y) {
fa[find(x)] = find(y);
}
Python:
fa = [i for i in range(n)]
#找到x的根节点
def find(x):
if x == fa[x]: return x
fa[x] = find(fa[x])
return fa[x]
#合并两个节点
def union(x,y):
fa[find(x)] = find(y)
5. 最小生成树
适用场景
连接无向图中所有的节点的最小费用。
常见的算法有2种:
- kruskal:稀疏图,时间复杂度是O(mlogm)。
- prim:稠密图,时间复杂度是O(n^2)。
ps:n是点的数量,m是边的数量
Kruskal
C++:
int N = 1e5; //点的数量
int fa[N];
void init(int n) {
for (int i = 0;i < n ; i++) fa[i] = i;
}
//找到x的根节点
int find(int x) {
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
//合并两个节点
void union(int x, int y) {
fa[find(x)] = find(y);
}
int kruskal(vector<vector<int>>& edges, int n, int m) {
// edges[i] = {a,b,w} 表示a和b之间存在有一条边,权重为w
init(n);
sort(edges.begin(), edges.end(), [](const vector<int>& a, const vector<int>& b){return a[2]<b[2];});
int ans = 0;
for (auto arr : edges) {
int a = arr[0], b = arr[1], w = arr[2];
if (find(a) != find(b)) {
union(a,b);
ans += w;
}
}
return ans;
}
Java:
int[] fa;
void init(int n) {
fa = new int[n];
for (int i = 0; i < n; i++) fa[i] = i;
}
//找到x的根节点
int find(int x) {
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
//合并两个节点
void union(int x, int y) {
fa[find(x)] = find(y);
}
int kruskal(int[][] edges, int n) {
// edges[i] = {a,b,w} 表示a和b之间存在有一条边,权重为w
init(n);
Arrays.sort(edges, (a,b)->a[2]-b[2]);
int ans = 0;
for (int[] arr: edges) {
int a = arr[0], b = arr[1], w = arr[2];
if (find(a) != find(b)) {
union(a,b);
ans += w;
}
}
return ans;
}
Python:
def kruskal(edges:List[List[int]], n:int,m:int) -> int:
edges.sort(key=lambda x : x[2])
fa = [i for i in range(n)]
#找到x的根节点
def find(x):
if x == fa[x]: return x
fa[x] = find(fa[x])
return fa[x]
#合并两个节点
def union(x,y):
fa[find(x)] = find(y)
ans = 0
for a,b,w in edges:
if find(a) != find(b):
union(a,b)
ans += w
return ans
Prim
C++:
int prim(vector<vector<int>>& graph, int n) {
vector<int> dis(n,INT_MAX);
vector<bool> vst(n, false);
int res = 0;
for (int i = 0 ; i < n ; i++) {
int min_index = -1;
for (int j = 0 ; j < n ; j++) {
if (!vst[j] && (min_index == -1 || dis[min_index] > dis[j]) min_index = j;
}
if (i != 0) res += dis[min_index];
vst[min_index] = true;
for (int j = 0 ; j < n ; j++) dis[j] = min(dis[j], graph[min_index][j]);
}
return res;
}
Java:
int prim(int[][] graph, int n) {
int[] dis = new int[n];
boolean[] vst = new boolean[n];
int res = 0;
Arrays.fill(dis, Integer.MAX_VALUE);
for (int i = 0 ; i < n ; i++) {
int min_index = -1;
for (int j = 0 ; j < n ; j++) {
if (!vst[j] && (min_index == -1 || dis[min_index] > dis[j]) min_index = j;
}
if (i != 0) res += dis[min_index];
vst[min_index] = true;
for (int j = 0 ; j < n ; j++) dis[j] = Math.min(dis[j], graph[min_index][j]);
}
return res;
}
Python:
def prim(graph: List[List[int]], n: int) -> int:
