LLM 为什么使用ID,每个单词不都是有编码的吗
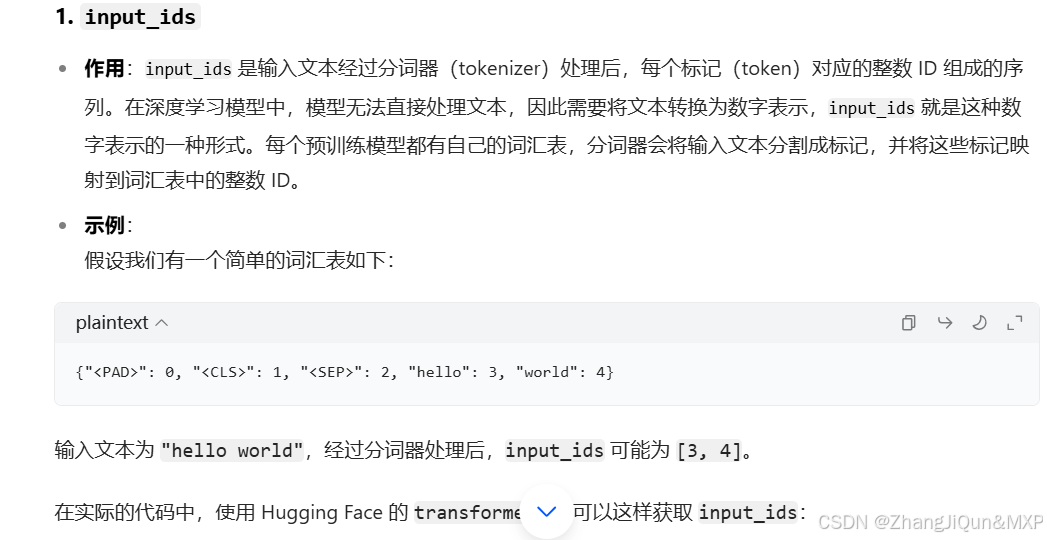
在自然语言处理(NLP)里,把文本转换为整数 ID 来表示是一种常见的做法,以下为你详细阐述使用 ID 的原因,以及是否每个单词都有编码。
使用 ID 的原因
1. 计算机可处理性
计算机没办法直接处理文本数据,因为文本是人类使用的符号系统,计算机只能处理数字。所以,要把文本转换为数字形式,这样模型才能对其进行计算和学习。使用整数 ID 是一种简单且高效的文本数字化表示方法。
2. 减少内存占用
相较于直接使用字符串来表示文本,使用整数 ID 可以显著减少内存占用。例如,一个较长的单词字符串可能需要多个字节来存储,而一个整数 ID 通常只需要几个字节。这样在处理大规模文本数据时,能节省大量的内存空间。
3. 方便模型计算
深度学习模型通常是基于张量(Tensor)进行计算的,张量中的元素是数字。使用整数 ID 可以直接将文本转换为张量