dis = [inf for _ in range(n)]
vst = [False for _ in range(n)]
res = 0
for i in range(n):
min_index = -1
for j in range(n):
if not vst[j] and (min_index == -1 or dis[min_index] > dis[j]) min_index = j
if i != 0: res += dis[min_index]
vst[min_index] = True
for j in range(n): dis[j] = min(dis[j], graph[min_index][j])
return res
6. BFS层序遍历求最短路
适用场景
如果图中的节点的不存在边权(边权均为1),那么直接BFS即可求出最短路。
C++:
// 返回从st到达target的最短路径
int bfs(int st, int target, int n, vector<vector<int>>& graph) {
queue<int> q;
vector<bool> vst(n, false);
q.push(st);
vst[st] = true;
int cnt = 0
while (!q.size()) {
int size = q.size();
while(size--) {
int node = q.front();q.pop();
if (node == target) return cnt;
for (int next: graph[node]) {
if (vst[next]) continue;
vst[next] = true;
q.push(next);
}
}
cnt++;
}
return -1;
}
Java:
// 返回从st到达target的最短路径
int bfs(int st, int target, int n, List<List<Integer>> graph) {
Deque<Integer> q;
boolean[] vst = new boolean[n];
q.addLast(st);
vst[st] = true;
int cnt = 0;
while (!q.isEmpty()) {
int size = q.size();
while (size-- > 0) {
int node = q.pollFirst();
if (node == target) return cnt;
for (int next: graph.get(node)) {
if (vst[next]) continue;
vst[next] = true;
q.addLast(next);
}
}
cnt++;
}
return -1;
}
Python:
def bfs(st: int, target: int, n: int, graph: dict) -> int:
q = deque()
vst = [False for _ in range(n)]
q.append(st)
vst[st] = True
cnt = 0
while q:
size = len(q)
for _ in range(size):
node = q.popleft()
if node == target: return cnt
for next in graph[node]:
if vst[next]: continue
vst[next] = True
q.append(next)
cnt+=1
return -1
7. 迪杰斯特拉
朴素版本
C++:
//求st为起点的最短路
//graph[i][j]: i到j的距离,不存在则初始化成最大值
//n表示节点的数量
void dijkstra(int st, int n, vector<vector<int>>& graph) {
vector<int> dis(n, INT_MAX);
vector<bool> vst(n, false);
dis[st] = 0;
for (int i = 0 ; i < n ; i++) {
int x = -1;
for (int j = 0 ; j < n ; j++) {
if (!vst[j] && (x == -1 || dis[j] < dis[x])) x=j;
}
vst[x] = true;
for (int j = 0 ; j < n ; j++) {
dis[j] = min(dis[j], dis[x] + graph[x][j]);
}
}
}
Java:
//求st为起点的最短路
//graph[i][j]: i到j的距离,不存在则初始化成最大值
//n表示节点的数量
void dijskra(int[][] G, int st, int ed, int n) {
int[] dis = new int[n + 1];
Arrays.fill(dis, 100010);
dis[st] = 0;
boolean[] vst = new boolean[n + 1];
for (int i = 0; i < n; i++) {
int x = -1;
for (int y = 0; y < n; y++) {
if (!vst[y] && (x == -1 || dis[y] < dis[x])) x = y;
}
vst[x] = true;
for (int y = 0; y < n; y++) dis[y] = Math.min(dis[y], dis[x] + G[x][y]);
}
}
Python:
def dijkstra(st: int, n: int, graph: List[List[int]]):
dis = [inf for _ in range(n)]
vst = [False for _ in range(n)]
dis[st] = 0
for i in range(n):
x = -1
for y in range(n):
if not vst[y] and (x==-1 or dis[y] < dis[x]): x = y
vst[x] = True
for y in range(n):
dis[y] = min(dis[y], dis[x] + graph[x][y])
堆优化版本
C++:
void dijkstra(int st, int n, vector<vector<pair<int,int>>>& graph) {
vector<int> dis(n, INT_MAX);
vector<bool> vst(n, false);
dis[st] = 0;
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<>> pq;
pq.push({0, st});
while (!pq.size()) {
int d = pq.top().first();
int u = pq.top().second();
pq.pop();
if (vst[u]) continue;
vist[u] = true;
for (auto [v,w] : graph[u]) {
if (dis[v] > dis[u] + w) {
dis[v] = dis[u] + w;
pq.push({dis[v], v});
}
}
}
}
Java:
void dijkstra(int st, int n, List<List<int[]>> graph) {
int[] dis = new int[n];
Arrays.fill(dis, Integer.MAX_VALUE);
boolean[] vst = new boolean[n];
dis[st] = 0;
PriorityQueue<int[]> pq = new PriorityQueue<>((a,b)->a[0]-b[0]);
pq.add(new int[]{0, st});
while (!pq.isEmpty()) {
int[] arr = pq.poll();
int d = arr[0], u = arr[1];
if (vst[u]) continue;
vst[u] = true;
for (int[] A: graph.get(u)) {
int v = A[0], w = A[1];
if (dis[v] > dis[u] + w) {
dis[v] = dis[u] + w;
pq.add(new int[]{dis[v], v});
}
}
}
}
Python:
def dijkstra(st: int, n: int, graph: dict):
dis = [inf for _ in range(n)]
vst = [False for _ in range(n)]
dis[st] = 0
h = []
heapq.heappush(h, [0, st])
while h:
d,u = heapq.heappop(h)
if vst[u]: continue
vst[u] = True
for v,w in graph[u]:
if dis[v] > dis[u] + w:
dis[v] = dis[u] + w
heapq.heappush(h, [dis[v], v])
8. 弗洛伊德
适用场景
多源最短路,可以在O(n^3)的时间内求出任意两个点的最短距离。
C++:
vector<vector<int>> dp;
for (int i = 0 ; i < n ; i++) {
for (int j = 0 ; j < n ; j++) {
dp[i][j] = graph[i][j];
}
}
for (int k = 0 ; k < n ; k++) {
for (int i = 0 ; i < n ; i++) {
for (int j = 0 ; j < n ; j++) {
dp[i][j] = min(dp[i][j], dp[i][k]+dp[k][j]);
}
}
}
Java:
int[][] dp = new int[n][n];
for (int i = 0 ; i < n ; i++) {
for (int j = 0 ; j < n ; j++) {
dp[i][j] = graph[i][j];
}
}
for (int k = 0 ; k < n ; k++) {
for (int i = 0 ; i < n ; i++) {
for (int j = 0 ; j < n ; j++) {
dp[i][j] = Math.min(dp[i][j], dp[i][k]+dp[k][j]);
}
}
}
Python:
dp = [[graph[i][j] for i in range(n)] for j in range(n)]
for k in range(n):
for i in range(n):
for j in range(n):
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j])
9. 强连通分量
可以用tarjan算法找到图中强连通分量的大小\每个节点属于哪个强连通分析.
ps:
强连通分量 (SCC)
在有向图中,一个强连通分量是最大的子图,其中任何两个顶点 u 和 v 都是相互可达的,即存在从 u 到 v 的路径,也存在从 v 到 u 的路径。
Python:
def tarjan(n, adj):
dfn = [0] * n # 访问节点时的时间戳
low = [0] * n # 节点可达的最低时间戳
in_stack = [False] * n # 布尔数组,用于检查节点是否在栈中
stack = [] # 用于存储节点的栈
dfncnt = 1 # 用于给访问的节点分配唯一编号的计数器
scc = [0] * n # 存储每个节点所属的强连通分量(SCC)编号的数组
sc = 0 # 找到的SCC数量的计数器
sz = [0] * n # 每个SCC的大小
def dfs(u):
nonlocal dfncnt, sc
dfn[u] = low[u] = dfncnt # 给节点分配时间戳
dfncnt += 1
stack.append(u) # 将当前节点加入栈
in_stack[u] = True # 标记节点为在栈中
for v in adj[u]: # 遍历每个相邻节点
if dfn[v] == 0: # 如果节点未被访问
dfs(v)
low[u] = min(low[u], low[v]) # 更新当前节点的最低可达时间戳
elif in_stack[v]: # 如果相邻节点在栈中
low[u] = min(low[u], dfn[v]) # 更新当前节点的最低可达时间戳,仅包括在栈中的节点
# 如果当前节点是SCC的根节点
if dfn[u] == low[u]:
sc += 1
while True:
v = stack.pop() # 弹出节点
in_stack[v] = False # 标记节点不在栈中
scc[v] = sc # 分配SCC编号
sz[sc - 1] += 1 # 增加SCC大小
if v == u: # 如果回到根节点,结束循环
break
# 从每个未访问的节点运行DFS
for i in range(n):
if dfn[i] == 0:
dfs(i)
return scc, sz # 返回SCC编号和每个SCC的大小
十、区间相关
1. 前缀和
适用场景
多次求区间和。O(n)的时间预处理出前缀和数组后,可以O(1)求出区间的和。不支持区间修改。
C++:
vector<int> nums;
int n;
vector<int> pre_sum(n + 1, 0);
for (int i = 1 ; i <= n ; i++ ) pre_sum[i] = pre_sum[i-1] +nums[i-1];
//查询区间和[left, right], 其中left,right是下标。
int sum = pre_sum[right+1] - pre_sum[lef t];
Java:
int[] nums;
int n;
int[] pres = new int[n + 1];
for (int i = 1; i <= n; i++) {
pre_sum[i] = pre_sum[i-1] +nums[i-1];
}
//查询区间和[left, right], 其中left,right是下标。
int sum = pre_sum[right+1] - pre_sum[left];
Python:
#python语法糖可以求前缀和
pres = list(accumulate(a,initial=0))
2. 二维前缀和
C++:
vector<vector<int>> matrix;
int m = matrix.size(), n = matrix[0].size();
vector<vector<int>> pre(m + 1, vector<int>(n + 1));
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
pre[i][j] = pre[i - 1][j] + pre[i][j - 1] - pre[i - 1][j - 1] + matrix[i - 1][j - 1];
}
}
# 查询子矩阵的和 [x1,y1] [x2,y2]表示子矩阵的左上和右下两个顶点
int sum = pre[x2 + 1][y2 + 1] - pre[x1][y2 + 1] - pre[x2 + 1][y1] + pre[x1][y1];
Java:
int[][] matrix;
int m = matrix.length, n = matrix[0].length;
int[][] pre = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
pre[i][j] = pre[i - 1][j] + pre[i][j - 1] - pre[i - 1][j - 1] + matrix[i - 1][j - 1];
}
}
# 查询子矩阵的和 [x1,y1] [x2,y2]表示子矩阵的左上和右下两个顶点
int sum = pre[x2 + 1][y2 + 1] - pre[x1][y2 + 1] - pre[x2 + 1][y1] + pre[x1][y1];
Python:
matrix # 原二维矩阵
m, n = len(matrix), len(matrix[0])
pre = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
pre[i][j] = pre[i - 1][j] + pre[i][j - 1] - pre[i - 1][j - 1] + matrix[i - 1][j - 1]
# 查询子矩阵的和 [x1,y1] [x2,y2]表示子矩阵的左上和右下两个顶点
sum_ = pre[x2 + 1][y2 + 1] - pre[x1][y2 + 1] - pre[x2 + 1][y1] + pre[x1][y1];
3. 差分
适用场景
给定一个数组和多次区间修改的操作,求修改后的数组。
C++:
int diff[10001];
void update(int l, int r, int val) {
diff[l] += v;
if (r+1 <n) diff[r+1] -= v;
}
int main() {
int nums[] = {1,3,2,4,5};
int n = sizeof(nums) / sizeof(int);
diff[0] = nums[0];
for(int i = 1; i < n; i++) diff[i] = nums[i] - nums[i - 1];
//多次调用update后,对diff数组求前缀和可以得出 多次修改后的数组
int* res = new int[n]; //修改后的数组
res[0] = diff[0];
for (int i=1 ; i<=n ; i++) res[i] += res[i-1] + diff[i];
}
Java:
int[] nums = {1,3,2,4,5};
int n = nums.length;
int[] diff = new int[n];
diff[0] = nums[0];
for (int i=0; i<n;i++) diff[i] = nums[i] - nums[i-1];
void update(int l, int r, int v) {
diff[l] += v;
if (r+1<n) diff[r+1] -=v;
}
int[] res = new int[n];
res[0] = diff[0];
for(int i=1;i<n;i++)res[i]=res[i-1]+diff[i];
Python:
nums = [1,3,2,4,5]
n = len(nums)
diff = [1 for _ in range(n)]
for i in range(1, n):
diff[i] = nums[i] - nums[i-1]
#将区间[l,r]的元素都加上v
def update(l, r, v):
diff[l] += v
if r+1 < n:
diff[r+1] -= v
'''多次调用update后,对diff数组求前缀和可以得出 多次修改后的数组'''
res = [0 for _ in range(n)]
res[0] = diff[0]
for i in range(1,n):
res[i] += res[i-1] + diff[i]
4. 二维差分
C++:
vector<vector<int>> matrix; //原数组
int n, m ; //长宽
vector<vector<int>> diff(n+1, vector<int>(m+1, 0));
void insert(int x1, int y1, int x2, int y2, int d) {
diff[x1][y1] += d;
diff[x2+1][y1] -= d;
diff[x1][y2+1] -= d;
diff[x2+1][y2+1] += d;
}
for (int i = 1 ; i <= n ; i++ ) {
for (int j = 1 ; j <= m ; j++) {
insert(i,j,i,j,matrix[i][j]);
}
}
int q; //修改次数
cin >> q;
while (q--) {
int x1,y1,x2,y2,d;
cin >> x1 >> y1 >> x2 >> y2 >> d;
insert(x1,y1,x2,y2,d);
}
for (int i = 1 ; i <= n ; i++) {
for (int j = 1 ; j <= m ; j++) {
matrix[i][j] = matrix[i-1][j] + matrix[i][j-1] - matrix[i-1][j-1] + diff[i][j];
}
}
// matrix就是复原后的数组
Java:
int[][] matrix; //原数组
int n,m; // 原数组的行列
int[][] diff; //差分数组
void insert(int x1, int y1, int x2, int y2, int d) {
diff[x1][y1] += d;
diff[x2+1][y1] -= d;
diff[x1][y2+1] -= d;
diff[x2+1][y2+1] += d;
}
void solution() {
diff = new int[n+1][m+1];
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
insert(i,j,i,j, matrix[i][j]);
}
}
int q ; //修改次数
while (q-- > 0) {
int x1,y1,x2,y2,d; // 输入需要修改的子矩阵顶点
insert(x1,y1,x2,y2,d);
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
matrix[i][j] = matrix[i-1][j] + matrix[i][j-1] - matrix[i-1][j-1] + diff[i][j];
}
}
}
Python:
'''二维矩阵依然可以进行差分运算'''
n, m = 0,0 #行和列
a = [[0 for _ in range(m+1)] for _ in range(n+1)] #原数组
diff = [[0 for _ in range(m+1)] for _ in range(n+1)]
def insert(x1, y1,x2,y2,d):
diff[x1][y1] += d
diff[x2+1][y1] -= d
diff[x1][y2+1] -= d
diff[x2+1][y2+1] += d
#差分数组初始化
for i in range(1, n+1):
for j in range(1,m+1):
insert(i,j,i,j,a[i][j])
q = 0 #修改次数
while q:
q-=1
x1,y1,x2,y2,d = 0,0,0,0,0 #对于矩阵的值增加d
insert(x1,y1,x2,y2,d)
#还原数组
for i in range(1,n+1):
for j in range(1,m+1):
a[i][j] = a[i-1][j] + a[i][j-1] -a[i-1][j-1]+ diff[i][j]
print(a)
5. 树状数组
适用场景
当我们进行 单点修改,然后进行区间 区间查询、单点查询的时候,适用树状数组可以在logn的复杂度求解。
C++:
vector<int> tree(MAXN, 0);
int lowbit(int x) {
return x&(-x);
}
// 单点修改,第i个元素增加x
inline void update(int i, int x)
{
for (int pos = i; pos < MAXN; pos += lowbit(pos))
tree[pos] += x;
}
// 查询前n项和
inline int query(int n)
{
int ans = 0;
for (int pos = n; pos; pos -= lowbit(pos))
ans += tree[pos];
return ans;
}
// 查询区间[a,b]的和
inline int query(int a, int b)
{
return query(b) - query(a - 1);
}
Java:
int[] tree; //长度为n,初始化为0
int N;
int lowbit(int x) {return x&(-x);}
// 单点修改,第i个元素增加x
void update(int i, int x) {
for (int p = i ; p < N ; p+=lowbit(p)) tree[p] += x;
}
// 查询前n项和
int query(int n) {
int ans = 0;
for (int p = n ; p; p -= lowbit(p)) ans += tree[p];
return ans;
}
// 查询区间[a,b]的和
int query(int a, int b) {
return query(b) - query(a-1);
}
Python:
class BIT:
def __init__(self, n):
self.MXN = n+1
self.tree = [0 for _ in range(self.MXN)]
def lowbit(self,x):
return x & (-x)
# 下标为index的元素新增x
def update(self,index, x):
i = index+1 #树状数组的下标从1开始
while i < self.MXN:
self.tree[i] += x
i += self.lowbit(i)
# 查询前n项总和
def queryPre(self,n):
ans = 0
while n:
ans += self.tree[n]
n -= self.lowbit(n)
return ans
# 查询区间[a,b]的和
def query(self,a, b):
return self.queryPre(b+1) - self.queryPre(a)
6. 线段树
适用场景
当我们需要区间修改、区间查询、单点查询的时候,可以使用线段树,能够在logn的复杂度下求解。
C++:
#define MAXN 100005
typedef long long ll;
ll n, m, A[MAXN], tree[MAXN * 4], mark[MAXN * 4]; // A原数组、 tree线段树数组、mark懒标记数组
inline void push_down(ll p, ll len)
{
mark[p * 2] += mark[p];
mark[p * 2 + 1] += mark[p];
tree[p * 2] += mark[p] * (len - len / 2);
tree[p * 2 + 1] += mark[p] * (len / 2);
mark[p] = 0;
}
// 建树
void build(ll l = 1, ll r = n, ll p = 1)
{
if (l == r)
tree[p] = A[l];
else
{
ll mid = (l + r) / 2;
build(l, mid, p * 2);
build(mid + 1, r, p * 2 + 1);
tree[p] = tree[p * 2] + tree[p * 2 + 1];
}
}
void update(ll l, ll r, ll d, ll p = 1, ll cl = 1, ll cr = n)
{
if (cl > r || cr < l)
return;
else if (cl >= l && cr <= r)
{
tree[p] += (cr - cl + 1) * d;
if (cr > cl)
mark[p] += d;
}
else
{
ll mid = (cl + cr) / 2;
push_down(p, cr - cl + 1);
update(l, r, d, p * 2, cl, mid);
update(l, r, d, p * 2 + 1, mid + 1, cr);
tree[p] = tree[p * 2] + tree[p * 2 + 1];
}
}
ll query(ll l, ll r, ll p = 1, ll cl = 1, ll cr = n)
{
if (cl > r || cr < l)
return 0;
else if (cl >= l && cr <= r)
return tree[p];
else
{
ll mid = (cl + cr) / 2;
push_down(p, cr - cl + 1);
return query(l, r, p * 2, cl, mid) + query(l, r, p * 2 + 1, mid + 1, cr);
}
}
/**
1.输入数组A,注意下标从[1,n]。
2.调用update(l,r,d)函数,这里的l和r并不是下标。
3.调用query(l,r) 这里的l和r并不是下标
*/
Java:
int MXN = 10005 ;
int n;
int[] A,tree,mark;
// 初始化
void init(int n) {
this.n = n;
A = new int[MXN];
tree = new int[MXN *4];
mark = new int[MXN *4];
}
void push_down(int p, int len) {
mark[p * 2] += mark[p];
mark[p * 2 + 1] += mark[p];
tree[p * 2] += mark[p] * (len - len / 2);
tree[p * 2 + 1] += mark[p] * (len / 2);
mark[p] = 0;
}
//构建线段树
void build() {
build(1,n,1);
}
void build(int l, int r, int p) {
if (l==r) tree[p] = A[l];
else {
int mid = (l+r) / 2;
build(l,mid, p*2);
build(mid+1,r,p*2+1);
tree[p] = tree[p*2] + tree[p*2+1];
}
}
// 区间[l,r]的值新增d
void update(int l, int r, int d) {
update(l,r,d, 1,1,n);
}
void update(int l, int r, int d, int p, int cl, int cr) {
if (cl > r || cr < l) return;
else if (cl >= l && cr <= r) {
tree[p] += (cr - cl + 1) * d;
if (cr > cl) mark[p] += d;
}
else {
int mid = (cl+cr) / 2;
push_down(p, cr-cl+1);
update(l,r,d,p*2,cl,mid);
update(l,r,d,p*2+1,mid+1,cr);
tree[p] = tree[p*2] + tree[p*2 + 1];
}
}
// 查询区间[l,r]的和
int query(int l, int r) {
return query(l, r,1,1,n);
}
int query(int l, int r, int p, int cl, int cr) {
if (cl > r || cr < l) return 0;
else if (cl >= l && cr <= r) return tree[p];
else {
int mid = (cl + cr) / 2;
push_down(p, cr-cl+1);
return query(l,r,p*2,cl,mid) + query(l,r,p*2+1,mid+1,cr);
}
}
void solution() {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
init(n);
for (int i = 1; i <= n; i++) {
A[i] = sc.nextInt(); // 输入元素
}
build();
update(1,2,2); // 更新区间[0,1],新增2, 这里并不是下标!!!
System.out.println(query(1,5)); // 查询区间[l,r]的总和,这里并不是下标!!!
}
Python:
MXN = int(1e5 + 5)
n = int(input())#数组长度
A = [0] + [int(c) for c in input().split(" ")]
tree = [0 for _ in range(MXN * 4)]
mark = [0 for _ in range(MXN * 4)]
def push_down(p, len):
mark[p * 2] += mark[p]
mark[p * 2 + 1] += mark[p]
tree[p * 2] += mark[p] * (len - len // 2)
tree[p * 2 + 1] += mark[p] * (len // 2)
mark[p] = 0
def build(l=1, r=n,p=1):
if l==r: tree[p] = A[l]
else:
mid = (l+r) // 2
build(l,mid,p*2)
build(mid+1,r,p*2+1)
tree[p] = tree[p*2] + tree[p*2 + 1]
def update(l,r,d,p=1,cl=1,cr=n):
if cl > r or cr < l: return
elif cl >= l and cr <= r:
tree[p] += (cr - cl + 1) * d
if cr > cl: mark[p] += d
else:
mid = (cl + cr) // 2
push_down(p, cr-cl+1)
update(l,r,d,p*2,cl,mid)
update(l,r,d,p*2+1,mid+1,cr)
tree[p] = tree[p*2] + tree[p*2+1]
def query(l,r,p=1,cl=1,cr=n):
if cl > r or cr < l: return 0
elif cl >= l and cr <= r: return tree[p]
else:
mid = (cl + cr) // 2
push_down(p, cr-cl+1)
return query(l,r,p*2,cl,mid) + query(l,r,p*2+1,mid+1,cr)
'''
1.输入数组A,注意下标从[1,n]。
2.调用update(l,r,d)函数,这里的l和r并不是下标。
3.调用query(l,r) 这里的l和r并不是下标
'''
十一、杂项
1. 求质数/素数
适用场景
筛法求质数,时间复杂度约为O(n)。
C++:
int cnt;
vector<int> primes;
bool st[N];
void get_primes(int n) {
for (int i = 2 ; i <= n ; i++) {
if (!st[i]) {
primes.push_back(i);
for (int j = i + i ; j <= n ; j += i) st[j] = true;
}
}
}
Java:
int cnt;
List<Integer> primes;
boolean[] st = new boolean[N];
void get_primes(int n) {
for (int i = 2 ; i <= n ; i++) {
if (!st[i]) {
primes.add(i);
for (int j = i+i ; j <= n ; j+=i) st[j] = true;
}
}
}
Python:
maxCNt
primes = [] #存储了组后的素数
st = [False for _ in range(maxCNt)]
index = 0
for i in range(2, maxCNt):
if not st[i]:
primes.append(i)
for j in range(i+i, maxCNt, i): st[j] = True
2. 求约数
适用场景
根号N的时间复杂度下求出一个数字的所有约数。
C++:
vector<int> get_divisors(int n) {
vector<int> res;
for (int i = 1; i <= n / i ; i++) {
if (n % i == 0) {
res.push_back(i);
if (i != n / i) res.push_back(n / i);
}
}
sort(res.begin(), res.end());
return res;
}
Java:
List<Integer> get_divisors(int n) {
List<Integer> res = new LinkedList();
for (int i = 1 ; i <= n /i ; i++) {
if (n%i == 0) {
res.add(i);
if (i!=n/i) res.add(n/i);
}
}
Collections.sort(res);
return res;
}
Python:
def get_divisors(n: int):
res = []
i = 1
while i <= n//i:
if n%i==0:
res.append(i)
if i!=n//i: res.append(n//i)
i+=1
res.sort()
return res
3. 快速幂
适用场景
快速的求出x的y次方。时间复杂度O(logn)
C++:
long long fast_pow(int x, int y, int mod) {
long long res = 1;
while (y > 0) {
if (y % 2 == 1) {
res = (long long)res * x % mod;
}
x = (long long)x * x % mod;
y /= 2;
}
return res;
}
Java:
long fastPow(int x, int y, int mod) {
long res = 1;
while (y > 0) {
if (y % 2 == 1) {
res = ((long)res * x % mod);
}
x = ((long)x * x % mod);
y /= 2;
}
return res;
}
Python:
def fast_pow(x, y, mod):
res = 1
while y > 0:
if y % 2 == 1:
res = (res * x) % mod
x = (x * x) % mod
y //= 2
return res
4. 离散化
适用场景
当数据值比较大的时候,可以映射成更小的值。例如[101,99,200] 可以映射成[1,0,2]。
C++:
int A[MAXN], C[MAXN], L[MAXN]; //原数组为A
memcpy(C, A, sizeof(A)); // 复制原数组到C中
sort(C, C + n); // 数组排序
int l = unique(C, C + n) - C; // 去重
for (int i = 0; i < n; ++i)
L[i] = lower_bound(C, C + l, A[i]) - C + 1; // 二分查找
Java:
int[] A = new int[MAXN];
int[] C = new int[MAXN];
int[] L = new int[MAXN];
System.arraycopy(A, 0, C, 0, A.length); // 复制原数组到C中
Arrays.sort(C); // 数组排序
int l = Arrays.stream(C).distinct().toArray().length; // 去重
for (int i = 0; i < n; ++i)
L[i] = Arrays.binarySearch(C, 0, l, A[i]) + 1; // 二分查找
Python:
a = [] #原数组
as = sorted(list(set(a)))
LS = [bisect.bisect_left(as,a[i]) for i in range(n)]
#其中,LS[i]表示的就是a[i]对应的离散后的下标。
5. 优先队列
C++:
priority_queue<int, vector<int>, [](int a, int b) {return a>b;}; // 队列存储int类型比较
priority_queue<int, vector<vector<int>>, [](const vector<int>& a, const vector<int>& b) {return a[1]>b[1];}; // 队列存储vector类型,按照第二个元素进行排序
Java:
PriorityQueue<Integer> pq = new PriorityQueue<Integer>((a,b)->a-b);// 队列存储int类型比较
PriorityQueue<int[]> pq = new PriorityQueue<int[]>((a,b)->a[1]-b[1]); // 队列存储vector类型,按照第二个元素进行排序
Python:
h = []
heapq.heappush(h, x) #插入元素
heapq.heappop(h) #弹出最小元素
6. 同余取模
你需要将最终答案表示成一个分数 a/b,其中a和b是互质的整数,但是题目要求你不是直接输出这个分数, 而是一个整数x,满足:

Python:
MOD = 10**9 + 7
# 使用费马小定理快速计算逆元(只适用于m是质数的情况)
def fast_inv(a, m=MOD):
return pow(a, m-2, m)
# 计算a/b mod MOD的值
def compute(a, b):
# 计算b的逆元
b_inv = fast_inv(b)
# 计算并返回结果
return (a * b_inv) % MOD
# 示例
a = 2
b = 3
result = compute(a, b)
print(f"The result is: {result}")